







 本文介绍了MapReduce的入门示例WordCount的启动过程,并对其工作原理进行了简单阐述,重点讨论了Shuffle阶段在MapReduce中如何整理数据以提高reduce阶段的效率。
本文介绍了MapReduce的入门示例WordCount的启动过程,并对其工作原理进行了简单阐述,重点讨论了Shuffle阶段在MapReduce中如何整理数据以提高reduce阶段的效率。
前言:任何一种编程语言,开场白基本都是“Hello World”,那么对于Hadoop的计算框架MapReduce一样有着自己的“开场白”,那就是“WordCount”,词频统计这一实例,在任何一个版本的Hadoop安装程序中都会有,下面也会给大家初步介绍如何启动,并分享一下我对Shuffle的初步理解
WordCount实例启动
1.创建任意文本并上传到HDFS
hadoop-2.8.1]$ bin/hdfs dfs -put test.log /wordcount/input/
2.提交jar包,计算,结果输出到/wordcount/output1中
hadoop-2.8.1]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /wordcount/input /wordcount/output1
3.查看输出目录
hadoop-2.8.1]$ hdfs dfs -ls /wordcount/output1
4.查看输出文件
hadoop-2.8.1]$ hdfs dfs -cat /wordcount/output1/part-r-00000WC作为MapReduce的初级实例,对我们理解MapReduce工作原理有很大帮助,详细内容大家可以参考如下博客链接。
Shuffle初步理解
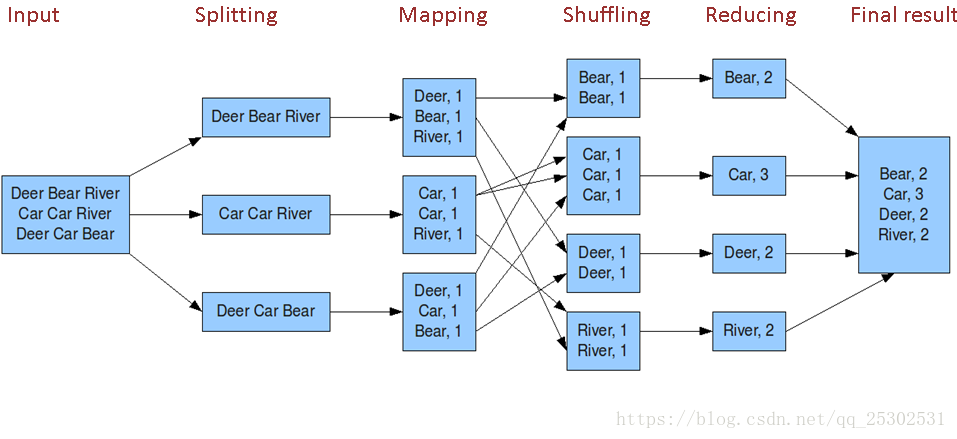
MapReduce的运行,按照时间顺序可分为:输入切片(input split)、map阶段、combiner阶段、shuffle阶段和reduce阶段。详细的介绍可以参考上文中提到的链接。
在运行一个MapReduce计算任务的时候,任务过程会被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。shuffle是map的输出作为reduce的输入之间的过程,也是MapReduce工作中优化的重点。
MapReduce所处理的数据都是海量文件,如上图所示,shuffle阶段将map阶段各节点中key相同的值进行归类,这样在reduce阶段就能较轻松的完成数据的规约输出,提高reduce的工作效率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









