







MySQL有B+Tree 索引及Hash索引等索引类型,B+Tree索引类型是MySQL采用最多的索引类型。Hash索引使用场景比较有限,文章将从Hash索引的底层结构出发,来分析Hash索引的利与弊。
1 hash数据结构
hash数据结构由键、哈希函数及哈希表组成。
键:可以是任何字符串或整数,作为哈希函数的输入。
哈希函数:接收输入键并返回值,该值为哈希表的数组元素的索引。
哈希表:以关联方式将数据存储在数组中,其中每个数据值都有自己的唯一索引。
1.1 为什么需要哈希数据结构
我们可以用数组来存储数据,但是在进行数据检索时,需要一个个检索,时间复杂度为O(n),我们通过哈希数据结构,可以将复杂度缩短为O(1)。
1.2 哈希函数
| 唯一性 | 能生成唯一的哈希值。 |
| 固定性 | 生成的哈希值长度是固定的。 |
| 不可逆性 | 一种单向函数,无法从哈希值推导出原始输入。 |
| 确定性 | 给定相同的输入,哈希函数总能生成相同的哈希值。 |
| 散列性 | 输出值看起来是随机的,并且即使输入值只有一点微小的变化,映射出来的哈希值也截然不同。 |
表 哈希函数的特点
哈希函数主要有以下作用:
- 具有极强的错误检测能力,输入有很小的不同,输出将会有很大的不同。
- 数据完整性验证,验证数据在传输或存储过程是否被篡改。当数据被传输或存储时,将原始数据进行哈希求值。然后将哈希值与接收到的数据的哈希值比较,如果两个哈希值不同,则说明数据已被篡改。
- 密码存储。
- 哈希表。
哈希函数性能从以下方面来评价:
- 高效可计算。
- 均匀地分布键。
- 尽量减少碰撞。
- 具有较低的负载系数(项目数/表的大小),较高的值会减少空间开销哎,但会增加查找成本。
1.2.1 极简的哈希函数-MOD
哈希值 = 键值 MOD X; 即取键值除以X的余数。X最好是素数,这样可以确保哈希值分布更均匀。
比如有键值:2,5,7,9,11。X取值为7.则对应的哈希值分别为:2,5,0,2,4。
这种函数计算键值速度快,但是X取值需要特别的考虑。
1.3 碰撞
不同的键值可能产生相同的哈希值(比如上面的键值2和9),这种情况称为碰撞。在哈希表中,面对这种情况该如何存储值。有两种方案:1)链接法;2)开放寻址。
1.3.1 链接法
发生碰撞时,在对应的哈希表数组位置建立个链式结构,将值分别插入到链式结构中。
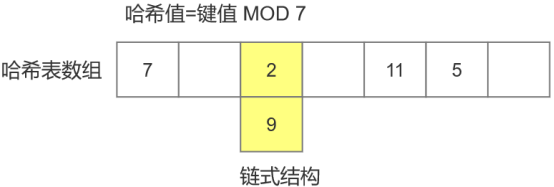
图 链接法示意图
1.3.2 开放寻址
所有原始都存储在哈希表本身中,每个哈希表数组元素包含一条记录或NULL。查找元素时,会逐个检查表槽,直到找到所需的元素或者明确该元素不在表中。
| 线性探测 |
|
| 二次探测 | 计算原始哈希值,并添加任意二次多项式的连续值,直到找到空槽。 |
| 双重哈希 | 利用两个函数f1及f2,先用f1计算哈希值,如果位置不为空,则借助f2来计算新的哈希值。 (f1(k) + i * f2(k))%n,其中n表示哈希表大小,k是键值,i是碰撞次数。 |
表 开放寻址的三种算法
2 MySQL的hash索引
MySQL的hash索引采用的是链式哈希表结构。是基于内存的支持,增删改查的时间复杂度都是O(1)。它只适合等值查找,其他查找时,发挥不了作用。
因为hash结构及其基于内存的缘故,hash索引有以下的缺陷:
- 绝对部分数据存放在磁盘,hash索引无法减少磁盘I/O次数,其只适用于小数据量的等值查询。
- 不同的键值经过hash计算后,最后的位置非常不确定,没有任何顺序。所以不适合范围、模糊查找及排序。
- 一旦哈希表扩容,就会导致所有的索引值重新计算存储位置,效率低。
2.1 自适应哈希索引
看似哈希索引百无一用,但是在MySQL中,有一种哈希索引发挥着关键的作用:自适应哈希索引。
索引根据存储形式分为聚集索引及二级索引。当我们使用二级索引进行查询时,MySQL会根据二级索引查询到的主键值,进行回表查询(即再根据主键值来获取该条数据)。频繁的回表查询将会降低查询效率。
自适应哈希索引,是为了避免频繁回表而创建的。MySQL会判断哪些二级索引值是热查询,为它们建立自适应索引,查询时,根据这个索引直接获取数据,而无需通过主键再获取数据。















 7751
7751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









