









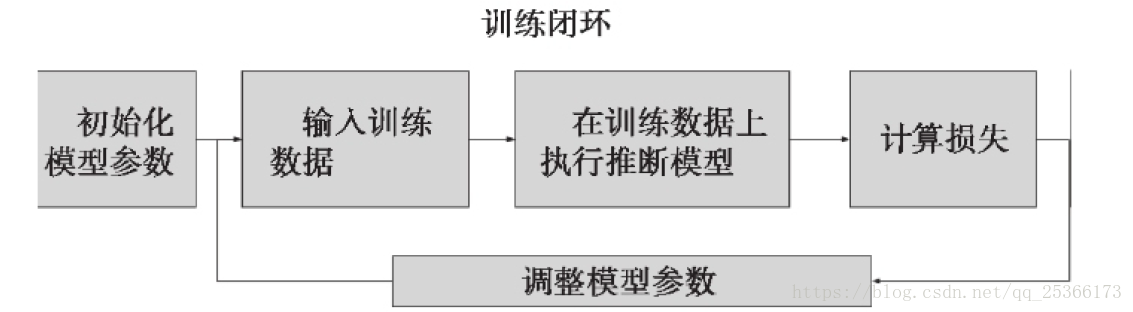
数据流图的高层、通用训练闭环
我们创建了一个训练闭环,它具有如下功能。
·首先对模型参数进行初始化。通常采用对参数随机赋值的方法,但对于比较简单的模型,也可以将各参数的初值均设为0。
·读取训练数据(包括每个数据样本及其期望输出)。通常人们会在这些数据送入模型之前,随机打乱样本的次序。
·在训练数据上执行推断模型。这样,在当前模型参数配置下,每个训练样本都会得到一个输出值。
·计算损失。损失是一个能够刻画模型在最后一步得到的输出与来自训练集的期望输出之间差距的概括性指标。
·调整模型参数。这一步对应于实际的学习过程。给定损失函数,学习的目的在于通过大量训练步骤改善各参数的值,从而将损失最小化。最常见的策略是使用梯度下降算法
上述闭环会依据所需的学习速率、所给定的模型及其输入数据,通过大量循环不断重复上述过程。
当训练结束后,便进入评估阶段。在这一阶段中,我们需要对一个同样含有期望输出信息的不同测试集依据模型进行推断,并评估模型在该数据集上的损失。该测试集中包含了何种样本,模型是预先无法获悉的。通过评估,可以了解到所训练的模型在训练集之外的推广能力。一种常见的方法是将原始数据集一分为二,将70%的样本用于训练,其余30%的样本用于评估。
下面利用上述结构为模型训练和评估定义一个通用的代码框架:
import tensorflow as tf # 初始化变量和模型参数,定义训练闭环中的运算 def inference(X): # 计算推断模型在数据X上的输出,并将结果保存 pass def loss(X, Y): # 依据训练数据X和期望输出Y计算损失 pass def inputs(): # 读取或生成训练数据X及其期望输出Y pass def train(total_loss): # 依据计算的总损失训练或调整模型参数 pass def evaluate(sess, X, Y): # 对训练得到的模型进行评估 pass # 在一个会话对象中启动数据流图,搭建流程 with tf.Session() as sess: tf.initialize_all_variables().run() X, Y = inputs() total_loss = loss(X, Y) train_op = train(total_loss) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 实际的训练迭代次数 training_steps = 1000 for step in range(training_steps): sess.run([train_op]) # 处于调试和学习的目的,查看损失在训练过程中的递减情况 if step % 10 == 0: print("loss:", sess.run([total_loss])) evaluate(sess, X, Y) coord.request_stop() coord.join(threads) sess.close()以上便是模型训练和评估的基本代码框架。首先需要对模型参数进行初始化;然后为每个训练闭环中的运算定义一个方法:读取训练数据(inputs方法),计算推断模型(inference方法),计算相对期望输出的损失(loss方法),调整模型参数(train方法),评估训练得到的模型(evaluate方法);之后,启动一个会话对象,并运行训练闭环。














 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









