










 本文介绍了如何在Ubuntu系统中安装CUDA和cudnn,以及如何在MindSpore环境中使用GPU进行minist数据集实验,包括数据预处理、模型定义、损失函数和优化器的使用,重点讲解了value_and_grad函数在反向传播中的应用。
本文介绍了如何在Ubuntu系统中安装CUDA和cudnn,以及如何在MindSpore环境中使用GPU进行minist数据集实验,包括数据预处理、模型定义、损失函数和优化器的使用,重点讲解了value_and_grad函数在反向传播中的应用。
1、安装GPU版
安装GPU版需要CUDA和cudnn,虚拟环境下的安装看我另一篇文章
在Ubuntu系统的conda虚拟环境下安装cuda和cudnn-CSDN博客
安装完cuda和cudnn后,进入mindspore官网
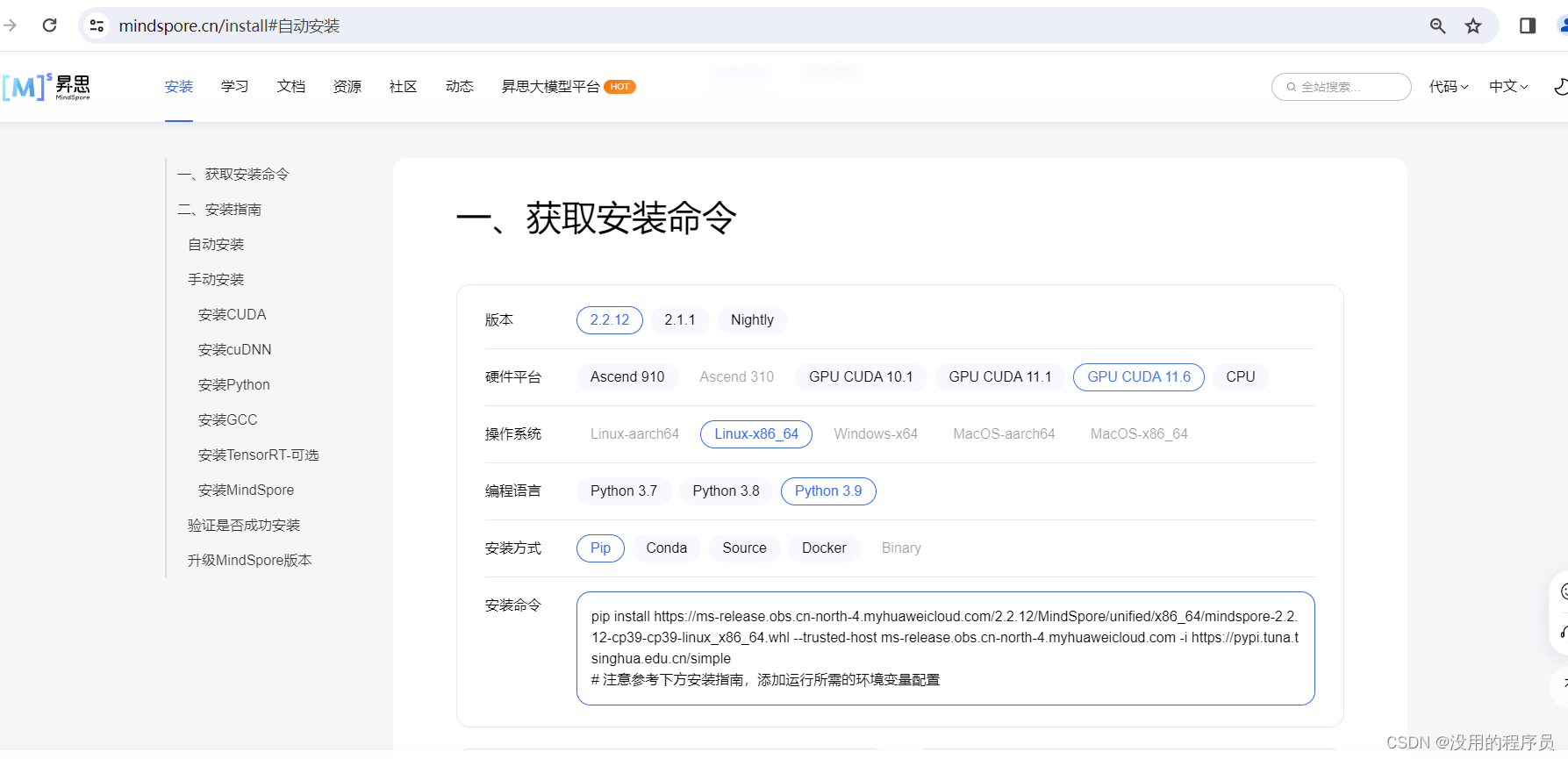
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.2.12/MindSpore/unified/x86_64/mindspore-2.2.12-cp39-cp39-linux_x86_64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple复制命令直接安装即可,这里不建议使用conda命令安装,我这边经常出现找不到镜像的情况,只要是切换到conda创建的环境下,使用pip安装只会安装到当前环境
2、minist数据集实验
官网教程里的代码是用jupyter写的,我把代码改了一下:
删了一部分,增加了指定gpu的代码
import mindspore
from mindspore import nn, value_and_grad
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
from mindspore import context
# 设置运行设备为GPU,device_id为0
context.set_context(device_target="GPU", device_id=1)
# Download data from open datasets
from download import download
''' 第一次运行时取消注释,下载数据集后加上注释即可,防止重复下载
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
'''
train_dataset = MnistDataset('MNIST_Data/train')
test_dataset = MnistDataset('MNIST_Data/test')
# 定义数据处理Pipline
def datapipe(dataset, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
# 归一化
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
# 28, 28, 1 --> channel, height, width 1, 28, 28
vision.HWC2CHW()
]
# uint8 --> int32
label_transform = transforms.TypeCast(mindspore.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
# 1, 28, 28 --> 64, 1, 28, 28
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset
train_dataset = datapipe(train_dataset, 64)
test_dataset = datapipe(test_dataset, 64)
# Define model
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()
# Instantiate loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
# 1. Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 2. Get gradient function
grad_fn = value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
def train(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
#loss = train_step(data, label)
#logits = model(data)
#loss = loss_fn(logits, label)
#grad_fn = value_and_grad(loss_fn(logits, label), None, optimizer.parameters)
#optimizer(grad_fn)
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
def test(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
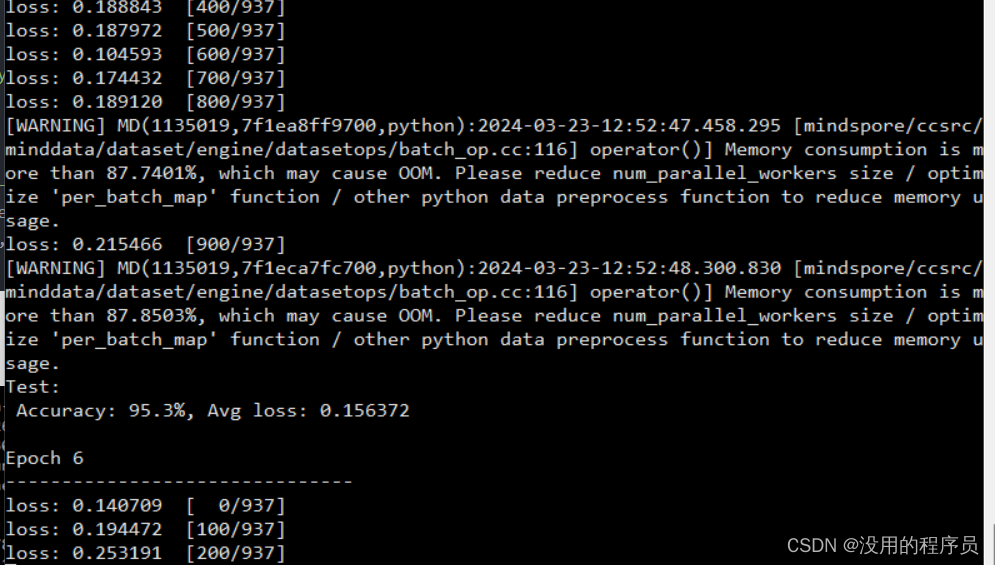
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
epochs = 100
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(model, train_dataset)
test(model, test_dataset, loss_fn)
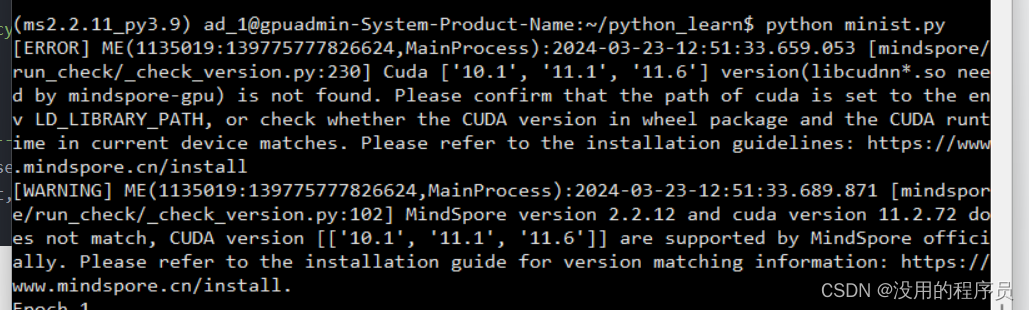
print("Done!")运行:我装的cuda的版本是11.8,稍微高了一点,但似乎不影响正常使用
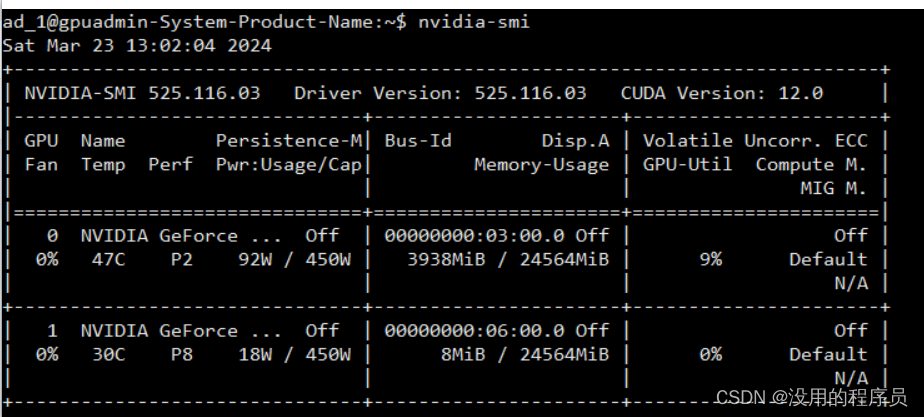
 没运行时显存占用:
没运行时显存占用:
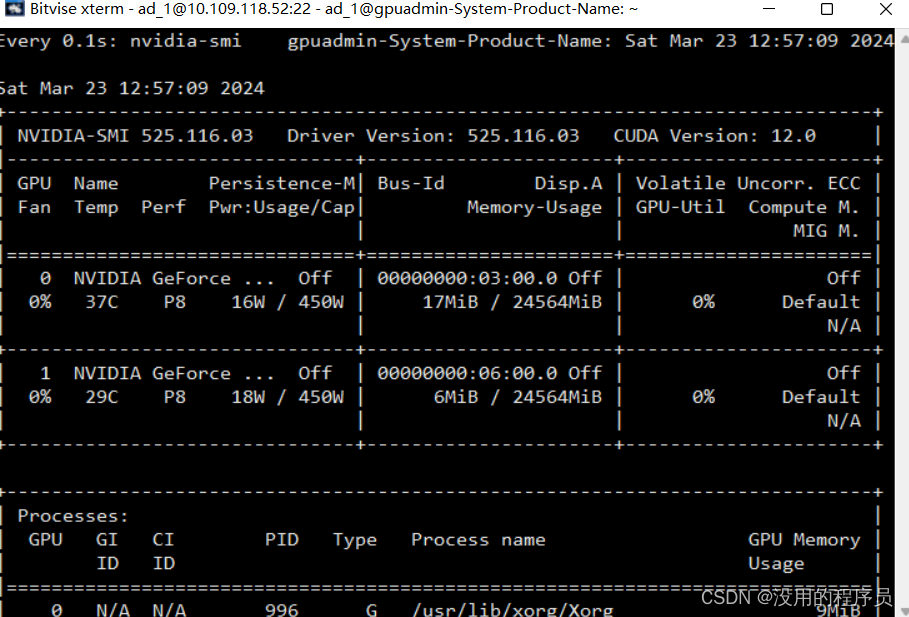
运行时显存占用:
使用nvidia-smi
使用gpustat

3、部分代码讲解
optimizer = nn.SGD(model.trainable_params(), 1e-2)# 1. Define forward function
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# 2. Get gradient function
grad_fn = value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True) for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
#loss = train_step(data, label)
#logits = model(data)
#loss = loss_fn(logits, label)
#grad_fn = value_and_grad(loss_fn(logits, label), None, optimizer.parameters)
#optimizer(grad_fn)
(loss, _), grads = grad_fn(data, label)
optimizer(grads)个人理解,主需要介绍的是mindspore中value_and_grad函数的用法,其中,如以value_and_grad函数中的第一个参数forward_fn,这里代表的应该是一个函数对象,这个函数可以是一个嵌套多次的函数,而需要求梯度的部分是optimizer.parameters中的部分,这也意味着,函数对象forward_fn中的参数是大于等于(包含)optimizer.parameters中的部分
还有就是反向传播的过程是需要知道输出和期望的差别,也就是损失,在pytorch里可以直接使用loss.back(),而在value_and_grad中,默认第一个参数forward_fn的返回值相当于loss,如果forward_fn有多个返回值,则需要在value_and_grad中把has_aux=True,这时,默认第一个返回值作为loss参与反向传播
如有问题请留言

















 3278
3278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









