







InfluxDB的基本操作
1、InfluxDB的安装与配置
2、InfluxDB基本操作
3、Springboot对接InfluxDB
4、InfluxDB小总结
5、telagraf+influxdb+grafana搭建监控系统
6、Grafana的基本使用
基础概念
- 与常见关系型数据库的对比
| 概念名称 | InfluxDb | 关系型数据库 |
|---|---|---|
| 数据库 | database | database |
| 表 | measurement | table |
| 行 | points | row |
| 列 | tag,field,timestamp | column |
- InfluxDB独有的概念
- Point:代表一行的数据,由时间戳(time)、数据(field)和标签(tags)组成
- tag sets: tags在InfluxDB中会按照字典序排序,不管是tag-key还是tag-value,只要不一致就分别属于两个key
- tag:标签,表名+tag一起作为数据库的索引是“key-value”的形式
- field name:InfluxDB支持一条数据插入多个fieldName。但实际存储中还是被当做多条数据存储
- timestamp: 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,以为了优化后续的查询操作
- Series 相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起
- retention policy: 存储策略,用于设置数据保留的时间,每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,之后用户可以自己设置,例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据
- Shard 在 InfluxDB 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file
-
TSM存储引擎组成
主要由几个部分组成: cache、wal、tsm file、compactor1)Cache:cache 相当于是 LSM Tree 中的 memtabl。插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中。
2)WAL:wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
3)TSM File:单个 tsm file 大小最大为 2GB,用于存放数据。
4)Compactor:compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。
主要进行两种操作,一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。
另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
常用命令
- 显示数据库
show databases
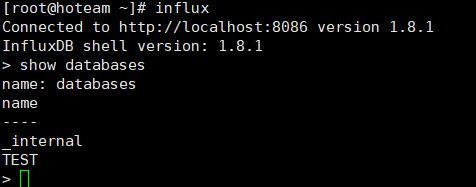
- 新建数据库
create database device
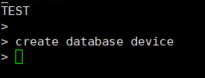
只有语句执行错误才会显示,所以不显示任何信息就标识任务执行成功了
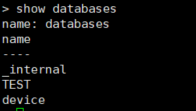
- 删除数据库
drop database test #区分大小写
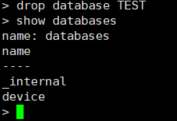
- 使用指定的数据库
use device
- 显示所有表
show measurements
- 新建表
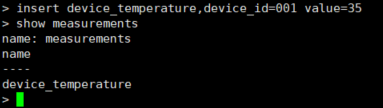
insert device_temperature,device_id=001 value=35
没有特定的建表语句所以插入时就会建表
其中device_temperature 是表名
device_id=001是索引tag
value=35是记录值field,记录值可以多个
添加数据时会自动写入时间戳,也可以自己指定时间戳
insert device_temperature,device_id=001 value=35 1435362189575692182
- 删除表
drop measurement device_temperature

- 数据保留策略
show retention policies on "db_name" #保留策略是定在数据库上的

- 创建数据库保留策略
create retention policy "rp_name" on "db_name" duration 3w replication 1 default
rp_name:保留策略名称
db_name:数据库名称
duration 3w: 3周,近3周之前的数据会被删除,还支持小时(h),天(d),星期(w),分钟(m),秒(s),为0的话表示永久保存
replication: 副本的个数,这里是1
default:是否是默认策略

- 修改数据库保留策略
alter retention policy "rp_name" on "db_name" duration 30d default

- 删除保留策略
drop retention policy "rp_name" on "db_name"

- 查询语句
- 数据查询
select * from device_temperature #查询此表所有数据
当然可以加limit限制查询的条数,可以按照time进行排序
select * from /.*/ LIMIT 1 #查询此数据库所有表的第一条记录
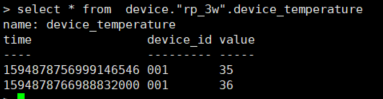
select * from device."rp_3w".device_temperature
delete from "device_temperature" #删除表所有数据,则表就不存在了
drop MEASUREMENT "device_temperature" #删除表(注意会把数据保留删除使用delete不会)
- 表信息查询
show measurements #查看表
show FIELD KEYS from measurement_name #查看字段key
show series from measurement_name #查看key数据
show tag keys from device_temperature #查看tag keys
show tag values from device_temperature with key=device_id #查看tag values 必须制定tag key

- 用户管理命令
SHOW USERS
CREATE USER test WITH PASSWORD '123456' #创建普通用户
CREATE USER test2 WITH PASSWORD '123456' WITH ALL PRIVILEGES #创建admin用户
REVOKE ALL PRIVILEGES FROM test2 #取消权限赋予
REVOKE READ ON mydb FROM test #取消test用户的读权限
SHOW GRANTS FOR test #展示test用户的权限
GRANT ALL ON mydb TO test #授予admin权限
GRANT READ ON mydb TO test #授权test在数据库中的读权限
- 查看数据存储文件
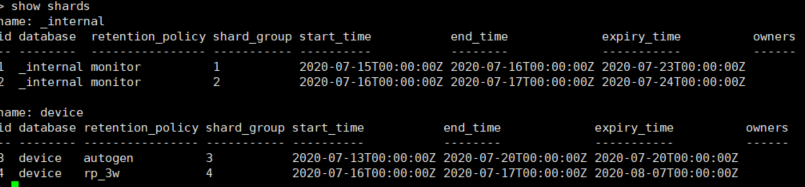
HTTP API
- 通过HTTP API操作数据库
curl -POST http://192.168.47.129:8086/query --data-urlencode "q=CREATE DATABASE mydb"

返回{“results”:[{“statement_id”:0}]}表示执行成功
curl -POST http://localhost:8086/query --data-urlencode "q=DROP DATABASE mydb"

query表明查询操作
query 后可增加?db=mydb指定数据库
q=DROP DATABASE mydb 是具体的语句
这里可以是create,drop,show,alter,grant,revoke,delete等关键词

- 通过HTTP API 添加数据
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000'

curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server02 value=0.67
cpu_load_short,host=server02,region=us-west value=0.55 1422568543702900257
cpu_load_short,direction=in,host=server01,region=us-west value=2.0 1422568543702900257'
- 通过HTTP API查询数据
curl -GET 'http://localhost:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT value FROM cpu_load_short WHERE region='us-west'"

(1)多条查询用“;”进行分割即可
(2)指定输出时间的格式 --data-urlencode “epoch=s” epoch=[h,m,s,ms,u,ns]
(3)指定查询条数 用chunk_size,–data-urlencode "chunk_size=200"表示查询200个point的数据

-
InfluxDB 的HTTP API响应
在使用HTTP API时,InfluxDB的响应主要有以下几个:
1)2xx:204代表no content,200代表InfluxDB可以接收请求但是没有完成请求。一般会在body体中带有出错信息。
2)4xx:InfluxDB不能解析请求。
3)5xx:系统出现错误。
客户端工具
InfluxDBStudio的下载地址
可以使用InfluxDBStudio 作为可视化管理工具
















 4783
4783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









