






模糊查询 - 通配符
_ 匹配单个字符
%匹配任何长度字符串
select name from employee
where name like 'A%' --获取以字母A开头的员工姓名(不区分大小写)
;
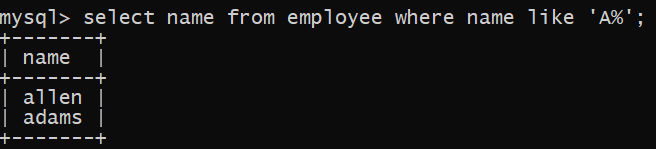
select name from employee
where name like '_m%' --查找名字第二个字母是m的员工姓名
;

select name from employeewhere name not like 'a%' --查找姓名不以A开头的员工
limit 5,2 --在筛选结果中,从第6个(5+1)开始展示,展示2个
;


group_concat()
count(*) vs count(column_name)
count(*) 统计所有记录,包括NULL值
count(column_name)统计指定列数据,不包括NULL值
sum(column_name) & avg(column_name) 统计指定列数据,也不包括NULL值

聚合函数针对无记录数据返回值比较
count(column_name) = 0
sum(column_name) & avg(column_name) = NULL

group_concat() - 可以理解为既展示分组信息,又展示分组内数据详情。通过group_concat() 对分组内数据进行拼接,从而使多行整合为一行数据
--按工种计算平均薪资,同时展示每个工种下对应的员工姓名
select job, group_concat(name), avg(sal)
from employee
group by job
;

--按部门进行分组,同时展示每个部门里员工姓名和对应薪资,按薪资倒序
select deptno, group_concat(name, ":", sal order by sal desc)
from employee
group by deptno;

where vs having
where:按数据表过滤数据,筛选条件字段必须出现在数据表中,但可以不出现在select字段中

报错原因:聚合字段avg(sal)本身没有出现在数据表中,是通过计算得到的新列,而where的执行顺序在分组语句group by之前,因此无法获取该新增字段,报错。
having:按分组过滤数据,筛选条件字段不一定出现在数据表中,但必须出现在select字段中
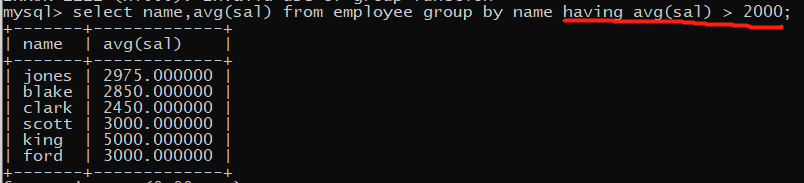
正确原因:having对分组后结果进行筛选,即执行顺序在group by之后,此时虚拟表中已经存在新增列avg(sal),因此having可以获取
多表关联 - 业务的完整数据可能根据其维度而分散在多个表
多表设计
通过ID关联:一般每一行数据我们会设置一个ID号,并把它设为主键。主键既是唯一识别表中每一行记录的字段,也将表中记录和其他表中数据进行关联。
通过外键关联:外键的主要作用在于保持表间数据的一致性。例如user_name是表A中的主键,但也存在于salary表中,那么对于salary表,user_name字段就是外键,它将表A和表salary关联起来。外键通过 FOREIGN KEY来指定
create table employee(
id int not null primary key auto_increment,
user_name varchar(20) not null,
......
NO ACTION `fk` FOREIGN KEY(`user_name`) REFERENCES salary(`user_name`) ON DELETE SET NULL ON UPDATE SET NULL
--外键模式:
--1)cascade 当父表中数据进行更新或删除时,同步字表匹配记录;
--2)no action:如果字表中有匹配记录,不允许父表进行更改删除操作;
--3)restrict:同上
--4)set null:在父表中进行更新删除操作时,将字表匹配数据设为NULL(外键不能为null)
);
表连接操作
并集:union vs union all
二者都是将从N张表(N>=2)中的数据整合到一个结果中(联合查询),因此union/union all 前后衔接的是“select”语句,并且要求所有子表被提取的字段及顺序一致,否则会报错。
【区别】
union:含有去重功能,会将两个子数据集中重复的记录删掉后拼接
union all:无论是否存在重复,直接将两个子数据集中的记录进行拼接,因而效率高于union操作

当对UNION子数据集的SQL进行排序操作时:1)使用括号;2)order by + limit 联合使用,否则无排序效果
笛卡尔积 & join/left join/right join/cross join
表连接JOIN的原理:笛卡尔积,我的理解是将两个表中的数据进行完全映射。表连接就是在笛卡尔积的基础上,通过限定匹配字段等信息,获得笛卡尔积的数据子集。

cross join VS full outer join
full outer join 如上图全红图例所示,返回的是按照限定条件匹配的表A表B并集,对于未匹配到的数据设为NULL
cross join:将表A和表B的所有数据做笛卡尔积,返回N*M个组合结果
子查询 - select查询语句作为另一个select查询的条件
子查询是表连接的一种。当两张表数据量都比较大的时候,我们做JOIN连接可能会非常消耗资源、时间。此时,可以通过子查询仅提取出表中的一部分数据,当做主要查询结果的限制条件子集。
1. from子句:子查询一般返回“临时表”(多行多列数据)
2. where子句:子查询一般返回一维数据,例如某个值(单行单列)、某一列数据(多行单列)、某一行数据(单行多列)
--查询比Smith薪资高的员工信息
select *
from employee
where sal > (select sal from employee where name = 'smith') --子查询返回单个值:Smith的工资
;--查询工资和职位和Smith一样的员工信息
select *
from employee
where (job, sal) = (select job, sal from employee where name = 'smith') --子查询返回一行数据:smith 职位 工资;
-- 子查询返回一列数据:in, not in, any, all, exists, not exists
--1. in & not in: 查询条件位于或不位于子查询结果集中,只能返回单个字段对应的数据(值或列)
--查询所有员工部门编号
select *
from employee
where deptno in (select deptno from dept)
;--2. any & all:查询条件满足子查询结果集中任意一条或全部数据
--查询工资不低于职位是manager的员工姓名的工资
select name, sal
from employee
where salary > any(select sal from employee where job = 'manager') -- 不低于
--where salary < any(select sal from employee where job = 'manager') --不高于
--where salary = any(select sal from employee where job = 'manager') --工资和任一manager职位一样 = in
;--查询工资高于职位是manager的员工姓名和工资
select name, sal
from employee
where sal > all(select sal from employee where job = 'manager') --高于
--where sal < all(select sal from employee where job = 'manager') --低于
;--3. exists & not exists: 当子查询有返回数据时(>=1)则exists置为TRUE,否则置为FALSE;当子查询无返回数据时,not exists置为TRUE,否则置为FALSE
--查询部门表中的部门编号、员工姓名,如果某部门没有员工,则只显示该部门
select *
from dept
where not exists(select * from employee where deptno = dept.deptno)
;
--如果dept.deptno = deptno 没有匹配到,not exists = TRUE,返回dept表内所有信息
MySQL 8.0 Reference Manual Subqueries with Exists or Not exists

where vs on
1. left join & right join
left join:左表的全部记录被查询显示,on限制条件对左表无用,但对右表有限制作用;若要进一步筛选,需要通过where达成;
right join:右表的全部记录被查询显示,on限制条件对右表无用,但对左表有限制作用;若要进一步筛选,需要通过where达成;
即on限制条件对主表不起左右,仅限制附表的数据提取;若要限制主表的数据提取,需要使用where限定。
示例:
-- 结果返回:student表中,即使是性别为女的学生信息,也全部返回
select a.*, b.*
from student a
left join sc b
on a.sid = b.sid
and a.ssex = '男'
;


2. inner join
on = where : 对于inner join来说,on限制条件均作用于两张表,执行结果等同于使用where。
示例:
select a.*, b.*
from student a
inner join sc b
on a.sid = b.sid
and a.ssex = '男'
;select a.*, b.*
from student a
inner join sc b
on a.sid = b.sid
where a.ssex = '男'
;

















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









