






昨天菜鸟小白做了一个小软件——PDFtoWORD,作用就是将pdf文件中的文字提取出来自动转化为可编辑的word类型。但是这个软件目前也只能将文件PDF中的文字提取出来,还无法提取图片。为了进一步完善这个小工具,菜鸟小白一下班就看有没有什么方法能够将pdf中的图片提取出来。
功夫不负有心人,还真让菜鸟小白找到了方法。使用fitz库能够很好的提取出图片,然后通过python-docx库将提取出来的图片拷贝到word中去。整体的过程如下:
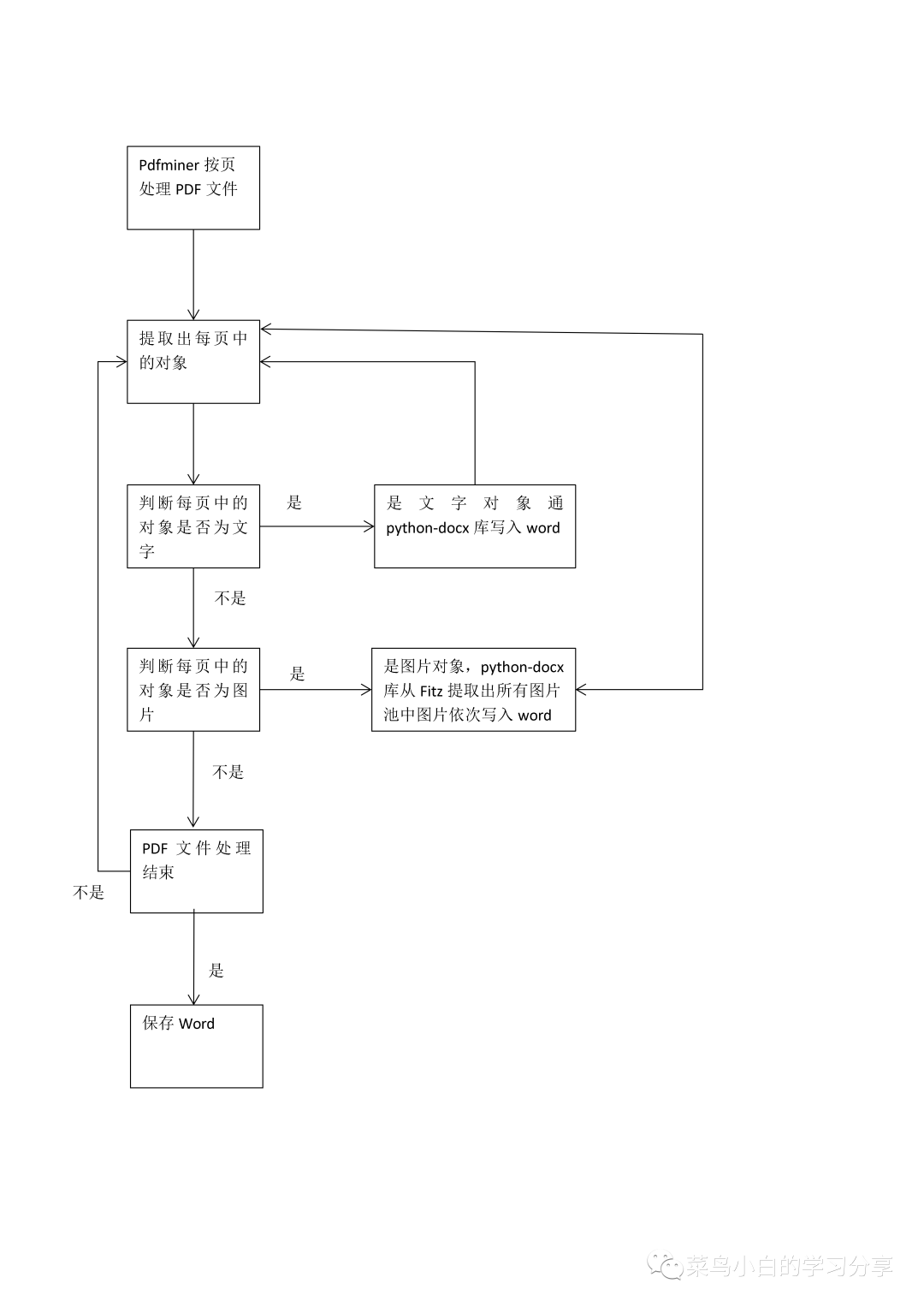
PDF文件中提取文字
接下来我们就来看看代码,通过pdfminer处理PDF文件还是昨天的代码,有不理解的地方可以直接参考昨天的分享。
PDF文件中提取图片
我们先看看如何将PDF中的图片从PDF中提取出来存放到资源池中。
# -*- coding:utf-8 -*-
#author:菜鸟小白的学习分享
import fitz
import time
import re
import os
def pdf2pic(path, pic_path):
t0 = time.clock() # 生成图片初始时间
checkXO = r"/Type(?= */XObject)" # 使用正则表达式来查找图片
checkIM = r"/Subtype(?= */Image)"
doc = fitz.open(path) # 打开pdf文件
imgcount = 0 # 图片计数
lenXREF = doc._getXrefLength() # 获取对象数量长度
# 打印PDF的信息
print("文件名:{}, 页数: {}, 对象: {}".format(path, len(doc), lenXREF - 1))
# 遍历每一个对象
for i in range(1, lenXREF):
text = doc._getXrefString(i) # 定义对象字符串
isXObject = re.search(checkXO, text) # 使用正则表达式查看是否是对象
isImage = re.search(checkIM, text) # 使用正则表达式查看是否是图片
if not isXObject or not isImage: # 如果不是对象也不是图片,则continue
continue
imgcount += 1
pix = fitz.Pixmap(doc, i) # 生成图像对象
new_name = "图片{}.png".format(imgcount) # 生成图片的名称
if pix.n < 5: # 如果pix.n<5,可以直接存为PNG
pix.writePNG(os.path.join(pic_path, new_name))
else: # 否则先转换CMYK
pix0 = fitz.Pixmap(fitz.csRGB, pix)
pix0.writePNG(os.path.join(pic_path, new_name))
pix0 = None
pix = None # 释放资源
t1 = time.clock() # 图片完成时间
print("运行时间:{}s".format(t1 - t0))
print("提取了{}张图片".format(imgcount))
if __name__ == '__main__':
pic_path = r'.\图片'
path = "oracle数据库安装.pdf"
# 创建保存图片的文件夹
if os.path.exists(pic_path):
print("文件夹已存在,不必重新创建!")
pass
else:
os.mkdir(pic_path)
pdf2pic(path, pic_path)
这个是一个可以独立运行的程序,作用就是将pdf中的图片存放在图片文件夹下面。在运行之前我们首先要使用pip install pymupdf库,库中包含了我们需要使用的fitz库。

将图片写入word文档
为了大致保证图片粘贴的位置和PDF中的位置一致,我们需要在昨天程序的基础上修改一下对每一页PDF文件的处理,对每一页的对象进行判断,若是文字则直接拷贝到word中,若是图片则按照pdf中的顺序依次拷贝到word中。代码如下:
# 循环遍历列表,每次处理一个page内容
# doc.get_pages()获取page列表
for page in doc.get_pages():
interpreter.process_page(page)
# 接收该页面的LTPage对象
layout = device.get_result()
# 这里的layout是一个LTPage对象 里面存放着page解析出来的各种对象
# 一般包括LTTextBox,LTFigure,LTImage,LTTextBoxHorizontal等等一些对像
# 想要获取文本就得获取对象的text属性
for x in layout:
try:
if (isinstance(x, LTTextBoxHorizontal)):
# with open('%s' % (save_path), 'a') as f:
# result = x.get_text()
# print(result)
# f.write(result + "\n")
result = x.get_text()
print(result)
doc_object.add_paragraph(result)
elif (isinstance(x, LTFigure)):
cont +=1
images = r".\图片\图片{}.png".format(cont)
print(images)
# doc.add_paragraph(string) # 添加文字
doc_object.add_picture(images, width=Inches(7)) # 添加图, 设置宽度
except:
print("Failed")
最后我们再将主函数修改一下,进行调用
if __name__ == '__main__':
# 解析本地PDF文本,保存到本地TXT
file_name = input("请输入需要转化的文件名:")
doc_name = input("请输入转化后的文件名(支持TXT、doc、HTML格式):")
pic_path = r'.\图片'
flag = False
# 创建保存图片的文件夹
if os.path.exists(pic_path):
print("文件夹已存在,不必重新创建!")
pass
else:
os.mkdir(pic_path)
flag = True
PNGfromPDF.pdf2pic(file_name,pic_path)
doc = Document() # doc对象
# with open(r'菜鸟小白.pdf', 'rb') as pdf_html:
# parse(pdf_html, r'菜鸟小白的学习分享.doc')
with open(file_name, 'rb') as pdf_html:
parse(pdf_html, doc_name,doc)
doc.save(doc_name) # 保存路径
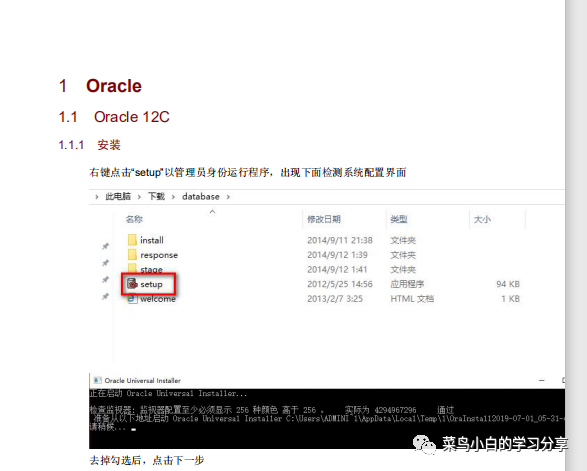
最终实现效果
原始PDF文件
转化后的word
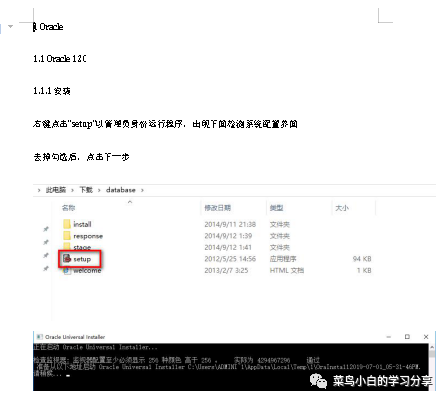
细心的小伙伴一定发现了一些问题,就是图片并没有完全按照PDF的顺序进行放置。这个我后来查阅资料和调试程序发现:pdfminer程序在处理每一页PDF时会将对象进行分类,返回的结果也是按照不同类型的对象分块的,这样就造成了我们还原的word中每一页都是所有的文字在前,图片在后的情况。
这个遗留就当做软件的一个bug遗留吧,版本先行发布,有需要获取最新转化工具的关注“菜鸟小白的学习分享”公众号,回复"PDFtoWORD_V1.1"获取吧。
好了,今天的分享就到这里,如果你也喜欢菜鸟小白的分享,就给菜鸟小白点击一个关注、在看、点赞+鸡腿吧。
晚安~
推荐阅读:
关注微信公众号——菜鸟小白的学习分享
妈妈再也不用担心我找不到路了

一个人的学习孤单
一群人的学习幸福
点亮小花
让更多人督促我们学习成长
















 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











