






 本文详述了在Linux环境中搭建伪分布式Hadoop系统,包括JDK和Hadoop的部署、环境变量配置、Hadoop配置文件的修改、WordCount示例的运行,以及输出结果的查看。
本文详述了在Linux环境中搭建伪分布式Hadoop系统,包括JDK和Hadoop的部署、环境变量配置、Hadoop配置文件的修改、WordCount示例的运行,以及输出结果的查看。
文章目录
前言
在linux里面使用伪分布式的hadoop操作
1.制作 一个文件,里面包含10-20不同的或部分相同的单词。
2.使用wordcount方法实现单词出现频率统计。
在Linux环境下使用伪分布式Hadoop进行单词出现频率统计是一项常见的任务。Hadoop是一个开源的分布式计算框架,主要用于大规模数据的存储和处理。而在伪分布式环境下,我们可以在单台计算机上模拟出Hadoop的基本功能,以便学习、测试和开发分布式系统,而无需真正的多台物理计算机。
本文将介绍如何在Linux环境中完成以下两个任务:
- 制作一个包含10-20个不同或部分相同单词的文本文件。
- 使用Hadoop的WordCount方法实现对这些单词出现频率的统计。
通过这个实例,读者将了解到如何在伪分布式环境下配置和运行Hadoop,并利用其强大的分布式计算能力进行数据处理。
一、linux伪分布式是什么?
在Linux环境下,"伪分布式"是指在单台计算机上模拟分布式系统的运行方式。它通常用于学习、测试和开发分布式系统,而无需真正拥有多台物理计算机。
具体来说,伪分布式通常涉及以下几个方面:
-
单节点多组件: 在单台计算机上运行多个分布式系统组件,如Hadoop的NameNode、DataNode、ResourceManager、NodeManager等,或者Apache Spark的Master和Worker节点等。
-
模拟网络环境: 通过配置虚拟网络或者使用本地主机来模拟多台计算机之间的网络通信。在伪分布式环境中,这些模拟的网络通常是通过localhost或者本地IP地址实现的。
-
数据存储和处理: 数据通常会在本地文件系统上进行存储和处理,模拟分布式文件系统或者分布式存储系统的功能。在伪分布式环境中,这些数据通常被分割成多个部分,并在单台计算机上进行处理。
-
任务调度和管理: 通过模拟分布式任务调度和管理系统,如YARN(Hadoop的资源管理器)或者Mesos,来管理计算机资源和任务分配。
总的来说,伪分布式提供了一种简便的方式来学习和测试分布式系统的各个方面,而无需投入大量的物理资源和设置复杂的网络环境。然而,它也有其局限性,因为所有的组件都运行在同一台计算机上,所以可能无法完全模拟出真实的分布式系统的行为和性能。
二、实现过程
实验过程中需要把jdk-8u191-linux-x64.tar.gz和hadoop-2.8.5.tar.gz上传到linux目录下,如下图:
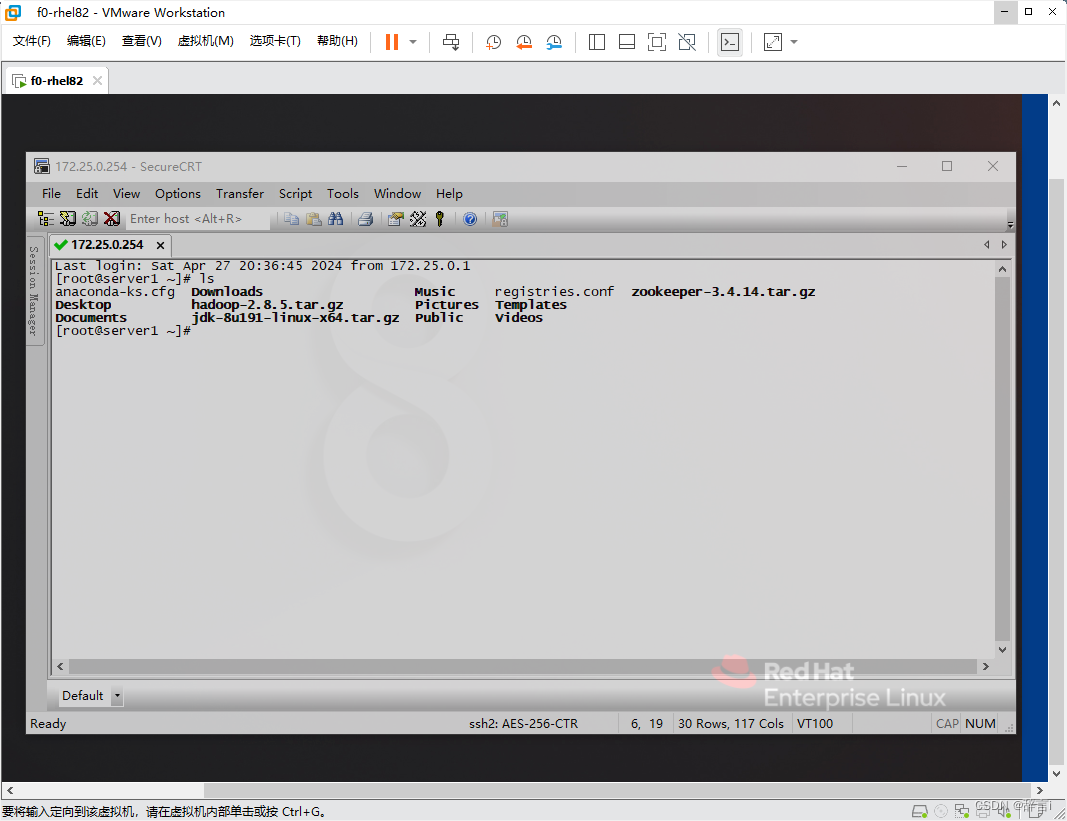
逐步分析并详细说明每个步骤:
JDK部署
-
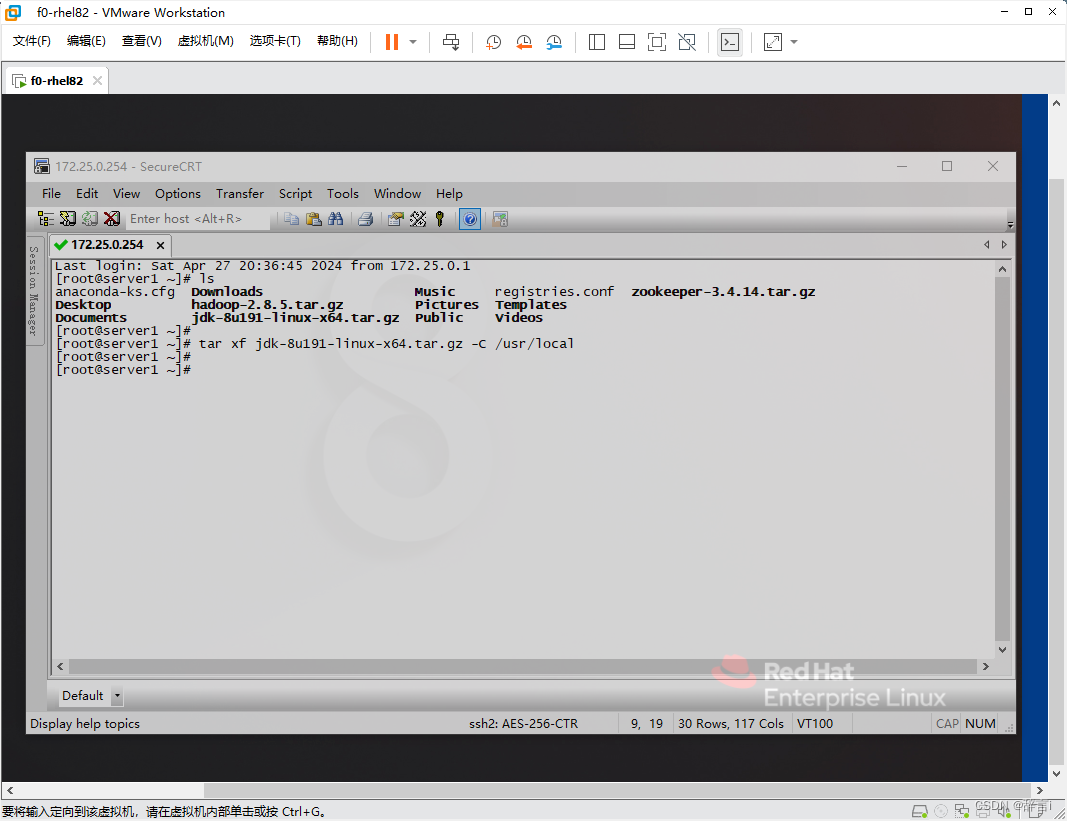
解压JDK:
- 使用
tar命令解压jdk-8u191-linux-x64.tar.gz文件到/usr/local目录:tar xf jdk-8u191-linux-x64.tar.gz -C /usr/local
- 使用
-
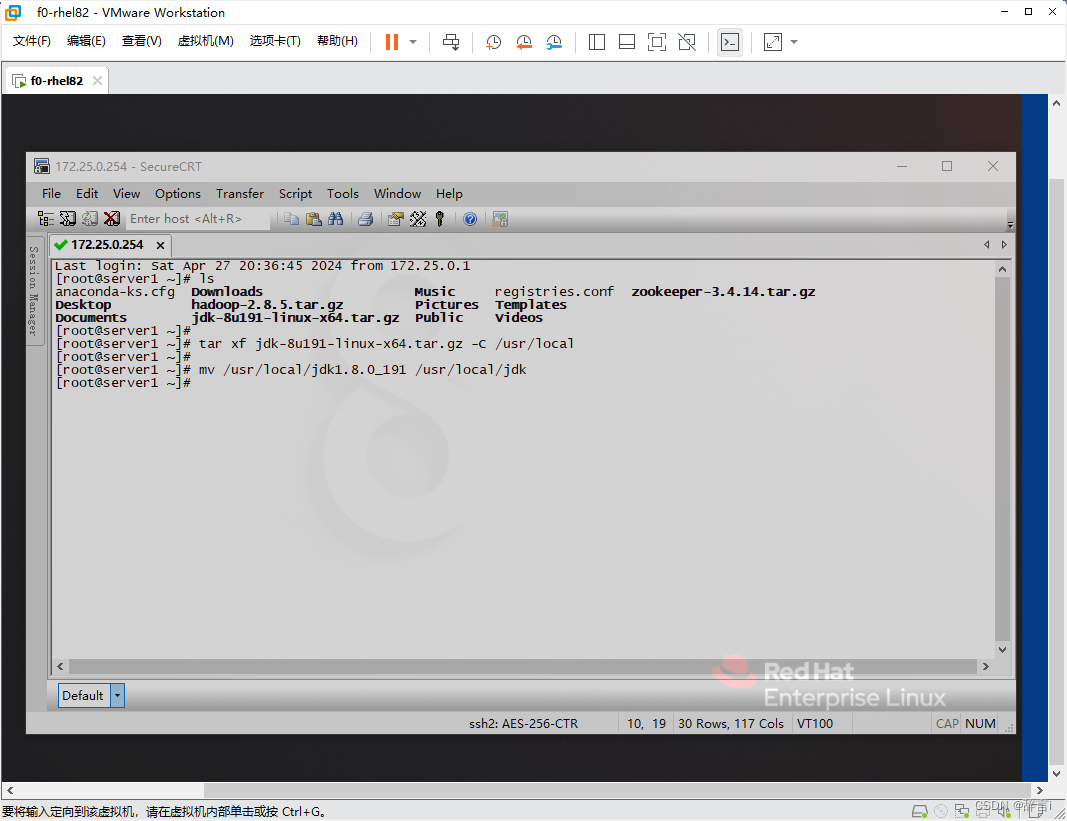
修改目录名称:
- 将解压后的 JDK 目录重命名为
/usr/local/jdk:mv /usr/local/jdk1.8.0_191 /usr/local/jdk
- 将解压后的 JDK 目录重命名为
Hadoop部署
-
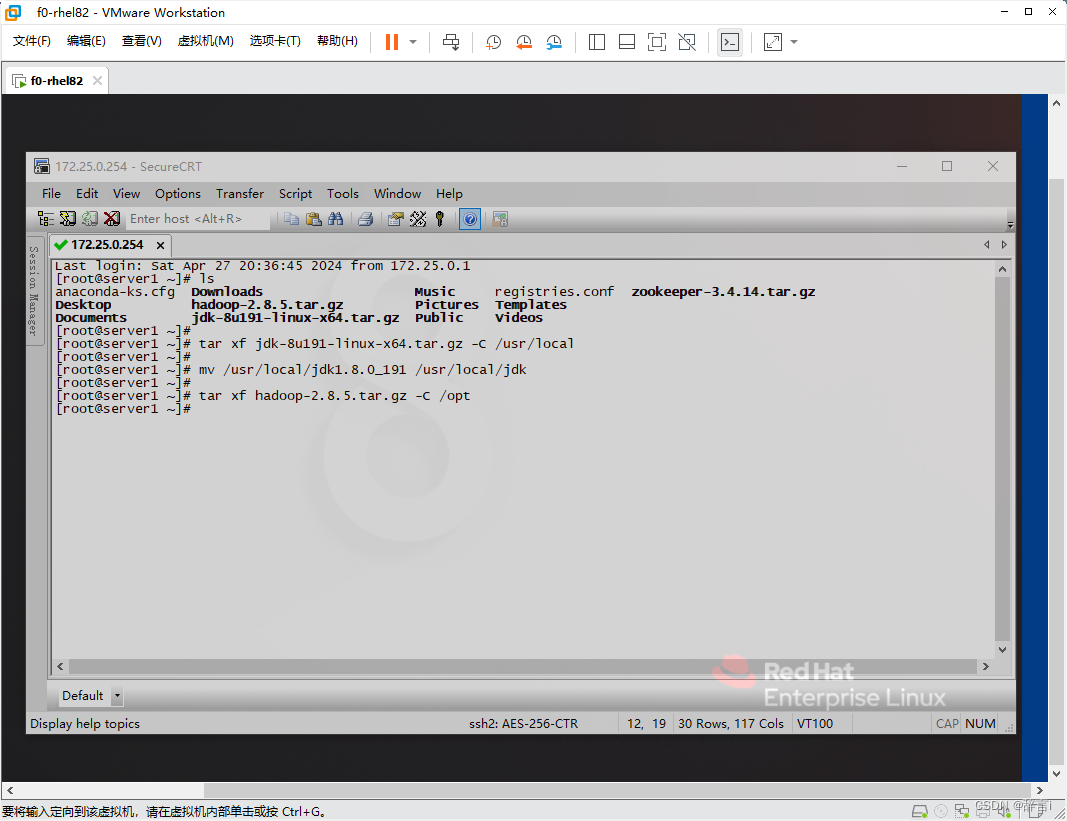
解压Hadoop:
- 使用
tar命令解压hadoop-2.8.5.tar.gz文件到/opt目录:tar xf hadoop-2.8.5.tar.gz -C /opt
- 使用
-
修改目录名称:
- 将解压后的 Hadoop 目录重命名为
/opt/hadoop:mv /opt/hadoop-2.8.5 /opt/hadoop

- 将解压后的 Hadoop 目录重命名为
Linux系统环境变量配置
-
编辑profile文件:
- 使用
vim编辑器打开/etc/profile文件:vim /etc/profile 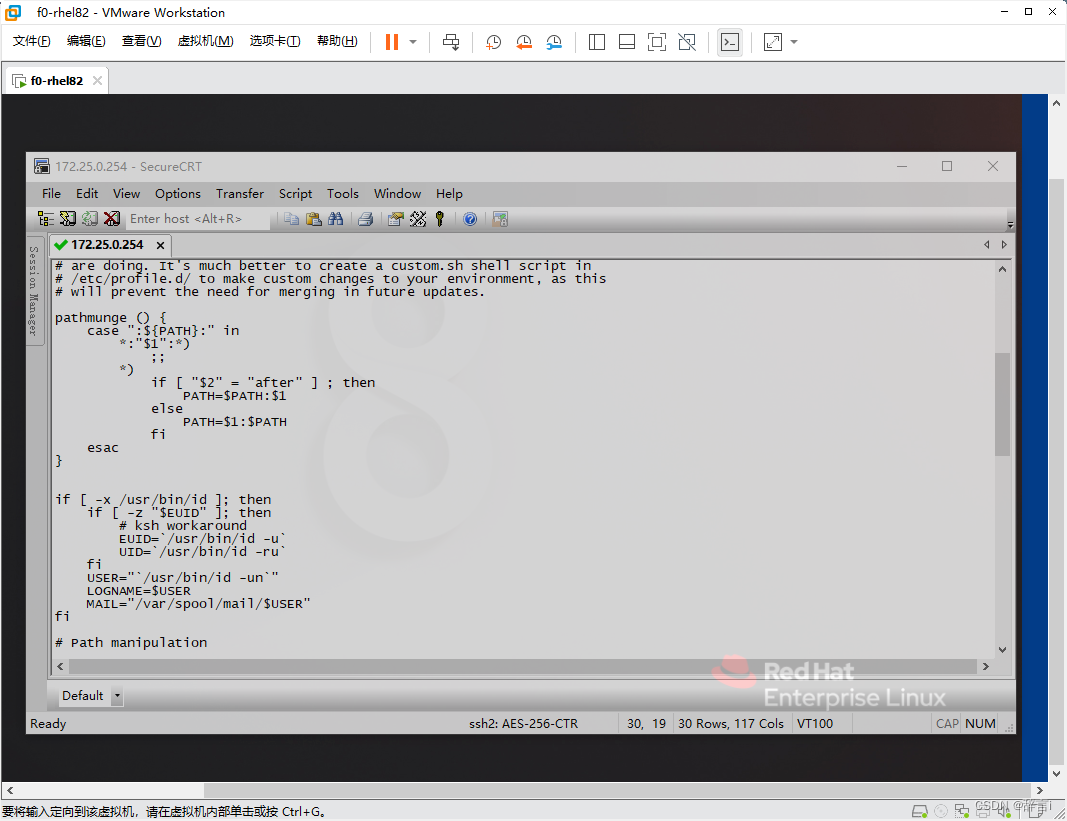
- 使用
-
添加环境变量:
- 在文件末尾添加以下内容:
export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/opt/hadoop export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
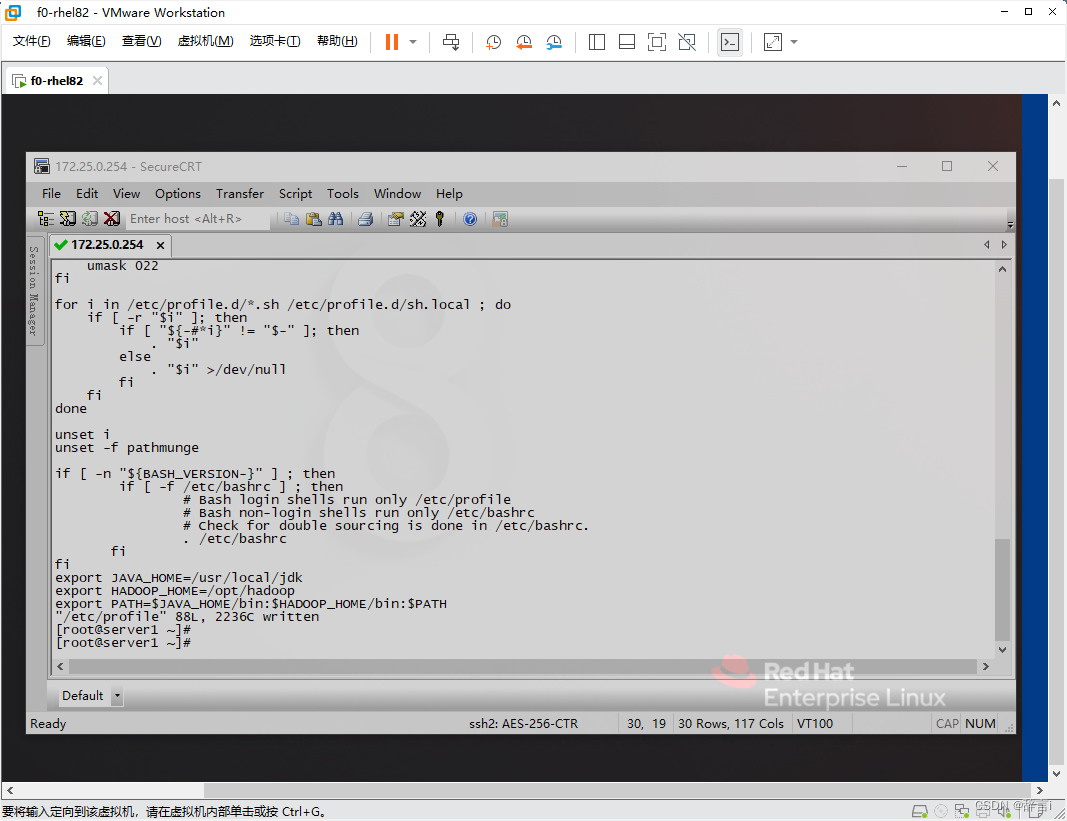
- 在文件末尾添加以下内容:
-
使配置生效:
- 运行
source命令使配置生效:source /etc/profile
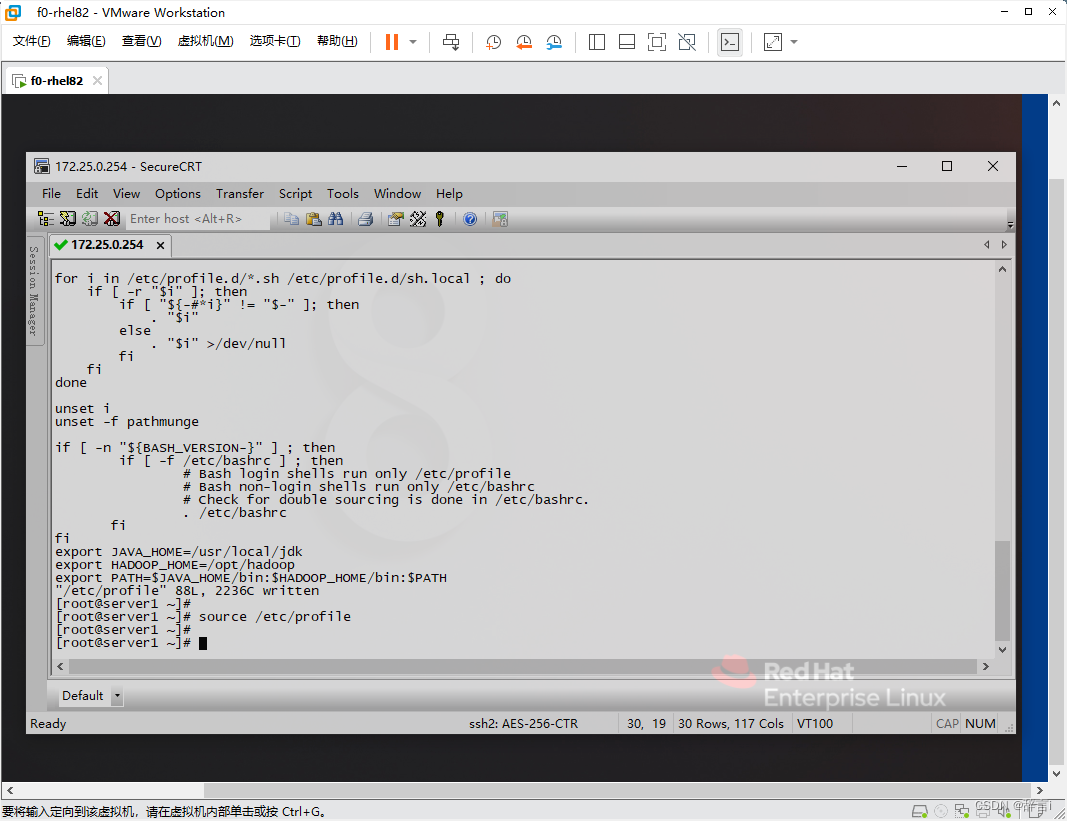
- 运行
修改Hadoop配置文件
-
进入Hadoop配置目录:
- 使用
cd命令进入/opt/hadoop/etc/hadoop目录:cd /opt/hadoop/etc/hadoop
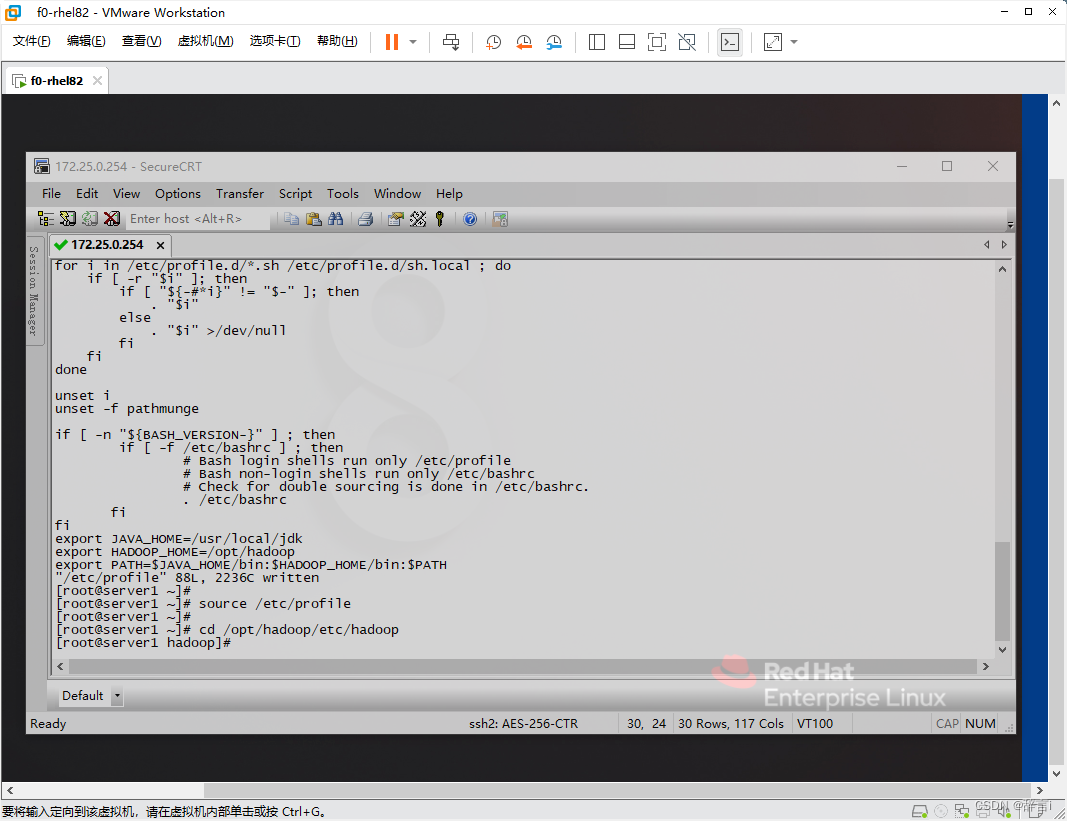
- 使用
-
修改环境变量:
- 使用
vim编辑器修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JAVA_HOME参数。
- 使用
使用 vim 编辑器修改hadoop-env.sh 文件:vim hadoop-env.sh
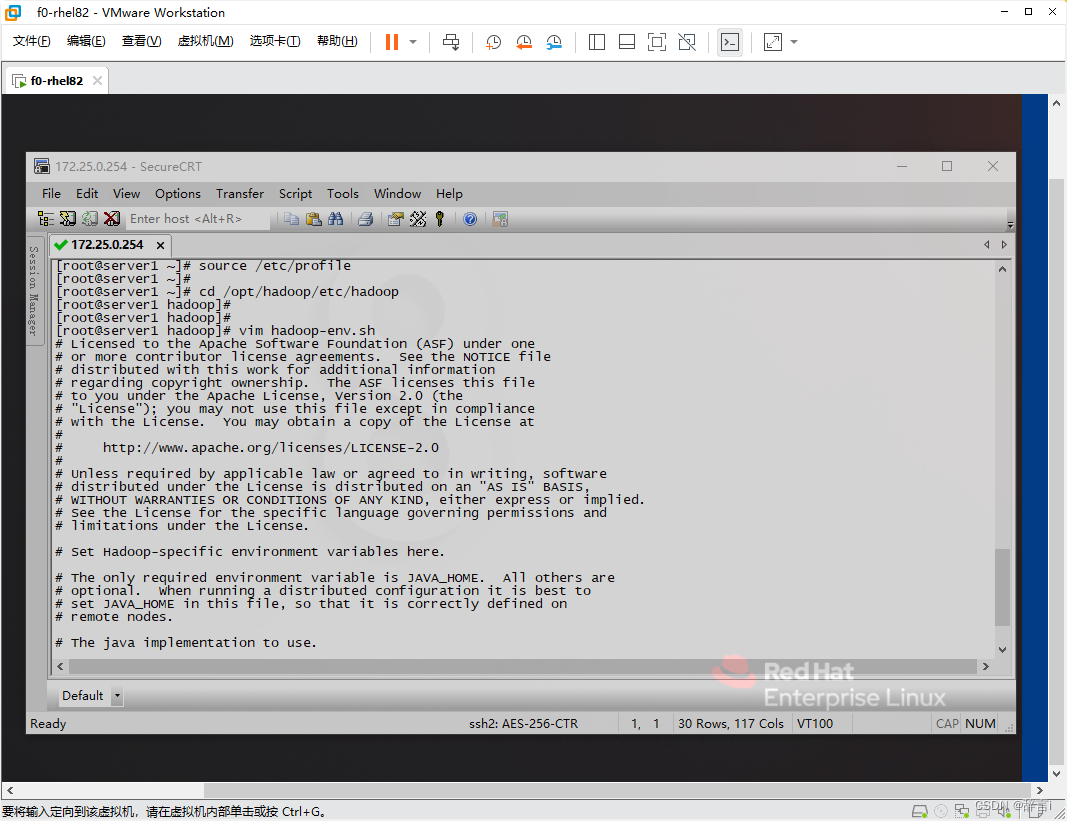
在 hadoop-env.sh 文件中添加以下内容:
export JAVA_HOME="/usr/local/jdk"
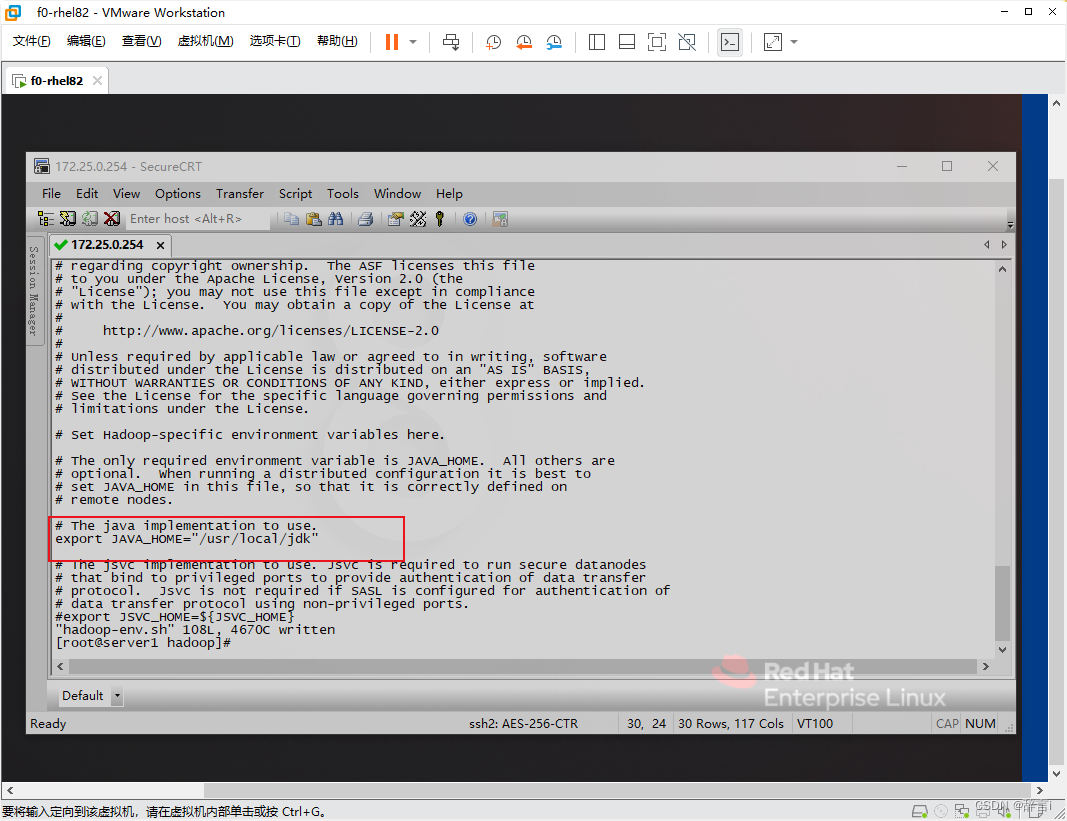
使用 vim 编辑器修改mapred-env.sh 文件:vim mapred-env.sh
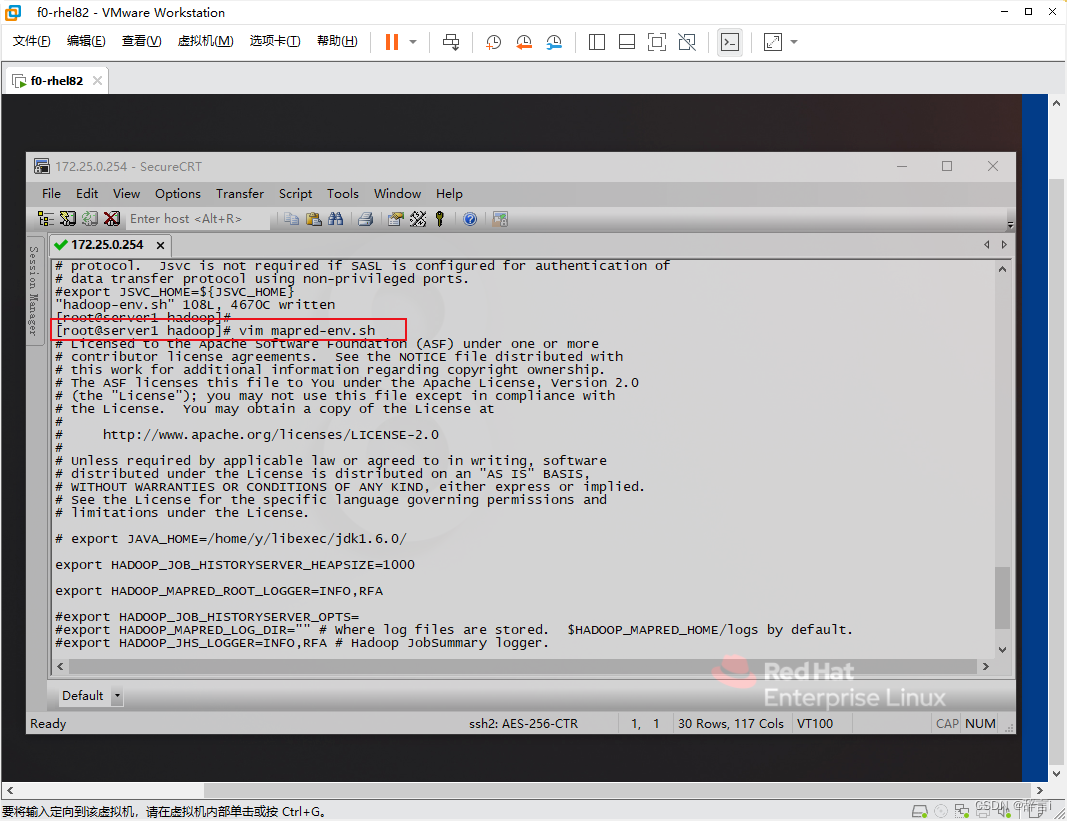
在 mapred-env.sh 文件中添加以下内容:
export JAVA_HOME="/usr/local/jdk"
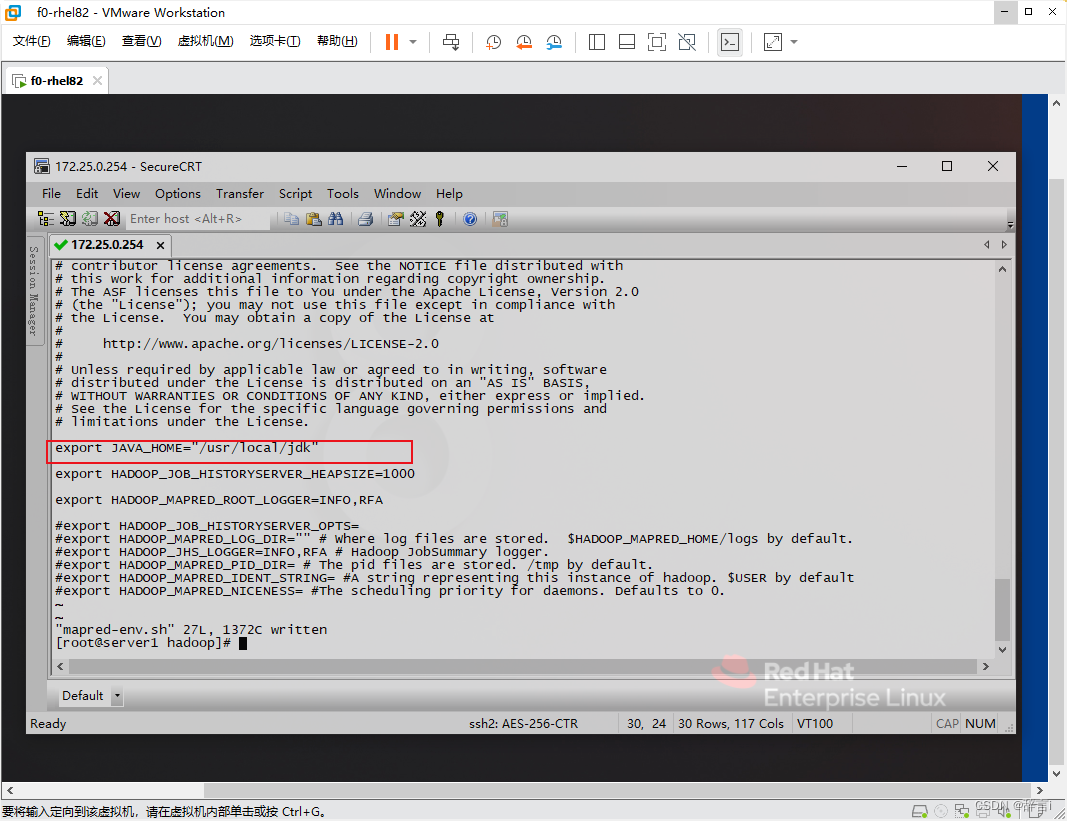
使用 vim 编辑器修改yarn-env.sh 文件:vim yarn-env.sh
在 yarn-env.sh 文件中添加以下内容:
export JAVA_HOME="/usr/local/jdk"
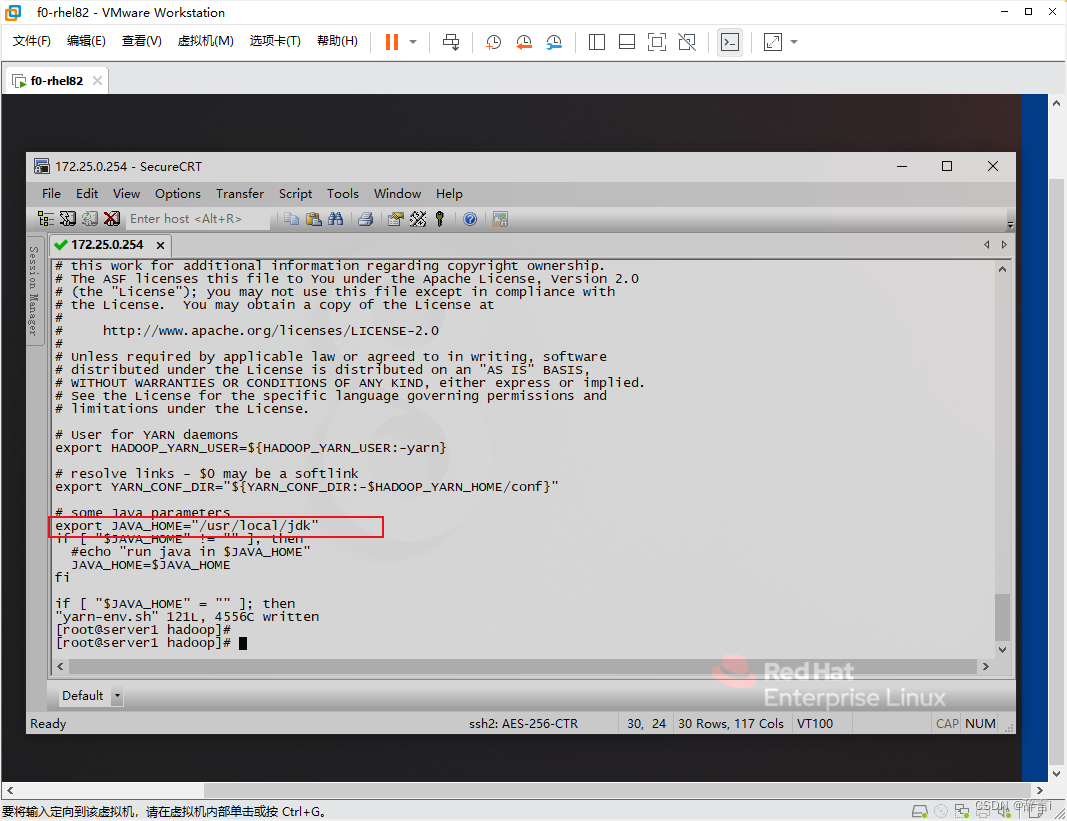
这些修改将确保 Hadoop 各个组件能够正确找到 Java 环境。
配置core-site.xml
-
编辑core-site.xml:
- 使用
vim编辑器打开core-site.xml文件:vim core-site.xml 
- 使用
-
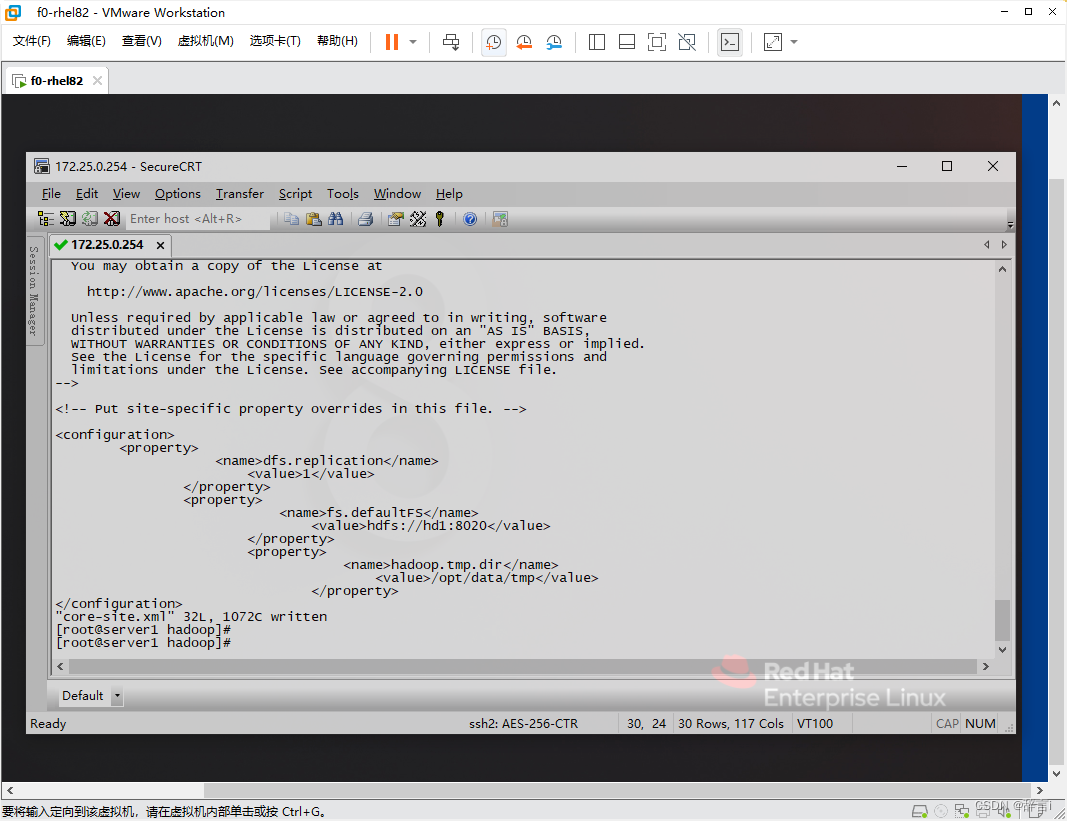
添加配置:
- 添加以下属性:
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hd1:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/tmp</value> </property>
- 添加以下属性:
配置hdfs-site.xml
-
编辑hdfs-site.xml:
- 使用
vim编辑器打开hdfs-site.xml文件:vim hdfs-site.xml 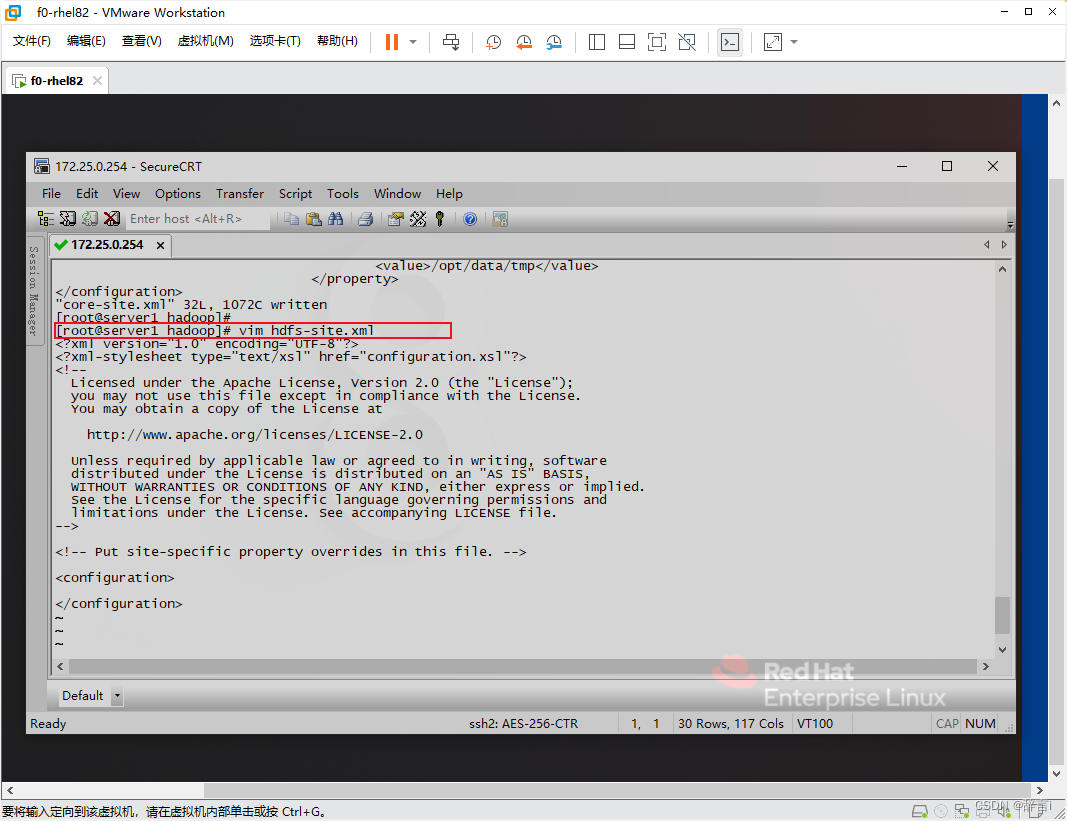
- 使用
-
添加配置:
- 添加以下属性:
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/tmp</value> </property>
- 添加以下属性:
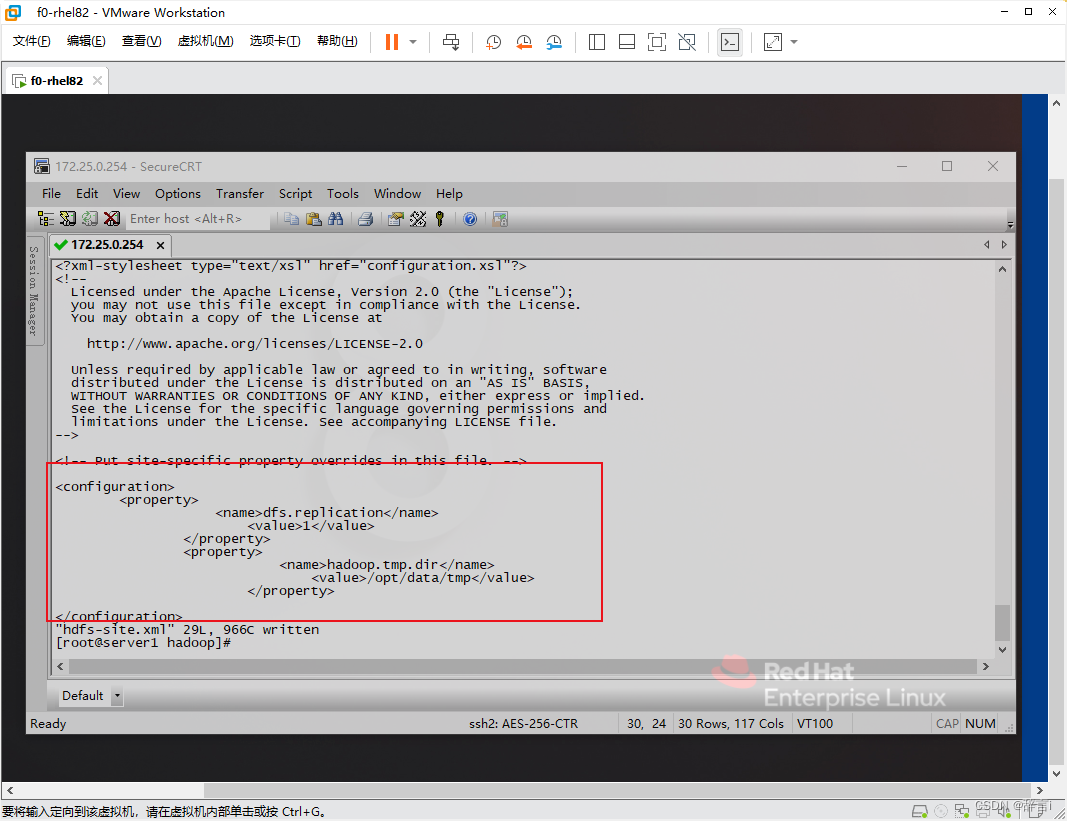
配置hosts文件
-
编辑hosts文件:
- 使用
vim编辑器打开/etc/hosts文件:vim /etc/hosts 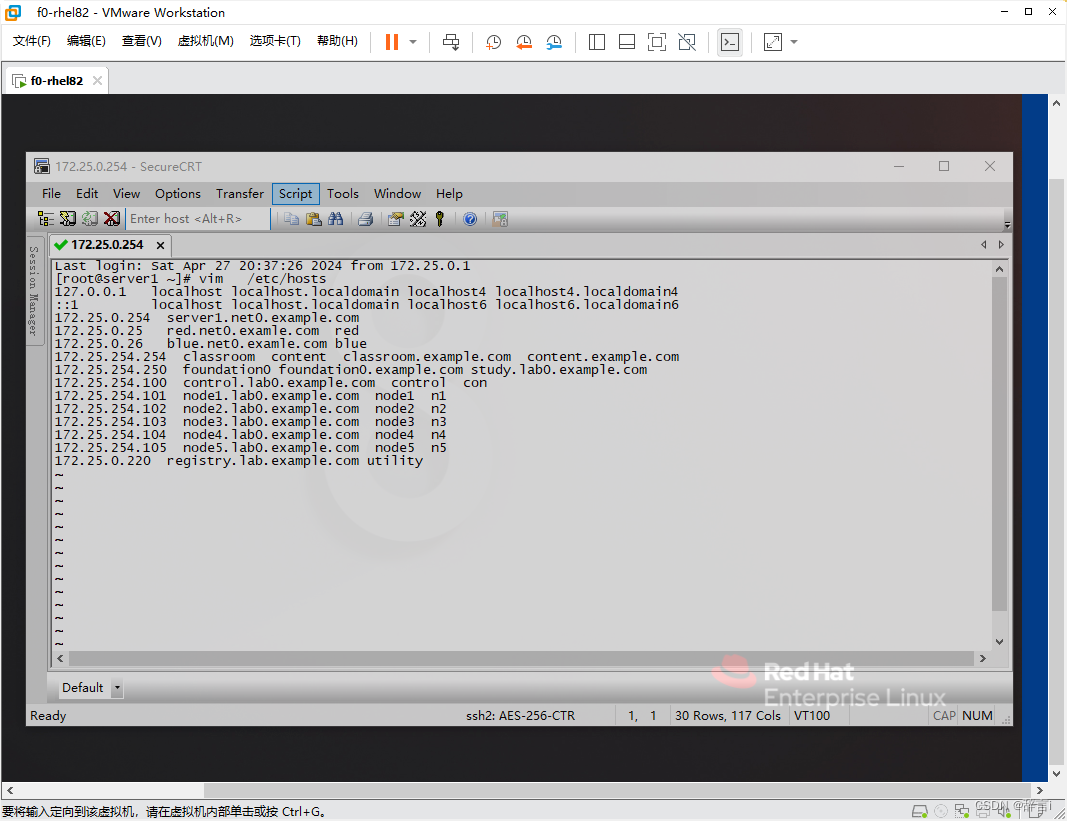
- 使用
-
添加IP地址和主机名映射:
- 在文件中添加
172.25.0.254 hd1。
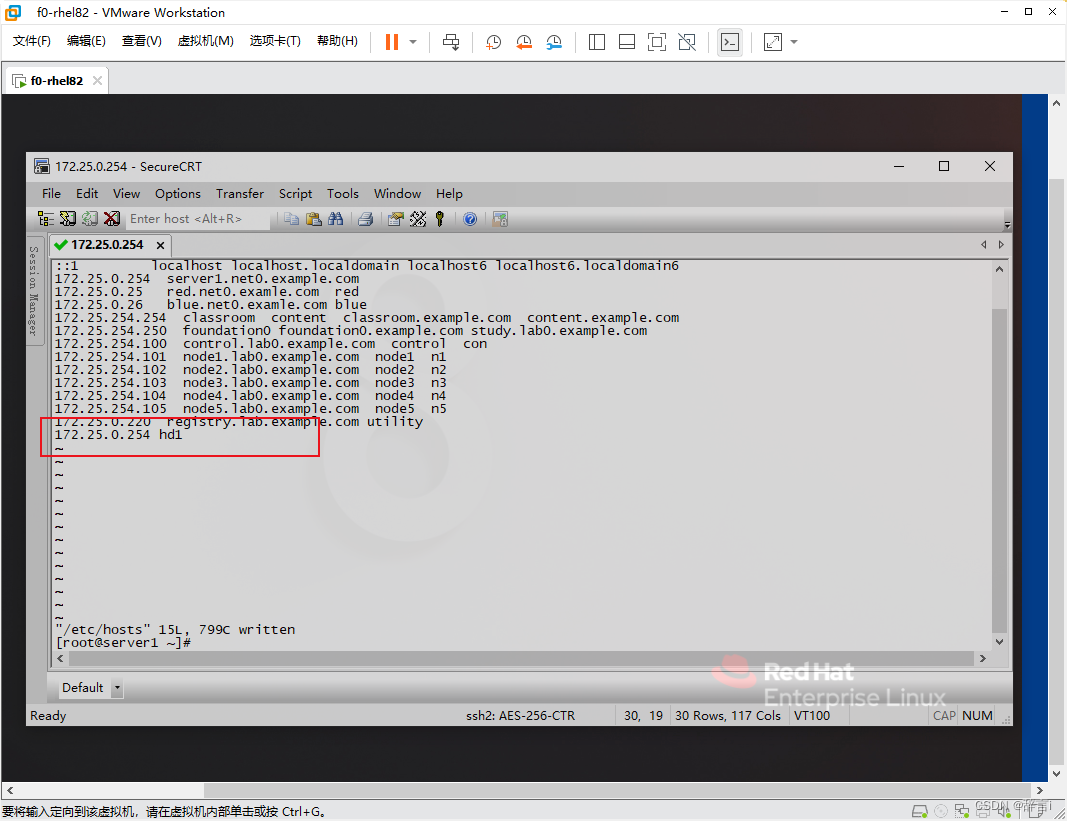
- 在文件中添加
重新格式化HDFS
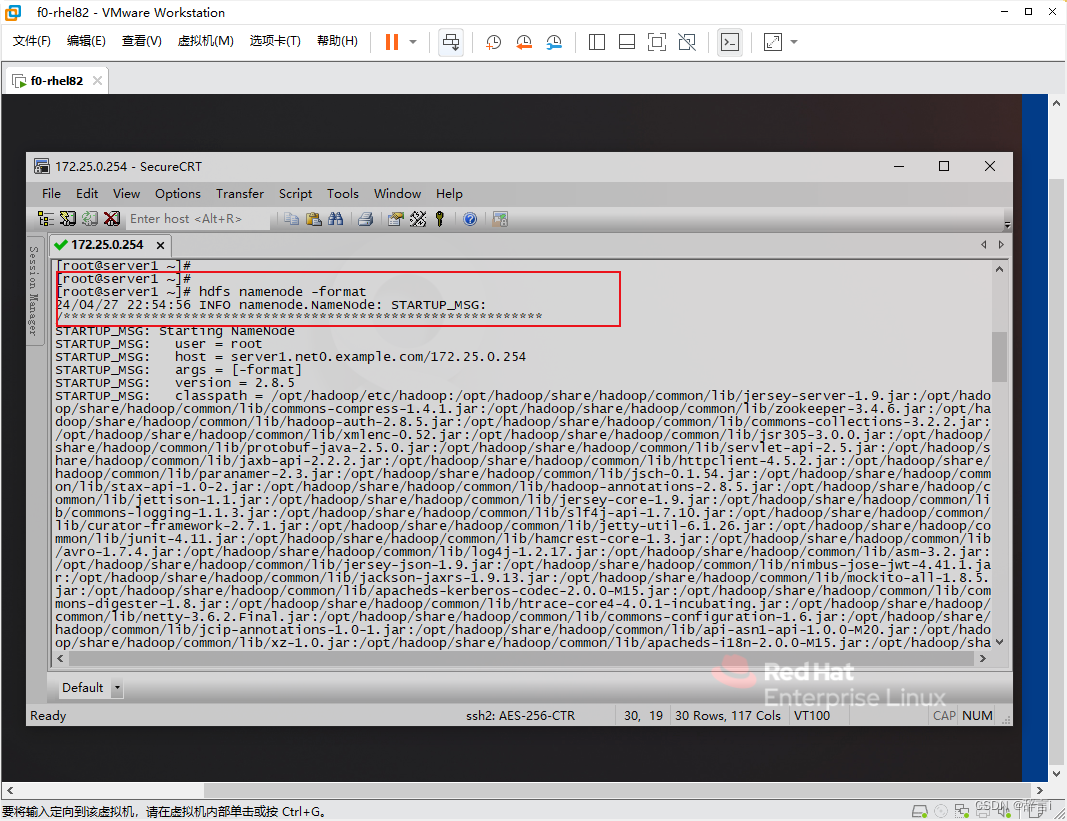
- 运行
hdfs namenode -format命令重新格式化 HDFS 以应用更改。
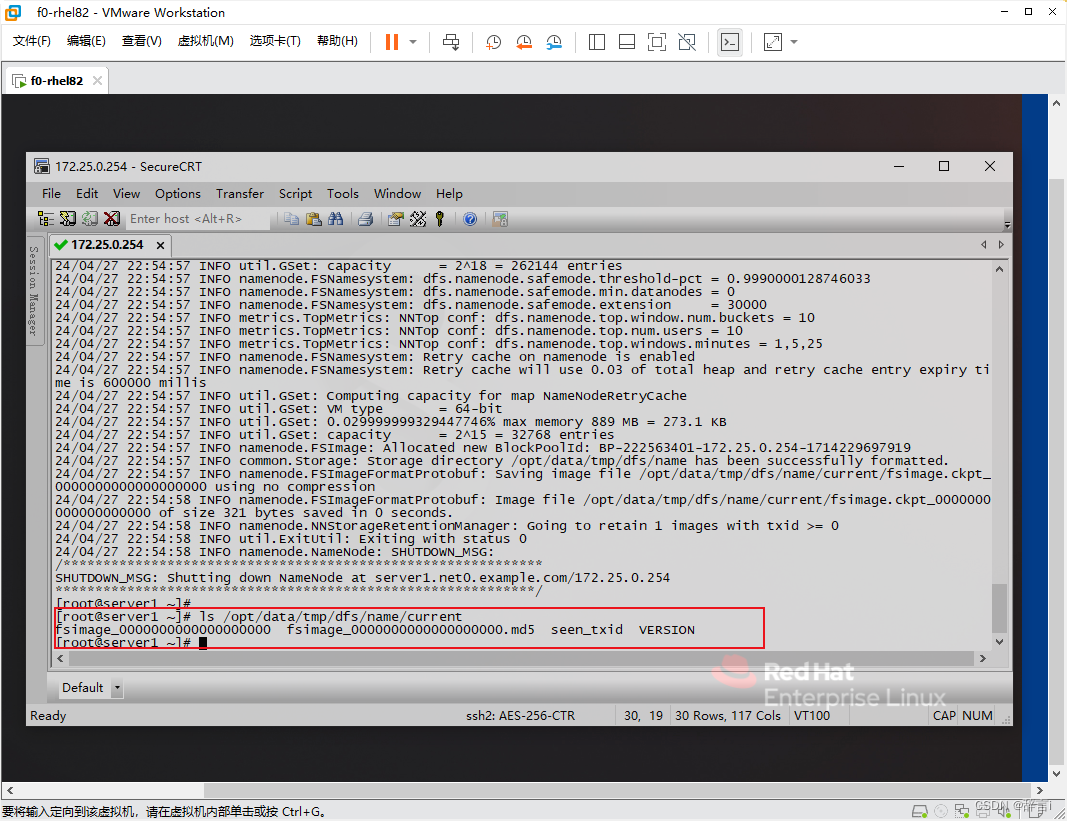
查看hdfs临时目录
使用 ls查看hdfs临时目录:ls /opt/data/tmp/dfs/name/current
配置环境变量
-
编辑profile文件:
- 使用
vim编辑器打开/etc/profile文件:vim /etc/profile 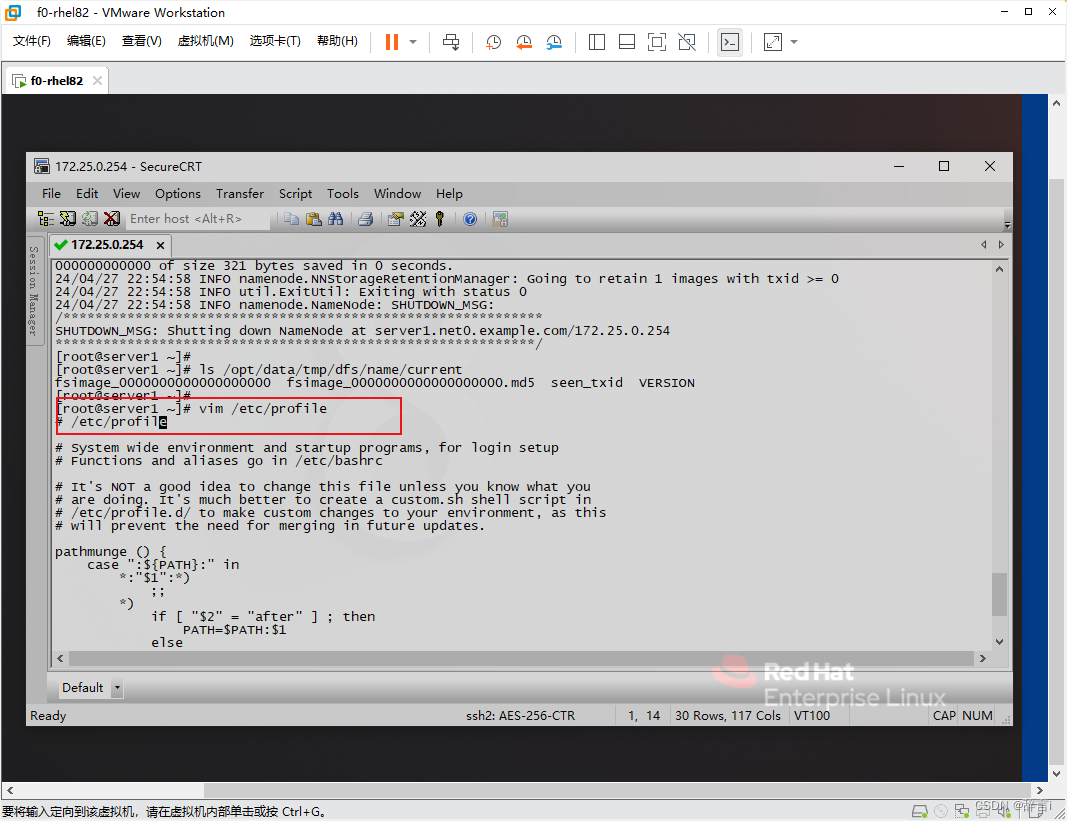
- 使用
-
添加Hadoop命令到PATH:
- 在文件末尾添加以下内容:
export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/opt/hadoop export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH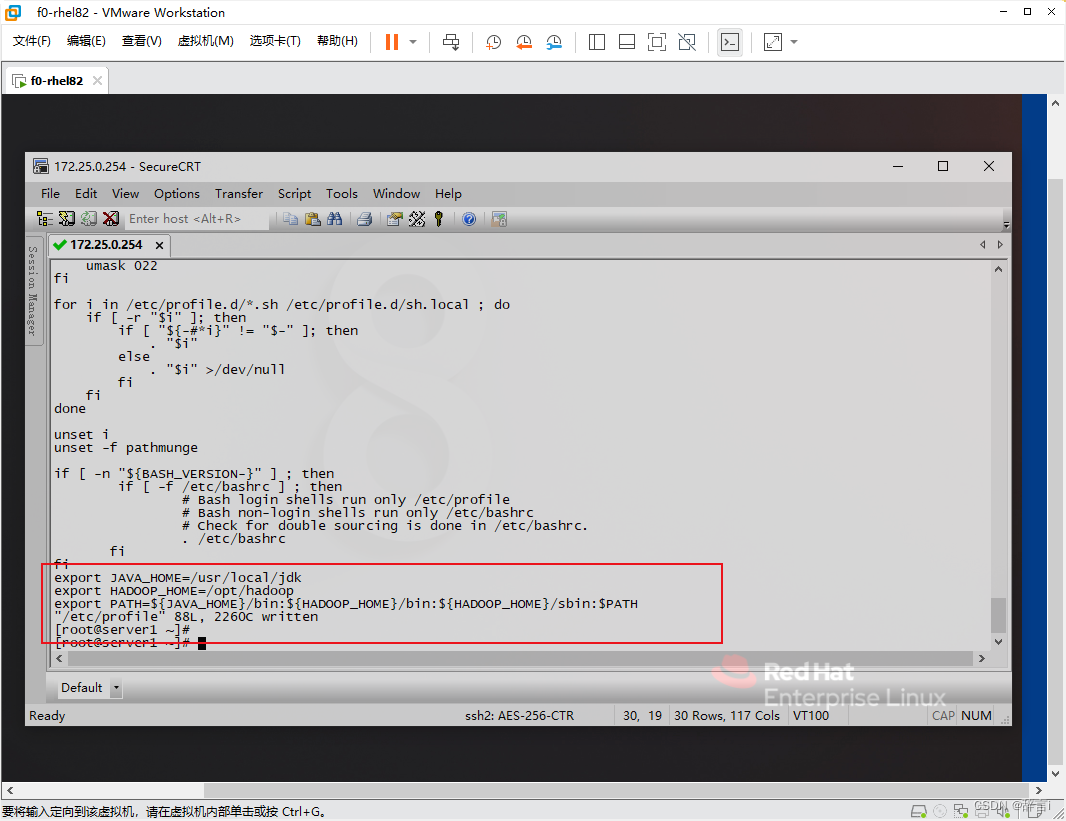
- 在文件末尾添加以下内容:
-
使更改生效:
- 运行
source命令使配置生效:source /etc/profile
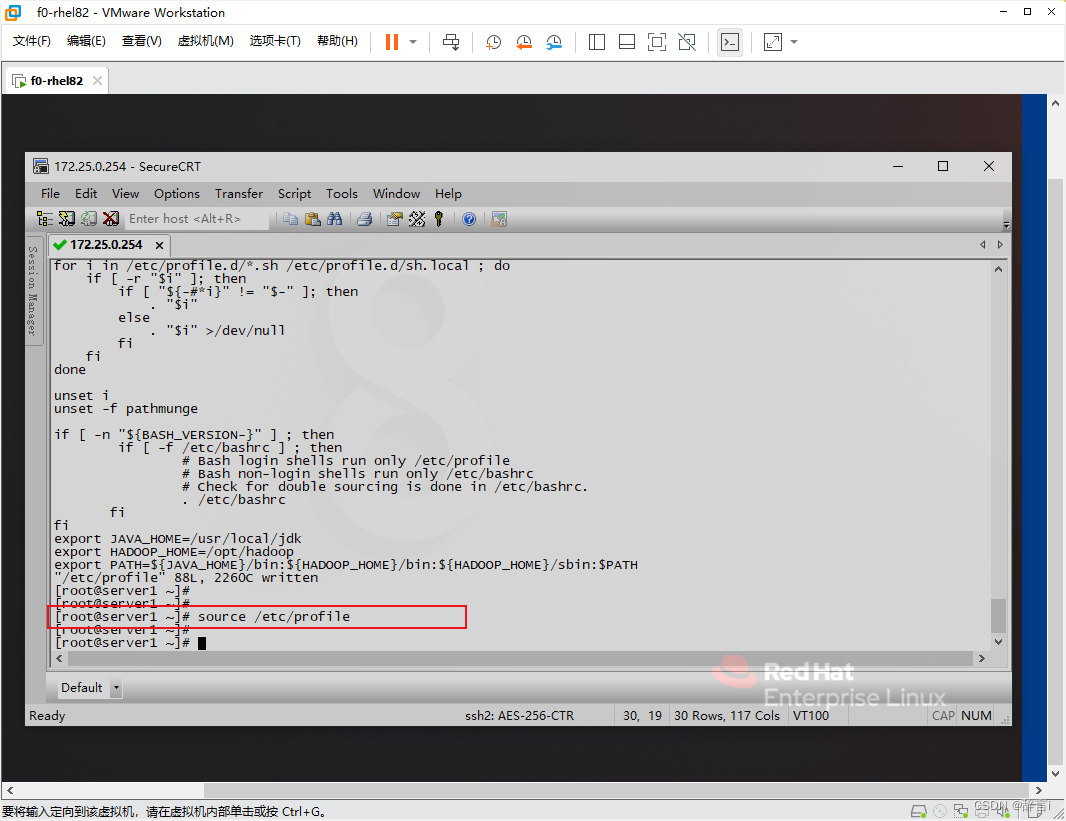
- 运行
启动Hadoop服务
- 启动
namenode和datanode服务:hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode
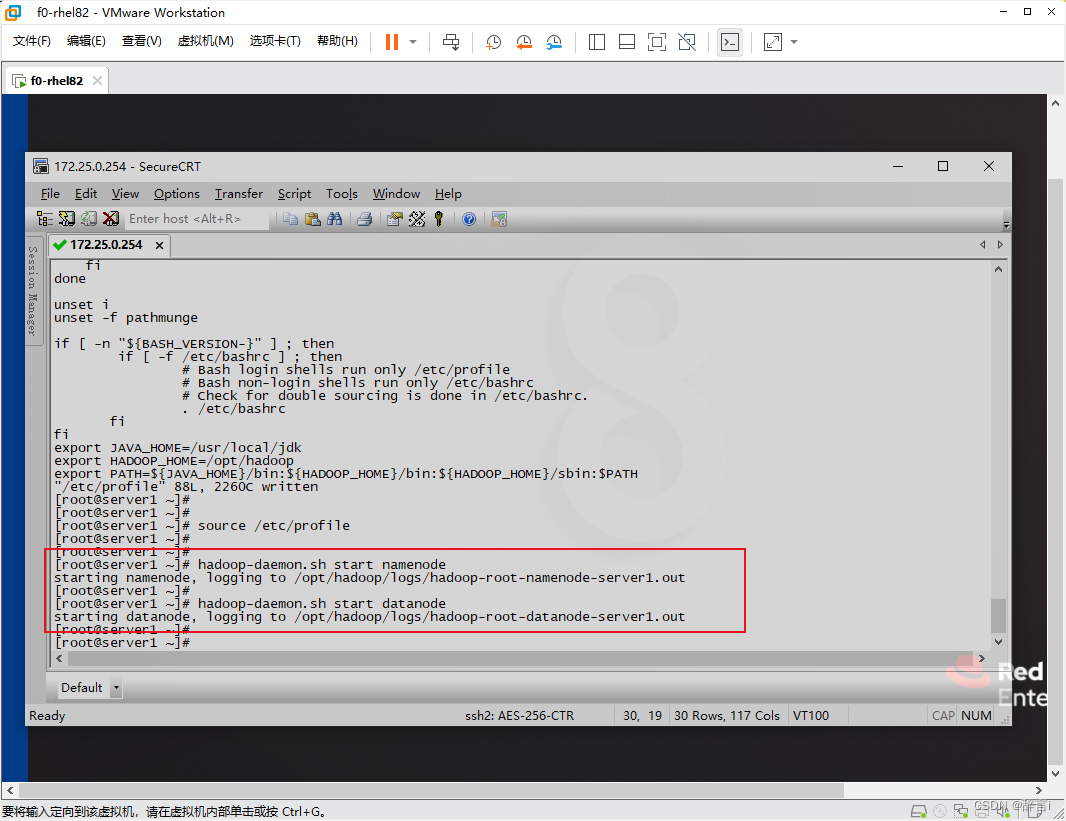
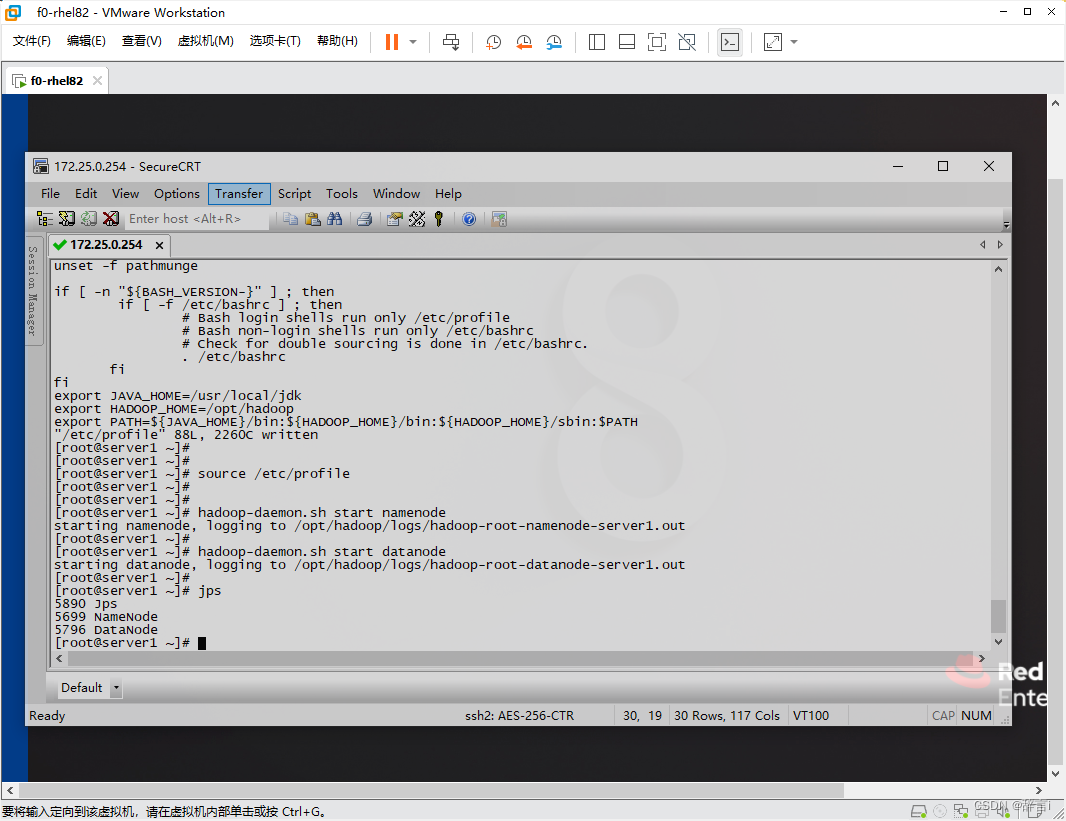
验证
通过命令:jps
配置mapred-site.xml
-
复制模板文件:
- 复制
mapred-site.xml.template文件为mapred-site.xml - 指令:
cp /opt/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/etc/hadoop/mapred-site.xml 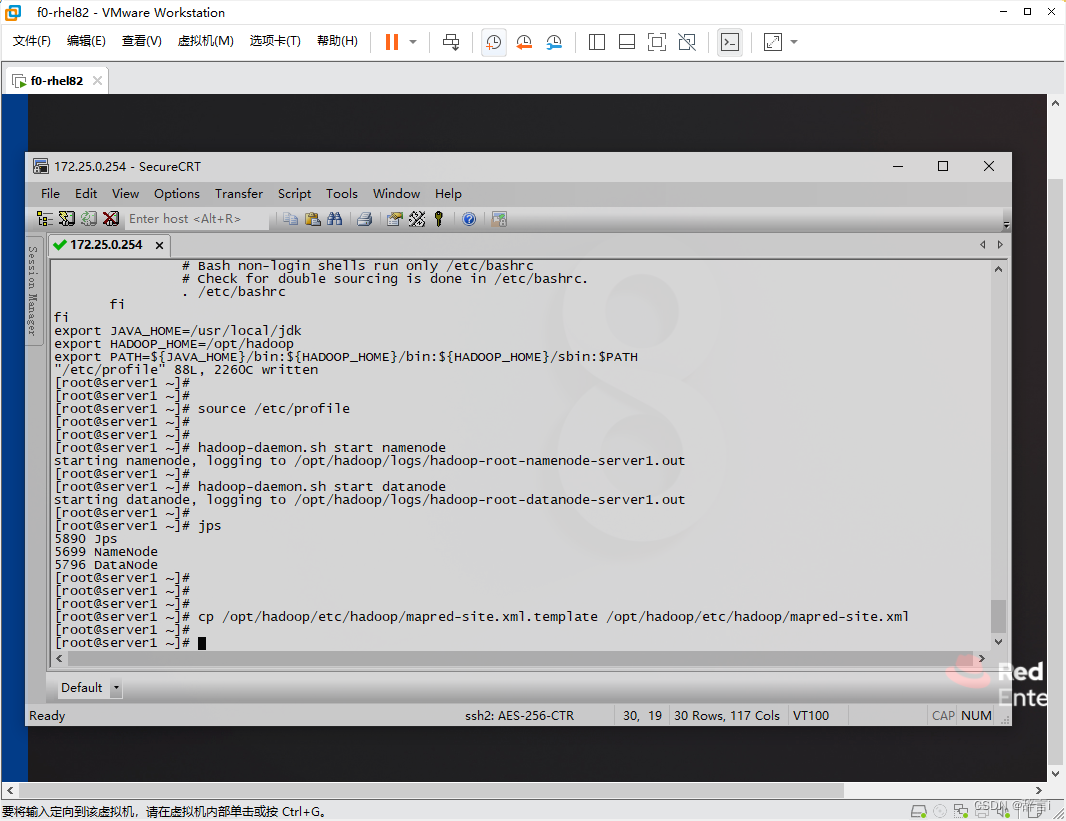
- 复制
-
编辑mapred-site.xml:
- 使用
vim编辑器打开mapred-site.xml文件:vim /opt/hadoop/etc/hadoop/mapred-site.xml 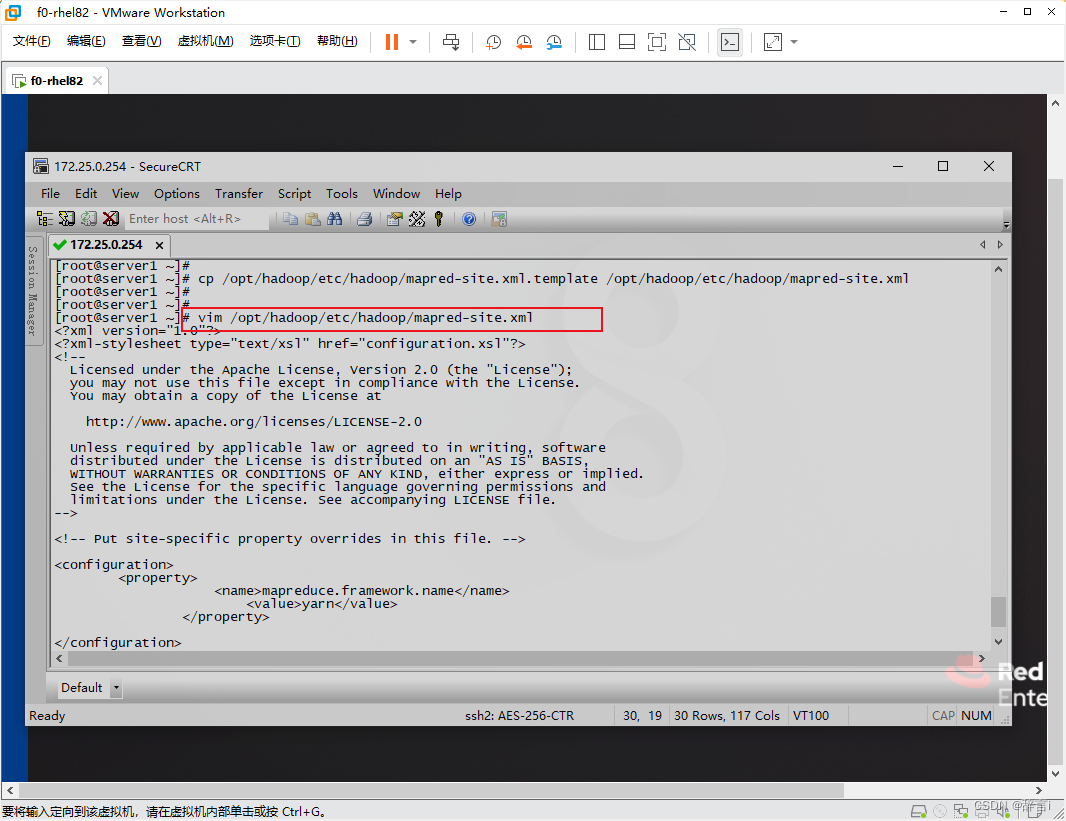
- 使用
-
添加配置:
- 添加以下属性:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
- 添加以下属性:
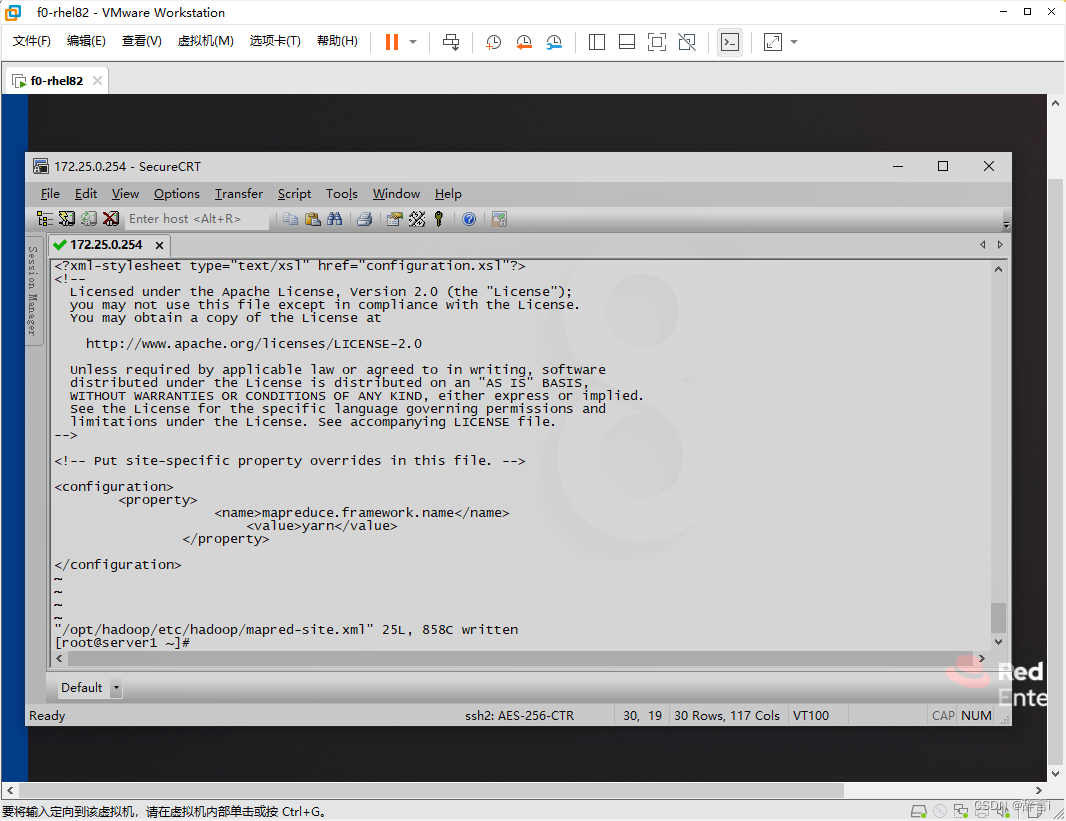
配置yarn-site.xml
-
编辑yarn-site.xml:
- 使用
vim编辑器打开yarn-site.xml文件 - 指令:
vim /opt/hadoop/etc/hadoop/yarn-site.xml 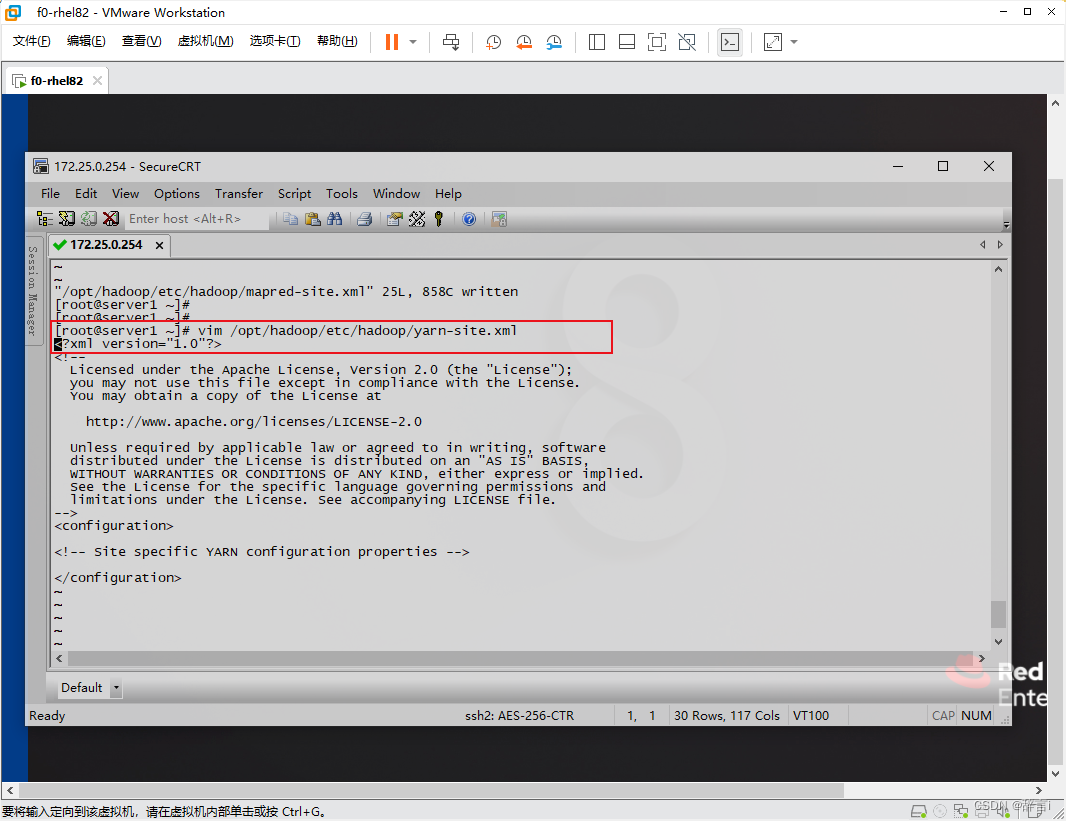
- 使用
-
添加配置:
- 添加以下属性:
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hd1</value> </property>
- 添加以下属性:
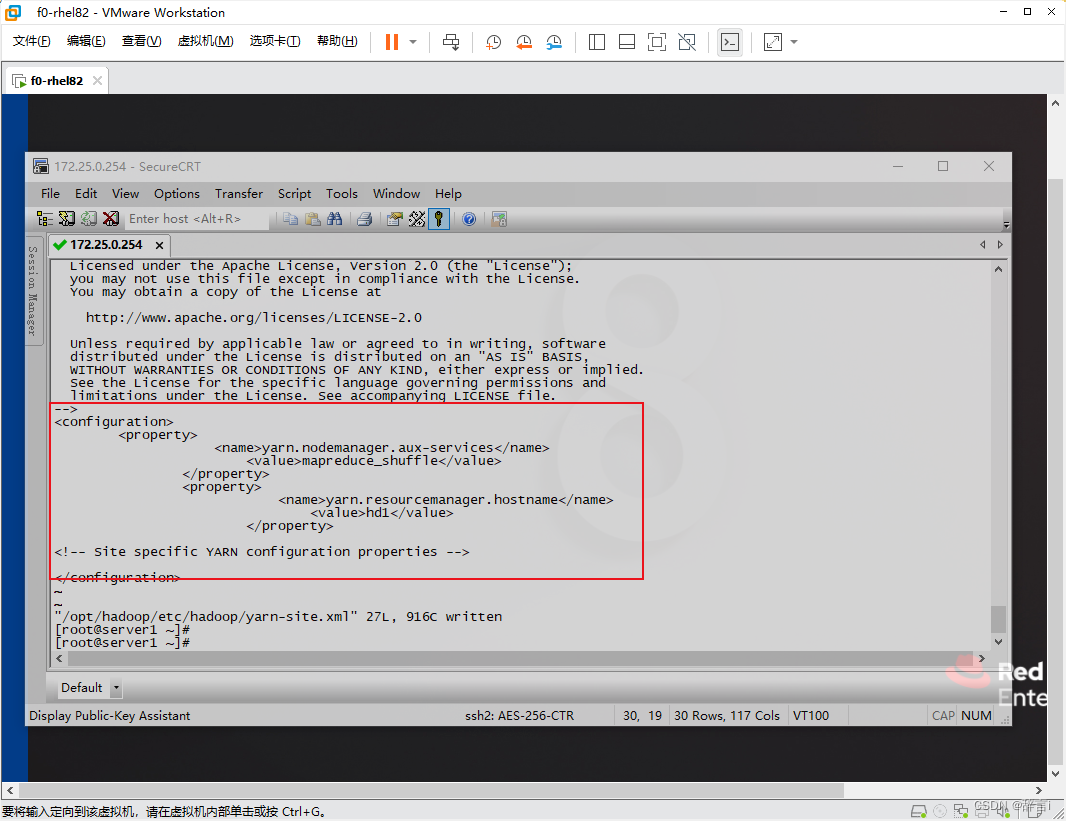
启动YARN服务
- 启动
resourcemanager和nodemanager服务:yarn-daemon.sh start resourcemanager yarn-daemon.sh start nodemanager
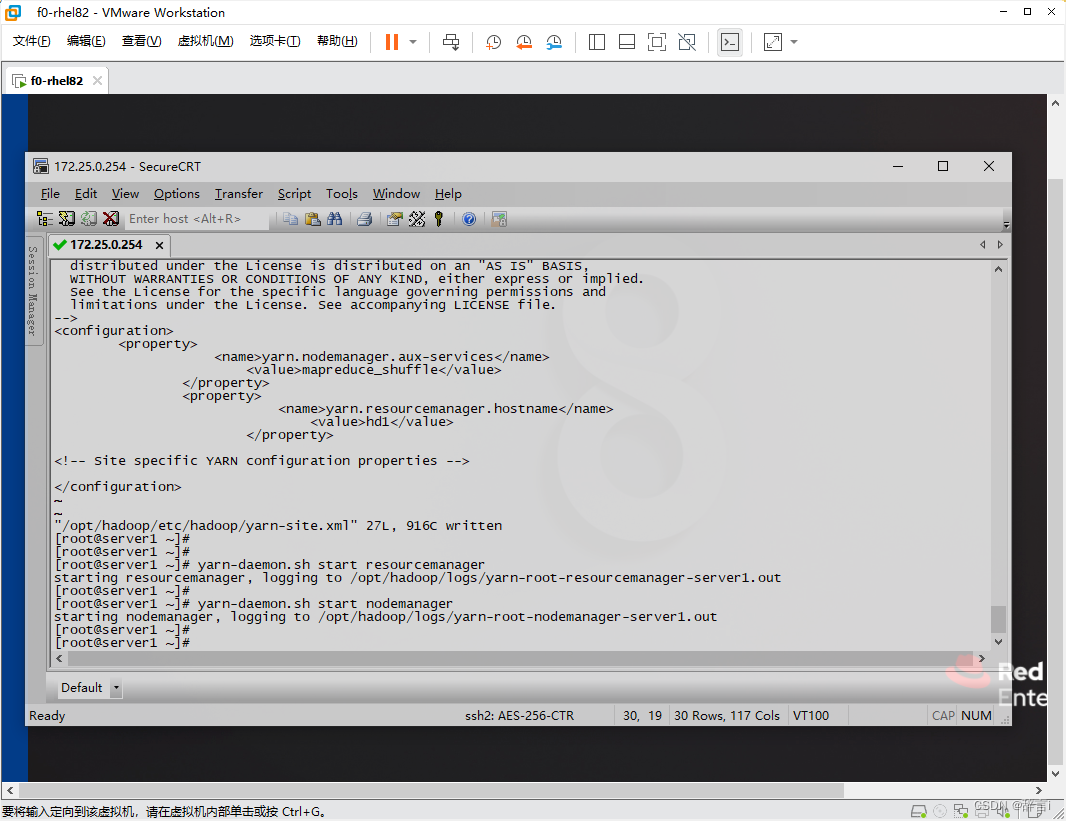
在linux网页搜索
在虚拟机里面通过linux里面的浏览器搜索:http://hd1:8088/
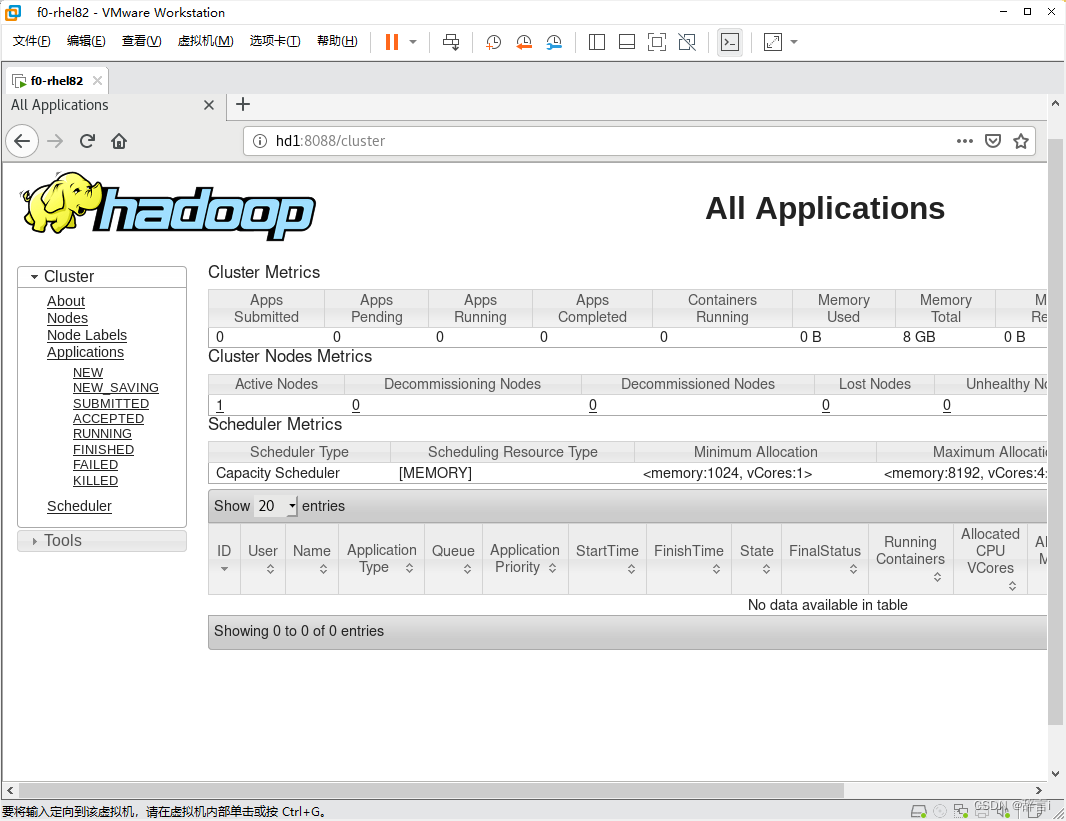
通过网页我们可以看见现还没有上传文件。
创建目录
通过命令:hdfs dfs -mkdir -p /test/input
然后在通过命令:cd /opt/data去到/opt/data目录下。
创建包含10-20个不同或部分相同的单词的文本文件:
创建一个新的文本文件:touch input.txt
打开文本编辑器并编辑该文件:vi input.txt
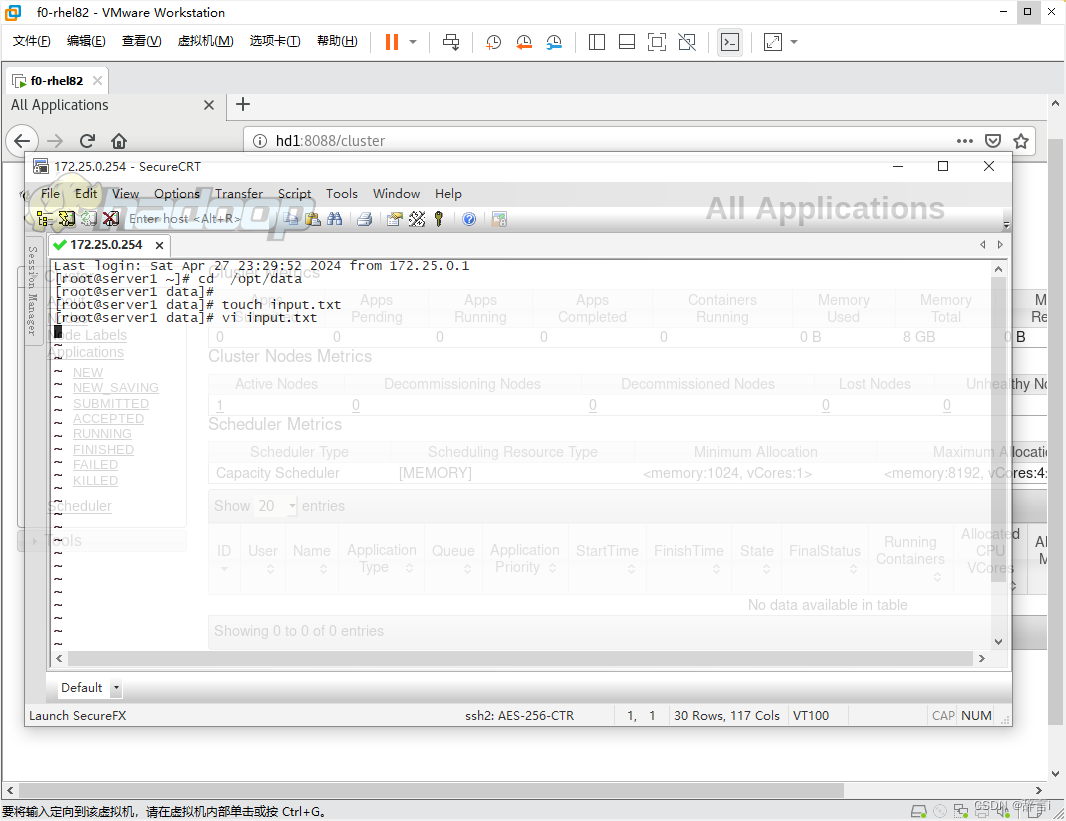
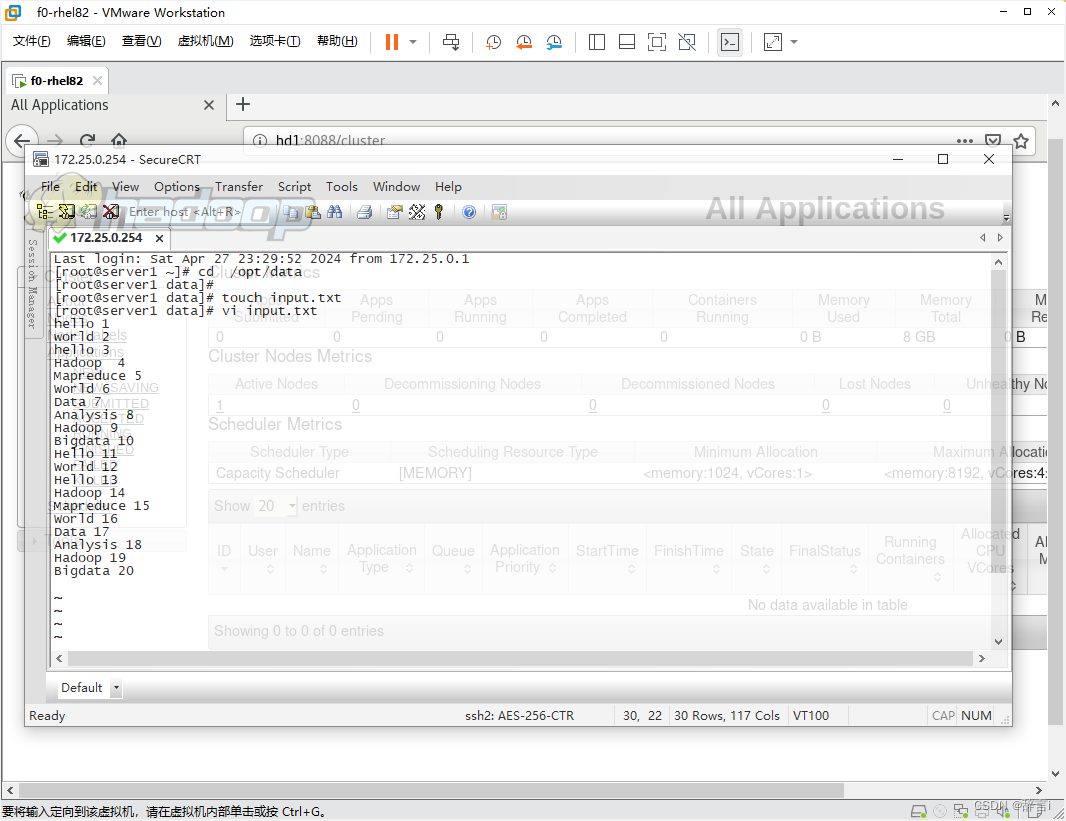
在文件中输入以下内容或类似内容(每个单词占一行):
hello 1
world 2
hello 3
Hadoop 4
Mapreduce 5
World 6
Data 7
Analysis 8
Hadoop 9
Bigdata 10
Hello 11
World 12
Hello 13
Hadoop 14
Mapreduce 15
World 16
Data 17
Analysis 18
Hadoop 19
Bigdata 20
保存文件并退出编辑器,存文件为 input.txt。
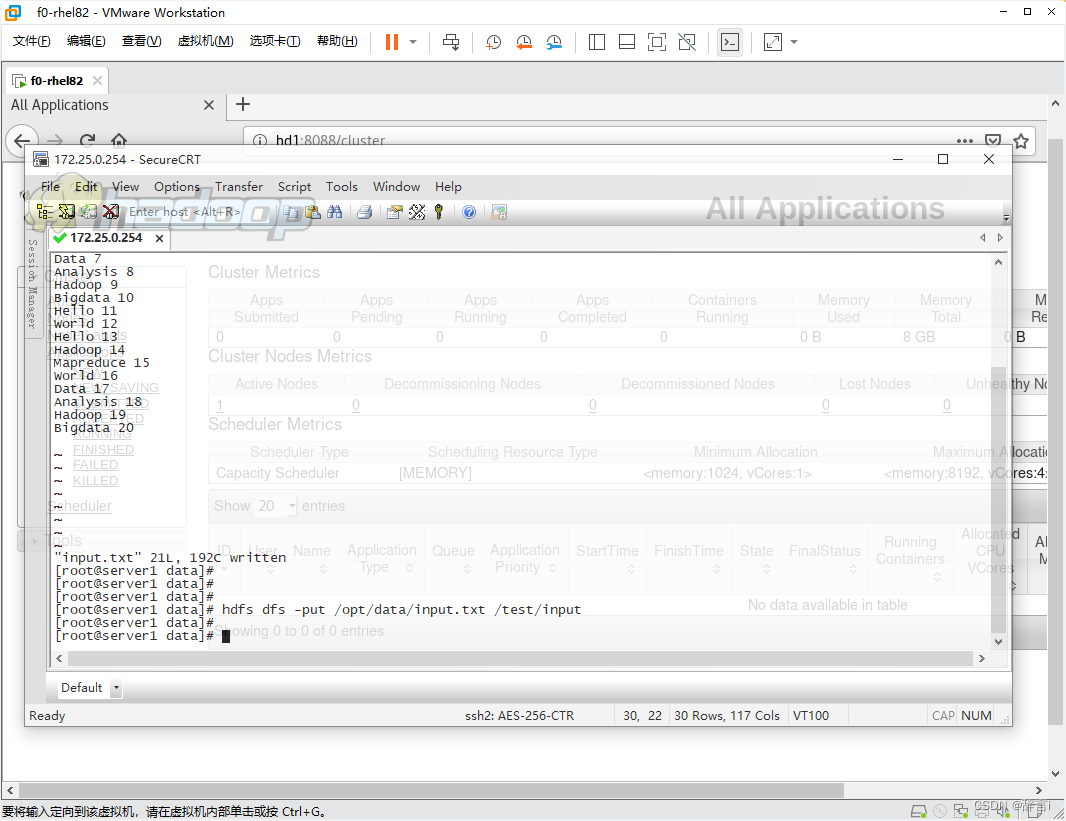
上传文件
将input.txt文件上传到HDFS的/test/input目录中:
指令:hdfs dfs -put /opt/data/input.txt /test/input
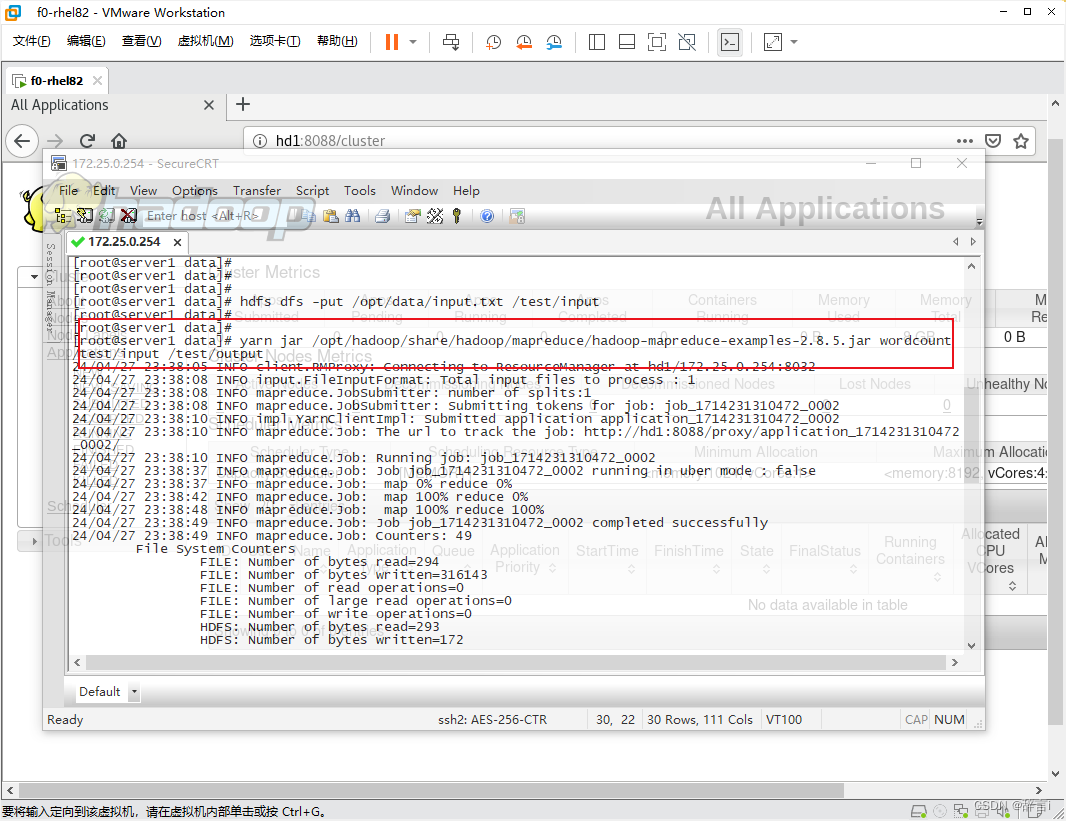
运行WordCount示例
- 使用
hadoop jar命令运行 WordCount 示例:yarn jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /test/input /test/output
返回linux浏览器查看是否上传成功
返回linux浏览器中刷新,如图所示:
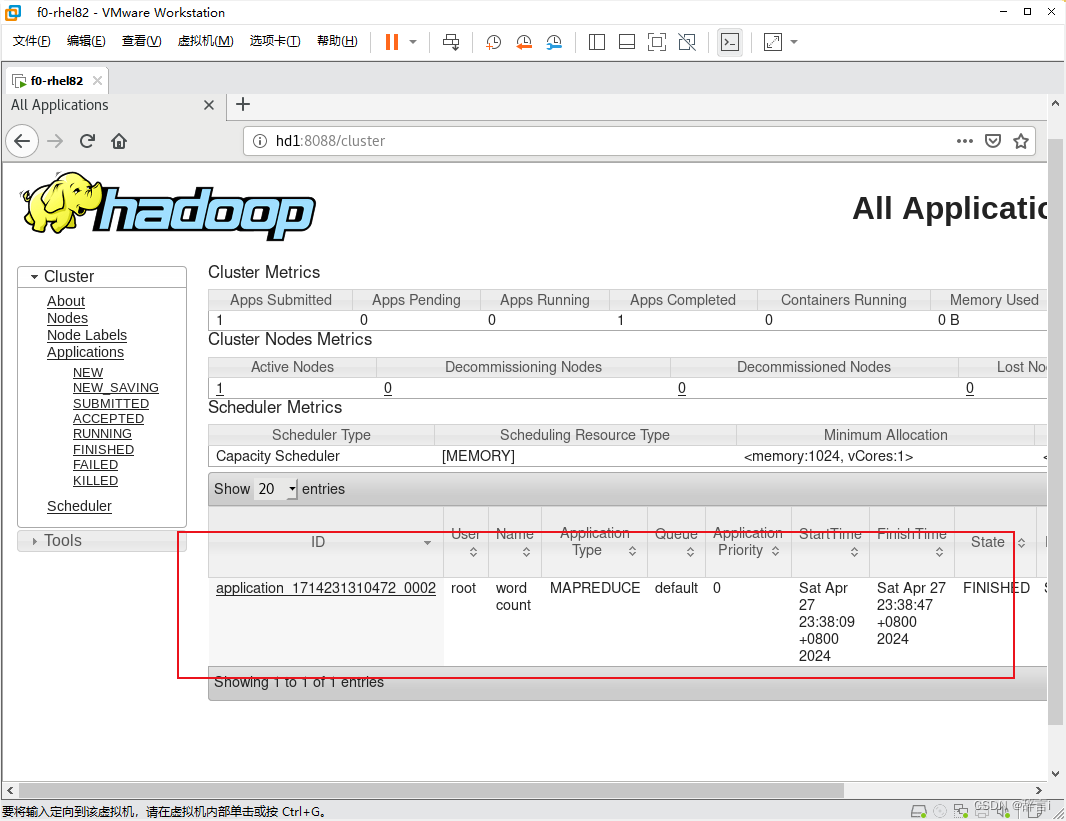
就已经说明上传成功了。
查看输出结果
- 使用
hdfs dfs --ls命令查看输出文件的内容 - 指令:
hdfs dfs -ls /test/output
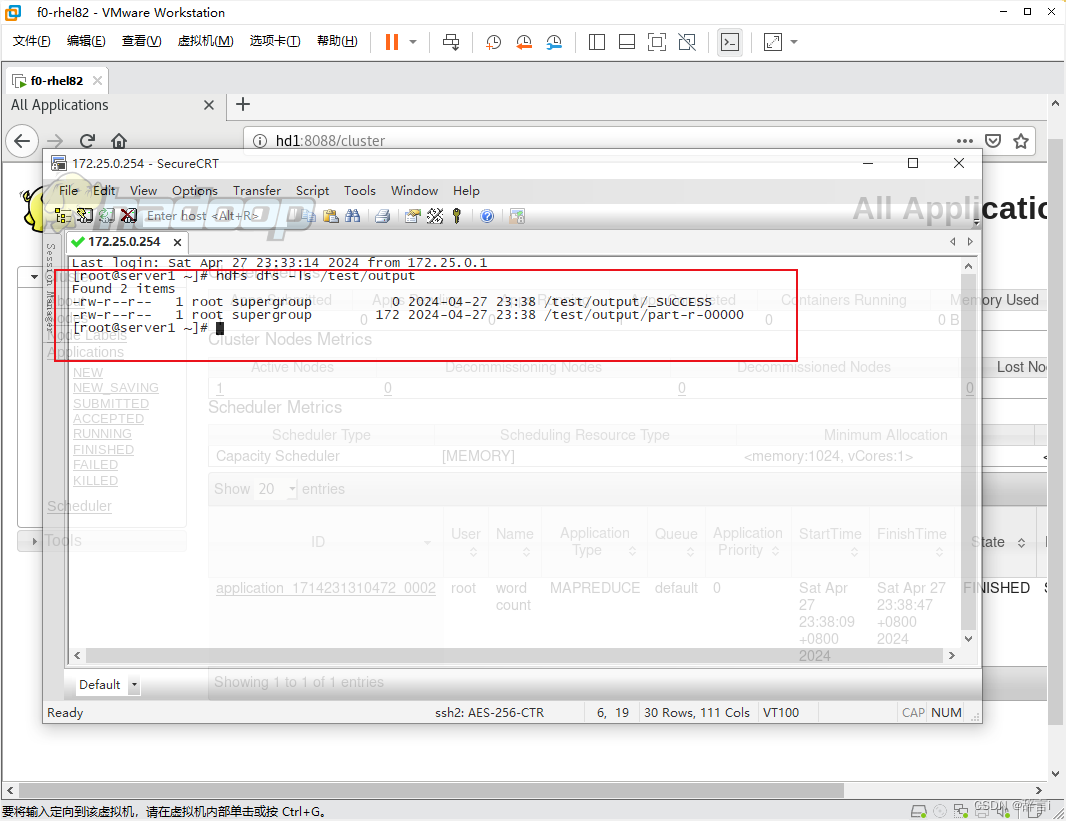
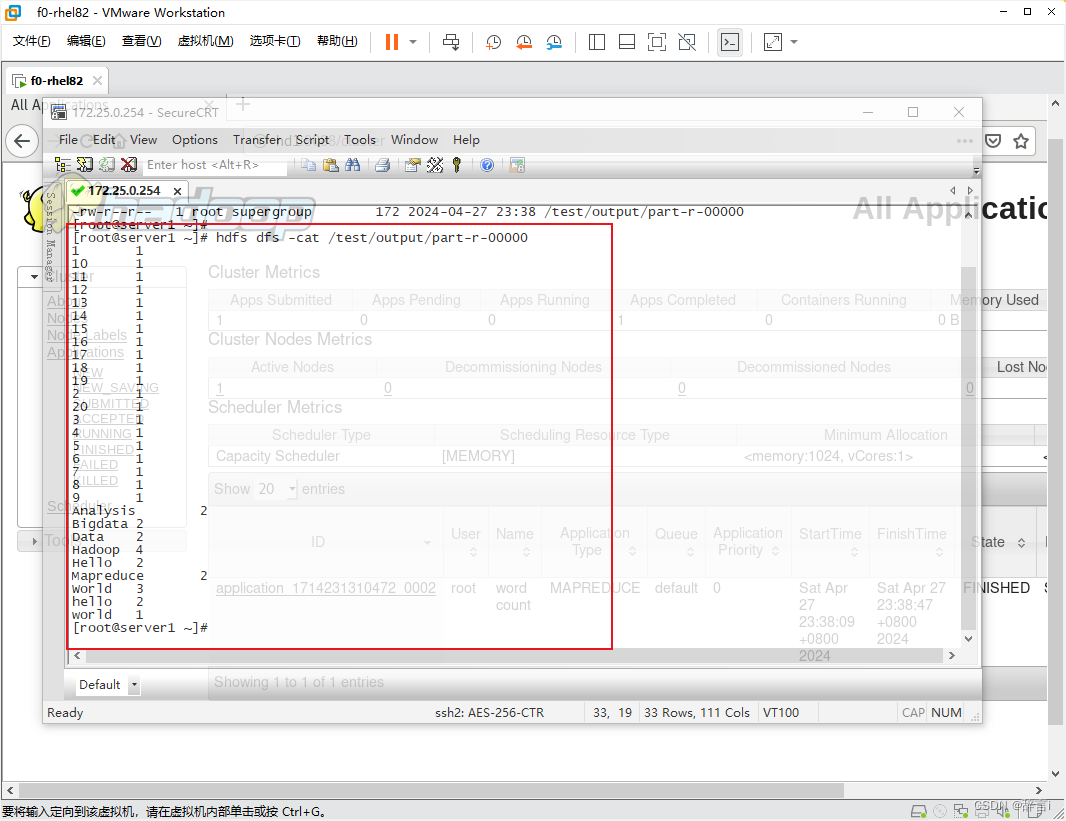
- 使用
hdfs dfs -cat命令查看输出文件的内容 - 指令:
hdfs dfs -cat /test/output/part-r-00000
以上步骤是对在Linux环境下进行伪分布式Hadoop部署和运行WordCount示例的详细解题思路。
总结
本文详细介绍了在Linux环境下使用伪分布式Hadoop进行部署和运行WordCount示例的步骤。主要包括以下内容:
- 准备工作:上传并解压JDK和Hadoop压缩包。
- JDK部署:解压JDK并配置环境变量。
- Hadoop部署:解压Hadoop并配置环境变量。
- 修改Hadoop配置文件:包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml等文件。
- 配置hosts文件:添加IP地址和主机名映射。
- 重新格式化HDFS:使用hdfs namenode -format命令。
- 创建输入文件:创建包含单词的文本文件,并上传到HDFS。
- 运行WordCount示例:使用hadoop jar命令运行示例。
- 查看输出结果:通过hdfs dfs命令查看输出文件的内容。
通过以上步骤,可以在单台计算机上模拟分布式环境,实现Hadoop的基本功能,如文件存储、作业调度和数据处理。这种伪分布式环境适合学习、测试和开发分布式系统,但需要注意其性能可能无法完全模拟真实的分布式环境。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











