






论文下载(提取码:3bp6)
该文章提出了PAGE-Net模型,该模型的创新之处主要包含了两个模块,分别是pyramid attention(即金字塔增强模块)和salient edge detection(即显著性边缘检测模块),前者可以使得模型更加关注和显著性有关的特征,作者将多尺度的显著性信息利用到atte-ntion机制中去(通过叠加不同尺度的attention实现),这样可使得attention模块中选出的特征具有更加有效的表达能力,因为堆叠不同尺度的attention可以使得获取的特征具有更大的感受野。后者可以利用显著性物体的边缘信息来细化最终分割的显著性物体的边缘,作者是通过监督学习预测显著性物体的边缘来获取边缘信息。
首先,在深度学习中,获取具有很好代表能力的特征是最关键最为基础的,而具有多尺度空间的特征可以具有很好的代表能力,尤其是在显著性检测任务中,有很多工作可以表明多尺度特征具有很大的作用,因为很多工作中的模型都是通过组合各中间层的特征输出而获取较好的结果(不同中间层的特征的尺度是不一样的)。再者,基于CNN的用来解决不同任务的模型都具有一个统一的骨干网络(Vgg、Res-Net或者其他),骨干网络主要负责提取统一的特征,后续根据不同任务而设计的网络再利用这些统一提取到的特征进行各自的任务,所以骨干网络提取到的特征具有广泛性或者说是具有冗余性,而不同的任务可能只需要骨干网络中提取到的特征的一部分,一般后续设计的特定网络应该会自适应地选取自己所需的特征,但是最近的一些关于attention的工作的成功表明,我们获取在接受骨干网络提取到的特征时就可以先对其进行筛选,这样的筛选会取得更好的结果,这可能是由于神经网络的学习能力还不够强,靠我们后续自己设计的网络去学习需要的特征还是有困难的,因为那些冗余的特征可能还会造成干扰,其实从这个角度来看,attention就是将原始的特征进行一些过滤,将那些响应值不大的特征滤除,增强响应值大的特征,将解空间减小,这样有助于后续的神经网络通过学习选取适合自己任务的特征。在显著性目标检测任务中,采用attention模块可以使得模型更加关注于与显著性相关的图像中的区域,从而有效地滤除背景中的一些干扰区域,有效提高模型的性能。attention要滤除不相干的特征,如何判断哪些特征是不相干的则变成一个有待解决的问题,最开始的方法便是直接对原始特征进行softmax或者sigmoid后得到[0,1]的与原始特征同尺寸的权重矩阵,用该权重矩阵与原始特征进行相应像素相乘进行筛选,这样做的动机便是认为响应值大的特征便是重要的特征,那些响应值小的特征应该就是不相关的特征,这样筛选方式还不够具有任务导向性,后面就有人采用了门的结构,将原始特征与有关的特征进行融合然后再进行上述的attention,类似的操作还有很多,在本片论文中,作者将多尺度特征提取和attention相结合,提取后的特征既具有较大的感受野(多尺度),而且还更加关注显著性区域(采用了attention),作者的做法就是对当前层的原始特征进行不同尺寸的下采样,对原始特征以及下采样后的特征再进行attention操作,最后将这些过滤后的特征再融合起来,便得到了pyramid attention后的结果。
显著性目标检测的任务大多是通过语义分割的方式来进行的,我们知道语义分割自从FCN以来就有一个缺点,那就是空间信息的丢失问题,由于CNN中的池化和下采样的存在,高层特征能够获取更大的感受野和更强的表示能力但是代价则是丢失了很多细节性的空间信息,而这些空间信息对于像素精细分类的任务来说是非常必要的,在显著性目标检测领域中,尽管有skip connect或者编码解码结构来解决这些问题,比如U-Net,通过逐步融合上一层的具有更多的空间信息的特征来一步步细化分割结果,很好地解决了空间信息缺失的问题,但是我觉得尽管融合了底层的特征可以很好地恢复丢失的空间信息,这种方法看似完美地同时解决了分类精度和空间信息恢复的问题,但是我觉得还是有不足的地方,因为尽管底层的特征具有更多的空间信息,但它毕竟就是特征,他的表示性相较于高层特征还具有一定差距,也就是具有语义上的鸿沟,融合高层和底层的特征就需要网络来缩小它们之间的语义鸿沟,这增加了网络的负担,而且缩小语义鸿沟和恢复空间信息貌似是两个具有矛盾性的问题,因为网络在融合的过程中肯定会权衡某个像素的分类是根据高层特征来分类还是通过底层特征来分类,若是对显著性目标进行定位肯定考虑高层特征多些,若是细化显著性目标的边缘肯定是考虑底层特征多些,若网络对于底层特征考虑过多,那么可能就会直接导致显著性目标检测的错误,尽管边缘可能会很好,若是网络对于高层特征考虑过多,则得出的结果显著性目标会检测到,但其边缘可能会有模糊不清的表现,所以我们可能会看到,U-Net可能对于那些较为容易检测出来的显著性物体有很准确的定位以及边缘分割效果,但是对于那些背景比较复杂的难以分类的显著性物体来说,要么会检测出背景中的物体,要么检测出来的显著性物体边缘会有模糊的现象,这可能就是类似于U-Net方法对于特征的语义鸿沟处理不当所造成的结果,虽然我并不知道如何解决这个问题,但是U-Net的缺点应该就是这样的。在本文中作者将显著性物体的边缘信息融入到提取到的特征中,作者是通过网络预测显著性物体边缘来得到边缘信息的,有了边缘信息可以使得模型更好地定位显著性物体以及细化分割结果。之前的方法中还有增加边缘loss,可以使得模型更加注重于显著性物体边缘的像素的分类。
本篇论文的模型如下图所示,模型主要由三部分构成,分别是用于提取特征的骨干网络(最左边的墨蓝色表示),每一层out-side的pyramid attention模块(中间灰色的虚线框所示),以及显著性边缘检测模块(最右边黄色虚线框表示)。

pyramid attention模块如图二所示,

X表示为显著性网络的一个卷积层输出的3D的特征张量(用![]() 表示),则
表示),则,M代表特征张量的尺寸,C代表通道数,我们的目的是学习系列和X尺寸相同的数值为[0,1]的attention mask,用以筛选原始特征X,获取多尺度特征的方式是逐步对X进行尺度为
的下采样,得到n个多尺度特征
,即
对于每一个,我们进行softmax操作得出attention mask,用
表示,具体计算公式如下所示:
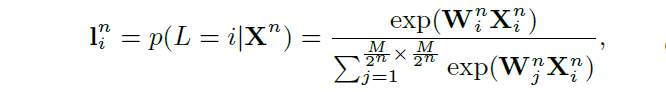
其中的是隐层的权重值,说明在softmax之前还对
进行一系列的卷积,将通道转化成单通道,i的取值是1到
,所有的
加起来等于1。然后对
进行上采样得到
,即
最终attention后的特征Y由以下公式得到,可见此处的attention是spatial attention没有考虑channel attention。
![]()
这样计算的attention后的feature有很多接近于0的值,这样不利于梯度的反向传播,原因可能类似于梯度弥散,为了解决这个问题,增加了恒等映射,则最终的公式变成如下所示:
![]()
若直接将得到的特征Y通过一小系列卷积以及最后的sigmoid激活函数便可进行分割结果的预测,但是这样做之后得到的结果并没有很精细的边界,通过添加显著性边缘预测模块可以使得网络更加注重于显著性边界像素的预测来学习如何细化分割边界。salient edge detection模块如图三所示:
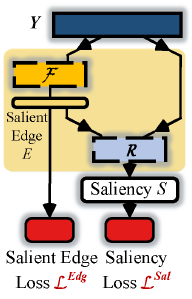
用表示训练数据,K便是batch_size的大小,
,
和
分别是三通道的原始彩色图,相应的ground truth和由ground truth生成的显著性边缘gt。经过pyramid attention后的特征Y先经过显著性边缘检测模块
(
),该模块由一系列卷积构成,
是
经过pyramid attention后的特征,
所采用的损失函数是L2范数,如下所示:

得到显著性边缘特征(
)后,将其和
一起送入到saliency readout network R(
,
(
))中得到最终的显著图的预测结果,整个模块的总的损失函数如下所示:
![]()
saliency loss的损失是加权的交叉熵loss,公式如下所示:

i表示搜索完图片中的所有像素点,S是最终的显著性预测,是显著性像素占整个GT的比例,添加
的目的就是解决显著性像素和非显著性像素数目不均衡的问题。
为了进一步提高模型的性能,作者也采用了密集连接,只不过他是将前面层的saliency map连接了过来,而不是feature map,如下所示:
![]()
是第
层经过pyramid attention后的特征,
和
分别是前面层预测的显著性边界和最终的显著性预测结果,
代表必要的采样和串联操作。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









