






这篇文章将 UNet 和条件变分自编码器(CVAE)结合在一起,使得 UNet 具有量化预测不确定性的能力,之前的 Dropout 和 Ensemble 是对模型的权重参数构建一个随机变量分布,这篇文章是对输入数据构建一个随机变量分布,目的是对输入产生若干随机扰动(perturbation),每产生一个波动就输出一个预测值,最后将所有预测值结合起来计算不确定性。具体做法如下图所示,求得一个低维的隐层概率空间(通过Prior Net),在该空间上进行多次随机采样然后和 UNet 的最后一层特征组合,产生多个输出。在这里作者没用直接在图片上进行扰动,而是在高层特征上,其实效果都是一样的。
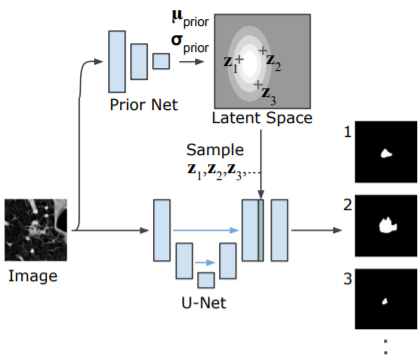
虽然基于权重构建分布和基于输入数据构建分布两种随机化的方式不同,但是在本质上其实是相通的,假定一组权重参数对应一个待分类数据,这套权重参数能够对待分类数据进行分类,则从概率的角度上来看,可以对这组权重参数进行随机扰动,也可以对待分类数据进行随机扰动,即对同一个待分类数据,存在多组权重都能将其进行分类,而对于同一组权重,也存在多个待分类数据能够被它分类,那么无论是将多组扰动后的权重进行统一,还是将多个扰动的分类数据进行统一,都能对基于该权重的网络对该数据分类的可靠性进行一个衡量。
上述对输入数据进行扰动的方式是用在测试阶段的,还需要对 Prior Net 的权重参数进行训练,则根据 CVAE 的设定,也引入了 Posterior Net,则训练过程如下图所示,注意图中的 μ \boldsymbol\mu μ 和 σ \boldsymbol\sigma σ 是多元高斯分布的均值和方差,由 Latent Space 采样生成的具有空间结构的特征则是用采样的多元向量沿着空间维度扩展而成,比如经过采样生成的是 1 × 1 × N 1\times 1 \times N 1×1×N 的向量,经过空间维度上的扩展就是 H × W × N H \times W \times N H×W×N 的特征,所以文章中说它的概率值来自于空间维度上所有像素的联合分布。
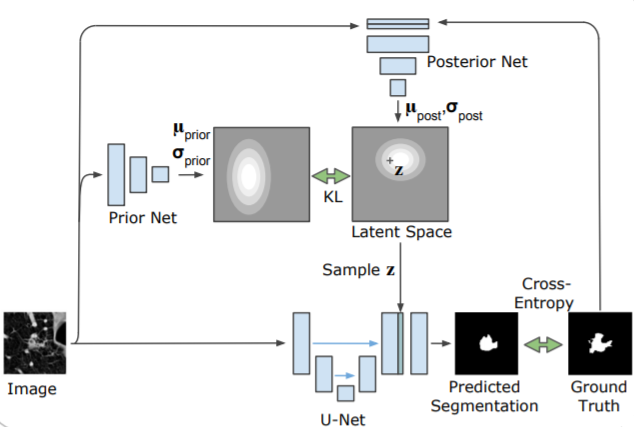
对于损失函数就是 CVAE 的 BELO,这在 CVAE 中已经有了详细的推到,损失函数如下:
L
(
Y
,
X
)
=
E
z
∼
Q
(
⋅
∣
Y
,
X
)
[
−
log
P
c
(
Y
∣
S
(
X
,
z
)
)
]
+
β
⋅
D
K
L
(
Q
(
z
∣
Y
,
X
)
∥
P
(
z
∣
X
)
)
(1)
\mathcal{L}(Y, X)=\mathbb{E}_{z \sim Q(\cdot \mid Y, X)}\left[-\log P_{c}(Y \mid S(X, z))\right]+\beta \cdot D_{\mathrm{KL}}(Q(z \mid Y, X) \| P(z \mid X)) \tag{1}
L(Y,X)=Ez∼Q(⋅∣Y,X)[−logPc(Y∣S(X,z))]+β⋅DKL(Q(z∣Y,X)∥P(z∣X))(1)
其中 Q ( z ∣ Y , X ) Q(z \mid Y, X) Q(z∣Y,X) 是 Posterior Net, P ( z ∣ X ) P(z \mid X) P(z∣X) 是 Prior Net, S ( X , z ) S(X, z) S(X,z) 是基于扰动产生的隐变量 z z z 生成的预测值。
在此基础上,后来在论文《A Hierarchical Probabilistic U-Net for Modeling Multi-Scale Ambiguitie》中作者又进行了改进,引入了多层次的隐层变量(hierarchical latent space)。
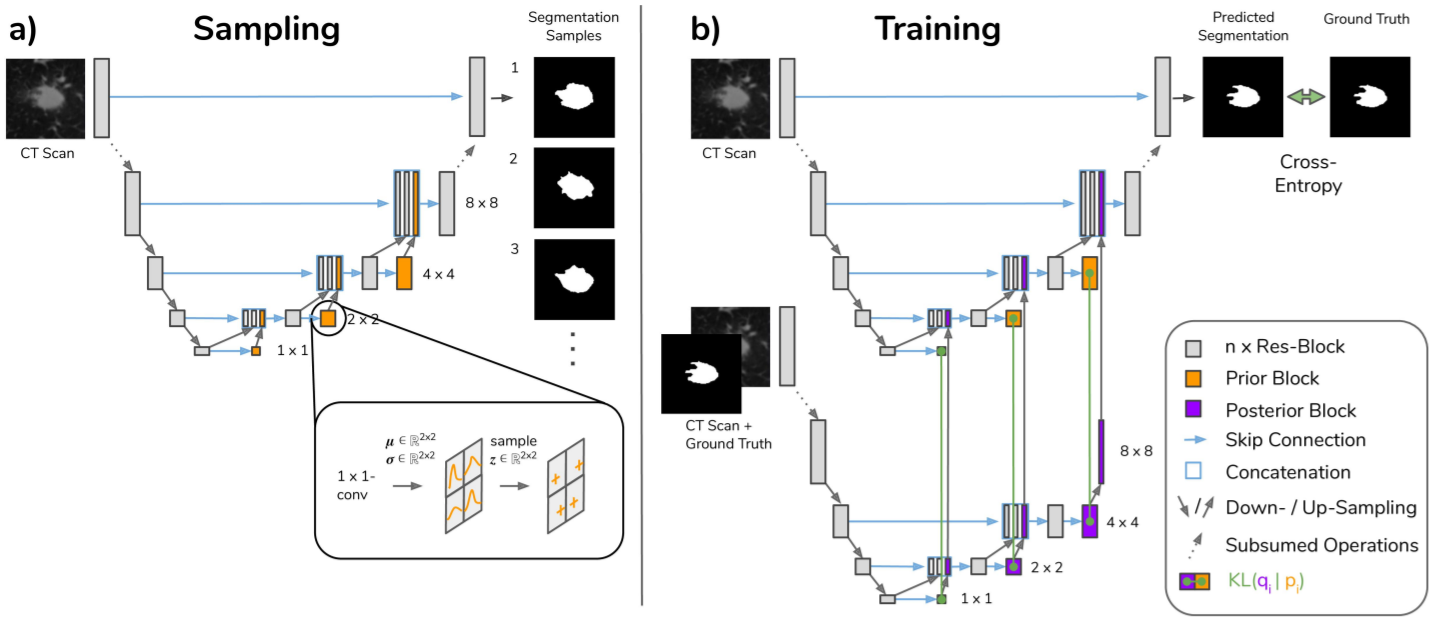
如上图所示,这篇文章中,作者除了引入多层次的隐层变量这个基本的思路上进行改进外,具体的改进有以下几点:
- 不用额外的 Prior Net 来生成隐层变量,如下图 a)所示,直接用 UNet 每层的特征预测均值和方差
- 之前的隐层变量为 1 × 1 × N 1\times1\times N 1×1×N 的向量,这里的隐层变量为 H i × W i H_{i} \times W_{i} Hi×Wi 的具有空间结构的向量, i i i 为产生隐层变量相应的层编号。
- 设计了一个串行的隐层变量生成机制,假设UNet中有
L
L
L 层生成了隐层变量,则分辨率最大的为第
L
L
L 层的隐层变量
z
L
\mathbf{z}_{L}
zL,而
z
L
\mathbf{z}_{L}
zL 不仅取决于输入数据
X
\mathbf{X}
X,还取决于
i
<
L
i < L
i<L 层的隐层变量
z
i
\mathbf{z}_{i}
zi,定义
z
<
i
:
=
(
z
i
−
1
,
…
,
z
0
)
\mathbf{z}_{<i}:=\left(\mathbf{z}_{i-1}, \ldots, \mathbf{z}_{0}\right)
z<i:=(zi−1,…,z0),有:
z i ∼ N ( μ i prior ( z < i , X ) , σ i prior ( z < i , X ) ) = : p ( z i ∣ z < i , X ) (1) \mathbf{z}_{i} \sim \mathcal{N}\left(\boldsymbol{\mu}_{i}^{\text {prior }}\left(\mathbf{z}_{<i}, X\right), \boldsymbol{\sigma}_{i}^{\text {prior }}\left(\mathbf{z}_{<i}, X\right)\right)=: p\left(\mathbf{z}_{i} \mid \mathbf{z}_{<i}, X\right) \tag{1} zi∼N(μiprior (z<i,X),σiprior (z<i,X))=:p(zi∣z<i,X)(1) 根据条件概率分布有:
P ( z 0 , … , z L ∣ X ) = p ( z L ∣ z < L , X ) ⋅ … ⋅ p ( z 0 ∣ X ) (2) P\left(\mathbf{z}_{0}, \ldots, \mathbf{z}_{L} \mid X\right)=p\left(\mathbf{z}_{L} \mid \mathbf{z}_{<L}, X\right) \cdot \ldots \cdot p\left(\mathbf{z}_{0} \mid X\right) \tag{2} P(z0,…,zL∣X)=p(zL∣z<L,X)⋅…⋅p(z0∣X)(2) 给定输入数据 X \mathbf{X} X 和隐层变量 z \mathbf{z} z,有 Y ′ = S ( X , z ) Y^{\prime}=S(\mathbf{X}, \mathbf{z}) Y′=S(X,z),其中 z = ( z L , … , z 0 ) \mathbf{z}=\left(\mathbf{z}_{L}, \ldots, \mathbf{z}_{0}\right) z=(zL,…,z0)。
训练过程如上图 b)所示,后验分布为:
Q
(
z
0
,
…
,
z
L
∣
X
,
Y
)
=
q
(
z
L
∣
z
<
L
,
X
,
Y
)
⋅
…
⋅
q
(
z
0
∣
X
,
Y
)
(3)
Q\left(\mathbf{z}_{0}, \ldots, \mathbf{z}_{L} \mid X, Y\right)=q\left(\mathbf{z}_{L} \mid \mathbf{z}_{<L}, X, Y\right) \cdot \ldots \cdot q\left(\mathbf{z}_{0} \mid X, Y\right) \tag{3}
Q(z0,…,zL∣X,Y)=q(zL∣z<L,X,Y)⋅…⋅q(z0∣X,Y)(3) 所需优化的 ELBO 为:
L
E
L
B
O
=
E
z
∼
Q
[
−
log
P
c
(
Y
∣
S
(
X
,
z
)
)
]
+
β
⋅
∑
i
=
0
L
E
z
<
i
∼
Q
D
K
L
(
q
i
(
z
i
∣
z
<
i
,
X
,
Y
)
∥
p
i
(
z
i
∣
z
<
i
,
X
)
)
(4)
\mathcal{L}_{\mathrm{ELBO}}=\mathbb{E}_{\mathbf{z} \sim Q}\left[-\log P_{\mathrm{c}}(Y \mid S(X, \mathbf{z}))\right]+\beta \cdot \sum_{i=0}^{L} \mathbb{E}_{\mathbf{z}_{<i} \sim Q} D_{\mathrm{KL}}\left(q_{i}\left(\mathbf{z}_{i} \mid \mathbf{z}_{<i}, X, Y\right) \| p_{i}\left(\mathbf{z}_{i} \mid \mathbf{z}_{<i}, X\right)\right) \tag{4}
LELBO=Ez∼Q[−logPc(Y∣S(X,z))]+β⋅i=0∑LEz<i∼QDKL(qi(zi∣z<i,X,Y)∥pi(zi∣z<i,X))(4)

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









