







ARMv6 MMU简述
1)MMU由协处理器CP15控制;
2)MMU功能:地址映射(VA->PA),内存访问权限控制;
3)虚拟地址到物理地址的转换过程:Micro TLB->Main TLB->Page Table Walk
址映射过程详述
参考《ARM1176 JZF-S Technical Reference Manual》6.11节,Hardware page table translation
关于页表:ARMv6的MMU进行地址映射时涉及到两种页表,一级页表(first level page table)和二级页表(coarse page table)。
关于映射方式:映射方式有两种,段映射和页映射。段映射只用到一级页表,页映射用到一级页表和二级页表。
关于映射粒度:段映射的映射粒度有两种,1M section和16M supersection;页映射的映射粒度也有两种,4K small page和64K large page。
硬件在做地址转换时,如何知道当前是什么映射方式以及映射粒度是多少呢?
一级页表的入口描述符(first-level descriptor)格式如下:
第[1:0]位决定映射方式:
[1:0]=10b时,是段映射,此时只需作一级映射,描述符的最高12或8位存放的是段基址;
[1:0]=01b时,是页映射,此时虚拟地址转换为物理地址需要经历二级映射,描述符的最高22位存放的是二级页表的物理地址;
第[18]位决定段映射的粒度:
[18]=0b时,映射粒度为1M,描述符的最高12位存放段基址;
[18]=1b时,映射粒度为16M,描述符的最高8位存放段基址;
当映射方式为页映射时,我们用到二级页表,二级页表的入口描述符(second-level descriptor)格式如下:
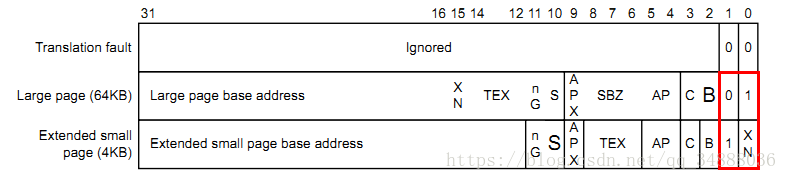
第[1:0]位决定页映射的映射粒度:
[1:0]=10b或11b时,映射粒度为4KB,描述符的最高20位为页基址;
[1:0]=01b时,映射粒度为64KB,描述符的最高16位为页基址;
下面分4种情况对地址映射过程做详细描述:
1)段映射,映射粒度为1M
2)段映射,映射粒度为16M
3)页映射,映射粒度为4K
4)页映射,映射粒度为64K
2.1段映射,映射粒度为1M
当映射方式为段映射,且映射粒度为1M时,映射图如下:

虚拟地址到物理地址的映射过程如下:
虚拟地址的[31:20]位存放一级页表的入口index,[19:0]位存放段偏移;
从TTBR(translation table base register,协处理器CP15中的一个寄存器,用于存放一级页表的基址)寄存器中获取一级页表的基址;
一级页表基址+ VA[31:20] = 该虚拟地址对应的页表描述符的入口地址;
页表描述符的[31:20]位为该虚拟地址对应的物理段基址;
物理段基址+ VA[19:0]段偏移= 物理地址
由映射图可知,一个虚拟地址可以索引2^12个一级页表入口,每个入口映射2^20大小的内存,故虚拟地址可以映射的最大物理内存为:2^12 * 2^20,即4G。
2.2 段映射,映射粒度为16M
当映射方式为段映射,且映射粒度为16M时,映射图如下:

虚拟地址到物理地址的映射过程如下:
虚拟地址的[31:24]位存放一级页表的入口index,[23:0]位存放段偏移;
从TTBR(translation table base register,协处理器CP15中的一个寄存器,用于存放一级页表的基址)寄存器中获取一级页表的基址;
一级页表基址+ VA[31:24] = 该虚拟地址对应的页表描述符的入口地址;
页表描述符的[31:24]位为该虚拟地址对应的物理段基址;
物理段基址+ VA[23:0]段偏移= 物理地址
由映射图可知,一个虚拟地址可以索引2^8个一级页表入口,每个入口映射2^24大小的内存,故虚拟地址可以映射的最大物理内存为:2^8 * 2^24,即4G。
2.3 页映射,映射粒度为4K
当映射方式为页映射,且映射粒度为4K时,映射图如下:

虚拟地址到物理地址的映射过程如下:
虚拟地址的[31:20]位存放一级页表的入口index,[19:12]位存放二级页表的入口index,[11:0]位存放页偏移;
从TTBR(translation table base register,协处理器CP15中的一个寄存器,用于存放一级页表的基址)寄存器中获取一级页表的基址;
一级页表基址+ VA[31:20] = 一级页表描述符的入口地址;
一级页表描述符的[31:10]位存放二级页表的基址;
二级页表基址+ VA[19:12] = 二级页表描述符的入口地址;
二级页表描述符的[31:12]位存放该虚拟地址在内存中的物理页基址;
物理页基址+ VA[11:0]页偏移= 物理地址
由映射图可知,一个虚拟地址可以索引2^12个一级页表入口,每个一级页表入口指向的二级页表最大可以有2^8个二级页表入口,每个二级页表入口映射2^12大小的内存,故虚拟地址可以映射的最大物理内存为:2^12 * 2^8 * 2^12 ,即4G。
2.4 页映射,映射粒度为64K
当映射方式为页映射,且映射粒度为64K时,映射图如下:

虚拟地址到物理地址的映射过程如下:
虚拟地址的[31:20]位存放一级页表的入口index,[19:16]位存放二级页表的入口index,[15:0]位存放页偏移;
从TTBR(translation table base register,协处理器CP15中的一个寄存器,用于存放一级页表的基址)寄存器中获取一级页表的基址;
一级页表基址+ VA[31:20] = 一级页表描述符的入口地址;
一级页表描述符的[31:10]位存放二级页表的基址;
二级页表基址+ VA[19:16] = 二级页表描述符的入口地址;
二级页表描述符的[31:16]位存放该虚拟地址在内存中的物理页基址;
物理页基址+ VA[15:0]页偏移= 物理地址
由映射图可知,一个虚拟地址可以索引2^12个一级页表入口,每个一级页表入口指向的二级页表最大可以有2^4个二级页表入口,每个二级页表入口映射2^16大小的内存,故虚拟地址可以映射的最大物理内存为:2^12 * 2^4 * 2^16 ,即4G。
2.5 地址映射总图
《ARM1176 JZF-S Technical Reference Manual》中有一张对上述四种映射情况的汇总图:
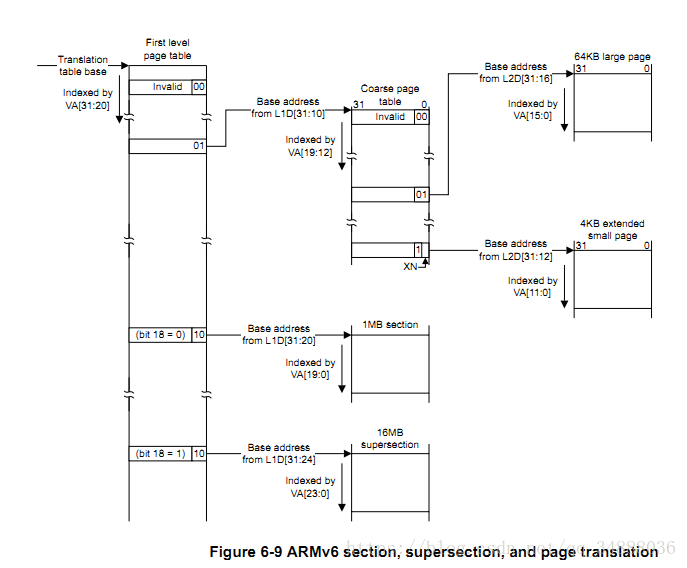
关于一级页表基址
参考《ARM1176 JZF-S Technical Reference Manual》6.12 MMU descriptors
ARMv6中有两个协处理器寄存器用来存放一级页表基地址,TTBR0和TTBR1。操作系统把虚拟内存划分为内核空间和用户空间,TTBR0存放用户空间的一级页表基址,TTBR1存放内核空间的一级页表基址。
In this model, the virtual address space is divided into two regions:
• 0x0 -> 1<<(32-N) that TTBR0 controls
• 1<<(32-N) -> 4GB that TTBR1 controls.
N的大小由TTBCR寄存器决定。0x0 -> 1<<(32-N)为用户空间,由TTBR0控制,1<<(32-N) -> 4GB为内核空间,由TTBR1控制。
N的大小与一级页表大小的关系图如下:
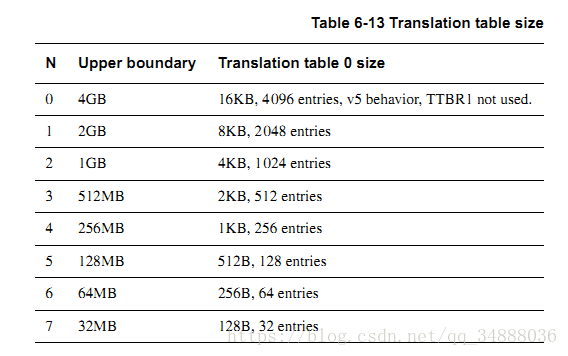
操作系统为用户空间的每个进程分配各自的页表,即每个进程的一级页表基址是不一样的,故当发生进程上下文切换时,TTBR0需要被存放当前进程的一级页表基址;TTBR1中存放的是内核空间的一级页表基址,内核空间的一级页表基址是固定的,故TTBR1中的基址值不需要改变。
4. u-boot中MMU初始化代码分析
u-boot中的MMU地址映射方式为段映射,映射粒度为1M,只用到一级页表。
start.S中的MMU初始化代码如下:
详见:https://www.cnblogs.com/tanghuimin0713/p/3917178.html
————————————————
版权声明:本文为CSDN博主「笑看江湖路6」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_34888036/article/details/81006738
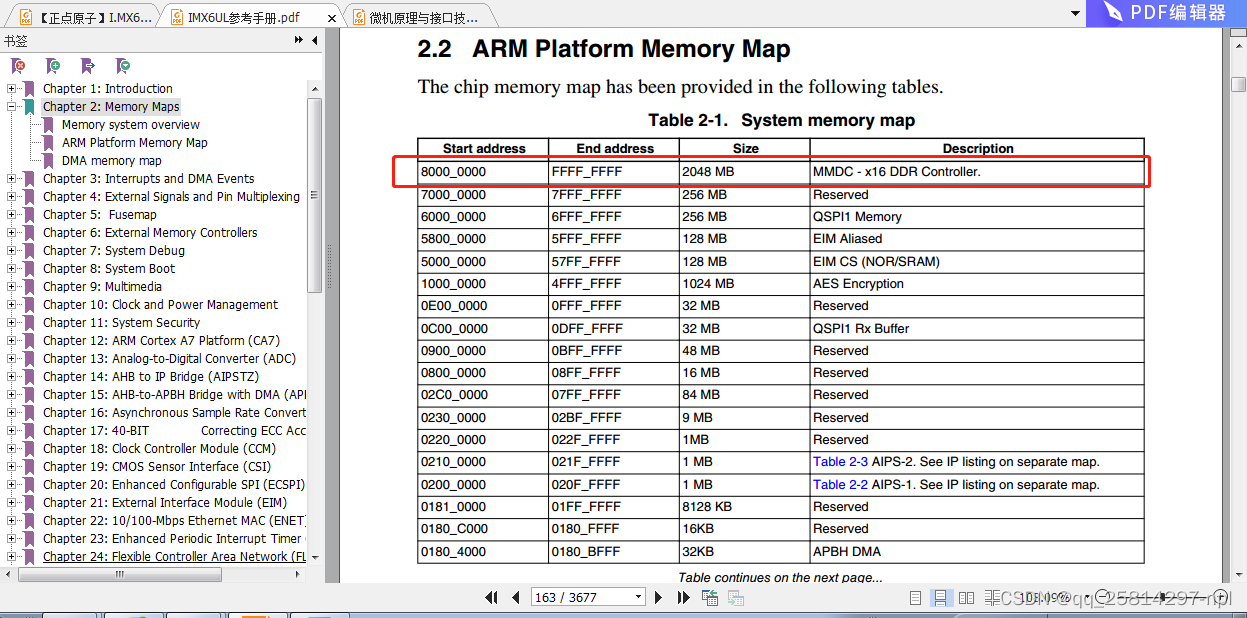
imx6ull存储器图如下,DDR对应的起始地址是8000 0000,此地址和其他存储部分地址一样是ARM 内部硬件电路寻址方式制作好的。就是实际的物理地址,这个物理地址也有MMU规定的方式由虚拟地址转换到对应的物理地址寻找到,至于MMDC如何对DDR进行操作由MMDC完成,和MMU没有关系。

MMDC
DDR的地址是从8000 0000-FFFF FFFF
而DDR需要MMDC管理,DDR的本身地址是从0-4G,如何和8000 0000对应上,MMDC内核会和系统通信,直观简单理解,地址偏移减去8000 0000变为0000 0000就对应上DDR本身内部的地址.后来理解8000 0000就是物理地址,硬件固定好的,有MMU根据虚拟地址转换物理地址规则寻址到。DDR本身的0-4G(2G)(imx6ull最大支持2G,参看Imx6ull参考手册),在整体存储中地址从8000 0000 到FFFF FFFF,MMDC进行DDR读写操作地址如何选择,是按0-2G还是8000_0000 到FFFF_FFFF,看厂家如何制作,猜测应该是从8000_0000开始的物理地址统一编址了,直接按照统一编址寻址,就像存储器一样,地址寻址电路是统一编址电路
以STM32的FSMC读写TFTLCD和片外RAM为例讲解外部存储器的基值如何确定以及偏移地址。类比理解imx6ull中的内存DDR的地址起始地址是0x8000_0000,而MMDC的外设寄存器地址范围是021B_0000 021B_3FFF,参见imx6ull参考手册
CM3存储器地图:重点是External RAM(FSMC能管理这个外部RAM区域,管理的器件有SRAM、ROM, NAND FLASH、 NOR FLASH 和 PSRAM ,PC卡等存储器地址范围正对应60000000-9FFFFFFF)和External device(FSMC控制器寄存器地址)
FSMC将AHB传输信号转换到适当的外部设备协议
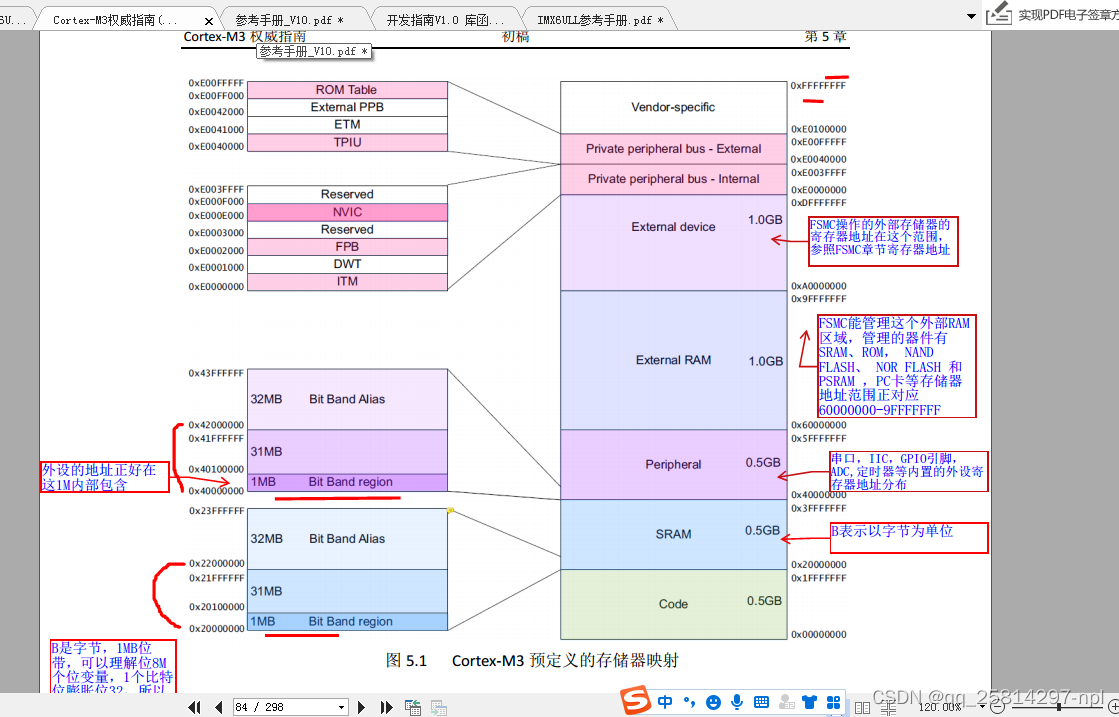
外部RAM

指定的地址计算公式: *(vu8*)(Bank1_SRAM3_ADDR+WriteAddr)
//在指定地址开始,连续写入 n 个字节.
//pBuffer:字节指针
//WriteAddr:要写入的地址//偏移地址,相对于基值的偏移地址2022.12.8
//n:要写入的字节数
void FSMC_SRAM_WriteBuffer(u8* pBuffer,u32 WriteAddr,u32 n)
{
for(;n!=0;n--)
{
*(vu8*)(Bank1_SRAM3_ADDR+WriteAddr)=*pBuffer;
WriteAddr+=2;//这里需要加 2,是因为 STM32 的 FSMC
//地址右移一位对其.加 2 相当于加 1.
pBuffer++;
}
}
TFTLCD
本实验,我们用到 FSMC 驱动 LCD,通过前面的介绍,我们知道 TFTLCD 的 RS 接在 FSMC
的 A10 上面, CS 接在 FSMC_NE4 上,并且是 16 位数据总线。 即我们使用的是 FSMC 存储器
1 的第 4 区,我们定义如下 LCD 操作结构体(在 lcd.h 里面定义):
//LCD 操作结构体
typedef struct
{
u16 LCD_REG;
u16 LCD_RAM;
} LCD_TypeDef;
//使用 NOR/SRAM 的 Bank1.sector4,地址位 HADDR[27,26]=11 A10 作为数据命令区分线
//注意 16 位数据总线时, STM32 内部地址会右移一位对其!
#define LCD_BASE ((u32)(0x6C000000 | 0x000007FE))//基值计算公式
#define LCD ((LCD_TypeDef *) LCD_BASE)
其中 LCD_BASE, 必须根据我们外部电路的连接来确定,我们使用 Bank1.sector4 就是从
地址 0X6C000000 开始,而 0X000007FE,则是 A10 的偏移量。 我们将这个地址强制转换为
LCD_TypeDef 结构体地址,那么可以得到 LCD->LCD_REG 的地址就是 0X6C00,07FE,对应
A10 的状态为 0(即 RS=0),而 LCD-> LCD_RAM 的地址就是 0X6C00,0800(结构体地址自增),
对应 A10 的状态为 1(即 RS=1)。
所以, 有了这个定义,当我们要往 LCD 写命令/数据的时候,可以这样写:
LCD->LCD_REG=CMD; //写命令
LCD->LCD_RAM=DATA; //写数据
而读的时候反过来操作就可以了,如下所示:
CMD= LCD->LCD_REG;//读 LCD 寄存器
DATA = LCD->LCD_RAM;//读 LCD 数据
屏的其他偏移地址的理解需要再深入学习了解下2022.12.8
依次类推,可以得到imx6ull中的内存DDR的地址起始地址是0x8000_0000,而MMDC的外设寄存器地址范围是021B_0000 021B_3FFF
原子教程
23.3.1 MMDC 控制器
学过 STM32 的同学应该记得,STM32 的 FMC 或 FSMC 外设用于连接 SRAM 或 SDRAM,
对于 I.MX6U 来说也有 DDR 内存控制器,否则的话它怎么连接 DDR 呢? MMDC 就是 I.MX6U
的内存控制器, MMDC 是一个多模的 DDR 控制器,可以连接 16 位宽的 DDR3/DDR3L、 16 位
宽的 LPDDR2, MMDC 是一个可配置、高性能的 DDR 控制器。
MMDC 外设包含一个内核
(MMDC_CORE)和 PHY(MMDC_PHY),内核和 PHY 的功能如下:
MMDC 内核:内核负责通过 AXI 接口与系统进行通信、 DDR 命令生成、 DDR 命令优化、
读/写数据路径。
MMDC PHY: PHY 负责时序调整和校准,使用特殊的校准机制以保障数据能够在 400MHz
被准确捕获。
MMDC 的主要特性如下:
①、支持 DDR3/DDR3Lx16、支持 LPDDR2x16,不支持 LPDDR1MDDR 和 DDR2。
②、支持单片 256Mbit~8Gbit 容量的 DDR,列地址范围: 8-12 位,行地址范围 11-16bit。 2
个片选信号。
③、对于 DDR3,最大支持 8bit 的突发访问。
④、对于 LPDDR2 最大支持 4bit 的突发访问。
⑤、 MMDC 最大频率为 400MHz,因此对应的数据速率为 800MT/S。
⑥、支持各种校准程序,可以自动或手动运行。支持 ZQ 校准外部 DDR 设备, ZQ 校准 DDR
I/O 引脚、校准 DDR 驱动能力
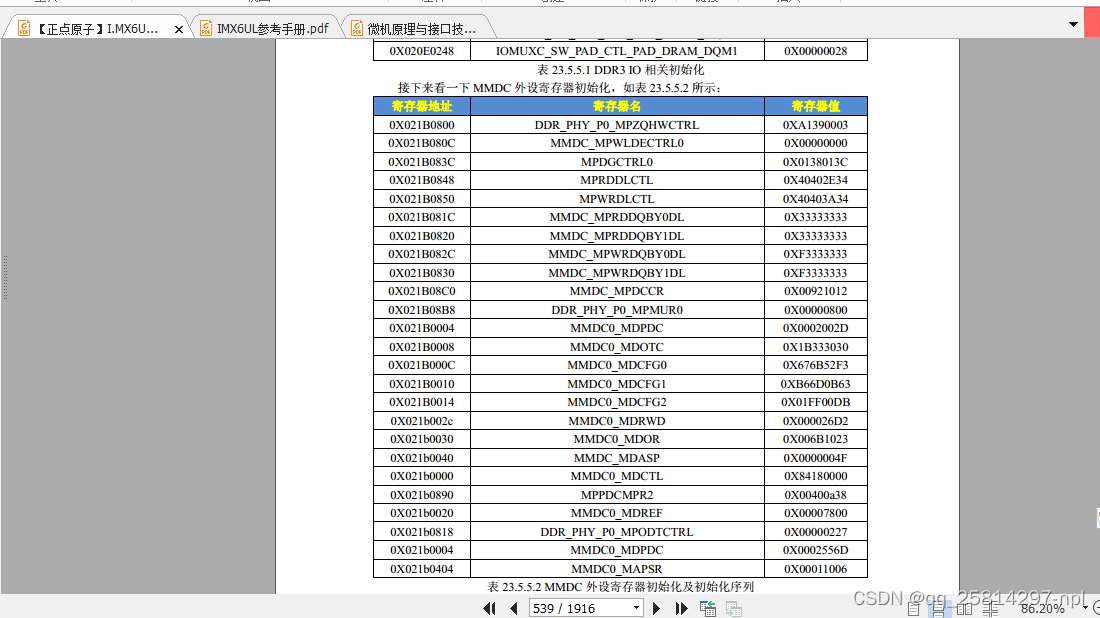
DDR IO 寄存器配置

MMDC外设寄存器配置,外设地址021B_0800开始的
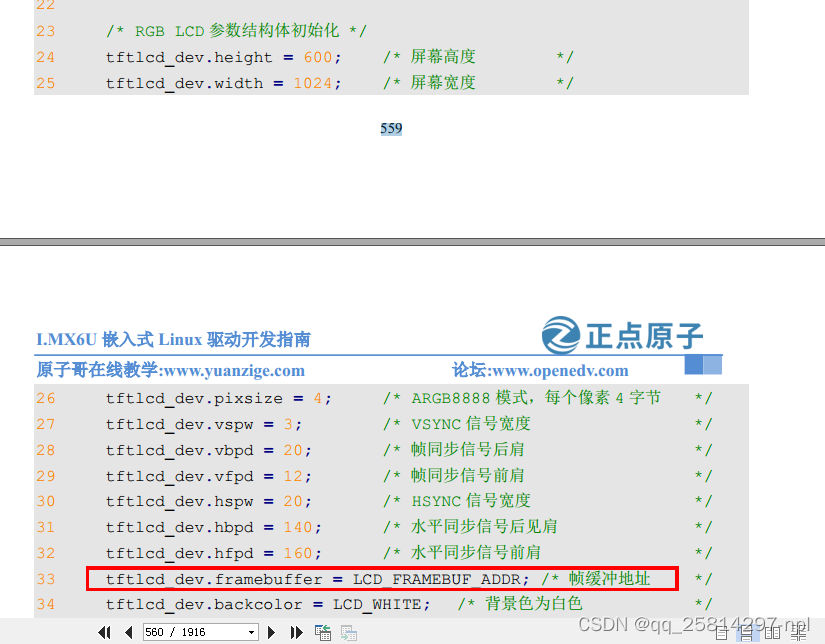
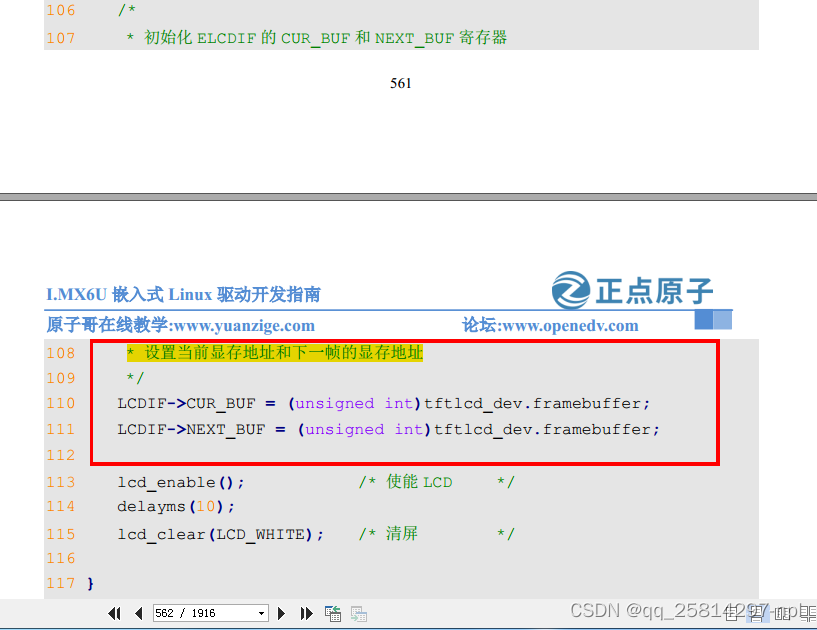
linux裸机屏LCD有专门的寄存器 LCDIF_CUR_BUF 和 LCDIF_NEXT_BUF,这两个寄存器分别为当前帧和下一帧缓冲区,也就是 LCD 显存。一般这两个寄存器保存同一个地址,也就是划分给 LCD的显存首地址。用来指定显存在DDR中的首地址,在裸机中我们可以随意的分配显存,但是在 Linux 系统中内存的管理很严格,显存是需要申请的,不是你想用就能用的。而且因为虚拟内存的存在,驱动程序设置的显存和应用程序访问的显存要是同一片物理内存。参见原子linux驱动开发教程:1387页
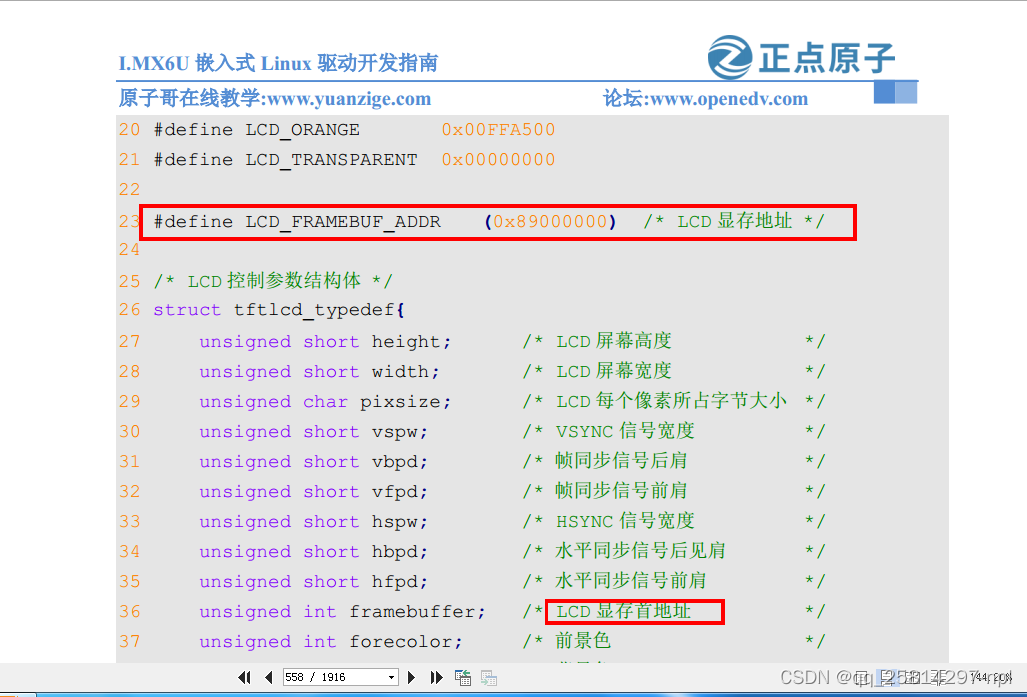
第 23 行的宏 LCD_FRAMEBUF_ADDR 是显存首地址,此处将显存首地址放到了 0X89000000
地址处。这个要根据所使用的 LCD 屏幕大小和 DDR 内存大小来确定的,前面我们说了 ATK7016
这款 RGB 屏幕所需的显存大小为 2.4MB,而 I.MX6U-ALPHA 开发板配置的 DDR 有 256 和
512MB 两种类型,内存地址范围分别为 0X80000000~0X90000000 和 0X80000000~0XA0000000。
所以 LCD 显存首地址选择为 0X89000000 不管是 256MB 还是 512MB 的 DDR 都可以使用。
由AXI接口引发的AHB,APB总线的深刻认识
总线协议
AXI(针对比如多处理器核、多重存储器结构、DMA 控制器等)
AXI(Advanced eXtensible Interface)是一种总线协议,该协议是ARM公司提出的AMBA(Advanced Microcontroller Bus Architecture)3.0协议中最重要的部分,是一种面向高性能、高带宽、低延迟的片内总线。它的地址/控制和数据相位是分离的,支持不对齐的数据传输,同时在突发传输中,只需要首地址,同时分离的读写数据通道、并支持Outstanding传输访问和乱序访问,并更加容易进行时序收敛。AXI 是AMBA 中一个新的高性能协议。AXI 技术丰富了现有的AMBA 标准内容,满足超高性能和复杂的片上系统(SoC)设计的需求。
外文名
Advanced eXtensible Interface
简 称
AXI
含 义
一种总线协议
发布公司
ARM公司
目录
目录
编辑 播报
·AXI的诞生·AXI的性能·AXI的特点·AXI的应用·市场格局
AXI的诞生
编辑 播报
随着SoC 设计复杂性的增加和CPU 处理能力的提升,总线结构会成为系统性能的瓶颈。在多处理器SoC 设计中,这种瓶颈现象更加明显。综合考虑成本、功耗和面积,SoC 设计中选用何种高效的总线结构是比较困难的,同时总线结构对系统所要求达到的性能又是非常重要的。
随着下一代高性能 SoC 设计的需要,比如多处理器核、多重存储器结构、DMA 控制器等,AMBA 需要新一代灵活性更强的总线结构,这就是AMBA 3.0 AXI 总线。AXI 是1999年发布的AMBA 2.0 的继承和提升,是ARM 公司与其他的芯片制造商包括高通、东芝和爱立信等公司共同研发的。新协议的发布,为新一代高性能SoC 的设计铺平了道路。
AXI的性能
编辑 播报
AXI 能够使SoC 以更小的面积、更低的功耗,获得更加优异的性能。AXI 获得如此优异性能的一个主要原因,就是它的单向通道体系结构。单向通道体系结构使得片上的信息流只以单方向传输,减少了延时。
选择采用何种总线,我们要评估到底怎样的总线频率才能满足我们的需求,而同时不会消耗过多的功耗和片上面积。ARM一直致力于以最低的成本和功耗追求更高的性能。这一努力已经通过连续一代又一代处理器内核的发布得到了实现,每一代新的处理器内核都会引入新的流水线设计、新的指令集以及新的高速缓存结构。这促成了众多创新移动产品的诞生,并且推动了ARM架构向性能、功耗以及成本之间的完美平衡发展。
AXI总线是一种多通道传输总线,将地址、读数据、写数据、握手信号在不同的通道中发送,不同的访问之间顺序可以打乱,用BUSID来表示各个访问的归属。主设备在没有得到返回数据的情况下可发出多个读写操作。读回的数据顺序可以被打乱,同时还支持非对齐数据访问。
AXI总线还定义了在进出低功耗节电模式前后的握手协议。规定如何通知进入低功耗模式,何时关断时钟,何时开启时钟,如何退出低功耗模式。这使得所有IP在进行功耗控制的设计时,有据可依,容易集成在统一的系统中。AXI与上一代总线AHB的主要性能比较见表1。
AXI的特点
编辑 播报
单向通道体系结构。信息流只以单方向传输,简化时钟域间的桥接,减少门数量。当信号经过复杂的片上系统时,减少延时。
支持多项数据交换。通过并行执行触发操作,极大地提高了数据吞吐能力,可在更短的时间内完成任务,在满足高性能要求的同时,又减少了功耗。
独立的地址和数据通道。地址和数据通道分开,能对每一个通道进行单独优化,可以根据需要控制时序通道,将时钟频率提到最高,并将延时降到最低。
增强的灵活性。AXI技术拥有对称的主从接口,无论在点对点或在多层系统中,都能十分方便地使用AXI技术。
AXI的应用
编辑 播报
SoC系统中总线的选择不仅要看其性能,还要看其应用范围,更加重要的是,是否有足够的IP核资源可供利用。为了加速基于AXI总线的应用设计,ARM最新发布了面向片内总线AXI的3种IP内核。分别为:二级缓存控制电路L220、输出AXI标准总线的工具PL300以及同步DRAM控制电路PL340。3种产品的供货将加快AXI的普及步伐。3种产品均为可逻辑合成的软核,支持ARM1156T2F-S、ARM1176JZF-S与MPCore三种CPU内核。
这些预先检验的AXI系统元件将协助研发者迅速针对内建ARM11系列处理器的SoC开发出高集成度的产品。AXI系统元件提供一条具备高效率的传输管道,从处理器连接快速缓存、存储控制器及外部存储器。上述优势使ARM11系列处理器即使搭配速度较慢的内存,也可以发挥出相当高的性能。由于CPU与芯片外部存储器之间的通信已成为主要的性能瓶颈,因此设计人员将会视该项技术为极具价值的方案。
二级缓存控制电路L220是面向ARM内核中首款支持二级缓存的电路。二级缓存除可用于个人电脑微处理器等一般用途外,还支持MIPS微处理器等。使用此次二级缓存控制电路、同时配备256kB的二级缓存时,MPEG-4的解码处理所需的时间只相当于没有配备二级缓存时的一半。另外,256kB二级缓存的面积采用台湾TSMC的130nm设计规格、为6mm2,成本大约为0.41美元(约合人民币3.4元)。L220支持ARM的电源电压与工作频率控制技术“IEM”,可有效控制二级缓存的电源电压等。
PL300是一种可以生成具有任意数量主从设备的总线的工具。传送速度在平均每层166MHz工作频率下为1.3GB/秒。使用XML记述主从设备等的设定,就会生成相应总线的设计数据。同步DRAM控制电路PL340配备16位×64位宽的DDR接口。今后将支持DDR2与奇偶校验。L220、PL300与PL340均已开始提供使用授权。只需在签合同时支付授权费用,之后的生产中不必每枚芯片交纳授权费用。
市场格局
编辑 播报
市场上的应用产品基本都是基于 AMBA 2 AHB,基于AXI 和ARM11 的应用产品还比较少,但是AXI 的广泛应用只是一个时间的问题。AXI 片上总线的推出,把SoC 的设计推向了一个新的台阶,设计者可以更加方便快速的设计出高性能SoC
AHB(先进高性能总线)支持多个主控制器,主从模块,CPU DSP DMA等模块控制器类间通信
随着深亚微米工艺技术日益成熟,集成电路芯片的规模越来越大。数字IC从基于时序驱动的设计方法,发展到基于IP核复用的设计方法,并在SOC设计中得到了广泛应用。在基于IP核复用的SoC(System on Chip的缩写,称为系统级芯片,也有称片上系统)设计中,片上总线设计是最关键的问题。为此,业界出现了很多片上总线标准。其中,由ARM公司推出的AMBA片上总线受到了广大IP开发商和SoC系统集成者的青睐,已成为一种流行的工业标准片上结构。AMBA规范主要包括了AHB(Advanced High performance Bus)系统总线和APB(Advanced Peripheral Bus)外围总线。
中文名
高级高性能总线
外文名
Advanced High Performance Bus
背 景
深亚微米工艺技术日益成熟
全 称
Advanced High Performance Bus
简 称
AHB
目录
简介
编辑 播报
AHB=Advanced High Performance Bus,译作高级高性能总线。如同USB(Universal Serial Bus)一样,也是一种总线接口。
AHB主要用于高性能模块(如CPU、DMA和DSP等)之间的连接,作为SoC的片上系统总线,它包括以下一些特性:单个时钟边沿操作;非三态的实现方式;支持突发传输;支持分段传输;支持多个主控制器;可配置32位~128位总线宽度;支持字节、半字和字的传输。AHB 系统由主模块、从模块和基础结构(Infrastructure)3部分组成,整个AHB总线上的传输都由主模块发出,由从模块负责回应。基础结构则由仲裁器(arbiter)、主模块到从模块的多路器、从模块到主模块的多路器、译码器(decoder)、虚拟从模块(dummy Slave)、虚拟主模块(dummy Master)所组成。针对Soc设计中IP复用问题提出了一种新的解决办法。传统的方法是将特定功能模块的非标准接口标准化为AHB主/从设备接口。本文提出了一种新的基于ARM的Soc通用平台设计寄存器总线标准接口,这种设计使整个系统的结构清晰,增强系统的通用性与系统中功能模块的可移植性。
AMBA
编辑 播报
AMBA 2.0规范包括四个部分:AHB、ASB、APB和Test Methodology。AHB的相互连接采用了传统的带有主模块和从模块的共享总线,接口与互连功能分离,这对芯片上模块之间的互连具有重要意义。AMBA已不仅是一种总线,更是一种带有接口模块的互连体系。
APB
编辑 播报
APB主要用于低带宽的周边外设之间的连接,例如UART、1284等,它的总线架构不像AHB支持多个主模块,在APB里面唯一的主模块就是APB 桥。其特性包括:两个时钟周期传输;无需等待周期和回应信号;控制逻辑简单,只有四个控制信号。
1)系统初始化为IDLE状态,此时没有传输操作,也没有选中任何从模块。2)当有传输要进行时,PSELx=1,PENABLE=0,系统进入SETUP状态,并只会在SETUP 状态停留一个周期。当PCLK的下一个上升沿时到来时,系统进入ENABLE 状态。
3)系统进入ENABLE状态时,维持之前在SETUP 状态的PADDR、PSEL、PWRITE不变,并将PENABLE置为1。传输也只会在ENABLE状态维持一个周期,在经过SETUP与ENABLE状态之后就已完成。之后如果没有传输要进行,就进入IDLE状态等待;如果有连续的传输,则进入SETUP状态。
转换
大多数挂在总线上的模块(包括处理器)只是单一属性的功能模块:主模块或者从模块。主模块是向从模块发出读写操作的模块,如CPU,DSP等;从模块是接受命令并做出反应的模块,如片上的RAM,AHB/APB 桥等。另外,还有一些模块同时具有两种属性,例如直接存储器存取(DMA)在被编程时是从模块,但在系统读传输数据时必须是主模块。如果总线上存在多个主模块,就需要仲裁器来决定如何控制各种主模块对总线的访问。虽然仲裁规范是AMBA总线规范中的一部分,但具体使用的算法由RTL设计工程师决定,其中两个最常用的算法是固定优先级算法和循环制算法。AHB总线上最多可以有16个主模块和任意多个从模块,如果主模块数目大于16,则需再加一层结构(具体参阅ARM公司推出的Multi-layer AHB规范)。APB 桥既是APB总线上唯一的主模块,也是AHB系统总线上的从模块。其主要功能是锁存来自AHB系统总线的地址、数据和控制信号,并提供二级译码以产生APB外围设备的选择信号,从而实现AHB协议到APB协议的转换。
APB(通过外设寄存器进行读写访问)
数字IC设计之APB实例解析
2020-06-11 12:21:37阅读 1.5K0
文章共1433字,阐述了AMBA APB协议读写信号状态机转换,以及用一个示例展示了APB协议的读写寄存器。通过和这几个寄存器交互,设计者可以将自定义的模块挂接到基于AMBA总线的SoC系统中。
APB是AMBA中相对比较简单的接口协议,用于连接低带宽,无需高性能流水线接口的外设。采用这种简单的协议,你可以轻松地将自定义外设挂在基于AMBA总线的SoC上。
许多APB外设都是慢速器件,例如UART、I2C等。一般SoC都是通过它们的寄存器进行访问。
APB每次传输至少需要两个周期,所有信号的转换仅在时钟的上升沿发生以便能够轻松地将APB外设集成到其他设计中。
APB还包括用于扩展APB传输的PREADY信号和用于指示传输失败的PSLVERR信号。

在时钟的第一个上升沿,是Setup阶段,地址信号PADDR、数据信号PWDATA、写信号PWRITE和选择信号PSEL开始改变。
在随后的时钟沿之后,使能信号PENABLE拉高,表示进行Access阶段。地址信号PADDR、数据信号PWDATA、写信号PWRITE、选择信号PSEL在整个Access阶段都保持有效。
APB写传输在Access阶段结束时完成。使能信号PENABLE在传输结束时拉低,选择信号PSELx也拉低,除非后面紧接着另一个对该外设的传输。
有等待写传输:

在Access阶段,可以通过拉低PREADY来延长传输,这可确保对某些外设进行多周期访问。
建议在传输后不立即更改地址信号和写信号,在另一次访问之前保持稳定可以降低动态功耗。
无等待读传输:

上图显示了无等待读传输。APB slave必须在读传输结束之前提供数据。
有等待读传输:

上图显示了PREADY信号如何扩展读传输。如果在Access阶段PREADY拉低,则读传输会延长。
下图是AMBA APB的工作流程

IDLE - 这是APB的默认状态。
SETUP- 当需要传输时,总线进入SETUP状态,其中相应的选择信号PSELx被置位。 总线仅在一个时钟周期内保持SETUP状态,并始终在时钟的下一个上升沿移至ACCESS状态。
ACCESS - 使能信号PENABLE在ACCESS状态下被置位。在从SETUP到ACCESS状态的转换期间,PADDR,PWRITE,PSELx和PWDATA信号必须保持稳定。
从ACCESS状态退出由来自APB slave的PREADY信号控制。如果APB slave将PREADY保持为低电平,则总线保持在ACCESS状态。如果APB slave将PREADY驱动为高电平,则退出ACCESS状态。
如果不再需要传输,则总线返回IDLE状态。如果紧跟着另一次传输则总线直接移动到SETUP状态。
根据上面的状态转换图可以很轻松地编写基于FSM的VerilogHDL。
下面是一个非状态机写法的APB slave 的verilog实例,大家可以在此基础上设计自己APB slave接口的自定义模块,将外设挂接到SoC上。
// Sample APB register code// Standard read/write registers// Adress offset:// 0x00 : 32 bit read of status32 register// 0x04 : 32 bit read&write of control32 port// 0x08 : 16 bit read of status16 register// 0x0C : 16 bit read&write of control16 register
module apb_regs ( // system input reset_n, input enable,
// APB input pclk, input [ 3:0] paddr, input pwrite, input psel, input penable, input [31:0] pwdata, output reg [31:0] prdata, output pready, output pslverr,
//Interface // Interface input [31:0] status32, input [15:0] status16, input [31:0] control32_rd, input [15:0] control16_rd, output reg [31:0] control32_wr, output reg [15:0] control16_wr,);...endmodule复制
其中,//system部分接口是系统全局信号用于复位和使能,//APB部分接口是APB协议所需信号。
//Interface部分接口是用于和自定义功能模块的接口寄存器即系统和模块之间交互桥梁。status32和status16全部为只读,control32和control16可读可写。
wire apb_write = psel & penable &pwrite;wire apb_read = psel & ~pwrite;复制
apb_write和apb_read是为了满足APB协议做的读写控制,具体可以查阅APB协议官方文档
assign pready = 1'b1;assign pslverr = 1'b0;复制
该APB slave模块只是对一些控制和状态寄存器进行读写,无等待传输同时不生成传输错误信号。
always @(posedge pclk or negedge reset_n)beginif (!reset_n)begin control32_wr <= 32'h0; control16_wr <= 16'h0; prdata <= 32'h0; end else if (enable) begin if (apb_write) begin case (paddr) //4'h0:status32 read only 4'h4 : control32_wr <= pwdata; //4'h8:status16 read only 4'hC : control16_wr <=pwdata[15:0]; endcase end // write if (apb_read) begin case (paddr) 4'h0: prdata <= status32; 4'h4: prdata <= control32_rd; 4'h8: prdata[15:0] <= status16; 4'hC: prdata[15:0] <=control16_rd; endcase end // read else prdata <= 32'h0; // so we can OR all bussesendend多核CPU运行基础知识及核间通信
多核CPU运行模式主要有以下三种:
•非对称多处理(Asymmetric multiprocessing,AMP)——每个CPU内核运行一个独立的操作系统或同一操作系统的独立实例(instantiation)。
•对称多处理(Symmetric multiprocessing,SMP)——一个操作系统的实例可以同时管理所有CPU内核,且应用并不绑定某一个内核。
•混合多处理(Bound multiprocessing,BMP)——一个操作系统的实例可以同时管理所有CPU内核,但每个应用被锁定于某个指定的核心。
背景介绍:
在开发MCU应用系统时,如果单颗MCU无法满足系统的要求,一个很普遍的做法就是使用两颗或更多的MCU,把一部分“杂项工作”分配给另一个有“助理”性质的低端MCU来完成。但是,采用两颗MCU,缺点也很明显,尤其是在芯片与PCB成本、系统可靠性及功耗方面都有先天的不足。此外,若采用了不同架构的MCU,还要面临需要不同的开发工具与开发人员的挑战。如果换一种思路,让MCU内部包含两个内核,其中一个用于主控,另一个用于协控,并且它们主控与协控在架构上能够向下兼容、高效通信,则在很多场合下都可以既保持多机系统的强大,又能避免多机系统的不足。
事实上,这即是“非对称多处理器(简称AMP)”架构的特点。AMP是与“对称多处理器(简称SMP)”相对的架构,后者各处理器有一致的编程模型,并且在分配工作时主要以均衡为原则。而AMP的优点在于精细的任务分工,灵活地适应不同情景,物尽其用,以最佳地平衡成本、性能与功耗。此外,AMP的编程难度也更低。因此,在MCU应用领域,AMP较SMP更为适合。
与独立的双MCU相比,AMP架构有很多优点。其中相当关键的就是,再添加一个内核的代价远比添加一个独立的MCU要低,尤其是当两个内核架构相似时,甚至仅相当于在现有硅片上再添加一两个UART。另一方面,两个内核可以有相同的主频,并且可以通过总线矩阵平等地访问片上资源。而在分立的双MCU方案中,协控MCU的主频常常远低于主控,并且双方使用低速的串行链路通信。
内核间的通信可分为两类:一类是控制与状态信息的通信,另一类则是数据通信。前者一般不携带数据,但往往有较高的实时要求;后者则主要是各类数据缓冲区,通常实时性要求偏低但数据量大。控制/状态通信有较大的通用性,并且与任务间的同步较为相似。这类通信适合由系统软件实现并提供编程接口。数据通信则往往与具体应用相关较大(尤其是在数据结构上),需要量体裁衣。在实现时,适合由应用软件定义各种数据结构。
内核间通过共享的RAM进行通信,并且每个内核都可以触发对方的一个中断源,通过准备数据-触发中断的方式进行通信。当然,内核也可以不使用中断,定期检查共享RAM的状态。
还可以通过消息队列进行交互…………………………
多核之间环形总线方式
上面的AXI接口也可以















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}