






前言
上传图片/视频/文件是我们经常会遇到的问题,但是一旦图片过大就会导致不好的操作体验。 图片上传是前端中常见的的业务场景。无论是前台还是后台,适当的对图片进行压缩处理, 可以显著的提升用户体验。而在后台管理系统中,图片压缩不仅仅能够提升后台管理员操作体验,更是可以防止后台设置过大的图片导致前台图片加载过久,从而影响用户体验。
关于压缩图片
思考
想想压缩图片基本流程
- input 读取到 文件 ,使用 FileReader 将其转换为 base64 编码
- 新建 img ,使其 src 指向刚刚的 base64
- 新建 canvas ,将 img 画到 canvas 上
- 利用 canvas.toDataURL/toBlob 将 canvas 导出为 base64 或 Blob
- 将 base64 或 Blob 转化为 File
将这些步骤逐个拆解,我们会发现似乎在canvas.toDataURL时涉及到图片质量,那咱们就从这里下手。
准备
HTMLCanvasElement.toDataURL()
HTMLCanvasElement.toDataURL() 方法返回一个包含图片展示的 data URI 。可以使用 type 参数其类型,默认为 PNG 格式。图片的分辨率为96dpi。
- 如果画布的高度或宽度是0,那么会返回字符串“data:,”。
- 如果传入的类型非“image/png”,但是返回的值以“data:image/png”开头,那么该传入的类型是不支持的。
语法
canvas.toDataURL(type, encoderOptions);
参数
- type 可选
图片格式,默认为 image/png
- encoderOptions 可选
在指定图片格式为 image/jpeg 或 image/webp的情况下,可以从 0 到 1 的区间内选择图片的质量。如果超出取值范围,将会使用默认值 0.92。其他参数会被忽略。 Chrome支持“image/webp”类型。
猜想
可能toDataURL(type,quality)的第二个参数(quality)越小,文件体积越小
实践
先看下原图信息大小是7.31kb
toDataURL(type,quality)quality默认0.92看看压缩结果如何
<input id="fileInput" type="file" />
<img id="img" src="" alt="">
复制代码let fileId = document.getElementById('fileInput')
let img = document.getElementById('img')
fileId.onchange = function (e) {
let file = e.target.files[0]
compressImg(file, 0.92).then(res => {//compressImg方法见附录
console.log(res)
img.src = window.URL.createObjectURL(res.file);
})
}
复制代码compressImg方法见附录
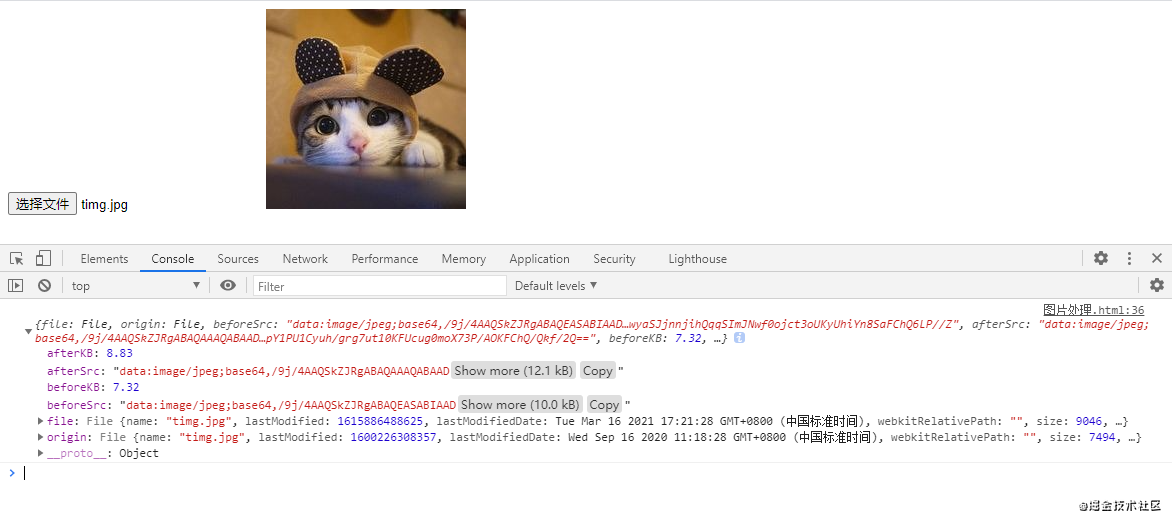 可以看到图片大小为
可以看到图片大小为8.83kb压缩后图片反而变大了,这是怎么回事?
看来起初的猜想不完全正确,咱们继续看看。
fileId.onchange = function (e) {
let file = e.target.files[0]
compressImg(file, 0.1).then(res => {//compressImg方法见附录
console.log(res)
img.src = window.URL.createObjectURL(res.file);
})
}
复制代码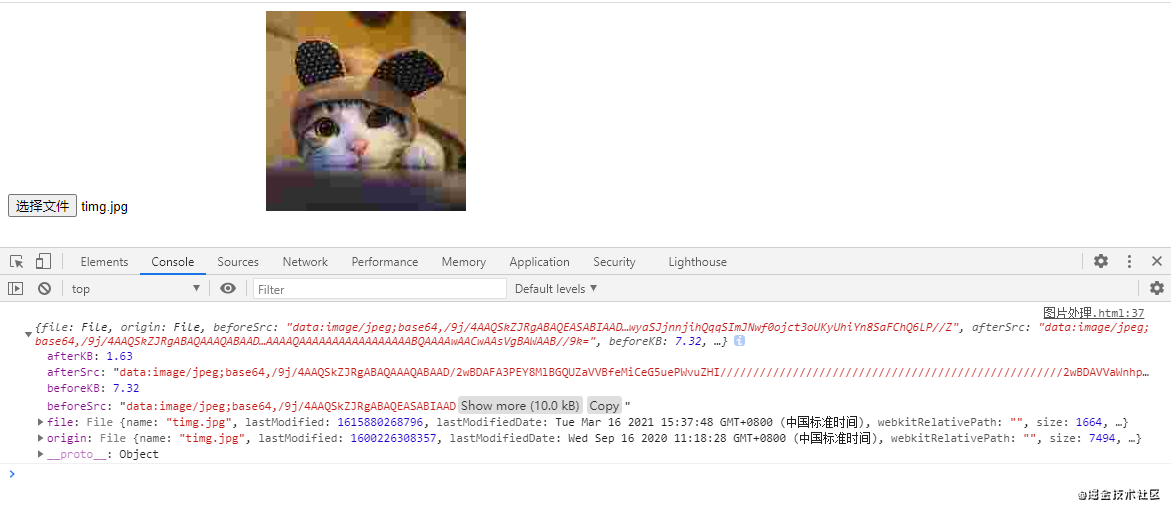 当
当quality为0.1的时候,图片仅有1.63kb,同样的质量也下降了
继续......A long time later
咱们用折线图来看吧更直观
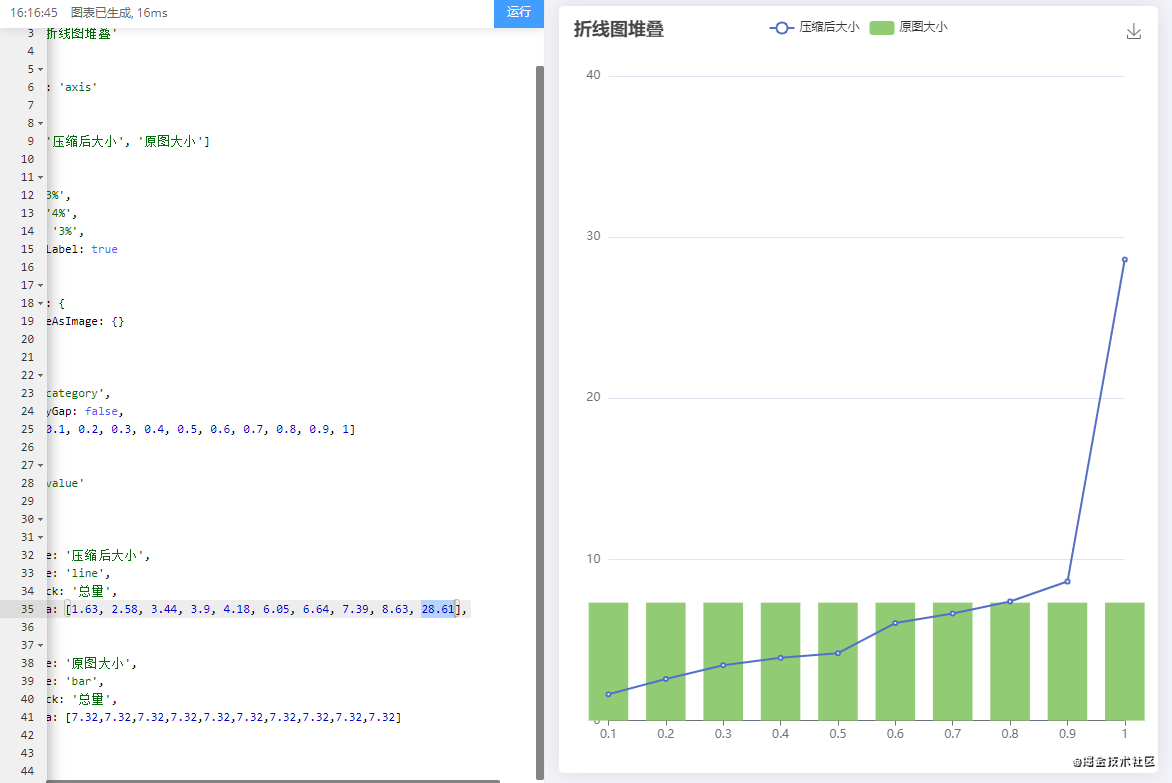 我又拿了几个图片让他们使用默认值0.92,结果都比原图大
我又拿了几个图片让他们使用默认值0.92,结果都比原图大
所以说默认值得到的图片往往比原图大
下面看看当quality为多少时对图片的压缩效率可以最大化
压缩效率最大化,即:在不影响图片质量的情况下最大化压缩
尝试了一系列的图片之后我发现 当quality在0.2~0.5之间,图片质量变化并不大,quality的值越小,压缩效率越可观(也就是在0.2左右时,压缩图片可以最大化,同时并不对图片质量造成太大影响)
结论
经过实践,可以得出结论这个默认值得到的图片往往比原图的图片质量要高。
当quality在0.2~0.5之间,图片质量变化并不大,quality的值越小,压缩效率越可观(也就是在0.2左右时,压缩图片可以最大化,同时并不对图片质量造成太大影响)
附录
/**
* 压缩方法
* @param {string} file 文件
* @param {Number} quality 0~1之间
*/
function compressImg(file, quality) {
if (file[0]) {
return Promise.all(Array.from(file).map(e => compressImg(e,
quality))) // 如果是 file 数组返回 Promise 数组
} else {
return new Promise((resolve) => {
const reader = new FileReader() // 创建 FileReader
reader.onload = ({
target: {
result: src
}
}) => {
const image = new Image() // 创建 img 元素
image.onload = async () => {
const canvas = document.createElement('canvas') // 创建 canvas 元素
canvas.width = image.width
canvas.height = image.height
canvas.getContext('2d').drawImage(image, 0, 0, image.width, image.height) // 绘制 canvas
const canvasURL = canvas.toDataURL('image/jpeg', quality)
const buffer = atob(canvasURL.split(',')[1])
let length = buffer.length
const bufferArray = new Uint8Array(new ArrayBuffer(length))
while (length--) {
bufferArray[length] = buffer.charCodeAt(length)
}
const miniFile = new File([bufferArray], file.name, {
type: 'image/jpeg'
})
resolve({
file: miniFile,
origin: file,
beforeSrc: src,
afterSrc: canvasURL,
beforeKB: Number((file.size / 1024).toFixed(2)),
afterKB: Number((miniFile.size / 1024).toFixed(2))
})
}
image.src = src
}
reader.readAsDataURL(file)
})
}
}
复制代码优化升级
使用过程中发现边界问题,即图片尺寸过大、 IOS 尺寸限制,png 透明图变黑等问题
所以优化了大尺寸图片等比例缩小,这极大的提高了压缩效率
举个栗子,以一张大小14M,尺寸6016X4016的图片为例
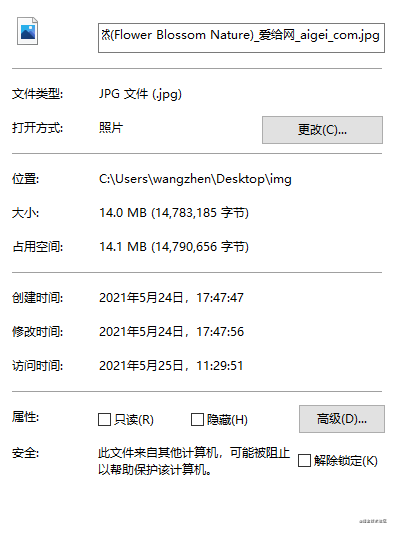
一个14M的原图(6016X4016)不改变质量只改变尺寸的前提下压缩后(1400X935)就剩139.62KB
可想而知,尺寸的限制能最大化提高压缩效率

/**
* 压缩图片方法
* @param {file} file 文件
* @param {Number} quality 图片质量(取值0-1之间默认0.92)
*/
compressImg(file, quality) {
var qualitys = 0.52
console.log(parseInt((file.size / 1024).toFixed(2)))
if (parseInt((file.size / 1024).toFixed(2)) < 1024) {
qualitys = 0.85
}
if (5 * 1024 < parseInt((file.size / 1024).toFixed(2))) {
qualitys = 0.92
}
if (quality) {
qualitys = quality
}
if (file[0]) {
return Promise.all(Array.from(file).map(e => this.compressImg(e,
qualitys))) // 如果是 file 数组返回 Promise 数组
} else {
return new Promise((resolve) => {
console.log(file)
if ((file.size / 1024).toFixed(2) < 300) {
resolve({
file: file
})
} else {
const reader = new FileReader() // 创建 FileReader
reader.onload = ({
target: {
result: src
}
}) => {
const image = new Image() // 创建 img 元素
image.onload = async() => {
const canvas = document.createElement('canvas') // 创建 canvas 元素
const context = canvas.getContext('2d')
var targetWidth = image.width
var targetHeight = image.height
var originWidth = image.width
var originHeight = image.height
if (1 * 1024 <= parseInt((file.size / 1024).toFixed(2)) && parseInt((file.size / 1024).toFixed(2)) <= 10 * 1024) {
var maxWidth = 1600
var maxHeight = 1600
targetWidth = originWidth
targetHeight = originHeight
// 图片尺寸超过的限制
if (originWidth > maxWidth || originHeight > maxHeight) {
if (originWidth / originHeight > maxWidth / maxHeight) {
// 更宽,按照宽度限定尺寸
targetWidth = maxWidth
targetHeight = Math.round(maxWidth * (originHeight / originWidth))
} else {
targetHeight = maxHeight
targetWidth = Math.round(maxHeight * (originWidth / originHeight))
}
}
}
if (10 * 1024 <= parseInt((file.size / 1024).toFixed(2)) && parseInt((file.size / 1024).toFixed(2)) <= 20 * 1024) {
maxWidth = 1400
maxHeight = 1400
targetWidth = originWidth
targetHeight = originHeight
// 图片尺寸超过的限制
if (originWidth > maxWidth || originHeight > maxHeight) {
if (originWidth / originHeight > maxWidth / maxHeight) {
// 更宽,按照宽度限定尺寸
targetWidth = maxWidth
targetHeight = Math.round(maxWidth * (originHeight / originWidth))
} else {
targetHeight = maxHeight
targetWidth = Math.round(maxHeight * (originWidth / originHeight))
}
}
}
canvas.width = targetWidth
canvas.height = targetHeight
context.clearRect(0, 0, targetWidth, targetHeight)
context.drawImage(image, 0, 0, targetWidth, targetHeight) // 绘制 canvas
const canvasURL = canvas.toDataURL('image/jpeg', qualitys)
const buffer = atob(canvasURL.split(',')[1])
let length = buffer.length
const bufferArray = new Uint8Array(new ArrayBuffer(length))
while (length--) {
bufferArray[length] = buffer.charCodeAt(length)
}
const miniFile = new File([bufferArray], file.name, {
type: 'image/jpeg'
})
console.log({
file: miniFile,
origin: file,
beforeSrc: src,
afterSrc: canvasURL,
beforeKB: Number((file.size / 1024).toFixed(2)),
afterKB: Number((miniFile.size / 1024).toFixed(2)),
qualitys: qualitys
})
resolve({
file: miniFile,
origin: file,
beforeSrc: src,
afterSrc: canvasURL,
beforeKB: Number((file.size / 1024).toFixed(2)),
afterKB: Number((miniFile.size / 1024).toFixed(2))
})
}
image.src = src
}
reader.readAsDataURL(file)
}
})
}
},
作者:凉城a
链接:https://juejin.cn/post/6940430496128040967
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。














 552
552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









