







通常我们想在一个字符串中匹配一个子字符串,会遍历字符串,对于每一个字符,都遍历子字符串进行匹配,这样时间复杂度为O(nm);
使用KMP算法只需先进行一个O(m)的预处理(生成next数组),就能将搜索的时间复杂度降低至O(n+m)。下面讲一讲KMP算法的实现原理。
对于ABCDEABD...和ABCDEABC,当匹配至最后一位是发现不匹配,之前的ABCDEAB都是匹配的,这段字符串包含有哪些信息?即相同的前缀AB和后缀AB,这样,下一次移动子字符串可以直接移至下一个AB进行匹配,移动了7-2位(7是匹配的字符串长度,2是匹配的前缀后缀长度),而next数组就是表示匹配前缀后缀长度的数组。
搜索词 A B C D A B D
next 0 0 0 0 1 2 0
"A"的前缀和后缀都为空集,共有元素的长度为0;
"AB"的前缀为[A],后缀为[B],共有元素的长度为0;
"ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
"ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
"ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
"ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
"ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
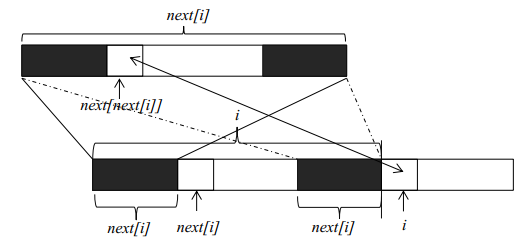
next数组计算
理解了kmp算法的基本原理,下一步就是要获得字符串f每一个位置的最大公共长度。这个最大公共长度在算法导论里面被记为next数组。在这里要注意一点,next数组表示的是长度,下标从1开始;但是在遍历原字符串时,下标还是从0开始。假设我们现在已经求得next[1]、next[2]、……next[i],分别表示长度为1到i的字符串的前缀和后缀最大公共长度,现在要求next[i+1]。由上图我们可以看到,如果位置i和位置next[i]处的两个字符相同(下标从零开始),则next[i+1]等于next[i]加1。如果两个位置的字符不相同,我们可以将长度为next[i]的字符串继续分割,获得其最大公共长度next[next[i]],然后再和位置i的字符比较。这是因为长度为next[i]前缀和后缀都可以分割成上部的构造,如果位置next[next[i]]和位置i的字符相同,则next[i+1]就等于next[next[i]]加1。如果不相等,就可以继续分割长度为next[next[i]]的字符串,直到字符串长度为0为止。
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
String str = "ABCDABD";
int[] next = getNext(str);
String s = "ABCDABEABCDABABCABDAB";
int count = 0;
int i = 0;
while (i < s.length()) {
int tmp = i;
count = 0;
if (s.charAt(tmp) != str.charAt(count)) {
i++;
continue;
}
while (tmp < s.length()&&s.charAt(tmp) == str.charAt(count)) {
count++;
tmp++;
if (count == str.length()) {
System.out.println("match");
return;
}
}
i += count - next[count];
}
System.out.println("not match");
}
public static int[] getNext(String str) {
int len = str.length();
int[] next = new int[len + 1];
next[0] = next[1] = 0;
int j = 0;
for (int i = 1; i < len; i++) {
j = next[i];
while (j > 0 && str.charAt(i) != str.charAt(j))
j = next[j];
if (str.charAt(i) == str.charAt(j))
j++;
next[i + 1] = j;
}
return next;
}
}















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









