







最近稍微学习了部分有关服务雪崩的知识,所以便有了这篇博客来着~
服务雪崩,是指:
由于一个或多个服务的不可用或响应时间过长,导致系统中的多个服务相继出现不可用或响应时间过长的情况,最终导致整个系统瘫痪的现象.
这样说起来确实略显抽象,所以我们看看这张图:

从这张一点都不抽象的图片上,易得存在一条Service A到Service B到Service C的调用链
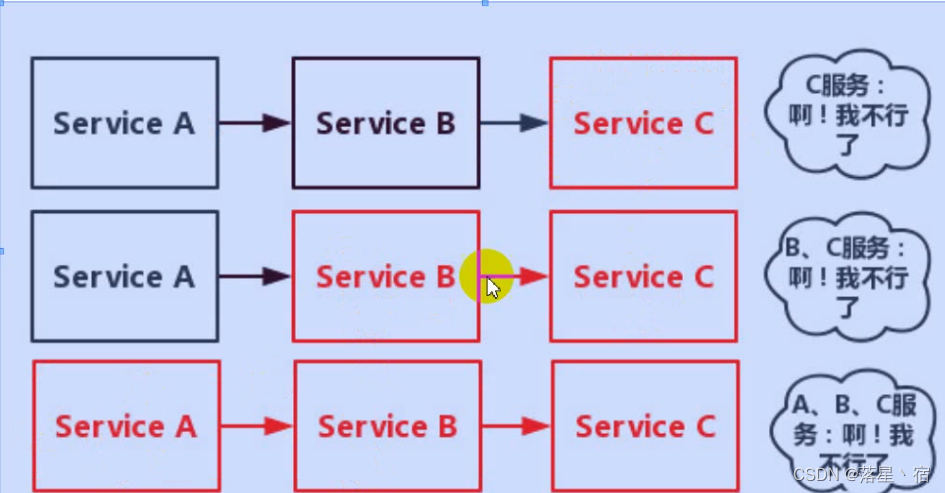
而因为某种原因,当Service C变得不可用时,Service B的请求也会相应的阻塞.而随着阻塞的积累,B的资源会逐渐消耗殆尽,Service B自然也会变得不可用,之后的Service A也自然逃不过不可用的命运.
这样一个服务失败,最后导致整个链路上所有服务都失败的情况,就叫做服务雪崩.
知道了服务雪崩的概念,那我们自然需要了解服务雪崩出现的原因,而说起原因,又不得不提一下雪崩的三个阶段:
阶段一:单个服务的异常或不可用
这个阶段出现的原因可能是多种多样的,有可能是硬件故障(关我们程序员什么事.jpg),有可能是程序bug,亦有可能是用户大量请求,缓存击穿之类的~
阶段二:其他服务开始尝试重新连接到出现问题的服务,从而导致这些服务也变得不可用或响应时间过长
(PS:这个过程既有用户发现服务不可用疯狂刷新,也有代码相关逻辑(未设置好相关配置)重试,但不论如何,这加重了服务的负载)
阶段三:由于不断尝试重新连接和重试,导致负载进一步增加,最终导致所有依赖服务的服务都无法正常工作,整个系统出现瘫痪。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2103
2103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









