







一、CAP介绍
-
C(Consistency):一致性,也就是写入什么,读出来什么。这就要求:主从之间的数据实现一致性,这里指的是partition的leader 和 flower之间的一致性
强一致性: 如果数据更新后,并发访问情况下可立即感知 ==> 监听器、leader轮询通知 最终一致如果之后一段时间后,一定可以感知该更新 ==> flower定时来拉取 弱一致:允许很长时间之后才同步 -
A(Availability):可用性。集群能确保在一定时间内相应请求
-
P(Partition tolerance):分区容错性。由于网络原因,分区之间
-
的通信(同步)可能会失败,这种情况需要考虑到并且解决。
Kafka CAP矛盾 ==> C 和 A的矛盾
-
1、CAP最多只能实现其中两点,其中P是肯定是要实现的,所以只能在C 和 A之间做取舍。一个框架,要么是CP,要么是AP。
-
2、要想实现强一致性,leader接受到数据之后,就必须等到所有replica同步过去之后才能响应procuder ack。如果replication同步失败,则leader无法响应ack,这就没法实现可用性(A)。

-
3、反之亦然
二、kafka 使用ISR实现C 和 A之间的平衡
-
1、kafka对每一个partition都会在zookeeper上维护一个ISR列表记录着那些和leader同步非常及时的replication,这样只要这些副本同步成功了,就可以响应producer的ACK。
-
2、问题? 如果leader失败了,一个未完全同步数据的replication被选择为了leader,那岂不是数据丢失?不一致?
答案:是的,这种情况可以保证可用性,但是不能保证一致性 这里有一个参数可以指定只允许ISR中的replication作为leader来保证一致性 unclean.leader.election.enable=false 同样的,如果ISR中的replication都不能启动,就会一直没有leader,没法对外服务 也就是虽然保证了一致性,但是就会丢失了可用性
三、原理详解
-
1、关于参数
-
1.1、broker端参数
replication.factor:partition副本数量 unclean.leader.election.enable:leader挂了之后,如何选举leader -
1.2Topic配置,创建topic时指定
min.insync.replicas = 1:ISR中至少有多少个分区 -
1.3、producer端参数
request.required.asks = 0:不确认,发了就完事,没有可靠性 request.required.asks = 1:leader收到数据就返回ack确认,不能保证flower同步,可能会丢失 request.required.asks = -1:要求leader和ISR表中的flower都同步完成才向producer返回ack确 认,安全性最高,性能最低 retries:如果没有ack相应,失败之后重试的次数
-
-
2、关于作用
-
2.1、producer设置ack的作用
producer的request.required.asks = -1只有设置为 -1时,才会涉及到leader和flower之间同步的 问题,而0和1参数都不需要等待flower同步。 由于有的flower挂了、或者同步速度很慢,如果leader需要等到所有flower都同步完成才向producer相应 ack,黄花菜都凉了,所以leader在zookeeper的/broker/topics/{topic}/partitions/ {partition}/state下维护了一个ISR列表来记录那些同步及时的flower,加快ack相应时间,格式为: {"controller_epoch":18,"leader":-1,"version":1,"leader_epoch":86,"isr":[]}。 -
2.2、ISR剔除和加入的规则参数
rerplica.lag.time.max.ms=10000 如果leader发现flower超过10秒没有向它发起fech请求,那么leader考虑这个flower是不是程序出了点 问题或者资源紧张调度不过来,它太慢了,不希望它拖慢后面的进度,就把它从ISR中移除。 rerplica.lag.max.messages=4000 相差4000条就移除,flower慢的时候,保证高可用性,同时满足这两个条件后又加入ISR中,在可用性与一 致性做了动态平衡 亮点 -
2.3、leader的选举参数unclean.leader.election.enable
- true:第一个flower启动设置为leader,可用性高,一致性低。如果是ISR之外的flower作为leader,那么ISR的flower offset会比这个leader要大,需要进行删除,和新leader一直后才能进行同步会丢2、3、4、5这几条数据
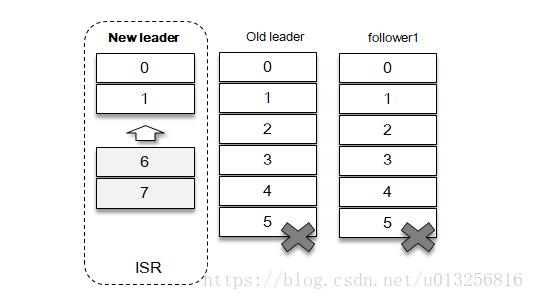
- false:一定要ISR中的flower启动才设置为leader,可用性低,一致性高。ISR的数据和原来Leader一致,所以不会丢数据,flower继续同步即可。kafka 0.11之后将原来的默认值true改为false,提高了一致性
-















 2517
2517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









