






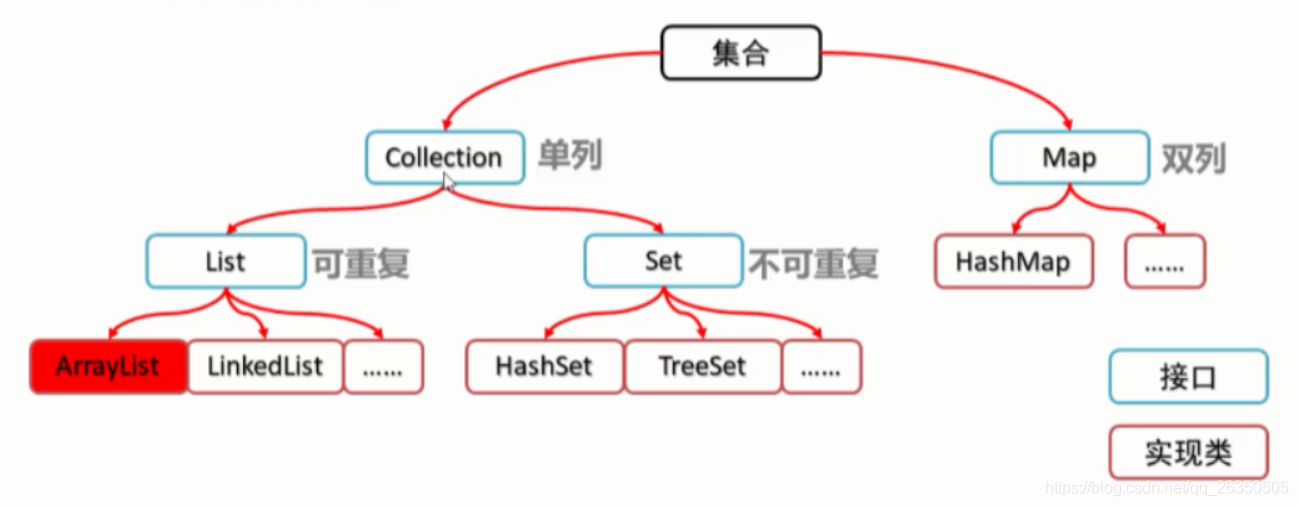
集合
在java中,我们常常需要存放多个数据,这时我们常常想到用数组来存放,但如果需要存放的数据是不同类型的数据或者数据个数未知的,数组就无能为力了.这时使用集合来存放数据就解决了这些问题.
集合和数组比起来:
1.数组的长度是固定的,集合的长度是可变的.
2.数组只能存储同类型的对象,集合可以存储不同类型的对象.
3.集合只能存储对象,不能存储基本数据类型.(系统会自动将基本数据类型封装成对应的包装类型存储)
Collection
Collection是所有单列集合的父接口,在Collection中定义了单例集合(List和Set)的一些通用的方法,这些方法可以操作所有的单列集合.
常用方法:
public boolean add(E e):把给定的对象添加到当前集合中.
Collection<String> collection = new ArrayList<>();
System.out.println(collection.add("abc")); //true
public void clear():清空集合中所有的元素.
Collection<String> collection = new ArrayList<>();
collection.clear();
System.out.println(collection); //[]
public boolean remove(E e): 把给定的对象在当前集合中删除.
Collection<String> collection = new ArrayList<>();
collection.add("abc");
collection.remove("abc");
System.out.println(collection); //[]
public boolean contains(Object obj): 判断当前集合中是否包含给定的对象.
Collection<String> collection = new ArrayList<>();
collection.add("abc");
System.out.println(collection.contains("a")); //false
System.out.println(collection.contains("abc")); //true ("abc"为一个对象)
public boolean isEmpty(): 判断当前集合是否为空.
Collection<String> collection = new ArrayList<>();
System.out.println(collection.isEmpty()); //true
collection.add("abc");
System.out.println(collection.isEmpty()); //false
public int size(): 返回集合中元素的个数.
Collection<String> collection = new ArrayList<>();
System.out.println(collection.size()); //o
collection.add("abc");
System.out.println(collection.size()); //1
public Object[] toArray(): 把集合中的元素,存储到数组中.
Collection<String> collection = new ArrayList<>();
collection.add("abc");
collection.add("123");
collection.add("@#$%");
System.out.println(Arrays.toString(collection.toArray())); //[abc, 123, @#$%]
Collection的遍历
- for增强(foreach)遍历(底层是依靠Iterator迭代器实现的)
Collection<String>collection=new ArrayList<>();
collection.add("a");
collection.add("b");
collection.add("c");
for (String s : collection) {
System.out.print(s+" "); //a b c
}
- 迭代器遍历
Collection<String> collection = new ArrayList<>();
collection.add("a");
collection.add("b");
collection.add("c");
Iterator<String> iterator = collection.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next()+" "); //a b c
}
- 注意事项
在遍历过程中不允许对集合进行增删操作,否则会出现IllegalStateException异常
Collection<String> collection = new ArrayList<>();
collection.add("a");
collection.add("b");
collection.add("c");
Iterator<String> iterator = collection.iterator();
for (String s : collection) {
if(s.equals("a")){
iterator.remove(); //IllegalStateException
}
}
正确对集合增删操作的方法:
Collection<String> collection = new ArrayList<>();
collection.add("a");
collection.add("b");
collection.add("c");
Iterator<String> iterator = collection.iterator();
while (iterator.hasNext()){
String next = iterator.next();
if(next.equals("a")){
iterator.remove();
}
}
System.out.println(collection); //[b, c]
Collections常用方法
public static void shuffle(List<?> list):打乱集合顺序.
List<Integer>list=new ArrayList<>();
list.add(10);
list.add(20);
list.add(30);
Collections.shuffle(list);
System.out.println(list); //[20, 10, 30]
public static <T> void sort(List<T> list):将集合中元素按照默认规则排序.(在对应的类中已定义好默认排序规则)
List<Integer>list=new ArrayList<>();
list.add(20);
list.add(30);
list.add(10);
Collections.sort(list);
System.out.println(list); //[10, 20, 30]
public static <T> void sort(List<T> list,Comparator<? super T> com ):将集合中元素按照指定规则排序.
List<Integer> list = new ArrayList<>();
list.add(20);
list.add(30);
list.add(10);
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer integer, Integer t1) {
return t1 - integer; //t1 - integer 为降序
} //integer - t1 为升序
});
System.out.println(list); //[30, 20, 10]
List
List接口是Collection接口的子接口具备Collection的所有方法.将实现了List接口的对象称为List集合.
List接口的特点:
- 它是一个元素存取有序的集合.取出元素的顺序跟存入元素时的顺序相同.
- 它带有索引.可以通过索引精确地操作集合中的元素.
- 它允许集合中的元素重复.
常用方法: List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法.
public void add(int index, E element):将指定的元素,添加到该集合中的指定位置上.
List<String> list = new ArrayList<>();
list.add("a");
list.add("c");
list.add(1,"b");
System.out.println(list); //[a, b, c]
public E get(int index):返回集合中指定位置的元素。
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
System.out.println(list.get(1)); //b
public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
System.out.println(list.remove(1)); //b
System.out.println(list); //[a]
public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
System.out.println(list.set(1,"c")); //b
System.out.println(list); //[a, c]
ArrayList
ArrayList集合数据存储的结构是数组结构,所以它查询快,而在对集合进行增删操作时,由于集合是有序的,对应操作元素之后的元素都要向前或向后移动,它的底层是有一定容量的,若容量不足还会创建一个新的容量足够的ArrayList集合再将元素拷贝到新集合中.所以它增删慢.它用来查询数据、遍历数据是比较合适的.
LinkedList
LinkedList集合数据存储的结构是链表结构,在查询元素的时候底层会判断index离链头还是链尾更近,用来确定正向还是反向遍历,并找到该index对应的元素,所以它查询慢,而在对集合进行增删操作时,由于它是双向链表结构,只需要将被操作元素和它前后元素的引用关系修改就完成了.所以它增删快.如果要对集合中的数据进行大量的增删操作,用LinkedList会更好.
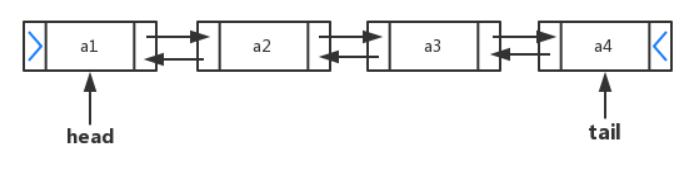
LinkedList是List的子类,List中的方法LinkedList都是可以使用,它还提供了大量首尾操作的方法.
public void addFirst(E e):将指定元素插入此列表的开头.
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("b");
System.out.println(linkedList); //[b]
linkedList.addFirst("a");
System.out.println(linkedList); //[a, b]
public void addLast(E e):将指定元素添加到此列表的结尾.
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("b");
System.out.println(linkedList); //[b]
linkedList.addLast("a");
System.out.println(linkedList); //[b, a]
public E getFirst():返回此列表的第一个元素.
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("a");
linkedList.add("b");
System.out.println(linkedList.getFirst()); //a
public E getLast():返回此列表的最后一个元素.
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("a");
linkedList.add("b");
System.out.println(linkedList.getLast()); //b
public E removeFirst():移除并返回此列表的第一个元素.
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("a");
linkedList.add("b");
System.out.println(linkedList.removeFirst()); //a
public E removeLast():移除并返回此列表的最后一个元素.
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("a");
linkedList.add("b");
System.out.println(linkedList.removeLast()); //b
public E pop():从此列表所表示的堆栈处弹出一个元素.
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("a");
linkedList.add("b");
System.out.println(linkedList.pop()); //a
System.out.println(linkedList); //[b]
public void push(E e):将元素推入此列表所表示的堆栈.
同1.public void addFirst(E e):将指定元素插入此列表的开头.public boolean isEmpty():如果列表不包含元素.则返回true.
LinkedList<String> linkedList = new LinkedList<>();
System.out.println(linkedList.isEmpty()); //true
linkedList.add("a");
System.out.println(linkedList.isEmpty()); //false
Set
Set接口继承了Collection接口,也继承了它的所有方法,实现了Set接口的类叫做Set集合.
Set接口的特点:
元素无索引,元素存取无序,元素不可重复.
HashSet
HashSet保证元素唯一的原理: 它的底层是哈希表结构,哈希表保证元素唯一依赖于hashCode()和equals()方法.
当HashSet集合存储元素时,就会调用该元素的hashCode方法计算哈希值,然后判断该哈希值位置上是否有相同哈希值的元素,如果没有就直接存储,如果有就产生了哈希冲突,这时就会调用该元素的equals方法与该哈希值位置上的元素一一进行比较,如果该位置上有任一元素与该元素相同,就不存储,如果该位置上所有元素都与该元素不同,就直接存储.
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的元素不可重复性.
import java.util.*;
class Person {
private String name;
private String job;
public Person(String name, String job) {
this.name = name;
this.job = job;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(name, person.name) &&
Objects.equals(job, person.job);
}
@Override
public int hashCode() {
return Objects.hash(name, job);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", job='" + job + '\'' +
'}';
}
}
public class Demo {
public static void main(String[] args) {
Person p1 = new Person("张三", "老师");
Person p2 = new Person("李四", "医生");
Person p3 = new Person("李四", "医生");
HashSet<Person> hashSet = new HashSet<>();
hashSet.add(p1);
hashSet.add(p2);
hashSet.add(p3);
System.out.println(hashSet); //[Person{name='李四', job='医生'}, Person{name='张三', job='老师'}]
System.out.println(p1.hashCode()); //25062431
System.out.println(p2.hashCode()); //26795352
System.out.println(p3.hashCode()); //26795352
}
}
LinkedHashSet
LinkedHashSet是链表和哈希表组合的一个数据存储结构,使用它可以保证元素取出时的顺序和存入时相同.
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
linkedHashSet.add("a");
linkedHashSet.add("c");
linkedHashSet.add("b");
for (String s : linkedHashSet) {
System.out.print(s+" "); //a c b
}
HashSet<String> hashSet = new HashSet<>();
hashSet.add("a");
hashSet.add("c");
hashSet.add("b");
for (String s : hashSet) {
System.out.print(s+" "); //a b c
}
TreeSet
TreeSet集合是Set接口的一个实现类,底层依赖于TreeMap,是一种基于红黑树的实现,它元素唯一,元素没有索引,使用元素的自然顺序对元素进行排序,或者根据创建时提供的Comparator进行排序.
TreeSet<Integer> treeSet1 = new TreeSet<>();
treeSet1.add(3);
treeSet1.add(1);
treeSet1.add(2);
System.out.println(treeSet1); //[1, 2, 3]
TreeSet<Integer> treeSet2 = new TreeSet<>(new Comparator<Integer>() {
@Override
public int compare(Integer integer, Integer t1) {
return t1 - integer; //t1 - integer为降序
} //integer - t1为升序
});
treeSet2.add(3);
treeSet2.add(1);
treeSet2.add(2);
System.out.println(treeSet2); //[3, 2, 1]
Map
Map接口是所有双列集合的顶层父接口.Map<K,V> K用来限制键的类型,V用来限制值的类型.
- Map集合存储元素是以键值对的形式存储,也就是说每一个键值对都有键和值
- 通过键取值
- Map集合中的键不能重复,如果键重复了,那么值就会被覆盖.
- Map集合中的值是可以重复的.
常用方法:
public V put(K key, V value):把指定的键与指定的值添加到Map集合中.
Map<String,Integer>map=new HashMap<>();
map.put("张三",18);
System.out.println(map); //{张三=18}
public V remove(Object key):把指定的键所对应的键值对元素在Map集合中删除,返回被删除元素的值.
Map<String,Integer>map=new HashMap<>();
map.put("张三",18);
map.put("李四",19);
System.out.println(map.remove("张三")); //18
System.out.println(map); //{李四=19}
public V get(Object key):根据指定的键,在Map集合中获取对应的值.
Map<String,Integer>map=new HashMap<>();
map.put("张三",18);
map.put("李四",19);
System.out.println(map.get("张三")); //18
public boolean containsKey(Object key):判断该集合中是否有此键
Map<String,Integer>map=new HashMap<>();
map.put("张三",18);
System.out.println(map.containsKey("张三")); //true
System.out.println(map.containsKey("李四")); //false
public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中.
Map<String,Integer>map=new HashMap<>();
map.put("张三",18);
map.put("李四",19);
map.put("王五",20);
Set<String> keys = map.keySet();
System.out.println(keys); //[李四, 张三, 王五]
public Collection<V> values()获取Map集合中所有的值,存储到Collection集合中.
Map<String,Integer>map=new HashMap<>();
map.put("张三",18);
map.put("李四",19);
map.put("王五",20);
Collection<Integer> values = map.values();
System.out.println(values); //[19, 18, 20]
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合).
Map<String, Integer> map = new HashMap<>();
map.put("张三", 18);
map.put("李四", 19);
map.put("王五", 20);
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
System.out.println(entrySet); //[李四=19, 张三=18, 王五=20]
Map的遍历
- for增强(foreach)遍历(底层是依靠Iterator迭代器实现的)
Map<String, Integer> map = new HashMap<>();
map.put("张三", 18);
map.put("李四", 19);
map.put("王五", 20);
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
for (Map.Entry<String, Integer> entries : entrySet) {
System.out.print(entries+" "); //李四=19 张三=18 王五=20
}
- 迭代器遍历
Map<String, Integer> map = new HashMap<>();
map.put("张三", 18);
map.put("李四", 19);
map.put("王五", 20);
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
for (Map.Entry<String, Integer> entries : entrySet) {
String key = entries.getKey();
Integer value = entries.getValue();
System.out.print(key+"="+value+" "); //李四=19 张三=18 王五=20
}
HashMap
键唯一,键值对存取无序, 由哈希表保证键唯一.
HashMap<String,Integer> HashMap =new HashMap<>();
HashMap.put("张三",18);
HashMap.put("李四",19);
HashMap.put("王五",20);
System.out.println(HashMap); //{李四=19, 张三=18, 王五=20}
LinkedHashMap
键唯一,键值对存取有序(取出顺序与存入顺序一致),由哈希表保证键唯一,由链表保证键值对存取有序.
LinkedHashMap<String,Integer>linkedHashMap=new LinkedHashMap<>();
linkedHashMap.put("张三",18);
linkedHashMap.put("李四",19);
linkedHashMap.put("王五",20);
System.out.println(linkedHashMap); //{张三=18, 李四=19, 王五=20}
TreeMap
键唯一,可以对键值对进行排序.
TreeMap集合和Map相比没有特有的功能,底层的数据结构是红黑树,可以对元素的键进行排序,排序方式有两种:自然排序和比较器排序,到时使用的是哪种排序,取决于我们在创建对象的时候所使用的构造方法.
TreeMap<Integer, String> treeMap1 = new TreeMap<>();
treeMap1.put(1, "张三");
treeMap1.put(2, "李四");
treeMap1.put(3, "张三");
System.out.println(treeMap1); //{1=张三, 2=李四, 3=张三}
TreeMap<Integer, String> treeMap2 = new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer integer, Integer t1) {
return t1 - integer; //t1 - integer为降序
} //integer - t1为升序
});
treeMap2.put(1, "张三");
treeMap2.put(2, "李四");
treeMap2.put(3, "张三");
System.out.println(treeMap2); //{3=张三, 2=李四, 1=张三}















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









