







java开发实现读取word 文件内容
目录
一、实现功能
1.java读取word文档内容,兼容doc和docx(不含图片、表格不带格式)
2.java读取docx文档内容的两种方式
3.java读取docx文档内容转HTML(手动编写格式)(后缀名为docx)
4.java读取docx文档内容中表格跨列合并问题的解决方法
5.java读取word文档内容(含图片、表格手动编写格式)
二、具体实现
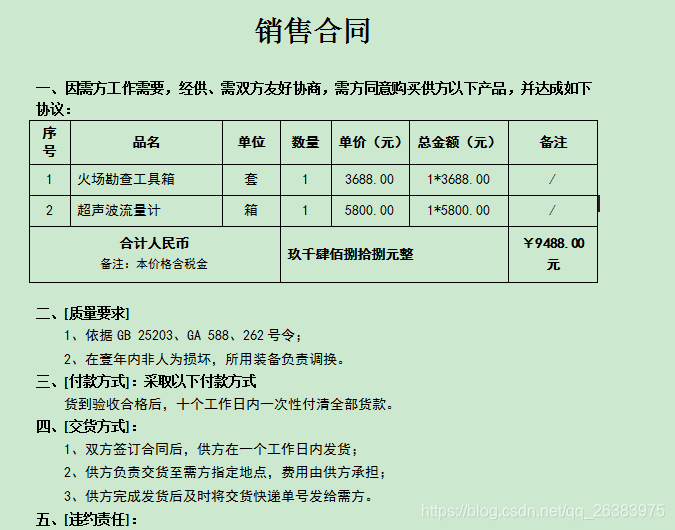
word文件内容:

1.添加必要依赖
<!-- poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>4.0.0</version>
</dependency>
<!-- 对JSP的支持 -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
</dependency>
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
</dependency>
2.代码实现
2.1 功能1:java读取word文档内容,兼容doc和docx
(1)创建controller,编写读取方法:
package com.example.filedemo.controller;
import java.io.File;
import java.io.FileInputStream;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.poi.hwpf.extractor.WordExtractor;
import org.apache.poi.xwpf.extractor.XWPFWordExtractor;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.ModelAndView;
import com.example.filedemo.common.wordUtil.WordRead;
/**
* word、pdf等文件读取
* @author Administrator
*
*/
/**
* @author Administrator
*
*/
@RequestMapping("/auth/readFile/")
@RestController
public class ReadFileController {
/**
* 首页
*/
@RequestMapping(value ="/index")
public ModelAndView toIndex(HttpServletRequest request){
return new ModelAndView("readFile/index");
}
/**
* 读取Word中的文档内容(doc\docx)不带格式
*/
@RequestMapping(value ="/readWordFile")
public Map<String,Object> readWordFile(HttpServletRequest request,HttpServletResponse response){
Map<String,Object> result = new HashMap<String, Object>();
//word文件地址放在src/main/webapp/下
//表示到项目的根目录(webapp)下,要是想到目录下的子文件夹,修改"/"即可
String path = request.getSession().getServletContext().getRealPath("/");
//String filePath = path+"template/w1.doc";
String filePath = path+"template/wp.docx";
String suffixName = filePath.substring(filePath.lastIndexOf("."));//从最后一个.开始截取。截取fileName的后缀名
try {
File file = new File(filePath);
FileInputStream fs = new FileInputStream(file);
if(suffixName.equalsIgnoreCase(".doc")){
//doc
StringBuilder result2 = new StringBuilder();
WordExtractor re = new WordExtractor(fs);
result2.append(re.getText());//获取word中的文本内容
re.close();
result.put("content", result2.toString());
}else{
//docx
XWPFDocument doc = new XWPFDocument(fs);
XWPFWordExtractor extractor = new XWPFWordExtractor(doc);
String text = extractor.getText();//获取word中的文本内容
extractor.close();
fs.close();
result.put("content", text);
}
}catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
(2)编写页面调用方法
<div class="m2">一:读取<span class="s1">Word文档内容</span>(doc\docx)</div>
<a href="#" class="easyui-linkbutton" onclick="doReadFile1();" data-options="iconCls:'icon-save'">读取Word文档内容(不带格式)</a>
<div id="wordDiv" style="display: block;margin-left: 16px;">
<!--word读取内容结果-->
</div>
<script type="text/javascript">
//读取word
function doReadFile1(){
$("#wordDiv").hide();
$.ajax({
type:"get",
url:"<%=basePath%>/auth/readFile/readWordFile",
data:{
},
dataType:"JSON",//预期服务器返回的数据类型
success:function(res){
console.log(res)
$("#wordDiv").show();
var html="";
html+="<h1>word内容如下:</h1>"
html+="<pre>"+res.content+"</pre>";
$("#wordDiv").html(html);
}
} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









