







概述
Kafka是一个基于Zookeeper的分布式消息中间件,支持消息分区,提供发布和订阅功能。使用Scala编写,主要特点是可水平扩展,高吞吐率以及高并发。
常见的使用场景:
- 企业级别活动数据和运营数据的消息传递,活动数据一般包括页面的访问,搜索。运营数据包括服务器上CPU,IO,用户活跃度等数据。
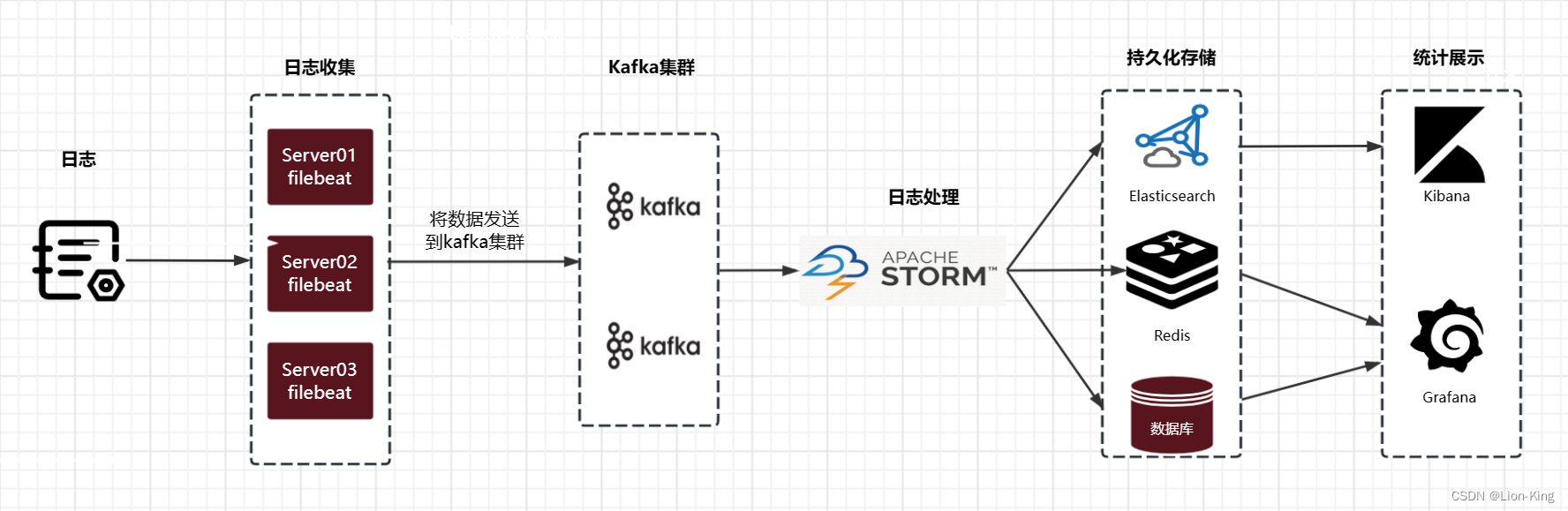
- 日志收集,收集的日志对接hadoop,Hbase,Elasticsearch等系统。
- 流式处理,支持spark streaming和storm。
基本架构以及概念
Kafka的主要工作原理是多个Producer发送Topic消息体到Kafka集群上,消息首先会存放在不同Broker对应的Leader分区上,Follower分区拉取Leader分区消息并写入日志,Consumer客户端同时也拉取Leader分区消息,完成消息消费。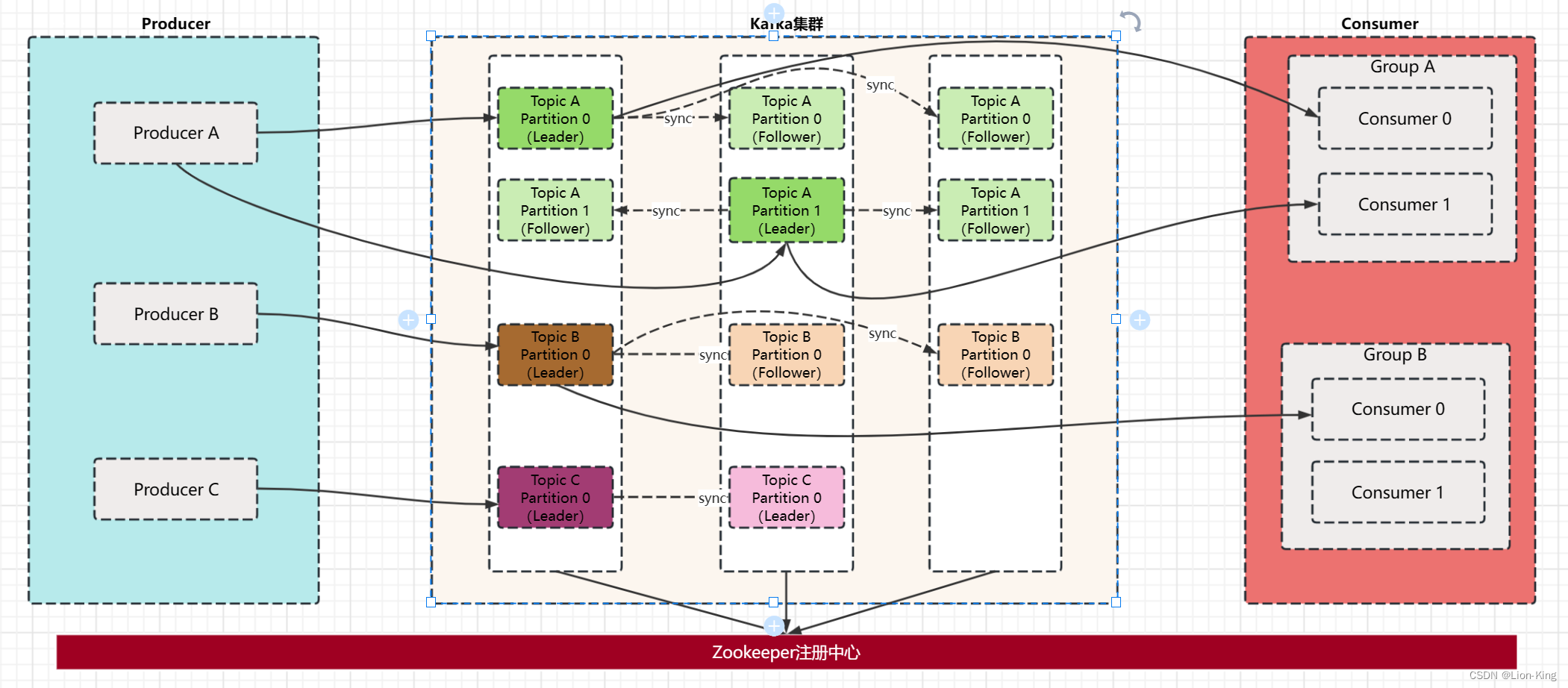
上图中,Kafka集群中有3台Broker,Kafka集群在启动的时候会将自身信息注册到Zookeeper集群中,保证信息的一致性。Producer有3个,分别发送Topic为A,B,C的消息体道Kafka集群中。Kafka集群中Topic A的Partition数为2,Replication数为3,Topic B的Partition数为1,Replication数为3,Topic C的Partition数为1,Replication数为2.每个Partition有主从之分,主Partition会接收Producer消息并共Consumer消费,从Partition只会从主Partition接收数据,不会和Producer以及Cosumer有直接联系。多个Consumer可以组成一个Group,同一group下不同的Consumer只能消费同一Topic下不同Partition的消息。例如Consumer Group A下的Consumer0和Consumer1只能分别消费Topic A中Partition0和Partition1的消息。
以下是Kafka部分概念解析
- Producer:消息生产者。
- Consumer:消息消费者。
- Consumer Group: 消费者群组,包含多个消费者,同组消费者消费同一个Topic下不同的分区的消息。
- Broker: Kafka实例,可以理解为不同的kafka服务器,每个都有一个唯一的编号。
- Message: 生产者传递给消费者的消息体。
- Topic: 消息主题,Broker上有不同的Topic, Message发送到不同的Topic供消费者消费。
- Partition: 相当于将消息进行了分发,一个Topic可以分为多个分区,消费者群组里面的消费者可以同时消费不同分区里面的消息,提高了吞吐量。
- Replication: 分区副本,默认最大为10个,不能大于Broker的数量,当分区的Leader挂掉之后,Follower继续工作,提供可靠性保证。
- Offset:消息持久化中消息的位置偏移信息。
- zookeeper: 保存Kafka集群的信息的Metadata,同样提供了可靠性保证
具体工作流程
- Producer发送数据到Broker
同一Topic下的消息在集群中有多个分区,Producer发送
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2557
2557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









