







HDFS,全称Hadoop Distributed FileSystem.是一个文件系统,用于存储文件,通过目录树/来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色(在一些非正式的文档或者旧文档中,也简称DFS)。
1.HDFS的设计特点:
①可以进行超大文件存储
②对商用硬件要求不高
③流式数据访问:适合一次写入,多次读出的场景,适合用来做数据分析,并不适合用来做网盘应用等文件系统。
④HDFS只支持单个写入者,而且文件的写入只能以“添加”方式在文件末尾写数据。
⑤因为namenode的原因,不适合大量小文件的存储。
⑥数据访问的延迟相对较高,不适合进行低延迟处理
⑦对商业硬件要求低,可以再廉价的机器上运行。
2. HDFS 文件块大小
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M.
HDFS的块比磁盘的块大(磁盘的块一般为512字节),其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。但是很多情况下HDFS使用128MB的块设置。块的大小:10ms*100*100M/s = 100M,然而真正实际开发中要把block设置的远大于128MB,比如存储文件是1TB时,一般把Block大小设置成512MB.但是也不能任意设置的太大,比如200GB一个,因为在MapReduce的map任务中通常一次只处理一个块中数据(切片大小默认等于block大小),如果设置太大,因为任务数太少(少于集群中的节点数量),那么作业的运行速度就会慢很多,此外比如故障等原因也会拖慢速度。
虽然HDFS以block块存储,对于大文件会被切分成很多以块大小的分块进行存储,但是如果文件小于HDFS的块大小,那么该文件的存储不会占用整个块的空间。比如一个10MB的文件,存储虽然在一个128MB的块上,但是该文件实际只用了10MB的空间,而不是128MB的空间。
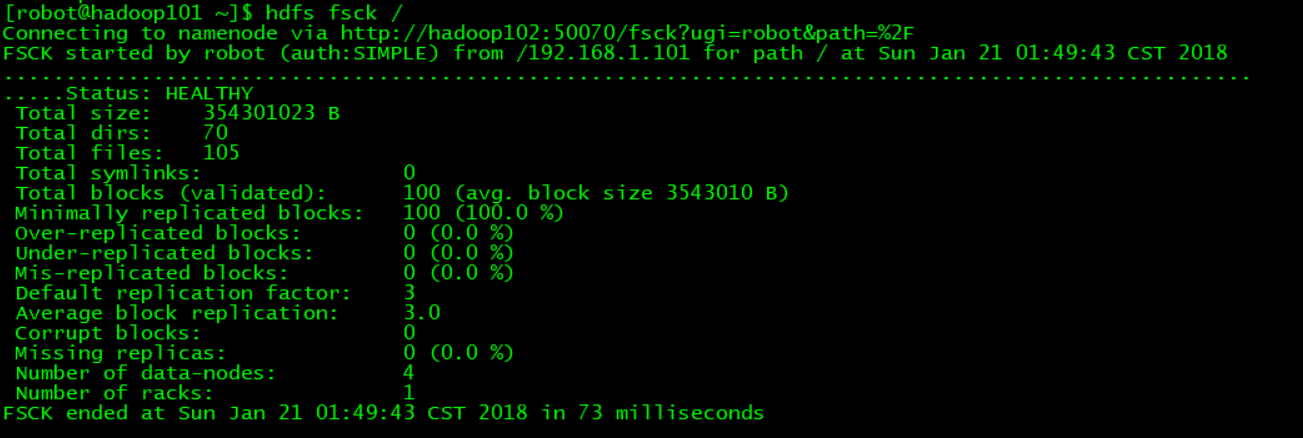
文件系统检查的工具fsck的使用:用来显示块信息,比如复本数,是否损坏等等。(具体使用参见我其他关于fsck的博客。)
语法格式:hdfs fsck / -files -block
举例:查看/根目录下的数据块情况 hdfs fsck /
3.块缓存机制
通常datanode从磁盘上读取块,但是对于频繁访问的数据块,datanode会将其缓存到dataNode节点的内存中,以堆外块缓存的形式(off-heap block cache )存在。默认情况下,一个块只缓存到一个datanode内存中(加入复本是3个,但是也只在一个datanode内存中缓存块)。这样的话,计算框架,比如MR或者Spark就可以在缓存块的节点上运行计算任务,可以大大提高读操作的性能,进而提高任务的效率。
用户也可以通过在缓存池(cache pool) 中增加一个cache directive 来告诉namenode需要缓存哪些文件,以及文件缓存多久,所谓缓存池就是一个用于管理缓存权限和资源使用的管理分组。
















 1696
1696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











