







为什么要用Pipeline 因为光速太慢
这不是一个噱头,我们考虑一下一种极端的情况,我们有一台内存很大服务器在北京,为其他服务提供数据。我们又在广东买了一台应用服务器来访问北京的redis服务器。这种情况是有可能存在的吧,先上一张图
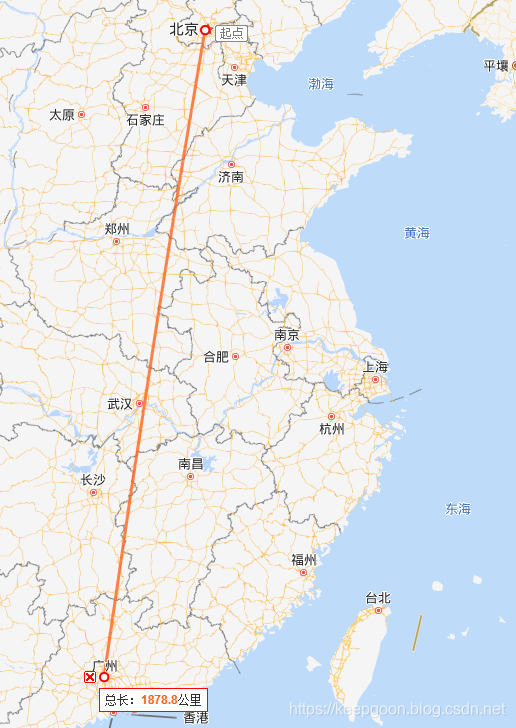
这里我们姑且按照直线距离为 1800公里来算,光速按照无损的 300000km/s 每秒
-
首先,redis客户端(广东)发送一条命令到 redis服务端(北京),然后redis服务端返回数据到redis客户端,这个过程有个很专业的称呼叫做RTT(Round Trip Time 往返时间)。
-
然后我们算一下 时间,1800*2 / 300000 = 0.012秒 也就是 12毫秒。
-
1000/12 = 83.3 ,也就是一秒钟redis只能读取 83次数据。
-
这我们不去计算redis的响应时间,但是光纤的传输是有损耗的,姑且按照光纤速度 = 2/3 光速
那么一次RTT时间为 18毫米,一秒钟只能访问 55次。 -
而Redis官方给出的读写速度为 10万/秒 ,是不是大相径庭,因此光速太慢,并非噱头。
pipeline 多带走些,多带回些
pipeline 管道可以将一组redis 命令进行封装,一次性将多个命令传输到redis服务端,并将数据一次性带回。
这样pipeline 可以通过一次RTT ,将多个数据带回,减少了数据传输的RTT消耗。
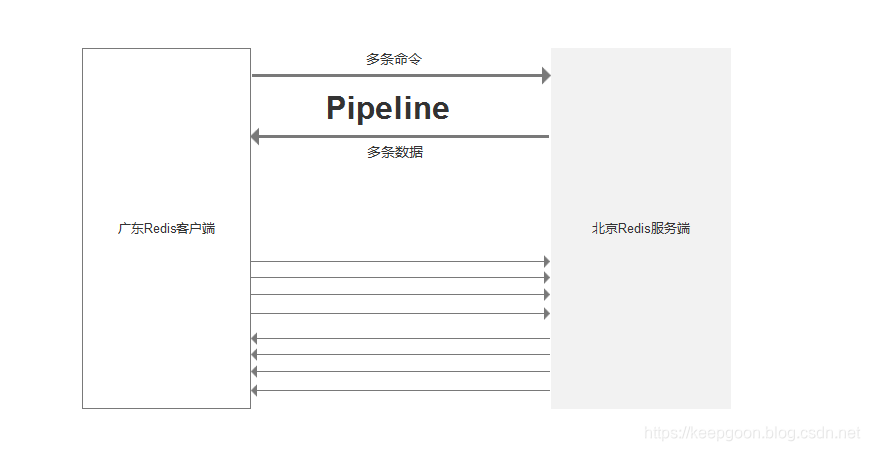
redis 的命令执行是微妙级别的,相对于redis 网络的速度并跟不上,因此才有了redis的性能瓶颈在网络的说法。并且事实上网络确实已经是redis的性能瓶颈之一。
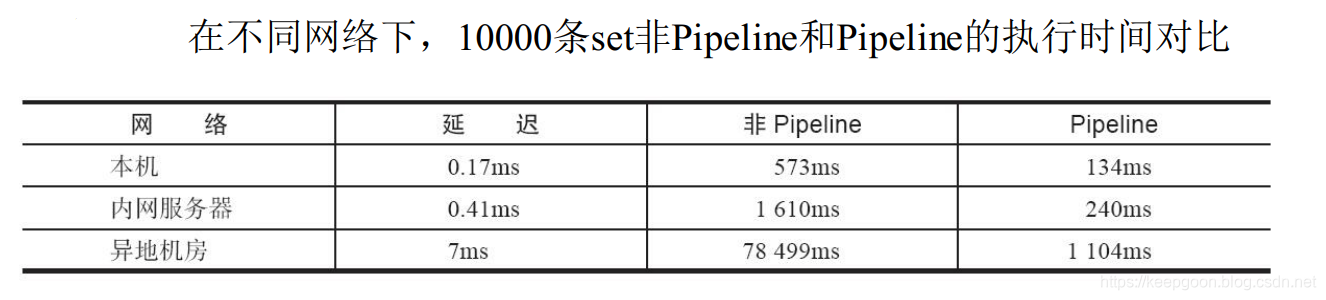
可以使用Pipeline模拟出批量操作的效果, 但是在使用时要注意它与原生批量命令的区别, 具体包含以下几点:
- 原生批量命令是原子的, Pipeline是非原子的。
- 原生批量命令是一个命令对应多个key, Pipeline支持多个命令。
- 原生批量命令是Redis服务端支持实现的, 而Pipeline需要服务端和客户端的共同实现。
pipeline 也有局限
- 每次封装命令的个数不宜过多,不易封装耗时过多的命令,否则会增加客户端的等待时间,和网络阻塞,一些O(n)复杂度的命令,还容易使服务端阻塞。
- pipeline 只能操作一个redis实例。















 3265
3265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











