





1.列出安装hadoop流程步骤
a)创建hadoop账号
b)更改ip
c)安装java更改/etc/profile配置环境变量
d)修改host文件域名
e)安装ssh配置无密码登录
f)解压hadoop
g)配置hadoopconf下面的配置文件
h)Hadoopnamenode-format格式化
i)Start启动
2.列出hadoop集群启动中的所有进程和进程的作用
a)Namenode管理集群记录namenode文件信息
b)Secondname可以做备份对一定范围内的数据做快照
c)Datanode存储数据
d)Jobtarcker管理任务分配任务
e)Tasktracker执行任务
3.启动报nameNode错误如何解决
a)检查hdfs有没有启动成功
b)检查输入文件是不是存在
4.写出下列执行命令
杀死一个job
Hadoopjob-list取得jobid
Hadoopjobkilljobid
删除hdfs上的/temp/aa目录
Hadoop-daemon。Shstartdatanode
加入一个新的节点或删除一个节点刷新集群状态的命令
5.列出你所知道的调肚脐说明其工作方法
a)Fifoschedular默认的调肚脐先进先出
b)Capacityschedular计算能力调肚脐选择占用内存小优先级高的
c)Fairschedular调肚脐公平调肚脐所有job占用相同资源
6.列出开发map/reduce元数据存储
a)
7.用你最熟悉的语言辨析一个mapreduce计算第四个原色的个数
a)Wordcount
8.你认为javastreatingpipe开发mapreduce优缺点
a)Java编写mapreduce可以实现复杂的逻辑如果需求简单则显得繁琐
b)Hivesql基本都是针对hive中表数据进行编写对复杂的逻辑很难实现
9.Hive有哪些保存元数据的方式并有哪些特点
a)内存数据库derby
b)本地mysql常用
c)远程mysql
10.简述hadoop怎么样实现二级缓存
11.简述hadoop实现join的及各种方式
reducesidejoin是一种最简单的join方式,其主要思想如下:
在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签(tag),比如:tag=0表示来自文件File1,tag=2表示来自文件File2。即:map阶段的主要任务是对不同文件中的数据打标签。
在reduce阶段,reduce函数获取key相同的来自File1和File2文件的valuelist,然后对于同一个key,对File1和File2中的数据进行join(笛卡尔乘积)。即:reduce阶段进行实际的连接操作。
2.2mapsidejoin
之所以存在reducesidejoin,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。Reducesidejoin是非常低效的,因为shuffle阶段要进行大量的数据传输。
Mapsidejoin是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多份,让每个maptask内存中存在一份(比如存放到hashtable中),然后只扫描大表:对于大表中的每一条记录key/value,在hashtable中查找是否有相同的key的记录,如果有,则连接后输出即可。
为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:
(1)用户使用静态方法DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的URI(如果是HDFS上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中9000是自己配置的NameNode端口号)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。(2)用户使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。
2.3SemiJoin
SemiJoin,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reducesidejoin,跨机器的数据传输量非常大,这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO。
实现方法很简单:选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,可以放到内存中。在map阶段,使用DistributedCache将File3复制到各个TaskTracker上,然后将File2中不在File3中的key对应的记录过滤掉,剩下的reduce阶段的工作与reducesidejoin相同。
12.
13.Java非递归二分查找
1.publicclassBinarySearchClass
2.{
3.
4.publicstaticintbinary_search(int[]array,intvalue)
5.{
6.intbeginIndex=0;//低位下标
7.intendIndex=array.length-1;//高位下标
8.intmidIndex=-1;
9.while(beginIndex<=endIndex){
10.midIndex=beginIndex+(endIndex-beginIndex)/2;//防止溢出
11.if(value==array[midIndex]){
12.returnmidIndex;
13.}elseif(value<array[midIndex]){
14.endIndex=midIndex-1;
15.}else{
16.beginIndex=midIndex+1;
17.}
18.}
19.return-1;
20.//找到了,返回找到的数值的下标,没找到,返回-1
21.}
22.
23.
24.//start提示:自动阅卷起始唯一标识,请勿删除或增加。
25.publicstaticvoidmain(String[]args)
26.{
27.System.out.println("Start...");
28.int[]myArray=newint[]{1,2,3,5,6,7,8,9};
29.System.out.println("查找数字8的下标:");
30.System.out.println(binary_search(myArray,8));
31.}
14.
15.Combiner和partition的作用
16.combine分为map端和reduce端,作用是把同一个key的键值对合并在一起,可以自定义的。
combine函数把一个map函数产生的<key,value>对(多个key,value)合并成一个新的<key2,value2>.将新的<key2,value2>作为输入到reduce函数中
这个value2亦可称之为values,因为有多个。这个合并的目的是为了减少网络传输。
partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定义的。这里其实可以理解归类。
我们对于错综复杂的数据归类。比如在动物园里有牛羊鸡鸭鹅,他们都是混在一起的,但是到了晚上他们就各自牛回牛棚,羊回羊圈,鸡回鸡窝。partition的作用就是把这些数据归类。只不过在写程序的时候,mapreduce使用哈希HashPartitioner帮我们归类了。这个我们也可以自定义。
shuffle就是map和reduce之间的过程,包含了两端的combine和partition。
Map的结果,会通过partition分发到Reducer上,Reducer做完Reduce操作后,通过OutputFormat,进行输出
shuffle阶段的主要函数是fetchOutputs(),这个函数的功能就是将map阶段的输出,copy到reduce节点本地
17.俩个文件用linux命令完成下列工作
a)俩个文件各自的ip数和综述
b)出现在b文件没有出现在a文件的ip
c)那个name的次数和他对一个的ip
1.hive内部表和外部表区别
2.1、在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而表则不一样;
2、在删除表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
那么,应该如何选择使用哪种表呢?在大多数情况没有太多的区别,因此选择只是个人喜好的问题。但是作为一个经验,如果所有处理都需要由Hive完成,那么你应该创建表,否则使用外部表!
3.Hbaserowkey怎么创建表交好列祖怎么创建比较好
HBase是一个分布式的、面向列的数据库,它和一般关系型数据库的最大区别是:HBase很适合于存储非结构化的数据,还有就是它基于列的而不是基于行的模式。
既然HBase是采用KeyValue的列存储,那Rowkey就是KeyValue的Key了,表示唯一一行。Rowkey也是一段二进制码流,最大长度为64KB,内容可以由使用的用户自定义。数据加载时,一般也是根据Rowkey的二进制序由小到大进行的。
HBase是根据Rowkey来进行检索的,系统通过找到某个Rowkey(或者某个Rowkey范围)所在的Region,然后将查询数据的请求路由到该Region获取数据。HBase的检索支持3种方式:
(1)通过单个Rowkey访问,即按照某个Rowkey键值进行get操作,这样获取唯一一条记录;
(2)通过Rowkey的range进行scan,即通过设置startRowKey和endRowKey,在这个范围内进行扫描。这样可以按指定的条件获取一批记录;
(3)全表扫描,即直接扫描整张表中所有行记录。
HBASE按单个Rowkey检索的效率是很高的,耗时在1毫秒以下,每秒钟可获取1000~2000条记录,不过非key列的查询很慢。
2HBase的RowKey设计
2.1设计原则
2.1.1Rowkey长度原则
Rowkey是一个二进制码流,Rowkey的长度被很多开发者建议说设计在10~100个字节,不过建议是越短越好,不要超过16个字节。
原因如下:
(1)数据的持久化文件HFile中是按照KeyValue存储的,如果Rowkey过长比如100个字节,1000万列数据光Rowkey就要占用100*1000万=10亿个字节,将近1G数据,这会极大影响HFile的存储效率;
(2)MemStore将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey的字节长度越短越好。
(3)目前操作系统是都是64位系统,内存8字节对齐。控制在16个字节,8字节的整数倍利用操作系统的最佳特性。
2.1.2Rowkey散列原则
如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
2.1.3Rowkey唯一原则
必须在设计上保证其唯一性。
2.2应用场景
基于Rowkey的上述3个原则,应对不同应用场景有不同的Rowkey设计建议。
2.2.1针对事务数据Rowkey设计
事务数据是带时间属性的,建议将时间信息存入到Rowkey中,这有助于提示查询检索速度。对于事务数据建议缺省就按天为数据建表,这样设计的好处是多方面的。按天分表后,时间信息就可以去掉日期部分只保留小时分钟毫秒,这样4个字节即可搞定。加上散列字段2个字节一共6个字节即可组成唯一Rowkey。如下图所示:
| 事务数据Rowkey设计 | ||||||
| 第0字节 | 第1字节 | 第2字节 | 第3字节 | 第4字节 | 第5字节 | … |
| 散列字段 | 时间字段(毫秒) | 扩展字段 | ||||
| 0~65535(0x0000~0xFFFF) | 0~86399999(0x00000000~0x05265BFF) |
| ||||
这样的设计从操作系统内存管理层面无法节省开销,因为64位操作系统是必须8字节对齐。但是对于持久化存储中Rowkey部分可以节省25%的开销。也许有人要问为什么不将时间字段以主机字节序保存,这样它也可以作为散列字段了。这是因为时间范围内的数据还是尽量保证连续,相同时间范围内的数据查找的概率很大,对查询检索有好的效果,因此使用独立的散列字段效果更好,对于某些应用,我们可以考虑利用散列字段全部或者部分来存储某些数据的字段信息,只要保证相同散列值在同一时间(毫秒)唯一。
2.2.2针对统计数据的Rowkey设计
统计数据也是带时间属性的,统计数据最小单位只会到分钟(到秒预统计就没意义了)。同时对于统计数据我们也缺省采用按天数据分表,这样设计的好处无需多说。按天分表后,时间信息只需要保留小时分钟,那么0~1400只需占用两个字节即可保存时间信息。由于统计数据某些维度数量非常庞大,因此需要4个字节作为序列字段,因此将散列字段同时作为序列字段使用也是6个字节组成唯一Rowkey。如下图所示:
| 统计数据Rowkey设计 | ||||||
| 第0字节 | 第1字节 | 第2字节 | 第3字节 | 第4字节 | 第5字节 | … |
| 散列字段(序列字段) | 时间字段(分钟) | 扩展字段 | ||||
| 0x00000000~0xFFFFFFFF) | 0~1439(0x0000~0x059F) |
| ||||
同样这样的设计从操作系统内存管理层面无法节省开销,因为64位操作系统是必须8字节对齐。但是对于持久化存储中Rowkey部分可以节省25%的开销。预统计数据可能涉及到多次反复的重计算要求,需确保作废的数据能有效删除,同时不能影响散列的均衡效果,因此要特殊处理。
2.2.3针对通用数据的Rowkey设计
通用数据采用自增序列作为唯一主键,用户可以选择按天建分表也可以选择单表模式。这种模式需要确保同时多个入库加载模块运行时散列字段(序列字段)的唯一性。可以考虑给不同的加载模块赋予唯一因子区别。设计结构如下图所示。
| 通用数据Rowkey设计 | ||||
| 第0字节 | 第1字节 | 第2字节 | 第3字节 | … |
| 散列字段(序列字段) | 扩展字段(控制在12字节内) | |||
| 0x00000000~0xFFFFFFFF) | 可由多个用户字段组成 | |||
2.2.4支持多条件查询的RowKey设计
HBase按指定的条件获取一批记录时,使用的就是scan方法。scan方法有以下特点:
(1)scan可以通过setCaching与setBatch方法提高速度(以空间换时间);
(2)scan可以通过setStartRow与setEndRow来限定范围。范围越小,性能越高。
通过巧妙的RowKey设计使我们批量获取记录集合中的元素挨在一起(应该在同一个Region下),可以在遍历结果时获得很好的性能。
(3)scan可以通过setFilter方法添加过滤器,这也是分页、多条件查询的基础。
在满足长度、三列、唯一原则后,我们需要考虑如何通过巧妙设计RowKey以利用scan方法的范围功能,使得获取一批记录的查询速度能提高。下例就描述如何将多个列组合成一个RowKey,使用scan的range来达到较快查询速度。
例子:
我们在表中存储的是文件信息,每个文件有5个属性:文件id(long,全局唯一)、创建时间(long)、文件名(String)、分类名(String)、所有者(User)。
我们可以输入的查询条件:文件创建时间区间(比如从20120901到20120914期间创建的文件),文件名(“中国好声音”),分类(“综艺”),所有者(“浙江卫视”)。
假设当前我们一共有如下文件:
| ID | CreateTime | Name | Category | UserID |
| 1 | 20120902 | 中国好声音第1期 | 综艺 | 1 |
| 2 | 20120904 | 中国好声音第2期 | 综艺 | 1 |
| 3 | 20120906 | 中国好声音外卡赛 | 综艺 | 1 |
| 4 | 20120908 | 中国好声音第3期 | 综艺 | 1 |
| 5 | 20120910 | 中国好声音第4期 | 综艺 | 1 |
| 6 | 20120912 | 中国好声音选手采访 | 综艺花絮 | 2 |
| 7 | 20120914 | 中国好声音第5期 | 综艺 | 1 |
| 8 | 20120916 | 中国好声音录制花絮 | 综艺花絮 | 2 |
| 9 | 20120918 | 张玮独家专访 | 花絮 | 3 |
| 10 | 20120920 | 加多宝凉茶广告 | 综艺广告 | 4 |
这里UserID应该对应另一张User表,暂不列出。我们只需知道UserID的含义:
1代表浙江卫视;2代表好声音剧组;3代表XX微博;4代表赞助商。调用查询接口的时候将上述5个条件同时输入find(20120901,20121001,”中国好声音”,”综艺”,”浙江卫视”)。此时我们应该得到记录应该有第1、2、3、4、5、7条。第6条由于不属于“浙江卫视”应该不被选中。我们在设计RowKey时可以这样做:采用UserID+CreateTime+FileID组成RowKey,这样既能满足多条件查询,又能有很快的查询速度。
需要注意以下几点:
(1)每条记录的RowKey,每个字段都需要填充到相同长度。假如预期我们最多有10万量级的用户,则userID应该统一填充至6位,如000001,000002…
(2)结尾添加全局唯一的FileID的用意也是使每个文件对应的记录全局唯一。避免当UserID与CreateTime相同时的两个不同文件记录相互覆盖。
按照这种RowKey存储上述文件记录,在HBase表中是下面的结构:
rowKey(userID6+time8+fileID6)namecategory….
00000120120902000001
00000120120904000002
00000120120906000003
00000120120908000004
00000120120910000005
00000120120914000007
00000220120912000006
00000220120916000008
00000320120918000009
00000420120920000010
怎样用这张表?
在建立一个scan对象后,我们setStartRow(00000120120901),setEndRow(00000120120914)。
这样,scan时只扫描userID=1的数据,且时间范围限定在这个指定的时间段内,满足了按用户以及按时间范围对结果的筛选。并且由于记录集中存储,性能很好。
然后使用SingleColumnValueFilter(org.apache.hadoop.hbase.filter.SingleColumnValueFilter),共4个,分别约束name的上下限,与category的上下限。满足按同时按文件名以及分类名的前缀匹配。
4.
5.Mapreduce怎么处理数据倾斜
6.map/reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有时是百倍或者千倍之多),这条key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完,此称之为数据倾斜。
用hadoop程序进行数据关联时,常碰到数据倾斜的情况,这里提供一种解决方法。
(1)设置一个hash份数N,用来对条数众多的key进行打散。
(2)对有多条重复key的那份数据进行处理:从1到N将数字加在key后面作为新key,如果需要和另一份数据关联的话,则要重写比较类和分发类(方法如上篇《hadoopjob解决大数据量关联的一种方法》)。如此实现多条key的平均分发。
intiNum=iNum%iHashNum;
StringstrKey=key+CTRLC+String.valueOf(iNum)+CTRLB+“B”;
(3)上一步之后,key被平均分散到很多不同的reduce节点。如果需要和其他数据关联,为了保证每个reduce节点上都有关联的key,对另一份单一key的数据进行处理:循环的从1到N将数字加在key后面作为新key
for(inti=0;i<iHashNum;++i){
StringstrKey=key+CTRLC+String.valueOf(i);
output.collect(newText(strKey),newText(strValues));}
以此解决数据倾斜的问题,经试验大大减少了程序的运行时间。但此方法会成倍的增加其中一份数据的数据量,以增加shuffle数据量为代价,所以使用此方法时,要多次试验,取一个最佳的hash份数值。
======================================
用上述的方法虽然可以解决数据倾斜,但是当关联的数据量巨大时,如果成倍的增长某份数据,会导致reduceshuffle的数据量变的巨大,得不偿失,从而无法解决运行时间慢的问题。
有一个新的办法可以解决成倍增长数据的缺陷:
在两份数据中找共同点,比如两份数据里除了关联的字段以外,还有另外相同含义的字段,如果这个字段在所有log中的重复率比较小,则可以用这个字段作为计算hash的值,如果是数字,可以用来模hash的份数,如果是字符可以用hashcode来模hash的份数(当然数字为了避免落到同一个reduce上的数据过多,也可以用hashcode),这样如果这个字段的值分布足够平均的话,就可以解决上述的问题。-
7.Hadoop框架中怎么优化
Storm用于处理高速、大型数据流的分布式实时计算系统。为Hadoop添加了可靠的实时数据处理功能
Spark采用了内存计算。从多迭代批处理出发,允许将数据载入内存作反复查询,此外还融合数据仓库,流处理和图形计算等多种计算范式。Spark构建在HDFS上,能与Hadoop很好的结合。它的RDD是一个很大的特点。
Hadoop当前大数据管理标准之一,运用在当前很多商业应用系统。可以轻松地集成结构化、半结构化甚至非结构化数据集。
8.
9.Hbase内部是什么机制
在HBase中无论是增加新行还是修改已有的行,其内部流程都是相同的。HBase接到命令后存下变化信息,或者写入失败抛出异常。默认情况下,执行写入时会写到两个地方:预写式日志(write-aheadlog,也称HLog)和MemStore(见图2-1)。HBase的默认方式是把写入动作记录在这两个地方,以保证数据持久化。只有当这两个地方的变化信息都写入并确认后,才认为写动作完成。
MemStore是内存里的写入缓冲区,HBase中数据在永久写入硬盘之前在这里累积。当MemStore填满后,其中的数据会刷写到硬盘,生成一个HFile。HFile是HBase使用的底层存储格式。HFile对应于列族,一个列族可以有多个HFile,但一个HFile不能存储多个列族的数据。在集群的每个节点上,每个列族有一个MemStore。
大型分布式系统中硬件故障很常见,HBase也不例外。设想一下,如果MemStore还没有刷写,服务器就崩溃了,内存中没有写入硬盘的数据就会丢失。HBase的应对办法是在写动作完成之前先写入WAL。HBase集群中每台服务器维护一个WAL来记录发生的变化。WAL是底层文件系统上的一个文件。直到WAL新记录成功写入后,写动作才被认为成功完成。这可以保证HBase和支撑它的文件系统满足持久性。大多数情况下,HBase使用Hadoop分布式文件系统(HDFS)来作为底层文件系统。
如果HBase服务器宕机,没有从MemStore里刷写到HFile的数据将可以通过回放WAL来恢复。你不需要手工执行。Hbase的内部机制中有恢复流程部分来处理。每台HBase服务器有一个WAL,这台服务器上的所有表(和它们的列族)共享这个WAL。
你可能想到,写入时跳过WAL应该会提升写性能。但我们不建议禁用WAL,除非你愿意在出问题时丢失数据。如果你想测试一下,如下代码可以禁用WAL:
注意:不写入WAL会在RegionServer故障时增加丢失数据的风险。关闭WAL,出现故障时HBase可能无法恢复数据,没有刷写到硬盘的所有写入数据都会丢失。
10.
11.我们在开发分布式计算jiob的是不是可以去掉reduce
由于MapReduce计算输入和输出都是基于HDFS文件,所以大多数公司的做法是把mysql或sqlserver的数据导入到HDFS,计算完后再导出到常规的数据库中,这是MapReduce不够灵活的地方之一。MapReduce优势在于提供了比较简单的分布式计算编程模型,使开发此类程序变得非常简单,像之前的MPI编程就相当复杂。
狭隘的来讲,MapReduce是把计算任务给规范化了,它可以等同于小和尚中Worker的业务逻辑部分。MapReduce把业务逻辑给拆分成2个大部分,Map和Reduce,可以先在Map部分把任务计算一半后,扔给Reduce部分继续后面的计算。当然在Map部分把计算任务全做完也是可以的。关于Mapreduce实现细节部分不多解释,有兴趣的同学可以查相关资料或看下楼主之前的C#模拟实现的博客【探索C#之微型MapReduce】。
如果把小明产品经理的需求放到Hadoop来做,其处理流程大致如下:
1.把100G数据导入到HDFS
2.按照Mapreduce的接口编写处理逻辑,分Map、Reduce两部分。
3.把程序包提交到Mapreduce平台上,存储在HDFS里。
4.平台中有个叫Jobtracker进程的角色进行分发任务。这个类似小和尚的Master负载调度管理。
5.如果有5台机器进行计算的话,就会提前运行5个叫TaskTracker的slave进程。这类似小和尚worker的分离版,平台把程序和业务逻辑进行分离了,简单来说就是在机器上运行个独立进程,它能动态加载、执行jar或dll的业务逻辑代码。
6.Jobtracker把任务分发到TaskTracker后,TaskTracker把开始动态加载jar包,创建个独立进程执行Map部分,然后把结果写入到HDFS上。
7.如果有Reduce部分,TaskTracker会创建个独立进程把Map输出的HDFS文件,通过RPC方式远程拉取到本地,拉取成功后,Reduce开始计算后续任务。
8.Reduce再把结果写入到HDFS中
9.从HDFS中把结果导出。
这样一看好像是把简单的计算任务给
12.
13.Hdfs数据压缩算法
14.1、在HDFS之上将数据压缩好后,再存储到HDFS
2、在HDFS内部支持数据压缩,这里又可以分为几种方法:
2.1、压缩工作在DataNode上完成,这里又分两种方法:
2.1.1、数据接收完后,再压缩
这个方法对HDFS的改动最小,但效果最低,只需要在block文件close后,调用压缩工具,将block文件压缩一下,然后再打开block文件时解压一下即可,几行代码就可以搞定
2.1.2、边接收数据边压缩,使用第三方提供的压缩库
效率和复杂度折中方法,Hook住系统的write和read操作,在数据写入磁盘之前,先压缩一下,但write和read对外的接口行为不变,比如:原始大小为100KB的数据,压缩后大小为10KB,当写入100KB后,仍对调用者返回100KB,而不是10KB
2.2、压缩工作交给DFSClient做,DataNode只接收和存储
这个方法效果最高,压缩分散地推给了HDFS客户端,但DataNode需要知道什么时候一个block块接收完成了。
推荐最终实现采用2.2这个方法,该方法需要修改的HDFS代码量也不大,但效果最高。
15.Mapreduce调度模式
MapReduce是hadoop提供一个可进行分布式计算的框架或者平台,显然这个平台是多用户的,每个合法的用户可以向这个平台提交作业,那么这就带来一个问题,就是作业调度。
任何调度策略都考虑自己平台调度需要权衡的几个维度,例如操作系统中的进程调度,他需要考虑的维度就是资源(CPU)的最大利用率(吞吐)和实时性,操作系统对实时性的要求很高,所以操作系统往往采用基于优先级的、可抢占式的调度策略,并且赋予IO密集型(相对于计算密集型)的进程较高的优先级,扯的有点远。
回到hadoop平台,其实MapReduce的作业调度并没有很高的实时性的要求,本着最大吞吐的原则去设计的,所以MapReduce默认采用的调度策略是FIFO(基于优先级队列实现的FIFO,不是纯粹的FIFO,这样每次h),这种策略显然不是可抢占式的调度,所以带来的问题就是高优先级的任务会被先前已经在运行并且还要运行很久的低优先级的作业给堵塞住。
16.
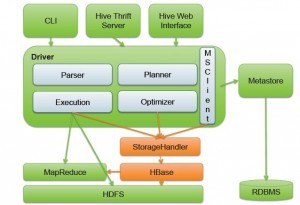
17.Hive底层和数据库交互原理
Hive和Hbase有各自不同的特征:hive是高延迟、结构化和面向分析的,hbase是低延迟、非结构化和面向编程的。Hive数据仓库在hadoop上是高延迟的。Hive集成Hbase就是为了使用hbase的一些特性。如下是hive和hbase的集成架构:
图1hive和hbase架构图
Hive集成HBase可以有效利用HBase数据库的存储特性,如行更新和列索引等。在集成的过程中注意维持HBasejar包的一致性。Hive集成HBase需要在Hive表和HBase表之间建立映射关系,也就是Hive表的列(columns)和列类型(columntypes)与HBase表的列族(columnfamilies)及列限定词(columnqualifiers)建立关联。每一个在Hive表中的域都存在于HBase中,而在Hive表中不需要包含所有HBase中的列。HBase中的RowKey对应到Hive中为选择一个域使用:key来对应,列族(cf:)映射到Hive中的其它所有域,列为(cf:cq)。例如下图2为Hive表映射到HBase表:
图2Hive表映射HBase表
18.
19.Hbase过滤器实现原则
到现在为止你了解到HBase拥有灵活的逻辑模式和简单的物理模型,它们允许应用系统的计算工作更接近硬盘和网络,并
在这个层次进行优化。设计有效的模式是使用HBase的一个方面,你已经掌握了一堆概念用来做到这点。你可以设计行键
以使访问的数据在硬盘上也存放在一起,所以读写操作时可以节省硬盘寻道时间。在读取数据时,你经常需要基于某种标
准进行操作,你可以进一步优化数据访问。过滤器就是在这种情况下使用的一种强大的功能。
我们还没有谈到使用过滤器的真实使用场景;一般来说调整表设计就可以优化访问模式。但是有时你已经把表设计调整得
尽可能好了,为不同访问模式优化得尽可能好了。当你仍然需要减少返回客户端的数据时,这就是考虑使用过滤器的时候
了。有时侯过滤器也被称为下推判断器(push-downpredicates),支持你把数据过滤标准从客户端下推到服务器(如图
4.16)。这些过滤逻辑在读操作时使用,对返回客户端的数据有影响。这样通过减少网络传输的数据来节省网络IO。但是
数据仍然需要从硬盘读进RegionServer,过滤器在RegionServer里发挥作用。因为你有可能在HBase表里存储大量数据,
网络IO的节省是有重要意义的,并且先读出全部数据送到客户端再过滤出有用的数据,这种做法开销很大。
图4.16在客户端完成数据过滤:从RegionServer把数据读取到客户端,在客户端使用过滤器逻辑处理数据;或者在服务
器端完成数据过滤:把过滤逻辑下推到RegionServer,因此减少了在网络上传输到客户端的数据量。实质上过滤器节省了
网络IO的开销,有时甚至是硬盘IO的开销。
HBase提供了一个API,你可以用来实现定制过滤器。多个过滤器也可以捆绑在一起使用。可以在读过程最开始的地方,基
于行健进行过滤处理。此后,也可以基于HFile读出的KeyValues进行过滤处理。过滤器必须实现HBaseJar包中的Filter
接口,或者继承扩展一个实现了该接口的抽象类。我们推荐继承扩展FilterBase抽象类,这样你不需要写样板代码。继承
扩展其他诸如CompareFilter类也是一个选择,同样可以正常工作。当读取一行时该接口有下面的方法在多个地方可以调
用(顺序如图4.17)。它们总是按照下面描述的顺序来执行:
1这个方法第一个被调用,基于行健执行过滤:
booleanfilterRowKey(byte[]buffer,intoffset,intlength)
基于这里的逻辑,如果行被过滤掉了(不出现在发送结果集合里)返回true,否则如果发送给客户端则返回false。
2如果该行没有在上一步被过滤掉,接着调用这个方法处理当前行的每个KeyValue对象:
ReturnCodefilterKeyValue(KeyValuev)
这个方法返回一个ReturnCode,这是在Filter接口中定义的一个枚举(enum)类型。返回的ReturnCode判断某个KeyValue
对象发生了什么。
3在第2步过滤KeyValues对象后,接着是这个方法:
voidfilterRow(Listkvs)
这个方法被传入成功通过过滤的KeyValue对象列表。倘若这个方法访问到这个列表,此时你可以在列表里的元素上执行任
何转换或运算。
4如果你选择过滤掉某些行,此时这个方法再一次提供了这么做的机会:
booleanfilterRow()
过滤掉考虑中的行,则返回true。
5你可以在过滤器里构建逻辑来提早停止一次扫描。你可以把该逻辑放进这个方法:
booleanfilterAllRemaining()
当你扫描很多行,在行健、列标识符或单元值里查找指定东西时,一旦找到目标,你就不再关心剩下的行了。此时这个方
法用起来很方便。这是过滤流程中最后调用的方法。
图4.17过滤流程的各个步骤。扫描器对象扫描范围里的每行都会执行这个流程。
另一个有用的方法是reset()。它会重置过滤器,在被应用到整行后由服务器调用。
注意这个API很强大,但是我们不觉得它是在应用系统里大量使用的。许多情况下,如果模式设计改变了,使用过滤器的
20.
21.Reduce后输出的量有多大
22.找到离存数据最近的一台机器运行和这个数据相关的map任务,reduce是按照你整理出的key有多少个来决定的。一个机器很难说,处理的快的处理多一点,保持所有机器使用平衡。
上面你都自己写了20个map,和文件大小个数有关,和数据条数无关。
要看你选择的输入格式是什么,默认是行偏移量,然后由你编写map函数,指定key和value是什么。相同的key整合起来传给reduce,由reduce进行下一步处理,最后输出到指定的地方。
23.Mapreduce掌握情况和hivehsql掌握情况
Hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据,可以将结构
化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL去查询分析需
要的内容,这套SQL简称HiveSQL,使不熟悉mapreduce的用户很方便的利用SQL语言查询,汇总,分析数据。而mapreduce开发人员可以把
己写的mapper和reducer作为插件来支持Hive做更复杂的数据分析。
它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。HIVE不适合用于联机
online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。
HIVE的特点:可伸缩(在Hadoop的集群上动态的添加设备),可扩展,容错,输入格式的松散耦合。
Hive的官方文档中对查询语言有了很详细的描述,请参考:http://wiki.apache.org/hadoop/Hive/LanguageManual,本文的内容大部分翻译自该页面,期间加入了一些在使用过程中需要注意到的事项。
DDL
•建表
•删除表
•修改表结构
•创建/删除视图
•创建数据库
•显示命令
建表:
CREATE[EXTERNAL]TABLE[IFNOTEXISTS]table_name
[(col_namedata_type[COMMENTcol_comment],...)]
[COMMENTtable_comment]
[PARTITIONEDBY(col_namedata_type[COMMENTcol_comment],...)]
[CLUSTEREDBY(col_name,col_name,...)
[SORTEDBY(col_name[ASC|DESC],...)]INTOnum_bucketsBUCKETS]
[ROWFORMATrow_format]
[STOREDASfile_format]
[LOCATIONhdfs_path]
•CREATETABLE创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用IFNOTEXIST选项来忽略这个异常
•EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
•LIKE允许用户复制现有的表结构,但是不复制数据
•COMMENT可以为表与字段增加描述
•ROWFORMAT
DELIMITED[FIELDSTERMINATEDBYchar][COLLECTIONITEMSTERMINATEDBYchar]
[MAPKEYSTERMINATEDBYchar][LINESTERMINATEDBYchar]
|SERDEserde_name[WITHSERDEPROPERTIES(property_name=property_value,property_name=property_value,...)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROWFORMAT或者ROWFORMATDELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
•STOREDAS
SEQUENCEFILE
|TEXTFILE
|RCFILE
|INPUTFORMATinput_format_classnameOUTPUTFORMAToutput_format_classname
如果文件数据是纯文本,可以使用STOREDASTEXTFILE。如果数据需要压缩,使用STOREDASSEQUENCE。
创建简单表:
hive>CREATETABLEpokes(fooINT,barSTRING);
创建外部表:
CREATEEXTERNALTABLEpage_view(viewTimeINT,useridBIGINT,
page_urlSTRING,referrer_urlSTRING,
ipSTRINGCOMMENT'IPAddressoftheUser',
countrySTRINGCOMMENT'countryoforigination')
COMMENT'Thisisthestagingpageviewtable'
ROWFORMATDELIMITEDFIELDSTERMINATEDBY'\054'
STOREDASTEXTFILE
LOCATION'<hdfs_location>';
建分区表
CREATETABLEpar_table(viewTimeINT,useridBIGINT,
page_urlSTRING,referrer_urlSTRING,
ipSTRINGCOMMENT'IPAddressoftheUser')
COMMENT'Thisisthepageviewtable'
PARTITIONEDBY(dateSTRING,posSTRING)
ROWFORMATDELIMITED‘\t’
FIELDSTERMINATEDBY'\n'
STOREDASSEQUENCEFILE;
建Bucket表
CREATETABLEpar_table(viewTimeINT,useridBIGINT,
page_urlSTRING,referrer_urlSTRING,
ipSTRINGCOMMENT'IPAddressoftheUser')
COMMENT'Thisisthepageviewtable'
PARTITIONEDBY(dateSTRING,posSTRING)
CLUSTEREDBY(userid)SORTEDBY(viewTime)INTO32BUCKETS
ROWFORMATDELIMITED‘\t’
FIELDSTERMINATEDBY'\n'
STOREDASSEQUENCEFILE;
创建表并创建索引字段ds
hive>CREATETABLEinvites(fooINT,barSTRING)PARTITIONEDBY(dsSTRING);
复制一个空表
CREATETABLEempty_key_value_store
LIKEkey_value_store;
例子
createtableuser_info(user_idint,cidstring,ckidstring,usernamestring)
rowformatdelimited
fieldsterminatedby'\t'
linesterminatedby'\n';
导入数据表的数据格式是:字段之间是tab键分割,行之间是断行。
及要我们的文件内容格式:
100636100890c5c86f4cddc15eb7yyyvybtvt
10061210086597cc70d411c18b6fgyvcycy
100078100087ecd6026a15ffddf5qa000100
显示所有表:
hive>SHOWTABLES;
按正条件(正则表达式)显示表,
hive>SHOWTABLES'.*s';
修改表结构
•增加分区、删除分区
•重命名表
•修改列的名字、类型、位置、注释
•增加/更新列
•增加表的元数据信息
表添加一列:
hive>ALTERTABLEpokesADDCOLUMNS(new_colINT);
添加一列并增加列字段注释
hive>ALTERTABLEinvitesADDCOLUMNS(new_col2INTCOMMENT'acomment');
更改表名:
hive>ALTERTABLEeventsRENAMETO3koobecaf;
删除列:
hive>DROPTABLEpokes;
增加、删除分区
•增加
ALTERTABLEtable_nameADD[IFNOTEXISTS]partition_spec[LOCATION'location1']partition_spec[LOCATION'location2']...
partition_spec:
:PARTITION(partition_col=partition_col_value,partition_col=partiton_col_value,...)
•删除
ALTERTABLEtable_nameDROPpartition_spec,partition_spec,...
重命名表
•ALTERTABLEtable_nameRENAMETOnew_table_name
修改列的名字、类型、位置、注释:
•ALTERTABLEtable_nameCHANGE[COLUMN]col_old_namecol_new_namecolumn_type[COMMENTcol_comment][FIRST|AFTERcolumn_name]
•这个命令可以允许改变列名、数据类型、注释、列位置或者它们的任意组合
表添加一列:
hive>ALTERTABLEpokesADDCOLUMNS(new_colINT);
添加一列并增加列字段注释
hive>ALTERTABLEinvitesADDCOLUMNS(new_col2INTCOMMENT'acomment');
增加/更新列
•ALTERTABLEtable_nameADD|REPLACECOLUMNS(col_namedata_type[COMMENTcol_comment],...)
•ADD是代表新增一字段,字段位置在所有列后面(partition列前)
REPLACE则是表示替换表中所有字段。
增加表的元数据信息
•ALTERTABLEtable_nameSETTBLPROPERTIEStable_propertiestable_properties:
:[property_name=property_value…..]
•用户可以用这个命令向表中增加metadata
改变表文件格式与组织
•ALTERTABLEtable_nameSETFILEFORMATfile_format
•ALTERTABLEtable_nameCLUSTEREDBY(userid)SORTEDBY(viewTime)INTOnum_bucketsBUCKETS
•这个命令修改了表的物理存储属性
创建/删除视图
•CREATEVIEW[IFNOTEXISTS]view_name[(column_name[COMMENTcolumn_comment],...)][COMMENTview_comment][TBLPROPERTIES(property_name=property_value,...)]ASSELECT
•增加视图
•如果没有提供表名,视图列的名字将由定义的SELECT表达式自动生成
•如果修改基本表的属性,视图中不会体现,无效查询将会失败
•视图是只读的,不能用LOAD/INSERT/ALTER
•DROPVIEWview_name
•删除视图
创建数据库
•CREATEDATABASEname
显示命令
•showtables;
•showdatabases;
•showpartitions;
•showfunctions
•describeextendedtable_namedotcol_name
hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。
DML包括:INSERT插入、UPDATE更新、DELETE删除
•向数据表内加载文件
•将查询结果插入到Hive表中
•0.8新特性insertinto
向数据表内加载文件
•LOADDATA[LOCAL]INPATH'filepath'[OVERWRITE]INTOTABLEtablename[PARTITION(partcol1=val1,partcol2=val2...)]
•Load操作只是单纯的复制/移动操作,将数据文件移动到Hive表对应的位置。
•filepath
•相对路径,例如:project/data1
•绝对路径,例如:/user/hive/project/data1
•包含模式的完整URI,例如:hdfs://namenode:9000/user/hive/project/data1
例如:
hive>LOADDATALOCALINPATH'./examples/files/kv1.txt'OVERWRITEINTOTABLEpokes;
加载本地数据,同时给定分区信息
•加载的目标可以是一个表或者分区。如果表包含分区,必须指定每一个分区的分区名
•filepath可以引用一个文件(这种情况下,Hive会将文件移动到表所对应的目录中)或者是一个目录(在这种情况下,Hive会将目录中的所有文件移动至表所对应的目录中)
LOCAL关键字
•指定了LOCAL,即本地
•load命令会去查找本地文件系统中的filepath。如果发现是相对路径,则路径会被解释为相对于当前用户的当前路径。用户也可以为本地文件指定一个完整的URI,比如:file:///user/hive/project/data1.
•load命令会将filepath中的文件复制到目标文件系统中。目标文件系统由表的位置属性决定。被复制的数据文件移动到表的数据对应的位置
例如:加载本地数据,同时给定分区信息:
hive>LOADDATALOCALINPATH'./examples/files/kv2.txt'OVERWRITEINTOTABLEinvitesPARTITION(ds='2008-08-15');
•没有指定LOCAL
如果filepath指向的是一个完整的URI,hive会直接使用这个URI。否则
•如果没有指定schema或者authority,Hive会使用在hadoop配置文件中定义的schema和authority,fs.default.name指定了Namenode的URI
•如果路径不是绝对的,Hive相对于/user/进行解释。Hive会将filepath中指定的文件内容移动到table(或者partition)所指定的路径中
加载DFS数据,同时给定分区信息:
hive>LOADDATAINPATH'/user/myname/kv2.txt'OVERWRITEINTOTABLEinvitesPARTITION(ds='2008-08-15');
TheabovecommandwillloaddatafromanHDFSfile/directorytothetable.NotethatloadingdatafromHDFSwillresultinmovingthefile/directory.Asaresult,theoperationisalmostinstantaneous.
OVERWRITE
•指定了OVERWRITE
•目标表(或者分区)中的内容(如果有)会被删除,然后再将filepath指向的文件/目录中的内容添加到表/分区中。
•如果目标表(分区)已经有一个文件,并且文件名和filepath中的文件名冲突,那么现有的文件会被新文件所替代。
将查询结果插入Hive表
•将查询结果插入Hive表
•将查询结果写入HDFS文件系统
•基本模式
INSERTOVERWRITETABLEtablename1[PARTITION(partcol1=val1,partcol2=val2...)]select_statement1FROMfrom_statement
•多插入模式
FROMfrom_statement
INSERTOVERWRITETABLEtablename1[PARTITION(partcol1=val1,partcol2=val2...)]select_statement1
[INSERTOVERWRITETABLEtablename2[PARTITION...]select_statement2]...
•自动分区模式
INSERTOVERWRITETABLEtablenamePARTITION(partcol1[=val1],partcol2[=val2]...)select_statementFROMfrom_statement
将查询结果写入HDFS文件系统
•INSERTOVERWRITE[LOCAL]DIRECTORYdirectory1SELECT...FROM...
FROMfrom_statement
INSERTOVERWRITE[LOCAL]DIRECTORYdirectory1select_statement1
[INSERTOVERWRITE[LOCAL]DIRECTORYdirectory2select_statement2]
•
•数据写入文件系统时进行文本序列化,且每列用^A来区分,\n换行
INSERTINTO
•INSERTINTOTABLEtablename1[PARTITION(partcol1=val1,partcol2=val2...)]select_statement1FROMfrom_statement
SQL操作
•基本的Select操作
•基于Partition的查询
•Join
3.1基本的Select操作
SELECT[ALL|DISTINCT]select_expr,select_expr,...
FROMtable_reference
[WHEREwhere_condition]
[GROUPBYcol_list[HAVINGcondition]]
[CLUSTERBYcol_list
|[DISTRIBUTEBYcol_list][SORTBY|ORDERBYcol_list]
]
[LIMITnumber]
•使用ALL和DISTINCT选项区分对重复记录的处理。默认是ALL,表示查询所有记录。DISTINCT表示去掉重复的记录
•
•Where条件
•类似我们传统SQL的where条件
•目前支持AND,OR,0.9版本支持between
•IN,NOTIN
•不支持EXIST,NOTEXIST
ORDERBY与SORTBY的不同
•ORDERBY全局排序,只有一个Reduce任务
•SORTBY只在本机做排序
Limit
•Limit可以限制查询的记录数
SELECT*FROMt1LIMIT5
•实现Topk查询
•下面的查询语句查询销售记录最大的5个销售代表。
SETmapred.reduce.tasks=1
SELECT*FROMtestSORTBYamountDESCLIMIT5
•REGEXColumnSpecification
SELECT语句可以使用正则表达式做列选择,下面的语句查询除了ds和hr之外的所有列:
SELECT`(ds|hr)?+.+`FROMtest
例如
按先件查询
hive>SELECTa.fooFROMinvitesaWHEREa.ds='<DATE>';
将查询数据输出至目录:
hive>INSERTOVERWRITEDIRECTORY'/tmp/hdfs_out'SELECTa.*FROMinvitesaWHEREa.ds='<DATE>';
将查询结果输出至本地目录:
hive>INSERTOVERWRITELOCALDIRECTORY'/tmp/local_out'SELECTa.*FROMpokesa;
选择所有列到本地目录:
hive>INSERTOVERWRITETABLEeventsSELECTa.*FROMprofilesa;
hive>INSERTOVERWRITETABLEeventsSELECTa.*FROMprofilesaWHEREa.key<100;
hive>INSERTOVERWRITELOCALDIRECTORY'/tmp/reg_3'SELECTa.*FROMeventsa;
hive>INSERTOVERWRITEDIRECTORY'/tmp/reg_4'selecta.invites,a.pokesFROMprofilesa;
hive>INSERTOVERWRITEDIRECTORY'/tmp/reg_5'SELECTCOUNT(1)FROMinvitesaWHEREa.ds='<DATE>';
hive>INSERTOVERWRITEDIRECTORY'/tmp/reg_5'SELECTa.foo,a.barFROMinvitesa;
hive>INSERTOVERWRITELOCALDIRECTORY'/tmp/sum'SELECTSUM(a.pc)FROMpc1a;
将一个表的统计结果插入另一个表中:
hive>FROMinvitesaINSERTOVERWRITETABLEeventsSELECTa.bar,count(1)WHEREa.foo>0GROUPBYa.bar;
hive>INSERTOVERWRITETABLEeventsSELECTa.bar,count(1)FROMinvitesaWHEREa.foo>0GROUPBYa.bar;
JOIN
hive>FROMpokest1JOINinvitest2ON(t1.bar=t2.bar)INSERTOVERWRITETABLEeventsSELECTt1.bar,t1.foo,t2.foo;
将多表数据插入到同一表中:
FROMsrc
INSERTOVERWRITETABLEdest1SELECTsrc.*WHEREsrc.key<100
INSERTOVERWRITETABLEdest2SELECTsrc.key,src.valueWHEREsrc.key>=100andsrc.key<200
INSERTOVERWRITETABLEdest3PARTITION(ds='2008-04-08',hr='12')SELECTsrc.keyWHEREsrc.key>=200andsrc.key<300
INSERTOVERWRITELOCALDIRECTORY'/tmp/dest4.out'SELECTsrc.valueWHEREsrc.key>=300;
将文件流直接插入文件:
hive>FROMinvitesaINSERTOVERWRITETABLEeventsSELECTTRANSFORM(a.foo,a.bar)AS(oof,rab)USING'/bin/cat'WHEREa.ds>'2008-08-09';
Thisstreamsthedatainthemapphasethroughthescript/bin/cat(likehadoopstreaming).Similarly-streamingcanbeusedonthereduceside(pleaseseetheHiveTutorialorexamples)
3.2基于Partition的查询
•一般SELECT查询会扫描整个表,使用PARTITIONEDBY子句建表,查询就可以利用分区剪枝(inputpruning)的特性
•Hive当前的实现是,只有分区断言出现在离FROM子句最近的那个WHERE子句中,才会启用分区剪枝
3.3Join
Syntax
join_table:
table_referenceJOINtable_factor[join_condition]
|table_reference{LEFT|RIGHT|FULL}[OUTER]JOINtable_referencejoin_condition
|table_referenceLEFTSEMIJOINtable_referencejoin_condition
table_reference:
table_factor
|join_table
table_factor:
tbl_name[alias]
|table_subqueryalias
|(table_references)
join_condition:
ONequality_expression(ANDequality_expression)*
equality_expression:
expression=expression
•Hive只支持等值连接(equalityjoins)、外连接(outerjoins)和(leftsemijoins)。Hive不支持所有非等值的连接,因为非等值连接非常难转化到map/reduce任务
•LEFT,RIGHT和FULLOUTER关键字用于处理join中空记录的情况
•LEFTSEMIJOIN是IN/EXISTS子查询的一种更高效的实现
•join时,每次map/reduce任务的逻辑是这样的:reducer会缓存join序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统
•实践中,应该把最大的那个表写在最后
join查询时,需要注意几个关键点
•只支持等值join
•SELECTa.*FROMaJOINbON(a.id=b.id)
•SELECTa.*FROMaJOINb
ON(a.id=b.idANDa.department=b.department)
•可以join多于2个表,例如
SELECTa.val,b.val,c.valFROMaJOINb
ON(a.key=b.key1)JOINcON(c.key=b.key2)
•如果join中多个表的joinkey是同一个,则join会被转化为单个map/reduce任务
LEFT,RIGHT和FULLOUTER
•例子
•SELECTa.val,b.valFROMaLEFTOUTERJOINbON(a.key=b.key)
•如果你想限制join的输出,应该在WHERE子句中写过滤条件——或是在join子句中写
•
•容易混淆的问题是表分区的情况
•SELECTc.val,d.valFROMcLEFTOUTERJOINdON(c.key=d.key)
WHEREa.ds='2010-07-07'ANDb.ds='2010-07-07‘
•如果d表中找不到对应c表的记录,d表的所有列都会列出NULL,包括ds列。也就是说,join会过滤d表中不能找到匹配c表joinkey的所有记录。这样的话,LEFTOUTER就使得查询结果与WHERE子句无关
•解决办法
•SELECTc.val,d.valFROMcLEFTOUTERJOINd
ON(c.key=d.keyANDd.ds='2009-07-07'ANDc.ds='2009-07-07')
LEFTSEMIJOIN
•LEFTSEMIJOIN的限制是,JOIN子句中右边的表只能在ON子句中设置过滤条件,在WHERE子句、SELECT子句或其他地方过滤都不行
•
•SELECTa.key,a.value
FROMa
WHEREa.keyin
(SELECTb.key
FROMB);
可以被重写为:
SELECTa.key,a.val
FROMaLEFTSEMIJOINbon(a.key=b.key)
UNIONALL
•用来合并多个select的查询结果,需要保证select中字段须一致
•select_statementUNIONALLselect_statementUNIONALLselect_statement...
1、Hive不支持等值连接
•SQL中对两表内联可以写成:
•select*fromduala,dualbwherea.key=b.key;
•Hive中应为
•select*fromdualajoindualbona.key=b.key;
而不是传统的格式:
SELECTt1.a1asc1,t2.b1asc2FROMt1,t2WHEREt1.a2=t2.b2
2、分号字符
•分号是SQL语句结束标记,在HiveQL中也是,但是在HiveQL中,对分号的识别没有那么智慧,例如:
•selectconcat(key,concat(';',key))fromdual;
•但HiveQL在解析语句时提示:
FAILED:ParseError:line0:-1mismatchedinput'<EOF>'expecting)infunctionspecification
•解决的办法是,使用分号的八进制的ASCII码进行转义,那么上述语句应写成:
•selectconcat(key,concat('\073',key))fromdual;
3、IS[NOT]NULL
•SQL中null代表空值,值得警惕的是,在HiveQL中String类型的字段若是空(empty)字符串,即长度为0,那么对它进行ISNULL的判断结果是False.
4、Hive不支持将数据插入现有的表或分区中,
仅支持覆盖重写整个表,示例如下:
1.INSERTOVERWRITETABLEt1
2.SELECT*FROMt2;
4、hive不支持INSERTINTO,UPDATE,DELETE操作
这样的话,就不要很复杂的锁机制来读写数据。
INSERTINTOsyntaxisonlyavailablestartinginversion0.8。INSERTINTO就是在表或分区中追加数据。
5、hive支持嵌入mapreduce程序,来处理复杂的逻辑
如:
1.FROM(
2.MAPdoctextUSING'pythonwc_mapper.py'AS(word,cnt)
3.FROMdocs
4.CLUSTERBYword
5.)a
6.REDUCEword,cntUSING'pythonwc_reduce.py';
--doctext:是输入
--word,cnt:是map程序的输出
--CLUSTERBY:将wordhash后,又作为reduce程序的输入
并且map程序、reduce程序可以单独使用,如:
1.FROM(
2.FROMsession_table
3.SELECTsessionid,tstamp,data
4.DISTRIBUTEBYsessionidSORTBYtstamp
5.)a
6.REDUCEsessionid,tstamp,dataUSING'session_reducer.sh';
--DISTRIBUTEBY:用于给reduce程序分配行数据
6、hive支持将转换后的数据直接写入不同的表,还能写入分区、hdfs和本地目录。
这样能免除多次扫描输入表的开销。
1.FROMt1
2.
3.INSERTOVERWRITETABLEt2
4.SELECTt3.c2,count(1)
5.FROMt3
6.WHEREt3.c1<=20
7.GROUPBYt3.c2
8.
9.INSERTOVERWRITEDIRECTORY'/output_dir'
10.SELECTt3.c2,avg(t3.c1)
11.FROMt3
12.WHEREt3.c1>20ANDt3.c1<=30
13.GROUPBYt3.c2
14.
15.INSERTOVERWRITELOCALDIRECTORY'/home/dir'
16.SELECTt3.c2,sum(t3.c1)
17.FROMt3
18.WHEREt3.c1>30
19.GROUPBYt3.c2;
创建一个表
CREATETABLEu_data(
useridINT,
movieidINT,
ratingINT,
unixtimeSTRING)
ROWFORMATDELIMITED
FIELDSTERMINATEDBY'/t'
STOREDASTEXTFILE;
下载示例数据文件,并解压缩
wgethttp://www.grouplens.org/system/files/ml-data.tar__0.gz
tarxvzfml-data.tar__0.gz
加载数据到表中:
LOADDATALOCALINPATH'ml-data/u.data'
OVERWRITEINTOTABLEu_data;
统计数据总量:
SELECTCOUNT(1)FROMu_data;
现在做一些复杂的数据分析:
创建一个weekday_mapper.py:文件,作为数据按周进行分割
importsys
importdatetime
forlineinsys.stdin:
line=line.strip()
userid,movieid,rating,unixtime=line.split('/t')
生成数据的周信息
weekday=datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print'/t'.join([userid,movieid,rating,str(weekday)])
使用映射脚本
//创建表,按分割符分割行中的字段值
CREATETABLEu_data_new(
useridINT,
movieidINT,
ratingINT,
weekdayINT)
ROWFORMATDELIMITED
FIELDSTERMINATEDBY'/t';
//将python文件加载到系统
addFILEweekday_mapper.py;
将数据按周进行分割
INSERTOVERWRITETABLEu_data_new
SELECT
TRANSFORM(userid,movieid,rating,unixtime)
USING'pythonweekday_mapper.py'
AS(userid,movieid,rating,weekday)
FROMu_data;
SELECTweekday,COUNT(1)
FROMu_data_new
GROUPBYweekday;
处理ApacheWeblog数据
将WEB日志先用正则表达式进行组合,再按需要的条件进行组合输入到表中
addjar../build/contrib/hive_contrib.jar;
CREATETABLEapachelog(
hostSTRING,
identitySTRING,
userSTRING,
timeSTRING,
requestSTRING,
statusSTRING,
sizeSTRING,
refererSTRING,
agentSTRING)
ROWFORMATSERDE'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITHSERDEPROPERTIES(
"input.regex"="([^]*)([^]*)([^]*)(-|//[[^//]]*//])([^/"]*|/"[^/"]*/")(-|[0-9]*)(-|[0-9]*)(?:([^/"]*|/"[^/"]*/")([^/"]*|/"[^/"]*/"))?",
"output.format.string"="%1$s%2$s%3$s%4$s%5$s%6$s%7$s%8$s%9$s"
)
STOREDASTEXTFILE;
24.
25.Datanode在什么情况下不备份
26.在配置文件中datanode的数量设置为1时
27.Combiner出现在那个过程
28.Hdfs体系结构
我们首先介绍HDFS的体系结构,HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。图1-3给出了HDFS的体系结构。
NameNode和DataNode都被设计成可以在普通商用计算机上运行。这些计算机通常运行的是GNU/Linux操作系统。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署NameNode和DataNode。一个典型的部署场景是集群中的一台机器运行一个NameNode实例,其他机器分别运行一个DataNode实例。当然,并不排除一台机器运行多个DataNode实例的情况。集群中单一的NameNode的设计则大大简化了系统的架构。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
| (点击查看大图)图1-3 HDFS的体系结构图 |
29.
30.Flush体系结构
31.什么是列队linkedList队列
32.List和set去表
33.数据库三大范式
34.第一范式,又称1NF,它指的是在一个应用中的数据都可以组织成由行和列的表格形式,且表格的任意一个行列交叉点即单元格,都不可再划分为行和列的形式,实际上任意一张表格都满足1NF;第二范式,又称2NF,它指的是在满足1NF的基础上,一张数据表中的任何非主键字段都全部依赖于主键字段,没有任何非主键字段只依赖于主键字段的一部分。即,可以由主键字段来唯一的确定一条记录。比如学号+课程号的联合主键,可以唯一的确定某个成绩是哪个学员的哪门课的成绩,缺少学号或者缺少课程号,都不能确定成绩的意义。第三范式,又称3NF,它是指在满足2NF的基础上,数据表的任何非主键字段之间都不产生函数依赖,即非主键字段之间没有依赖关系,全部只依赖于主键字段。例如将学员姓名和所属班级名称放在同一张表中是不科学的,因为学员依赖于班级,可将学员信息和班级信息单独存放,以满足3NF。
35.三个datanode当有一个出现错误会怎么样
36.Sgoop导入数据到mysql中如何让数据不重复导入?存在数据问题sgoop会怎么样
37.
38.
39.Hadop基础知识和问题分析能力
3.1描述一下hadoop中,有哪些地方使用了缓存机制,作用分别是什么
3.2请描述https://issues.apache.org/jira/browse/HDFS-2379说的是什么问题,最终解
决的思路是什么?
4、MapReduce开发能力
请参照wordcount实现一个自己的mapreduce,需求为:
a输入文件格式:
xxx,xxx,xxx,xxx,xxx,xxx,xxx
b输出文件格式:
xxx,20
xxx,30
xxx.40
c功能:根据命令行参数统计输入文件中指定关键字出现的次数,并展示出来
例如:hadoopjarxxxxx.jarkeywordcountxxx,xxx,xxx,xxx(四个关键字)
5、MapReduce优化
请根据第五题中的程序,提出如何优化MR程序运行速度的思路
6、Linux操作系统知识考察
请列举曾经修改过的/etc下的配置文件,并说明修改要解决的问题?
7、Java开发能力
7.1写代码实现1G大小的文本文件,行分隔符为\x01\x02,统计一下该文件中的总行数,
要求注意边界情况的处理
7.2请描述一下在开发中如何对上面的程序进行性能分析,对性能进行优化的过程。
五、来自*****提供的hadoop面试题21道:
1、设计一套系统,使之能够从不断增加的不同的数据源中,提取指定格式的数据。
要求:
编者QQ:104019525316
1)、运行结果要能大致得知提取效果,并可据此持续改进提取方法;
2)、由于数据来源的差异性,请给出可弹性配置的程序框架;
3)、数据来源可能有Mysql,sqlserver等;
4)、该系统具备持续挖掘的能力,即,可重复提取更多信息
2.经典的一道题:
现有1亿个整数均匀分布,如果要得到前1K个最大的数,求最优的算法。
(先不考虑内存的限制,也不考虑读写外存,时间复杂度最少的算法即为最优算法)
我先说下我的想法:分块,比如分1W块,每块1W个,然后分别找出每块最大值,从这最
大的1W个值中找最大1K个,
那么其他的9K个最大值所在的块即可扔掉,从剩下的最大的1K个值所在的块中找前1K
个即可。那么原问题的规模就缩小到了1/10。
问题:
(1)这种分块方法的最优时间复杂度。
(2)如何分块达到最优。比如也可分10W块,每块1000个数。则问题规模可降到原来
1/100。但事实上复杂度并没降低。
(3)还有没更好更优的方法解决这个问题。
3.MapReduce大致流程?
4.combiner,partition作用?
5.用mapreduce实现sql语句selectcount(x)fromagroupbyb?
6.用mapreduce如何实现两张表连接,有哪些方法?
7.知道MapReduce大致流程,map,shuffle,reduce
编者QQ:104019525317
8.知道combiner,partition作用,设置compression
9.搭建hadoop集群,master/slave都运行那些服务
10.HDFS,replica如何定位
11.版本0.20.2->0.20.203->0.20.205,0.21,0.23,1.0.1
新旧API有什么不同
12.Hadoop参数调优,clusterlevel:JVM,map/reduceslots,joblevel:reducer
#,memory,usecombiner?usecompression?
13.piglatin,Hive语法有什么不同
14.描述HBase,zookeeper搭建过程
15.hadoop运行的原理?
16.mapreduce的原理?
17.HDFS存储的机制?
18.举一个简单的例子说明mapreduce是怎么来运行的?
19.使用mapreduce来实现下面实例
实例:现在有10个文件夹,每个文件夹都有1000000个url.现在让你找出
top1000000url。
20.hadoop中Combiner的作用?
21.如何确认Hadoop集群的健康状况。
六、来自****提供的hadoop面试题9道:
1.使用的hadoop版本都是什么?
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525318
2.mpareduce原理是什么?
3.mapreduce作业,不使用reduce来输出,用什么能代替reduce的功能
4.hive如何调优?
5.hive如何权限控制?
6.hbase写数据的原理是什么?
7.hive能像关系数据库那样,建多个库吗?
8.hbase宕机如何处理?
9.假设公司要建一个数据中心,你会如何规划?
七、hadoop选择判断题33道:
单项选择题
1.下面哪个程序负责HDFS数据存储。
a)NameNodeb)Jobtrackerc)Datanoded)secondaryNameNodee)tasktracker
2.HDfS中的block默认保存几份?
a)3份b)2份c)1份d)不确定
3.下列哪个程序通常与NameNode在一个节点启动?
a)SecondaryNameNodeb)DataNodec)TaskTrackerd)Jobtracker
4.Hadoop作者
a)MartinFowlerb)KentBeckc)Dougcutting
5.HDFS默认BlockSize
a)32MBb)64MBc)128MB
6.下列哪项通常是集群的最主要瓶颈
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525319
a)CPUb)网络c)磁盘d)内存
7.关于SecondaryNameNode哪项是正确的?
a)它是NameNode的热备b)它对内存没有要求
c)它的目的是帮助NameNode合并编辑日志,减少NameNode启动时间
d)SecondaryNameNode应与NameNode部署到一个节点
多选题:
8.下列哪项可以作为集群的管理工具
a)Puppetb)Pdshc)ClouderaManagerd)d)Zookeeper
9.配置机架感知的下面哪项正确
a)如果一个机架出问题,不会影响数据读写
b)写入数据的时候会写到不同机架的DataNode中
c)MapReduce会根据机架获取离自己比较近的网络数据
10.Client端上传文件的时候下列哪项正确
a)数据经过NameNode传递给DataNode
b)Client端将文件切分为Block,依次上传
c)Client只上传数据到一台DataNode,然后由NameNode负责Block复制工作
11.下列哪个是Hadoop运行的模式
a)单机版b)伪分布式c)分布式
12.Cloudera提供哪几种安装CDH的方法
a)Clouderamanagerb)Tarballc)Yumd)Rpm
判断题:
13.Ganglia不仅可以进行监控,也可以进行告警。()
14.BlockSize是不可以修改的。()
15.Nagios不可以监控Hadoop集群,因为它不提供Hadoop支持。()
16.如果NameNode意外终止,SecondaryNameNode会接替它使集群继续工作。()
17.ClouderaCDH是需要付费使用的。()
18.Hadoop是Java开发的,所以MapReduce只支持Java语言编写。()
19.Hadoop支持数据的随机读写。()
20.NameNode负责管理metadata,client端每次读写请求,它都会从磁盘中读取或则
会写
入metadata信息并反馈client端。()
21.NameNode本地磁盘保存了Block的位置信息。()
22.DataNode通过长连接与NameNode保持通信。()
23.Hadoop自身具有严格的权限管理和安全措施保障集群正常运行。()
24.Slave节点要存储数据,所以它的磁盘越大越好。()
25.hadoopdfsadmin–report命令用于检测HDFS损坏块。()
26.Hadoop默认调度器策略为FIFO()
27.集群内每个节点都应该配RAID,这样避免单磁盘损坏,影响整个节点运行。()
28.因为HDFS有多个副本,所以NameNode是不存在单点问题的。()
29.每个map槽就是一个线程。()
30.Mapreduce的inputsplit就是一个block。()
31.NameNode的WebUI端口是50030,它通过jetty启动的Web服务。()
32.Hadoop环境变量中的HADOOP_HEAPSIZE用于设置所有Hadoop守护线程的内
存。它默
认是200GB。()
33.DataNode首次加入cluster的时候,如果log中报告不兼容文件版本,那需要
NameNode
执行“Hadoopnamenode-format”操作格式化磁盘。()
八、mr和hive实现手机流量统计面试题6道:
1.hive实现统计的查询语句是什么?
2.生产环境中为什么建议使用外部表?
3.hadoopmapreduce创建类DataWritable的作用是什么?
4.为什么创建类DataWritable?
5.如何实现统计手机流量?
6.对比hive与mapreduce统计手机流量的区别?
九、来自aboutyun的面试题1道:
最近去面试,出了个这样的题目,大家有兴趣也试试。
用Hadoop分析海量日志文件,每行日志记录了如下数据:
TableName(表名),Time(时间),User(用户),TimeSpan(时间开销)。
要求:
编写MapReduce程序算出高峰时间段(如上午10点)哪张表被访问的最频繁,以及
十、来自aboutyun的面试题6道:
前段时间接到阿里巴巴面试云计算,拿出来给我们共享下
1、hadoop运转的原理?
2、mapreduce的原理?
3、HDFS存储的机制?
4、举一个简略的比方阐明mapreduce是怎么来运转的?
5、面试的人给你出一些疑问,让你用mapreduce来完成?
比方:如今有10个文件夹,每个文件夹都有1000000个url.如今让你找出
top1000000url。
6、hadoop中Combiner的效果?
论坛某网友的回复:
1.hadoop即是mapreduce的进程,服务器上的一个目录节点加上多个数据节点,将程序
传递到各个节点,再节点上进行计算。
2.mapreduce即是将数据存储到不一样的节点上,用map方法对应办理,在各个节点上
进行计算,最后由reduce进行合并。
3.java程序和namenode合作,把数据存放在不一样的数据节点上
4.怎么运转用图来表明最好了。图无法画。谷歌下
5.不思考歪斜,功能,运用2个job,第一个job直接用filesystem读取10个文件夹作为
map输入,url做key,reduce计算个url的sum,
下一个jobmap顶用url作key,运用-sum作二次排序,reduce中取top10000000
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525323
第二种方法,建hive表A,挂分区channel,每个文件夹是一个分区.
selectx.url,x.cfrom(selecturl,count(1)ascfromAwherechannel=''groupby
url)xorderbyx.cdesclimie1000000;
6combiner也是一个reduce,它可以削减map到reudce的数据传输,进步shuff速度。
牢记平均值不要用。需求输入=map的输出,输出=reduce的输入。
十一、小萝卜(hadoop月薪13k)的笔试和面试题11道:
一、笔试
1、java基础类:
1)继承:写的一段代码,让写出结果;
2)引用对象和值对象;
Java基础类记不太清了,有很多都是基础。
2、linux基础:
1)find用法
2)给出一个文本:比如http://aaa.com
http://bbb.com
http://bbb.com
http://bbb.com
http://ccc.com
http://ccc.com
让写shell统计,最后输出结果:aaa1
Ccc2
Bbb3
要求结果还要排序
还有别的,也是比较基础的
3、数据库类:oracle查询语句
二、面试
讲项目经验:问的很细,给纸,笔,让画公司hadoop的项目架构,最后还让自己说几条业
务数据,然后经过平台后,出来成什么样子。
java方面:io输入输出流里有哪些常用的类,还有webService,线程相关的知识
linux:问到jps命令,kill命令,问awk,sed是干什么用的、还有hadoop的一些常用命
令
hadoop:讲hadoop1中map,shuffle,reduce的过程,其中问到了map端和reduce端
溢写的细节(幸好我之前有研究过)
项目部署:问了项目是怎么部署,代码怎么管理
Hive也问了一些,外部表,还有就是hive的物理模型跟传统数据库的不同
三、某互联网公司的面试:
问到分析人行为的算法:我当时想到我们做的反洗钱项目中,有用到。我就给举例:我
们是怎么筛选出可疑的洗钱行为的。
十二、闪客、找自己、大数等提供的面试题26道:
****信Hadoop面试笔试题(共14题,还有一题记不住了)
1、hadoop集群搭建过程,写出步骤。
2、hadoop集群运行过程中启动那些线程,各自的作用是什么?
3、/tmp/hadoop-root/dfs/namethepathisnotexistsorisnotaccessable.
NameNodemain中报错,该怎么解决。(大意这样一个什么异常)
4、工作中编写mapreduce用到的语言,编写一个mapreduce程序。
5、hadoop命令
1)杀死一个job任务(杀死50030端口的进程即可)
2)删除/tmp/aaa文件目录
3)hadoop集群添加或删除节点时,刷新集群状态的命令
6、日志的固定格式:
a,b,c,d
a,a,f,e
b,b,d,f
使用一种语言编写mapreduce任务,统计每一列最后字母的个数。
7、hadoop的调度器有哪些,工作原理。
8、mapreduce的join方法有哪些?
9、Hive元数据保存的方法有哪些,各有什么特点?
10、java实现非递归二分法算法。
11、mapreduce中Combiner和Partition的作用。
12、用linux实现下列要求:
ipusername
a.txt
210.121.123.12zhangsan
34.23.56.78lisi
编者QQ:104019525326
11.56.56.72wanger
.....
b.txt
58.23.53.132liuqi
34.23.56.78liba
.....
a.txt,b.txt中至少100万行。
1)a.txt,b.txt中各自的ip个数,ip的总个数。
2)a.txt中存在的ip而b.txt中不存在的ip。
3)每个username出现的总个数,每个username对应的ip个数。
13、大意是hadoop中java、streaming、pipe处理数据各有特点。
14、如何实现mapreduce的二次排序。
大数遇到的面试题:
15、面试官上来就问hadoop的调度机制;
16、机架感知;
17、MR数据倾斜原因和解决方案;
18、集群HA。
@找自己提供的面试题:
19、如果让你设计,你觉得一个分布式文件系统应该如何设计,考虑哪方面内容;
每天百亿数据入hbase,如何保证数据的存储正确和在规定的时间里全部录入完毕,
不残留数据。
20、对于hive,你写过哪些UDF函数,作用是什么
21、hdfs的数据压缩算法
22、mapreduce的调度模式
23、hive底层与数据库交互原理
24、hbase过滤器实现原则
25、对于mahout,如何进行推荐、分类、聚类的代码二次开发分别实现那些借口
26、请问下,直接将时间戳作为行健,在写入单个region时候会发生热点问题,为什么呢?
十三、飞哥(hadoop月薪13k)提供的面试题17道:
1、hdfs原理,以及各个模块的职责
2、mr的工作原理
3、map方法是如何调用reduce方法的
4、shell如何判断文件是否存在,如果不存在该如何处理?
5、fsimage和edit的区别?
6、hadoop1和hadoop2的区别?
笔试:
1、hdfs中的block默认报错几份?
2、哪个程序通常与nn在一个节点启动?并做分析
3、列举几个配置文件优化?
4、写出你对zookeeper的理解
5、datanode首次加入cluster的时候,如果log报告不兼容文件版本,那需要namenode
执行格式化操作,这样处理的原因是?
6、谈谈数据倾斜,如何发生的,并给出优化方案
7、介绍一下hbase过滤器
8、mapreduce基本执行过程
9、谈谈hadoop1和hadoop2的区别
10、hbase集群安装注意事项
11、记录包含值域F和值域G,要分别统计相同G值的记录中不同的F值的数目,简单编
写过程。
十四、飞哥(hadoop月薪13k)提供的面试题3道:
1、算法题:有2个桶,容量分别为3升和5升,如何得到4升的水,假设水无限使用,写
出步骤。
2、java笔试题:忘记拍照了,很多很基础的se知识。后面还有很多sql相关的题,常用的
查询sql编写,答题时间一个小时。
3、Oracle数据库中有一个表字段name,namevarchar2(10),如何在不改变表数据的情况
下将此字段长度改为varchar2(2)?
十五、海量数据处理算法面试题10道:
第一部分:十道海量数据处理面试题
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到
IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个
大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525329
进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的
IP中,找出那个频率最大的IP,即为所求。
或者如下阐述(雪域之鹰):
算法思想:分而治之+Hash
(1).IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理;
(2).可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP
日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址;
(3).对于每一个小文件,可以构建一个IP为key,出现次数为value的Hashmap,同
时记录当前出现次数最多的那个IP地址;
(4).可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上
出现次数最多的IP;
2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的
长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果
除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就
是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
典型的TopK算法,还是在这篇文章里头有所阐述,详情请参见:十一、从头到尾彻底解
析Hash表算法。
文中,给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了
排序,特此订正。July、2011.04.27);
第二步、借助堆这个数据结构,找出TopK,时间复杂度为N‘logK。
即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题
目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们
最终的时间复杂度是:O(N)+N’*O(logK),(N为1000万,N’为300万)。ok,
更多,详情,请参考原文。
或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的
最小推来对出现频率进行排序。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限
制大小是1M。返回频数最高的100个词。
方案:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文
件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。
如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到
的小文件的大小都不超过1M。
对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),
并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应
的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类
似与归并排序)的过程了。
4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的
query都可能重复。要求你按照query的频度排序。
还是典型的TOPK算法,解决方案如下:
方案1:
顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)
中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
找一台内存在2G左右的机器,依次对用hash_map(query,query_count)来统计每个
query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和
对应的query_cout输出到文件中。这样得到了10个排好序的文件(记为)。
对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次
性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query
出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式
的架构来处理(比如MapReduce),最后再进行合并。
5、给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让
你找出a、b文件共同的url?
方案1:可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不
可能将其完全加载到内存中处理。考虑采取分而治之的方法。
遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000
个小文件(记为a0,a1,…,a999)中。这样每个小文件的大约为300M。
遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,…,b999)。
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525332
这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,…,a999vsb999)
中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url
即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍
历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同
的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloomfilter,4G内存大概可以表示340亿
bit。将其中一个文件中的url使用Bloomfilter映射为这340亿bit,然后挨个读取另外一
个文件的url,检查是否与Bloomfilter,如果是,那么该url应该是共同的url(注意会有
一定的错误率)。
Bloomfilter日后会在本BLOG内详细阐述。
6、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多
次,11无意义)进行,共需内存2^32*2bit=1GB内存,还可以接受。然后扫描这2.5
亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完
事后,查看bitmap,把对应位是01的整数输出即可。
方案2:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重
复的整数,并排序。然后再进行归并,注意去除重复的元素。
7、腾讯面试题:给40亿个不重复的unsignedint的整数,没排过序的,然后再给一个数,
如何快速判断这个数是否在那40亿个数当中?
与上第6题类似,我的第一反应时快速排序+二分查找。以下是其它更好的方法:
方案1:oo,申请512M的内存,一个bit位代表一个unsignedint值。读入40亿个数,
设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示
不存在。
dizengrong:
方案2:这个问题在《编程珠玑》里有很好的描述,大家可以参考下面的思路,探讨一下:
又因为2^32为40亿多,所以给定一个数可能在,也可能不在其中;
这里我们把40亿个数中的每一个用32位的二进制来表示
假设这40亿个数开始放在一个文件中。
然后将这40亿个数分成两类:
1.最高位为0
2.最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=20亿,而另一个>=20亿
(这相当于折半了);
与要查找的数的最高位比较并接着进入相应的文件再查找
再然后把这个文件为又分成两类:
1.次最高位为0
2.次最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=10亿,而另一个>=10亿
(这相当于折半了);
与要查找的数的次最高位比较并接着进入相应的文件再查找。
…….
以此类推,就可以找到了,而且时间复杂度为O(logn),方案2完。
附:这里,再简单介绍下,位图方法:
使用位图法判断整形数组是否存在重复
判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几
次扫描,这时双重循环法就不可取了。
位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1
的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上1,如遇到5就给新数
组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这
说明这次的数据肯定和以前的数据存在着重复。这种给新数组初始化时置零其后置一的做
法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最
大值即能事先给新数组定长的话效率还能提高一倍。
欢迎,有更好的思路,或方法,共同交流。
8、怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并
记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面
的题)。
9、上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/
搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以
用第2题提到的堆机制完成。
10、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,
请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le
表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题
中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)
中较大的哪一个。
附、100w个数中找出最大的100个数。
方案1:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为
O(100w*lg100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分
在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的
元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最
小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有
的元素。复杂度为O(100w*100)。
致谢:http://www.cnblogs.com/youwang/。
第二部分:十个海量数据处理方法大总结
ok,看了上面这么多的面试题,是否有点头晕。是的,需要一个总结。接下来,本文将简
单总结下一些处理海量数据问题的常见方法,而日后,本BLOG内会具体阐述这些方法。
下面的方法全部来自http://hi.baidu.com/yanxionglu/blog/博客,对海量数据的处理方
法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一
些方法也基本可以处理绝大多数遇到的问题。下面的一些问题基本直接来源于公司的面试笔
试题目,方法不一定最优,如果你有更好的处理方法,欢迎讨论。
一、Bloomfilter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,
查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结
果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会
牵动到其他的关键字。所以一个简单的改进就是countingBloomfilter,用一个counter
数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个
数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少
要等于n*lg(1/E)才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit
数组里至少一半为0,则m应该>=nlg(1/E)*lge大概就是nlg(1/E)1.44倍(lg表示以2为
底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不
同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloomfilter内存上通
常都是节省的。
扩展:
Bloomfilter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全
1表示元素在不在这个集合中。Countingbloomfilter(CBF)将位数组中的每一位扩展为
一个counter,从而支持了元素的删除操作。SpectralBloomFilter(SBF)将其与集合元
素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是
4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿,n=50
亿,如果按出错率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,
这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大
大简单了。
二、Hashing
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存
基本原理及要点:
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是openhashing,也称为拉链法;另一种就是closedhashing,也称开
地址法,openedaddressing。
扩展:
d-lefthashing中的d是多个的意思,我们先简化这个问题,看一看2-lefthashing。2-left
hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别
配备一个哈希函数,h1和h2。在存储一个新的key时,同时用两个哈希函数进行计算,
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525338
得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]
位置,哪一个位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位
置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key存储在左
边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找
两个位置。
问题实例:
1).海量日志数据,提取出某日访问百度次数最多的那个IP。
IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后
进行统计。
三、bit-map
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展:bloomfilter可以看做是对bit-map的扩展
问题实例:
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99999999,大概需要99m个bit,大概10几m字节的内存即可。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示
出现2次及以上。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个
2bit-map。
四、堆
适用范围:海量数据前n大,并且n比较小,堆可以放入内存
基本原理及要点:最大堆求前n小,最小堆求前n大。方法,比如求前n小,我们比较当
前元素与最大堆里的最大元素,如果它小于最大元素,则应该替换那个最大元素。这样最
后得到的n个元素就是最小的n个。适合大数据量,求前n小,n的大小比较小的情况,
这样可以扫描一遍即可得到所有的前n元素,效率很高。
扩展:双堆,一个最大堆与一个最小堆结合,可以用来维护中位数。
问题实例:
1)100w个数中找最大的前100个数。
用一个100个元素大小的最小堆即可。
五、双层桶划分—-其实本质上就是【分而治之】的思想,重在“分”的技巧上!
适用范围:第k大,中位数,不重复或重复的数字
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定
范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
1).2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区
域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用
bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2).5亿个int找它们的中位数。
编者QQ:104019525340
这个例子比上面那个更明显。首先我们将int划分为2^16个区域,然后读取数据统计落
到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知
道这个区域中的第几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那
些数就可以了。
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受的程度。
即可以先将int64分成2^24个区域,然后确定区域的第几大数,在将该区域分成2^20个
子区域,然后确定是子区域的第几大数,然后子区域里的数的个数只有2^20,就可以直
接利用directaddrtable进行统计了。
六、数据库索引
适用范围:大数据量的增删改查
基本原理及要点:利用数据的设计实现方法,对海量数据的增删改查进行处理。
七、倒排索引(Invertedindex)
适用范围:搜索引擎,关键字查询
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一
个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0=“itiswhatitis”
T1=“whatisit”
T2=“itisabanana”
我们就能得到下面的反向文件索引:
“a”:{2}
“banana”:{2}
“is”:{0,1,2}
“it”:{0,1,2}
“what”:{0,1}
检索的条件”what”,”is”和”it”将对应集合的交集。
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序
频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中
心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档指向了它包含的
那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
八、外排序
适用范围:大数据的排序,去重
基本原理及要点:外排序的归并方法,置换选择败者树原理,最优归并树
扩展:
问题实例:
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限
制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,
所以可以用来排序。内存可以当输入缓冲区使用。
九、trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
1).有10个文件,每个文件1G,每个文件的每一行都存放的是用户的query,每个文件的
query都可能重复。要你按照query的频度排序。
2).1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符
串。请问怎么设计和实现?
3).寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超
过3百万个,每个不超过255字节。
十、分布式处理mapreduce
适用范围:数据量大,但是数据种类小可以放入内存
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
扩展:
问题实例:
1).ThecanonicalexampleapplicationofMapReduceisaprocesstocountthe
appearancesof
eachdifferentwordinasetofdocuments:
2).海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
3).一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如
何找到N^2个数的中数(median)?
经典问题分析
上千万or亿数据(有重复),统计其中出现次数最多的前N个数据,分两种情况:可一次读
入内存,不可一次读入。
可用思路:trie树+堆,数据库索引,划分子集分别统计,hash,分布式计算,近似统计,
外排序
所谓的是否能一次读入内存,实际上应该指去除重复后的数据量。如果去重后数据可以
放入内存,我们可以为数据建立字典,比如通过map,hashmap,trie,然后直接进行统
计即可。当然在更新每条数据的出现次数的时候,我们可以利用一个堆来维护出现次数最多
的前N个数据,当然这样导致维护次数增加,不如完全统计后在求前N大效率高。
如果数据无法放入内存。一方面我们可以考虑上面的字典方法能否被改进以适应这种情
形,可以做的改变就是将字典存放到硬盘上,而不是内存,这可以参考数据库的存储方法。
当然还有更好的方法,就是可以采用分布式计算,基本上就是map-reduce过程,首
先可以根据数据值或者把数据hash(md5)后的值,将数据按照范围划分到不同的机子,最
好可以让数据划分后可以一次读入内存,这样不同的机子负责处理各种的数值范围,实际
上就是map。得到结果后,各个机子只需拿出各自的出现次数最多的前N个数据,然后汇
总,选出所有的数据中出现次数最多的前N个数据,这实际上就是reduce过程。
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525344
实际上可能想直接将数据均分到不同的机子上进行处理,这样是无法得到正确的解的。
因为一个数据可能被均分到不同的机子上,而另一个则可能完全聚集到一个机子上,同时还
可能存在具有相同数目的数据。比如我们要找出现次数最多的前100个,我们将1000万
的数据分布到10台机器上,找到每台出现次数最多的前100个,归并之后这样不能保证
找到真正的第100个,因为比如出现次数最多的第100个可能有1万个,但是它被分到了
10台机子,这样在每台上只有1千个,假设这些机子排名在1000个之前的那些都是单独
分布在一台机子上的,比如有1001个,这样本来具有1万个的这个就会被淘汰,即使我们
让每台机子选出出现次数最多的1000个再归并,仍然会出错,因为可能存在大量个数为
1001个的发生聚集。因此不能将数据随便均分到不同机子上,而是要根据hash后的值将
它们映射到不同的机子上处理,让不同的机器处理一个数值范围。
而外排序的方法会消耗大量的IO,效率不会很高。而上面的分布式方法,也可以用于
单机版本,也就是将总的数据根据值的范围,划分成多个不同的子文件,然后逐个处理。处
理完毕之后再对这些单词的及其出现频率进行一个归并。实际上就可以利用一个外排序的归
并过程。
另外,还可以考虑近似计算,也就是我们可以通过结合自然语言属性,只将那些真正实
际中出现最多的那些词作为一个字典,使得这个规模可以放入内存。
十六、来自aboutyun的面试题6道:
1.说说值对象与引用对象的区别?
2.谈谈你对反射机制的理解及其用途?
3.ArrayList、Vector、LinkedList的区别及其优缺点?HashMap、HashTable的区别及其
优缺点?
3.列出线程的实现方式?如何实现同步?
4.sql题,是一个图表,具体忘了
5.列出至少五种设计模式?用代码或UML类图描述其中两种设计模式的原理?
6.谈谈你最近正在研究的技术,谈谈你最近项目中用到的技术难点及其解决思路。
十七、来自巴图提供的算法面试题1道:
用户手机号出现的地点出现的时间逗留的时间
11111111122014-02-1819:03:56.123445133
22222222212013-03-1403:18:45.263536241
33333333332014-10-2317:14:23.17634568
22222222212013-03-1403:20:47.123445145
33333333332014-09-1515:24:56.222222345
22222222222011-08-3018:13:58.111111145
22222222222011-08-3018:18:24.222222130
按时间排序
期望结果是:
22222222222011-08-3018:13:58.111111145
22222222222011-08-3018:18:24.222222130
22222222212013-03-1403:18:45.26353624
111111111~~~~~~~~
333333333~~~~~~~
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525346
十八、来自象夫提供的面试题7道:
Hdfs:
1.文件大小默认为64M,改为128M有啥影响?
2.RPC原理?
3.NameNode与SecondaryNameNode的区别与联系?
MapReduce:
4.介绍MadpReduce整个过程,比如把WordCount的例子的细节将清楚(重点讲解
Shuffle)?
5.对Hadoop有没有调优经验,没有什么使用心得?(调优从参数调优讲起)
6.MapReduce出现单点负载多大,怎么负载平衡?(可以用Partitioner)
7.MapReduce怎么实现Top10?
十九、来自mo•mo•ring提供的面试题13道:
xxxx软件公司
1.你胜任该职位有什么优势
2.java优势及原因(至少3个)
3.jvm优化
4.写一个冒泡程序
5.hadoop底层存储设计
6.职业规划
xxx网络公司
1.数据库
1.1第一范式,第二范式和第三范式
1.2给出两张数据表,优化表(具体字段不记得了,是关于商品定单和供应商方面的)
1.3以你的实际经验,说下怎样预防全表扫描
2.网络七层协议
3.多线程
4.集合HashTable和HashMap区别
5.操作系统碎片
6.zookeeper优点,用在什么场合
7.Hbase中的metastore用来做什么的?
二十、来自Clouds提供的面试题18道:
1,在线安装ssh的命令以及文件解压的命令?
2,把公钥都追加到授权文件的命令?该命令是否在root用户下执行?
3,HadoopHA集群中哥哥服务的启动和关闭的顺序?
4,HDFS中的block块默认保存几份?默认大小多少?
5,NameNode中的meta数据是存放在NameNode自身,还是DataNode等其他节点?
DatNOde节点自身是否有Meta数据存在?
6,下列那个程序通常与NameNode在一个节点启动?
7,下面那个程序负责HDFS数据存储?
8,在HadoopHA集群中国Zookeeper的主要作用,以及启动和查看状态的命令?
9,HBase在进行模型设计时重点在什么地方?一张表中国定义多少个ColumnFamily
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525348
最合适?为什么?
10,如何提高HBase客户端的读写性能?请举例说明。
11,基于HadoopHA集群记性MapReduce开发时,Configuration如何设置
hbase.zookeeper,quorum属性的值?
12,在hadoop开发过程中使用过哪些算法?其应用场景是什么?
13,MapReduce程序如何发布?如果MapReduce中涉及到了第三方的jar包,该如何
处理?
14,在实际工作中使用过哪些集群的运维工具,请分别阐述期作用。
15,hadoop中combiner的作用?
16,IO的原理,IO模型有几种?
17,Windows用什么样的模型,Linux用什么样的模型?
18,一台机器如何应对那么多的请求访问,高并发到底怎么实现,一个请求怎么产生的,
在服务端怎么处理的,最后怎么返回给用户的,整个的环节操作系统是怎么控制的?
二十一、来自****提供的面试题11道:
1.hdfs的client端,复制到第三个副本时宕机,hdfs怎么恢复保证下次写第三副本?block
块信息是先写dataNode还是先写nameNode?
2.快排现场写程序实现?
3.jvm的内存是怎么分配原理?
4.毒酒问题---1000桶酒,其中1桶有毒。而一旦吃了,毒性会在1周后发作。问最少需要
多少只老鼠可在一周内找出毒酒?
5.用栈实现队列?
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525349
6.链表倒序实现?
7.多线程模型怎样(生产,消费者)?平时并发多线程都用哪些实现方式?
8.synchonized是同步悲观锁吗?互斥?怎么写同步提高效率?
9.4亿个数字,找出哪些重复的,要用最小的比较次数,写程序实现。
10.java是传值还是传址?
11.java处理多线程,另一线程一直等待?
二十二、来自****提供的面试题18道:
1.一个网络商城1天大概产生多少G的日志?
2.大概有多少条日志记录(在不清洗的情况下)?
3.日访问量大概有多少个?
4.注册数大概多少?
5.我们的日志是不是除了apache的访问日志是不是还有其他的日志?
6.假设我们有其他的日志是不是可以对这个日志有其他的业务分析?这些业务分析都有什
么?
7、问:你们的服务器有多少台?
8、问:你们服务器的内存多大?
9、问:你们的服务器怎么分布的?(这里说地理位置分布,最好也从机架方面也谈谈)
10、问:你平常在公司都干些什么(一些建议)
下面是HBASE我非常不懂的地方:
11、hbase怎么预分区?
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525350
12、hbase怎么给web前台提供接口来访问(HTABLE可以提供对HTABLE的访问,但是
怎么查询同一条记录的多个版本数据)?
13、.htableAPI有没有线程安全问题,在程序中是单例还是多例?
14、我们的hbase大概在公司业务中(主要是网上商城)大概都几个表,几个表簇,大概
都存什么样的数据?
15、hbase的并发问题?
下面的Storm的问题:
16、metaq消息队列zookeeper集群storm集群(包括zeromq,jzmq,和storm本身)
就可以完成对商城推荐系统功能吗?还有没有其他的中间件?
17、storm怎么完成对单词的计数?(个人看完storm一直都认为他是流处理,好像没有
积攒数据的能力,都是处理完之后直接分发给下一个组件)
18、storm其他的一些面试经常问的问题?
二十三、飞哥(hadoop月薪13k)提供的面试题18道:
1、你们的集群规模?
开发集群:10台(8台可用)8核cpu
2、你们的数据是用什么导入到数据库的?导入到什么数据库?
处理之前的导入:通过hadoop命令导入到hdfs文件系统
处理完成之后的导出:利用hive处理完成之后的数据,通过sqoop导出到mysql数据库
中,以供报表层使用。
3、你们业务数据量多大?有多少行数据?(面试了三家,都问这个问题)
开发时使用的是部分数据,不是全量数据,有将近一亿行(8、9千万,具体不详,一般开
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525351
发中也没人会特别关心这个问题)
4、你们处理数据是直接读数据库的数据还是读文本数据?
将日志数据导入到hdfs之后进行处理
5、你们写hive的hql语句,大概有多少条?
不清楚,我自己写的时候也没有做过统计
6、你们提交的job任务大概有多少个?这些job执行完大概用多少时间?(面试了三家,都
问这个问题)
没统计过,加上测试的,会与很多
7、hive跟hbase的区别是?
8、你在项目中主要的工作任务是?
利用hive分析数据
9、你在项目中遇到了哪些难题,是怎么解决的?
某些任务执行时间过长,且失败率过高,检查日志后发现没有执行完就失败,原因出在
hadoop的job的timeout过短(相对于集群的能力来说),设置长一点即可
10、你自己写过udf函数么?写了哪些?
这个我没有写过
11、你的项目提交到job的时候数据量有多大?(面试了三家,都问这个问题)
不清楚是要问什么
12、reduce后输出的数据量有多大?
13、一个网络商城1天大概产生多少G的日志?4tb
14、大概有多少条日志记录(在不清洗的情况下)?7-8百万条
15、日访问量大概有多少个?百万
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525352
16、注册数大概多少?不清楚几十万吧
17、我们的日志是不是除了apache的访问日志是不是还有其他的日志?关注信息
18、假设我们有其他的日志是不是可以对这个日志有其他的业务分析?这些业务分析都有
什么?
二十四、来自aboutyun提供的面试题1道:
有一千万条短信,有重复,以文本文件的形式保存,一行一条,有重复。
请用5分钟时间,找出重复出现最多的前10条。
分析:
常规方法是先排序,在遍历一次,找出重复最多的前10条。但是排序的算法复杂度最低为
nlgn。
可以设计一个hash_table,hash_map<string,int>,依次读取一千万条短信,加载到
hash_table表中,并且统计重复的次数,与此同时维护一张最多10条的短信表。
这样遍历一次就能找出最多的前10条,算法复杂度为O(n)。
二十五、北京-南桑(hadoop月薪12k)提供的面试题5道:
1、job的运行流程(提交一个job的流程)?
2、Hadoop生态圈中各种框架的运用场景?
3、还有很多的选择题
4、面试问到的
hive中的压缩格式RCFile、TextFile、SequenceFile各有什么区别?
以上3种格式一样大的文件哪个占用空间大小..等等
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525353
还有Hadoop中的一个HA压缩。
5、假如:Flume收集到的数据很多个小文件,我需要写MR处理时将这些文件合并
(是在MR中进行优化,不让一个小文件一个MapReduce)
他们公司主要做的是中国电信的流量计费为主,专门写MR。
二十六、来自炎帝初始化提供的面试题2道:
以下题目不必都做完,挑最擅长的即可。
题一:RTB广告DSP算法大赛
请按照大赛的要求进行相应的建模和分析,并详细记录整个分析处理过程及各步骤成果物。
算法大赛主页:http://contest.ipinyou.com/cn/index.shtml
算法大赛数据下载地址:
http://pan.baidu.com/share/link?shareid=1069189720&uk=3090262723#dir
题二:cookieID识别
我们有M个用户N天的的上网日志:详见58.sample
字段结构如下:
ipstring客户端IP
ad_idstring宽带ADSL账号
time_stampstring上网开始时间
urlstringURL
refstringreferer
uastringUserAgent
dest_ipstring目标IP
cookiestringcookie
day_idstring日期
58.com的cookie值如:
bangbigtip2=1;bdshare_firstime=1374654651270;
CNZZDATA30017898=cnzz_eid%3D2077433986-1374654656-http%253A%252F%252Fsh.58.com
%26ntime%3D1400928250%26cnzz_a%3D0%26ltime%3D1400928244483%26rtime%3D63;
Hm_lvt_f5127c6793d40d199f68042b8a63e725=1395547468,1395547513,1395758399,13957594
68;id58=05dvZ1HvkL0TNy7GBv7gAg==;
Hm_lvt_3bb04d7a4ca3846dcc66a99c3e861511=1385294705;
__utma=253535702.2042339925.1400424865.1400424865.1400928244.2;
__utmz=253535702.1400424865.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none);city=sh;
pup_bubble=1;__ag_cm_=1400424864286;myfeet_tooltip=end;ipcity=sh%7C%u4E0A%u6D77
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525354
其中有一个属性能标识一个用户,我们称之为cookieID。
请根据样例数据分析出58.com的cookieID。
要求详细描述分析过程。
二十七、来自aboutyun提供的面试题7道:
1、解释“hadoop”和“hadoop生态系统”两个概念。
2、说明Hadoop2.0的基本构成。
3、相比于HDFS1.0,HDFS2.0最主要的改进在哪几方面?
4、试使用“步骤1,步骤2,步骤3…..”说明YARN中运行应用程序的基本流程。
5、“MapReduce2.0”与“YARN”是否等同,尝试解释说明。
6、MapReduce2.0中,MRAppMaster主要作用是什么,MRAppMaster如何实现任务
容错的?
7、为什么会产生yarn,它解决了什么问题,有什么优势?
二十八、来自然月枕流君提供的面试题6道:
1、集群多少台,数据量多大,吞吐量是多大,每天处理多少G的数据?
2、自动化运维了解过吗,你们是否是自动化运维管理?
3、数据备份,你们是多少份,如果数据超过存储容量,你们怎么处理?
4、怎么提升多个JOB同时执行带来的压力,如何优化,说说思路?
5、你们用HBASE存储什么数据?
6、你们的hive处理数据能达到的指标是多少?
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525355
二十九、来自夏天提供的面试题1道:
1、请说说hadoop1的HA如何实现?
三十、来自枫林木雨提供的面试题18道:
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??
编者QQ:104019525356
备注:想知道更多学员的面试经验,欢迎关注官网:www.crxy.cn。
1、10年工作经验罗同学由月薪18k飙升至45k:http://www.crxy.cn/detail/news/12;
2、14届应届本科生入职中国航天集团,基本年薪20w,年终奖10w:
http://www.crxy.cn/detail/news/12;
3、入职腾讯学员告诉你hadoop学习方法:http://www.crxy.cn/detail/jobinfo/10;
4、揭秘大专生月薪6.5k翻番至13k:http://www.crxy.cn/detail/jobinfo/8;
5、美女研究生hadoop工作经验分享:http://www.crxy.cn/detail/jobinfo/6。
QQ942609288????,???????QQ??
QQ942609288????,???????QQ??















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}