







多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
| select | poll | epoll | |
| 操作方式 | 遍历 | 遍历 | 回调 |
| 数据结构 | bitmap | 数组 | 红黑树 |
| 最大连接数 | 1024(x86)或2048 (x64) | 无上限 | 无上限 |
| 最大支持文件描述符数一般有最大值限制 | 65535 | 65535 | |
| fd拷贝 | 每次调用select,都需 要把fd集合从用户态搏 贝到内核态 | 每次调用poll,都需要 把fd集合从用户态拷贝 到内核态 | fd首次调用epol_ctl拷贝,每次调用 epollwait不拷贝 |
| 工作效率 | 每次调用都进行线性遍 历,时间复杂度为 o(n) | 每次调用都进行线性遍 历,时间复杂度为 (n) | 事件通知方式,每当fd就绪,系统注册的 回调函数就会被调用,将就绪fd放到 readyList里面,时间复杂度O(1) |
select
官网
Linux官网或者man select(2) - Linux manual page
select是第一个实现(1983左右在BSD里面实现)
优点
select其实就是把NIO中用户态要遍历的fd数组(我们的每一个socket链接,安装进ArrayList!里面的那个)拷贝到了内核态,让内核态来遍历,因为用户态判断socket是否有数据还是要调用内核态的,所有拷贝到内核态后,这样遍历判断的时候就不用一直用户态和内核态频繁切换了
问题
- bitmapi最大1024位,一个进程最多只能处理1024个客户端
- &rset不可重用,每次socket有数据就相应的位会被置位
- 文件描述符数组拷贝到了内核态(只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)),仍然有开销
- select调用需要传入fd数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select并没有通知用户态哪一个socket有数据,仍然需要O(n)的遍历。select仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历
C语言代码
// 创建套接字
socket(AF_INET, SOCK_STREAM, 0);
int sockfd; // 注意声明sockfd
// 清零addr结构体
memset(&addr, 0, sizeof(addr));
// 设置地址族
addr.sin_family = AF_INET; // 使用等号赋值
// 设置端口
addr.sin_port = htons(2000); // 使用等号赋值
// 设置IP地址为任意地址
addr.sin_addr.s_addr = INADDR_ANY; // 使用等号赋值
// 绑定套接字
bind(sockfd, (struct sockaddr*)&addr, sizeof(addr));
// 开始监听
listen(sockfd, 5);
// 模拟5个客户端连接
for (int i = 0; i < 5; i++) { // 初始化i,使用大括号包裹循环体
// 重置client结构体
memset(&client, 0, sizeof(client));
// 准备接收客户端地址长度
socklen_t addrlen = sizeof(client);
fds[i]=accept(sockfd,(struct sockaddr*)&client,&addrlen);
if(fds[i]>max) max fds[i];
}select方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次select的系统调用+N次就绪状态的文件描述符的read系统调用
poIl
优点
- poll使用pollfd数组来代替select中的bitmap,数组没有1024的限制,可以一次管理更多的client。它和select的主要区别就是,去掉了select只能监听1024个文件描述符的限制。
- 当pollfds数组中有事件发生,相应的revents置位为1,遍历的时候又置位回零,实现了pollfd数组的重用
问题
poll解决了select缺点中的前两条,其本质原理还是select的方法,还存在select中原来的问题
1、pollfds数组拷贝到了内核态,仍然有开销
2、poll并没有通知用户态哪一个socket有数据,仍然需要O(n)的遍历
Linux官网或者man
1997年实现了poll

C语言代码
pol的执行流程:
1.将五个fd从用户态烤贝到内核态
2.poll为阻塞方法,执行pol方法,如果有数据会将fd对应的revents置为POLLIN
3.pol方法返回
4.循环遍历,查找哪个fd被置位为POLL山N了
5.将reventsi重置为0便于复用
6.对置位的fd进行读取和处理
解决的问题:
1.解决了bitmap大小限制
2.解决了rset不可重用的情况
后面由于二者原理相同,所以没能解决

epoll
事件通知机制
- 当有网卡上有数据到达了,首先会放到DMA(内存中的一个bufr,网卡可以直接访问这个数区域)
- 网卡向cpu发起中断,让cpu先处理网卡的事
- 中断号在内存中会绑定一个回调,哪个socket中有数据,回调函数就把哪个socket放入就绪链表中
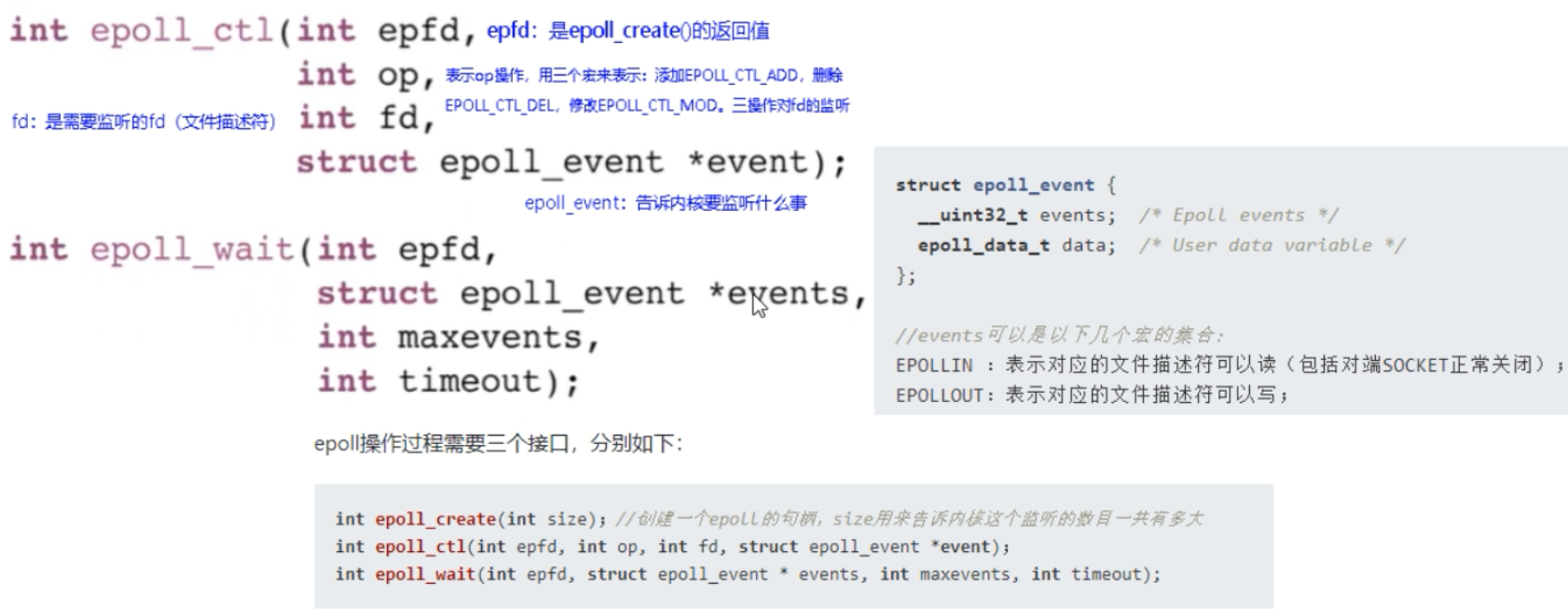
三步调用
epoll_create
创建一个epoll句柄
int epoll_create(int size)
epoll_ctl
向内核添加、修改或删除要监控的文件描述符

epoll_wait
类似发起了select()调用
Linux官网或者man
在2002年被神Davide Libenzi(戴维德.利本兹)发明出来了

C语言代码


结论
- 多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的while循环里多次系统调用,变成了一次系统调用+内核层遍历这些文件描述符。
- epoll是现在最先进的IO多路复用器,Redis、Nginx,.linux中的Java NIO都使用的是epoll。这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。
- 一个socket的生命周期中只有一次从用户态拷贝到内核态的过程,开销小
- 使用event事件通知机制,每次socket中有数据会主动通知内核,并加入到就绪链表中,不需要遍历所有的socket
- 在多路复用IO模型中,会有一个内核线程不断地去轮询多个socket的状态,只有当真正读写事件发送时,才真正调用实际的IO读写操作。因为在多路复用引O模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只真正有读写事件进行时,才会使用IO资源,所以它大大减少来资源占用。多路IO复用模型是利用select、pol、epoll可以同时监察多个流的I/O事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有IO事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。采用多路I/O复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈
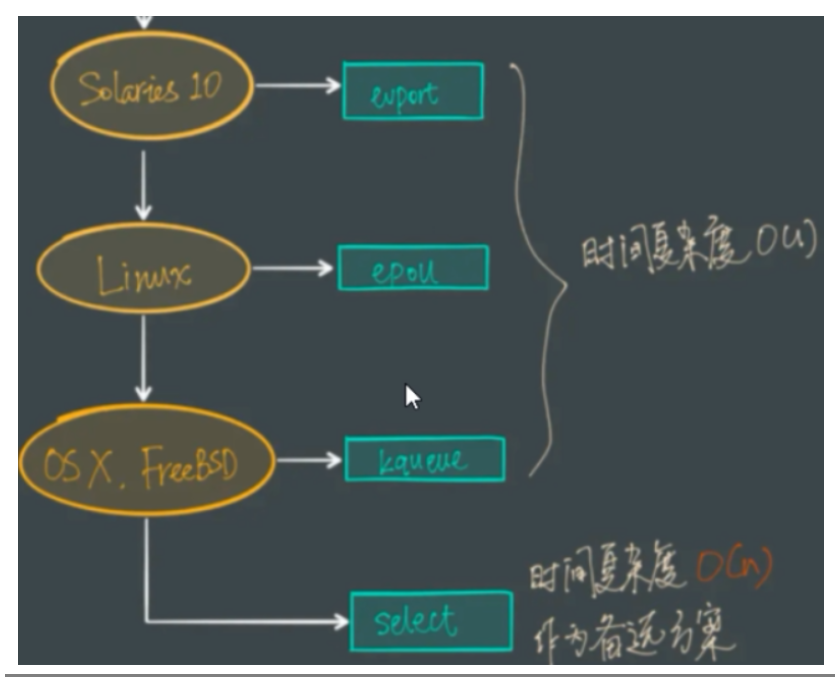
为什么3个都保有















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









