







一、从数据先验的角度
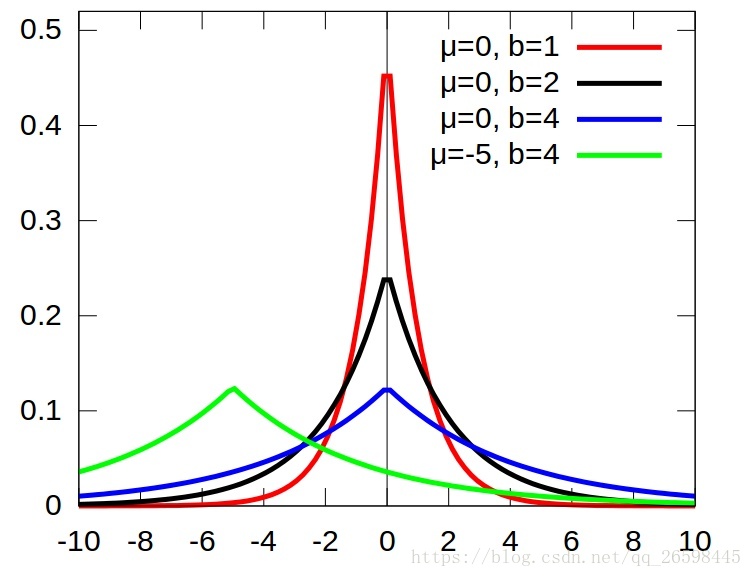
首先你要知道L1范式和L2范式是怎么来的,然后是为什么要把L1或者L2正则项加到代价函数中去.L1,L2范式来自于对数据的先验知识.如果你认为,你现有的数据来自于高斯分布,那么就应该在代价函数中加入数据先验P(x),一般由于推导和计算方便会加入对数似然,也就是log(P(x)),然后再去优化,这样最终的结果是,由于你的模型参数考虑了数据先验,模型效果当然就更好.哦对了,如果你去看看高斯分布的概率密度函数P(x),你会发现取对数后的log(P(x))就剩下一个平方项了,这就是L2范式的由来–高斯先验.同样,如果你认为你的数据是稀疏的,不妨就认为它来自某种laplace分布.不知你是否见过laplace分布的概率密度函数,我贴出一张维基上的图
作者:amnesia
链接:https://www.zhihu.com/question/37096933/answer/70668476
来源:知乎
二、从数据计算的角度
但为什么L1正则会产生稀疏解呢?这里利用公式进行解释。
假设只有一个参数为w,损失函数为L(w),分别加上L1正则项和L2正则项后有:
假设L(w)在0处的倒数为d0,即
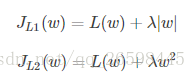
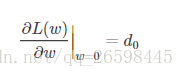
则可以推导使用L1正则和L2正则时的导数。
引入L2正则项,在0处的导数
引入L1正则项,在0处的导数
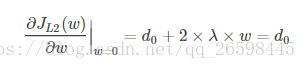
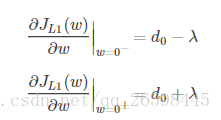
可见,引入L2正则时,代价函数在0处的导数仍是d0,无变化。而引入L1正则后,代价函数在0处的导数有一个突变。从d0+λ到d0−λ,若d0+λ和d0−λ异号,则在0处会是一个极小值点。因此,优化时,很可能优化到该极小值点上,即w=0处。
这里只解释了有一个参数的情况,如果有更多的参数,也是类似的。因此,用L1正则更容易产生稀疏解。
来自https://blog.csdn.net/f156207495/article/details/82794151?utm_source=copy














 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









