







SparkContext 和 SparkConf
任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数。
初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD和共享变量。
al conf = new SparkConf().setMaster("master").setAppName("appName")
val sc = new SparkContext(conf)
或者
val sc = new SparkContext("master","appName")
Note:
Once a SparkConf object is passed to Spark, it is cloned and can no longer be modified by the user.
也就是说一旦设置完成SparkConf,就不可被使用者修改
对于单元测试,您也可以调用SparkConf(false)来跳过加载外部设置,并获得相同的配置,无论系统属性如何。
咱们再看看setMaster()和setAppName()源码:
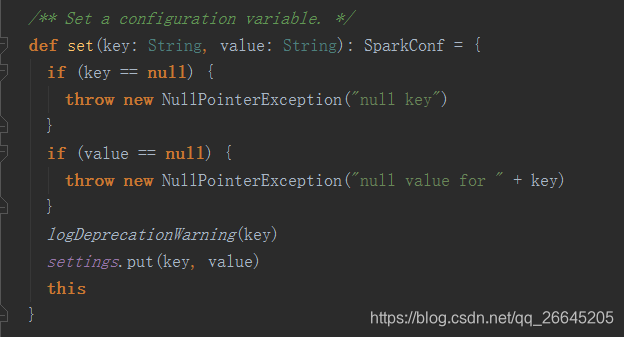
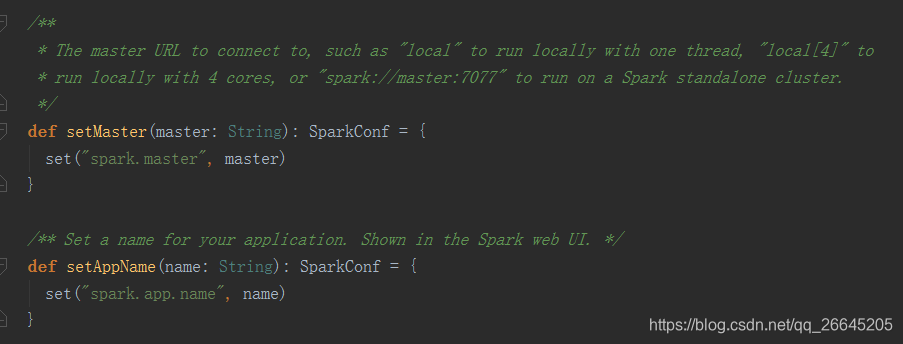 根据上面的解释,setMaster主要是连接主节点,如果参数是"local",则在本地用单线程运行spark,如果是 local[4],则在本地用4核运行,如果设置为spark://master:7077,就是作为单节点运行,而setAppName就是在web端显示应用名而已,它们说到底都调用了set()函数,让我们看看set()是何方神圣
根据上面的解释,setMaster主要是连接主节点,如果参数是"local",则在本地用单线程运行spark,如果是 local[4],则在本地用4核运行,如果设置为spark://master:7077,就是作为单节点运行,而setAppName就是在web端显示应用名而已,它们说到底都调用了set()函数,让我们看看set()是何方神圣
 SparkSession:
SparkSession:
SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的
val sparkSession = SparkSession.builder
.master("master")
.appName("appName")
.getOrCreate()
或者
SparkSession.builder.config(conf=SparkConf())
上面代码类似于创建一个SparkContext,master设置为"xiaojukeji",然后创建了一个SQLContext封装它。如果你想创建hiveContext,可以使用下面的方法来创建SparkSession,以使得它支持Hive(HiveContext):
val sparkSession = SparkSession.builder
.master("master")
.appName("appName")
.enableHiveSupport()
.getOrCreate()
//sparkSession 从csv读取数据:
val dq = sparkSession.read.option("header", "true").csv("src/main/resources/scala.csv")
getOrCreate():有就拿过来,没有就创建,类似于单例模式:
s1 = SparkSession().builder.config("k1", "v1").getORCreat()
s2 = SparkSession().builder.config("k2", "v2").getORCreat()
return s1.conf.get("k1") == s2.conf.get("k2")
True














 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









