







WebBrowser是一个.NET控件类(设置下web脚本错误忽略)支持获取页面加载完毕的源码,而不是初始化的源码
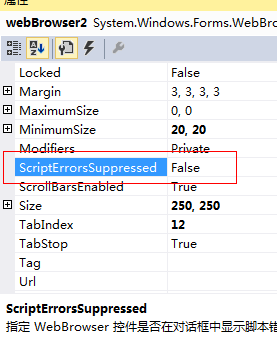
用到了一个web的一个文档全部加载事件:
调用方法:
webBrowser1.Navigate("http://news.baidu.com/");//web浏览百度新闻页面
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
System.IO.StreamReader streamReader = new System.IO.StreamReader(this.webBrowser1.DocumentStream, System.Text.Encoding.GetEncoding("gb2312"));//如果web浏览页面乱码可以使用这个方法进行转码
string strWebBrowserDocument = streamReader.ReadToEnd();
}
web的一些属性:
webBrowser1.Document.Title//获取或设置页面的title
webBrowser1.Document.Url//当前请求页面的地址
webBrowser1.DocumentText//获取或者设置html内容
webBrowser1.Document.GetElementsByTagName("h3")//获取所有标签为h3的标签
webBrowser1.Document.GetElementById("h3")//获取id为h3的标签
GetAttribute("className");//获取样式名称
GetAttribute("href")//获取a标签的里的url















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









