







1 共享存储
示例:
apiVersion: v1
kind: Pod
metadata:
name: podtest
spec:
containers:
- name: write
image: centos
commond: ["bash", "-c", "for i in (1..100);do echo $i >> /data/hello;sleep 1; done"]
volumeMounts: # 挂载数据卷
- name: data # 数据卷名称
mountPath: /data
- name: read
image: centos
command: ["bash", "-c", "tail -f /data/hello"]
volumeMounts: # 挂载数据卷
- name: data # 数据卷名称
mountPath: /data
volumes: # 定义数据卷
- name: data # 数据卷名称
emptyDir: {} # 空数据卷
2 镜像拉取策略
spec:
containers:
- image: nginx:1.14
name: nginx
imagePullPolicy: Always # 资源限制
imagePullPolicy定义镜像拉取策略,它有以下几种选项
- ifNotPresent: 默认值,镜像在宿主机上不存在时才拉取
- Always:每次创建Pod都会重新拉取一次镜像
- Never:Pod永远不会主动拉取这个镜像
3 Pod资源限制
apiVersion: v1
kind: pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "123@ABC"
resource: # 资源限制
requests: # 调度
memory: "64Mi" # 64m
cpu: "250m" # 0.25CPU
limits: # 最大大小
memory: "128Mi" # 126m
cpu: "500m" # 0.5CPU
CPU1核=1000m
4 Pod重启机制
apiVersion: v1
kind: pod
metadata:
name: test
spec:
containers:
- name: busybox
image: busybox:1.28.4
args:
- /bin/sh
- -c
- sleep 36000
restartPolicy: Never # 重启策略
restartPolicyAlways:当容器终止退出后,总是重启容器,默认策略OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。Never:当容器终止退出,从不启动容器
5 健康检查
容器检查,java堆内存溢出时,Pod可能还是Running状态,但是这个Pod明显是不能在提供服务的,容器检查无法排查出这样的错误
这时候就需要应用层面健康检查
- livenessProbe(存活检查),如果检查失败,将杀死容器,根据Pod的restartPolicy来操作
- readingressProbe(就绪检查),如果检查失败,Kubernetes会把Pod从service endpoints中剔除
- prob检查的三种方式:
- httpGet:发送HTTP请求,返回200-400范围状态则为成功
- exec:执行shell命令返回状态码是0为成功
- tcpSocket:发起TCP Socket建立成功
demo
apiVersion: v1
kind: pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox:1.28.4
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy
livenessProbe: # 检查策略
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
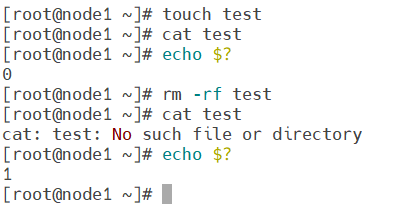
如上图,可根据状态码判断示威正常。
6 调度策略
6.1 pod创建过程
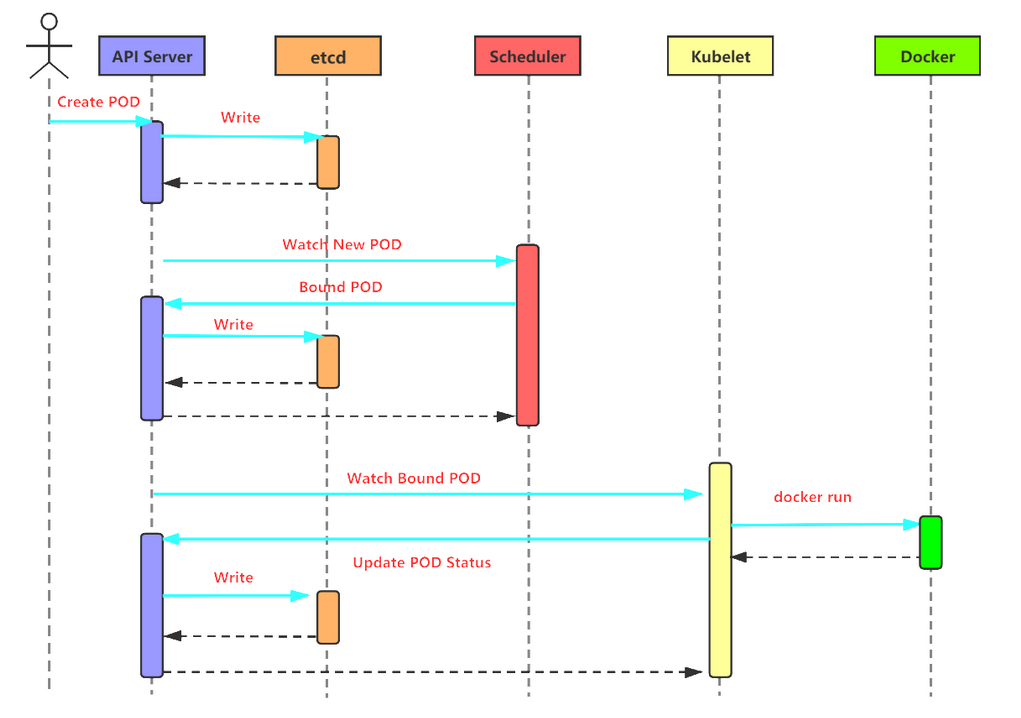
-
master节点
- create pod => apiserver => etcd
- scheduler监听,分配node =>apiserver => etcd
-
node节点
- kubelet => apiserver => 读取etcd拿到分配给当前节点的pod => docker创建容器
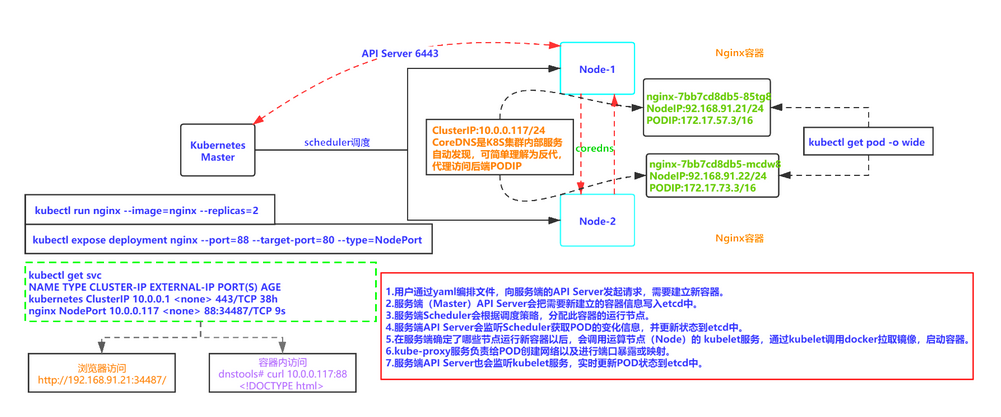
6.2 影响调度的属性
6.2.1、Pod资源限制对Pod调度产生影响
resources:
requests:
memory: "64Mi"
cpu: "250m"
根据request找到足够限制的node节点进行调度
6.2.2、节点选择器标签
apiVersion: v1
kind: Pod
metadata:
name: pod-example
spec:
nodeSelector: # 标签选择器
env_role: dev # 分组名称
containers:
- name: nginx
image: nginx:1.15
可以对node节点进行分组,根据分组名称进行调度
所以首先需要对节点起别名
# 给node1起别名dev
kubectl label node [node] env_role=[env]

# 查看labels
kubectl get nodes [node] --show-labels

可以看到刚刚打的标签
6.2.3、节点的亲和性
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinty
spec:
affinty:
nodeAffinity: # 亲和性节点
requiredDuring$chedulingIgnoredDuringExecution: # 硬亲和性
nodeSelectorTerms:
- matchExpressions:
- key: env_role # 关键词
operator: In # 操作符
values: # 操作值
- dev
- test
preferredDuring$chedulingIgnoredDuringExecution: # 软亲和性
- weigth: 1 # 权重
preference:
matchExpressions:
- key: group
operator: In
values:
- otherprod
containers:
- name: webdemo
image: nginx
节点亲和性 nodeAffinity 和之前 nodeSelector 基本一样的,根据节点上标签约束来绝对Pod调度到哪些节点上。
(1)硬亲和性
约束条件必须满足,如果不满足那么创建就会一直等待
(2)软亲和性
尝试满足,不保证,没有的话就找其他节点创建。
支持的常用操作符(operator)
In NotIn Exist Gt Lt DoesNotExists
6.2.4、污点 和 污点容忍
1、 基本介绍
nodeSelector和nodeAffinity: Pod根据配置调度到某些节点,Pod属性,调度的时候实现
Taint(污点):节点不做普通分配调度,是节点属性
2、场景
- 专用节点
- 配置特点硬件节点
- 基于Taint驱逐
3、具体实现
(1)查看节点污点情况
kubectl describe node [node] | grep Taint

NoSchedule
- 污点值有三个
- NoSchedule:一定不被调度
- PreferNoSchdule:尽量会被调度
- NoExecute:不会调度,并且还会驱逐Node已有Pod
(2)为节点添加污点
kubect taint node [node] key=value:污点值
# 创建nginx
kubectl create deployment nginx --image=nginx
# 追加到5个POD
kubectl scale deployment nginx --replicas=5
# 查看部署信息
kubectl get pods -o wide
需要时间去拉取镜像

稍等后查看可见是创建完成了,node1创建1个,node2创建3个

为了测试污点效果,先将其全部删除在实验

给node1加上污点
kubectl taint node node1 env_role=yes:NoSchedule
kubectl describe node node1 | grep Taint

可以发现之后创建的pod都不会挂载到node1节点
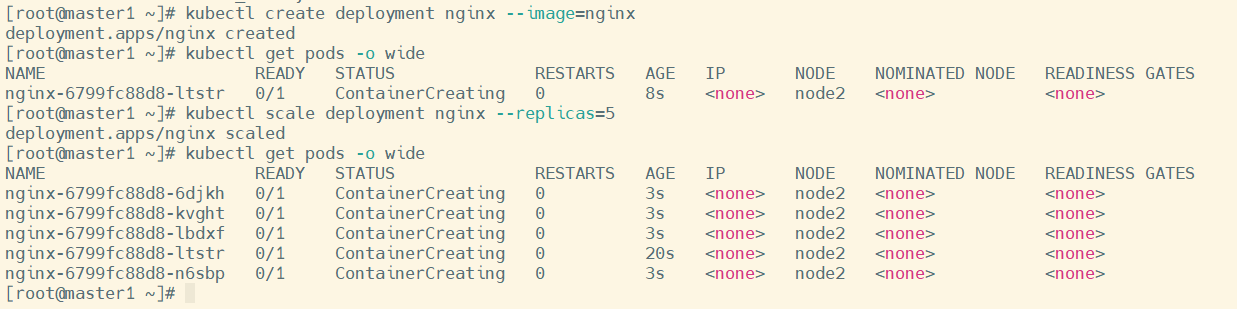
(3)删除污点
kubectl taint node node1 env_role:NoSchedule-

4、污点容忍
污点容忍配置后,就算节点是NoSchedule也可能被调度到
spec:
tolerations:
- key: "key" # 这里key是污点key,例如上文的env_role
operator: "Equal" # 操作符
value: "value" # 这里的value是污点value,例如上文的yes
effect: "NoSchedule" # 这里填写需要容忍的污点值
containers:
- name: demo
image: nginx















 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









