









Android开发艺术探索——第二章:IPC机制(上)
本章主要讲解Android的IPC机制,首先介绍Android中的多进程概念以及多进程开发模式中常见的注意事项,接着介绍Android中的序列化机制和Binder,然后详细的介绍Bundle,文件共享,AIDL,Messenger,ContentProvider和Socker等进程间通讯的方法,为了更好的使用AIDL进行进程间通讯,本章引入了Binder连接池的概念,最后,本章讲解各种进程间通信方式的优缺点和使用场景,通过本章,可以让读者对Android中的IPC机制和多线程开发模式有深入的了解
本章为上篇,知识点
- 2.1 Android IPC简介
- 2.2 Android 中的多进程模式
- 2.2.1 开启多进程模式
- 2.2.2 多进程模式的运行机制
- 2.3 IPC基础概念介绍
- Serializable 接口
- Parcelable 接口
- Binder
一.Android IPC简介
IPC是Inter-Process Communication的缩写,含义是进程间通信或者跨进程通信,是指两个进程间进行数据交互的一个过程,说起进程间通信,我们首先要理解什么是进程,什么是线程,进程和线程是截然不同的概念。按照操作系统中的描述,线程是CPU调度的最小单元,同时线程是一种有限的系统资源。而进程一般指一个执行单元,在PC和移动设备上指一个程序或者一个应用。一个进程可以包含多个线程,因此进程和线程是包含与被包含的关系。最简单的情况下,一个进程中可以只有一个线程,即主线程,在Android里面主线程也叫UI线程,在UI线程里才能操作界面元素。很多时候,一个进程中需要执行大量耗时的任务,如果这些任务放在主线程中去执行就会造成界面无法响应,严重影响用户体验,这种情况在PC系统和移动系统中都存在,在Android中有一个特殊的名字叫做ANR(Application Not Responding),即应用无响应。解决这个问题就需要用到线程,把一些耗时的任务放在线程中即可。
IPC不是Andrord中所独有的,任何一个操作系统都需要有相应的IPC机制,比如Windows上可以通过剪贴板、管道和邮槽等来进行进程间通信,、Linux上可以通过命名管道,共享内容、信号量等来进行进程间通信。可以看到不同的操作系统系统有着不同的进程通信方式,对于Android来说,它是一种基于Linux内核的操作系统,他的进程间通信方式并不能完全继承自Linux,相反,它有自己的进程间通信方式。在Android中最
有特色的进程间通信方式就是Binder了,通过Binder可以轻松地实现进程间通信。除了有特色的Binder,Android还支持Socket,通过Socket也可以实现任意两个终端之间的通信,当然同一个设备上的两个进程通过Socket通信自然也是可以的说到IPC的使用场景就必须提到多进程,只有面对多进程这种场景下,才需要考虑进程间通信。这个是很好理解的,如果只有一个进程在运行,又何谈多进程呢?多进程的情况分为两种。第一种情况是一个应用因为某些原因自身需要采用多进程模式来实现,至于原因,可能有很多,比如有些模块由于特殊原因需要运行在单独的进程中,又或者为了加大一个应用可使用的内存所以需要通过多进程来获取多份内存空间。Android对单个应用所
使用的最大内存做了限制,早期的一些版本可能是16MB,不同设备有不同的大小。另一种情况是当前应用需要向其他应用获取数据,由于是两个应用,所以必须采用跨讲程的方式来获取所需的数据,甚至我们通过系统提供的ContentProvider去查询数据的时候,其实也是一种进程间通信,只不过通信细节被系统内部屏蔽了,我们无法感知而已,后续的章节我们会详细的介绍ContentProvider的底层实现,这里就先不做介绍了,总之,不管我们处于何种原因,我们采用了多进程的设计方法,那么应用中就必须妥善地处理进程间通信的各种问题了。
二.Android中的多进程模式
在正式介绍进程间通信之前,我们必须先去理解Android中的多进程模式,通过给四大组件指定android:process属性,我们可以轻易的开启多进程模式,这看起来很简单,但是实际使用过程中却暗藏杀机,多进程远远没有我们想的那么简单,有时候我们可以通过多进程得到的好处甚至都不足以弥补使用多进程所带来的代码层面的负面影响,下面会详细分析这些问题
1.开启多进程模式
正常情况下,在Android中多进程是指一个应用中存在多个进程的情况,因此这里不讨论两个应用之间的情况,首先在Android中使用多进程只有一种方法,那就是给四大组件指定android:process,除此之外,没有其他办法,也就是说我们无法给一个线程或者实体类指定其运行时所在的进程,其实还有一种非常规的多进程方法,那就是通过JNI在native层去fork一个新的进程,但是这种方法属于特殊情况,也不是常用的创建多进程的方式,因此我们暂时不考虑这种方式,下面是一个实例,描述了;如何在Android中创建多进程
<activity
android:name=".MainActivity"
android:configChanges="orientation|screenSize"
android:launchMode="standard">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
<activity
android:name=".SecondActivity"
android:configChanges="screenLayout"
android:process=":remote" />
<activity
android:name=".ThirdActivity"
android:configChanges="screenLayout"
android:process="com.liuguilin.multiprocesssample.remote" />
上面的示例分别为SecondActivity和ThirdActivity指定了process属性,并且他们的属性值不同,当SecondActivity启动时,系统会为它创建一个单独的进程,进程名为con.liuguilin.multiprocesssample:remote,当ThridActivity启动的时候,系统也会为他创建一个单独的进程,进程名com.liuguilin.multiprocesssample.remote,同时,入口Activity是MainActivity,没有为他指定process属性,那么他运行在默认进程中,当我们运行的时候就可以看到,进程列表末尾存在三个进程,这说明我们成功的开启了多进程,是不是很简单尼?这只是一个开始,实际上多进程是有很多问题需要处理的

除了在DDMS中可以查看进程,我们还可以通过shell命令来查看
adb shell ps 或者 adb shell ps | grep com.liuguilin.multiprocesssample
不知道读者有没有注意到,SecondActivity和ThirdActivity的进程名分别为“:remote”和包名.remote,那么这两种方式有区别吗?其实是有区别的,区别在两面,首先”:“的含义,是指在当前的进程名前附加上包名,这是一种简写的方法,对于SecondActivity来说,他完整的进程名为com.liuguilin.multiprocesssample:remote,而对于ThirdActivity中的申明方式,它是一种完整的命名方式,不会附加包名信息;其次,进程以”:“开头的属于当前应用的私有进程,其他应用的组件不可以和它跑在同一个进程中,而进程名不以”:“开头的进程属于全局进程,其他应用通过ShareUID方式可以和它跑在同一进程中。
我们知道Android系统会为每个应用分配一个唯一的UID,具有相同UID的应用才能共享数据。这里要说明的是,两个应用通过ShareUID跑在同一个进程由是有要求的,需要这两个应用有相同的ShareUID并且签名相同才可以。在这种情况下,它们可以互相访问对方的私有数据,比如data目录、组件信息等,不管它们是否跑在同一个进程中。当然它们跑在同一个进程中,那么除了能共享data目录、组件信息,还可以共享内存数据,或者说它们看起来就像是一个应用的两个部分。
2.多进程模式的运行机制
如果用一句话来形容多进程,那笔者只能这样说:“当应用开启了多进程以后,各种奇怪的现象都出现了”,为什么这么说呢?这是有原因的。大部分人都认为开启多进程是很简单的事情,只需要给四大组件指定android:process属性即可。比如说在实际的产品开发中,可能会有多进程的需求,需要把某些组件放在单独的进程中去运行,很多人都会觉得这不很简单吗?然后迅速地给那些组件指定了android:process属性,然后编译运行,发现“正常地运行起来了”。这里笔者想说的是,那是真的正常地运行起来了吗?现在先不置可否,下面先给举个例子,然后引入本节的话题。还是本章刚开始说的那个例子,其中SecondActvity通过指定android:process属性从而使其运行在一个独立的进程中,这里做了一些改动,我们新建了一个类,叫做UserManager,这个类中有一个public的静态成员变量,如下所示。
/**
* Created by lgl on 16/9/24.
*/
public class UserManager {
public static int mUserId = 1;
}
然后在MainActivity 的 onCreate中我们把这个mUserld重新赋值为2,打印出这个静态变量的值后再启动SecondActivity,在SecondActivity中我们再打印一下mUserld的值。按照正常的逻辑,静态变量是可以在所有的地方共享的,并且一处有修改处处都会同步,下面是是运行时所打印的日志,我们看一下结果如何

当你看完这个日志,发现结果和我们想的完全不一致,正常情况下SecondActivily打印的mUserld的值应该是2才对,但是从日志上看它竟然还是1,可是我们的确已经在MainActivitv中把mUserld重新赋值为2了。看到这里,大家应该明白了这就是多进程所带来的问题,多进程绝非只是仅仅指定一个android:process属性那么简单。
上述问题出现的原因是SecondActivity运行在一个单独的进程中,我们知道Android为每一个应用都分配了一个独立的虚拟机,或者说为每个进程都分配一个独立的虚拟机,不同的虚拟机在内存上有不同的地址空间,这就导致在不同的虚拟机中访问同一个类的对象会产生多份副本,就我们这个例子来说,在进两个进程中都存在一个UserManager类,并且这两个类是互不干扰的,在一个进程中修改mUseld的值只会影响当前进程,对其他进程不会造成任何影响,这样我们就可以理解为什么在MainActivitv中修改了mUserld的值,但是在 SecondActivity 中这个值却
没有发生改变这个现象。所有运行在不同进程中的四大组件,只要它们之间需要通过内存来共享数据,都会共享失败这也是多进程带来的主要影响,正常情况下四大组件中间不可能不通过一些中间层来共享数据,那么通过简单地指定进程名来开启多进程都会无法正确运行。当然,特殊情况下,某些组件之间不需要共享数据,这个时候可以直接指定 android:process属性来开启多进程,但是这种场景是不常见的,几乎所有情况都需要共享数据。
一般来说,使用多进程会造成如下几方面的问题:
- 1.静态成员和单例模式完全失效
- 2.线程同步机制完全失效。
- 3.SharedPreferences的可靠性下降。
- 4.Application会多次创建。
第1个问题在上面已经进行了分析。第2个问题本质上和第一个问题是类似的,既然都不是一块内存了,那么不管是锁对象还是锁全局类都无法保证线程同步,因为不同进程锁都不是同一个对象。第3个问题是因为SharedPreferences不支持两个进程同时去执行写操作,否则会导致一定几率的数据丢失,这是因为SharedPreferences底层是通过读/写XML文件来实现的,并发写显然是可能出问题的,甚至并发读/写都有可能出问题。第4个问题也是显而易见的,当一个组件跑在一个新的进程中的时候,由于系统要在创建新的进程同时分配独立的虚拟机,所以这个过程其实就是启动一个应用的过程。因此,相当于系统又把这个应用重启动了一遍,既然重新启动了,那么自然会创建新的Application。这个问题其实可以这么理解,运行在同一个进程中的组件是属于同一个虚拟机和同一个Application的,同理,运行在不同进程中的组件是属于两个不同的虚拟机和Application的。为了更加清晰地展示这一点,下面我们来做一个测试,首先在Application 的onCreate方法中打印出当前进程的名字,然后连续启动三个同一个应用内但属于不同进程的Activity,按照期望,Application的onCreate应该执行三次并打印出三次进程名不同的log,代码如下所示。
/**
* Created by lgl on 16/9/24.
*/
public class MyApplication extends Application {
@Override
public void onCreate() {
super.onCreate();
String processName = getCurProcessName();
Log.i("TAG", "process name :" + processName);
}
/**
* 获取当前进程名
*
* @return 进程名
*/
private String getCurProcessName() {
int pid = android.os.Process.myPid();
ActivityManager mActivityManager = (ActivityManager) getSystemService(Context.ACTIVITY_SERVICE);
for (ActivityManager.RunningAppProcessInfo appProcess : mActivityManager
.getRunningAppProcesses()) {
if (appProcess.pid == pid) {
return appProcess.processName;
}
}
return "获取失败";
}
}
我们可以查看一下打印的log

通过log可以看出,Application执行了三次onCreate,并且每次的进程名都不一样,他们的进程名和我们在清单文件中指定的process一致,这也就证实了在多进程模式中,不同进程的组件的确会拥有独
虚拟机、Application以及内存空间,这会给实际的开发带来很多困扰,是尤其需要注意的,或者我们也可以这么理解同一个应用间的多进程:它就相当于两个不同的应用采用sharedUID的模式,这样能够更加直接地理解多进程模式的本质。本节我们分析了多进程所带来的问题,但是我们不能因为多进程有许多问题就不去正视他。为了解决这个问题,系统提供了很多跨进程通信方法,虽然不能够直接的共享内存,但是通过跨进程通信我们还是可以实现数据交互。实现跨进程通信的力式很多,比如Intent来传递数据,共享文件和SharedPreferences,基于Binder的Messenger和 AIDL以及Socket等,但是为了更好地理解各种IPC方式,我们需要先熟悉一些基础概念,比如序列化相关的Serializable和Parcelable接口,以及Binder的概念,熟悉完这些基础概念以后,再去理解各种IPC方式就比较简单了。
三.IPC基础概念
本节主要介绍IPC中的一些基础概念,主要包含三方面内容;Serializable接口,Parcelable接口以及Binder,只有熟悉这三方面的内容后,我们才能更好地理解跨进程通信的各种方式。Serializable和Parcelable接口可以完成对象的序列化过程,当我们需要通过Intent和Binder传输数据时就需要使用Parcelable或者Serializable。还有的时候我们需要把对象持久化到存储设备上或者通过网络传输给其他客户端,这个时候也需要使用Serializable来完成对象的持久化,下面先介绍如何使用Senalizabie来完成对象的序列化
1.Serializable
Serializable 是 java所提供的一个序列化接口,它是一个空接口,为对象提供标准的序列化和反序列化的操作。使用Serializable来实现序列化相当简单,只需要在类的声明中指定一个类似下面的标识即可自动实现默认的序列化过程
private static final long serialVersionUID = 8711368828010083044L;在Anarond中也提供了新的序列化方式,那就是Parcelable接口来实现对象的序列化,其过程要稍微复杂一点,本章节先介绍Serializable接口,上面提到,想让一个对象实现序列化,只需要这个类实现Serializable接口并且声明一个serialversionUID即可,实际上,甚至这个serialversionUID也是不是必须的,我们不声明这个serialversionUID同样也可以实现序列化,但是这将会对反序列化过程产生影响,具体什么影响,我们后面再介绍,User类就是一个实现了 Seralizable接口的类,它是可以被序列化和反序列化的:
/**
* Created by lgl on 16/9/24.
*/
public class User implements Serializable {
private static final long serialVersionUID = 8711368828010083044L;
public int userId;
public String userName;
public boolean isMale;
...
}
通过Serializable方式来实现对象的序列化,实现起来非常的简单,几乎所有工作都被系统自动完成了,如何进行对象的序列化和反序列化也非常的简单,只需要采用ObjectOutputStream和ObjectInputStream即可轻松实现,下面举一个简单的例子
//序列化
User user = new User(0, "lgl", true);
try {
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("cache.txt"));
out.writeObject(user);
out.getClass();
} catch (IOException e) {
e.printStackTrace();
}
//反序列化
try {
ObjectInputStream in = new ObjectInputStream(new FileInputStream("cache.txt"));
User newUser = (User) in.readObject();
in.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
上述代码演示了采用Serializable方式序列化对象的典型过程,很简单,只需要把实现了 Serializable接口的 User对象写到文件中就可以快速恢复了,恢复后的对象newUser和user的内容完全一样,但是两者并不是同一个对象。
刚开始提到,即使不指定serialVersionUID也可以实现序列化,那到底要不要指定呢?如果指定的话,serialversiontID后面那一长串数字又是什么含义呢?我们要明白,系统既然既然提供了了serialversionUID,那么他必然是有用的,这个serialversionUID是用来辅助序列化和反序列化过程的,原则上序列化后的数据中的serialversionUID只有和当前类的serialversionUID相同才能正常的序列化,serialversionUID的详细工作机制是这样的,序列化的时候会把当前类的serialversionUID写进序列化的文件中(也可能是其他中介),当反序列化的时候系统会去检测文件中的serialversionUID,看它是否和当前类的serialversionUID一致,如果一致就说明序列化的类的版本和当前类的版本是相同的,这个时候可以成功反序列化;否则就说明当前类和序列化的类相比发生了某些变换,比如成员,类型可能发生了变化,这个时候是无法正常的反序列化的;
一般来说,我们应该手动指定serialversionUID的值,比如1L,也可以让Eclipse根据当前类的结构自动去生成它的hash值,这样序列化和反序列化时两者的serialversionUID是相同的,因此可以正常进行反序列化。如果不手动指定serialversionUID的值,反序列化时当前类有所改变,比如增加或者删除了某些成员变量,那么系统就会重新计算当前类的hasj值并把它赋值给serialversionUID,这个时候当前类的serialversionUID就和序列化数据中的serialversionUID不一致,于是反序列化失败,程序就会出现crash,所以我们可以明显的感觉到serialversionUID的作用,当我们手动指定了它以后;就可以很大程度上避免反序列化过程的失败。比如当版本升级后,我们可能删除了某个变量或者新增加了一些新的成员变量,这个时候我们的反向序列化过程仍然能够成功,程序仍然能够最小限度的恢复数据,相反,如果不指定serialversionUID的话,程序则会挂掉当然我们还要考虑另外一种情况,,如果类结构发生了非常规性改变,比如修改了类名,修改了成员常量的类型,这个时候尽管serialversionUID验证通过了,但是反序列化过程还是会失败;因为类结构有了毁灭性的改变,根本无法从老版本的数据中还原出一个新的类结构的对象。
根据上面的分析,我们可以知道,给serialversionUID指定为1L或者采用Eclipse根据当前类结构去生成的hash值,这两者并没有本质区别,效果完全一样。以下两点需要特别提一下,首先静态成员变量属于类不属于对象,所以不会参与序列化过程,其次用transient关键字标记的成员变量不参与序列化过程。
另外,系统的默认序列化过程也是可以改变的,通过实现如下 writeObject和readObject两个方法即可重写系统默认的序列化和反序列化过程,具体怎么去重写这两个方法就是很简单的事了,这里就不再介绍了,毕竟这不是本章的重点,而且大部分情况下我们不需要重写这两个方法
2.Parcelable
上一节我们介绍了通过Serializable方式来实现序列化的方法,我们本节接着介绍另外一种序列化的方法Parcelable,Parcelable也是一个借口,一个类的对象就可以实现序列化并可以通过Intent和Binder传递,下面的实例就是一个典型的用法
/**
* Created by lgl on 16/9/24.
*/
public class User implements Parcelable {
public int userId;
public String userName;
public boolean isMale;
public Book book;
public User(int userId, String userName, boolean isMale) {
this.userId = userId;
this.userName = userName;
this.isMale = isMale;
}
@Override
public int describeContents() {
return 0;
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeInt(userId);
dest.writeString(userName);
dest.writeByte((byte) (isMale ? 1 : 0));
}
public static final Creator<User> CREATOR = new Creator<User>() {
@Override
public User createFromParcel(Parcel in) {
return new User(in);
}
@Override
public User[] newArray(int size) {
return new User[size];
}
};
protected User(Parcel in) {
userId = in.readInt();
userName = in.readString();
isMale = in.readByte() != 0;
}
}
我里先说一下Paicel, Paicel内部包装了可序列化的数据,可以在Binder中自由传输,从上述代码中可以看出,在序列化过程中需要实现的功能有序列化、反序列化和内容描述,序列化功能由writeToParcel方法来完成,最终是通过Parcel中的一系列write方法来完成的,反序列化功能由CREATOR来完成,其内部标明了如何创建序列化对象和数组,并通过Parcel的一系列read方法来完成反序列化过程;内容描述功能由describeContents方法来完成,几乎在所有情况下这个方法都应该返回0,仅当当前对象中存在文件描述符时,此方法返回1。需要注意的是,在User(Parcel in)方法中,由于book是另一个可序列化对象,所以它的反序列化过程需要传递当前线程的上下文类加载器,否则会报无法找到类的错误
系统已经为我们提供了很多实现了Parcelable接口的类,他们都是可以直接序列化的,比如Intent,Bundle等,问同时List和Map也可以序列化,前提是它们里面的每个元素都是可以序列化。
既然 Parcelatle 和Serializable都能实现序列化并且都可用于Inient间的数据传递,那么二者该如何选取呢? Serializable是Java中的序列化接口,其使用起来简单但是开销很大,序列化和反序列化过程需要大量I/O操作。而Parcelable是Andrord中的序列化方式,因此更适合用在Android平台上,它的缺点就是使用起来稍微麻烦点,但是它的效率很高,这是Android推荐的序列化方式,因此我们要首选Parcelatle,Parcelable主要用在内存序列化上,通过Parcelable将对象序列化到存储设备中或者将对象序列化后通过网络传输也都是可以的,但是这个过程会稍显复杂,因此在这两种情况下建议大家使用Serializabie.以上就是Parcelable和Serializable的区别。
3.Binder
Binder是一个很深入的话题,笔者也看过一些别人写的Binder相关的文章,发现很少有人能把它介绍清楚,不是深入代码细节不能自拔,就是长篇大论不知所云,看完后都是晕晕的感觉。所以,本节笔者不打算深入探讨Binder的底层细节,因为Binder太复杂了。本节的侧重点是介绍Binder的使用以及上层原理,为接下来的几节内容做铺垫.
直观来说,Binder是Android中的一个类,它实现了IBinder接口。从IPC角度来说,Binder是Android中的一种跨进程通信方式,Binder还可以理解为一种虚拟的物理设备,它的设备驱动是/dev/binder,该通信方式在Linux中没有;从Android Framework角度来说,Binder是ServiceManager连接各种Manager(ActivityManager、WindowManager,等等)和相应Managerservice的桥梁:从Android应用层来说,Binder是客户端和服务端进行通信的媒介,当bindService的时候,服务端会返回一个包含了服务端业务调用的Binder对象,通过这个Binder对象,客户端就可以获取服务端提供的服务或者数据,这里的服务包括普通服务和基于AIDL的服务。
Android开发中,Binder主要用在Service中,包括AIDL和Messenger,其中普通Service中的Binder不涉及进程间通信,所以较为简单,无法触及Binder的核心,而Messenger的的底层其实是AIDL,所以这里选择用AIDL来分析Binder的工作机制。为了分析Binder的工作机制,我们需要新建一个AIDL示例,SDK会自动为我们生产AIDL所对应的Binder类,然后我们就可以分析Binder的工作过程。还是采用本章开始时用的例子,新建Java包AIDL,然后新建三个文件Book.java、Book.aidl和IBookManageraidl,代码如下所示。
Book.java
/**
* Created by lgl on 16/9/24.
*/
public class Book implements Parcelable {
public int bookId;
public String bookName;
public Book(int bookId, String bookName) {
this.bookId = bookId;
this.bookName = bookName;
}
protected Book(Parcel in) {
bookId = in.readInt();
bookName = in.readString();
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeInt(bookId);
dest.writeString(bookName);
}
@Override
public int describeContents() {
return 0;
}
public static final Creator<Book> CREATOR = new Creator<Book>() {
@Override
public Book createFromParcel(Parcel in) {
return new Book(in);
}
@Override
public Book[] newArray(int size) {
return new Book[size];
}
};
}
Book.aidl
// Book.aidl.aidl
package com.liuguilin.multiprocesssample;
// Declare any non-default types here with import statements
parcelable Book;
IBookManager.aidl
// IBookManager.aidl
package com.liuguilin.multiprocesssample;
// Declare any non-default types here with import statements
interface IBookManager {
List<Book>getBookList();
void addBook(in Book book);
}
上面的三個文件,Book.java是一个表示图书信息的类,他实现了Parcelable接口,而Book.aidl是Book类在AIDL中的声明,IBookManager是我们定义的一个接口,里面有两个方法,getBookList和addBook,其中getBookList是从服务器中获取图书列表,而addBook用于往图书列表中添加一本书,当然这两个方法主要是演示用的,并不需要有实际的意义,我们可以看到,尽管Book类和IBookManager位于相同的包中,但是在为IBookManager仍然要导入Book类,这就是AIDL的特殊之处,在根目录下的aidl包中有一个IBookManager类,这就是我们要找的类,我们通过这个生成Binder来分析Binder的工作原理
相关代码就不贴出来了,比较多
上述代码是系统生成的,为了方便查看,作者稍微的修改了一下格式,在gen目录下,可以看到根据IBookManager.aidl系统为我们生成了这个java类,他继承了IIntenrface接口,同时他自己也还是一个接口,所有可以在Binder中传输的接口都需要继承IIntenrface接口,这个类刚开始看起来比较混乱,但是实际上还是很清晰的,通过它,我们可以清楚地了解到Binder的工作机制。这个类的结构其实很简单,首先,它声明了两个方法getBookList和addBook,显然这就是我们在IBookManager.aidl中所声明的方法,同时它还声明了两个整型的id分别用于标识这两个方法,这两个id用于标识在transact过程中客户端所请求的到底是哪个方法。接着,它声明了一个内部类Stub,这个Stub就是一个
Binder类,当客户端和服务端都位于同一个进程时,方法调用不会走跨进程的transact过程,而当两者位于不同进程时,方法调用需要走transact过程,这个逻辑由Stub的内部代理类Proxy来完成。这么来看,IBookManager这个接口的确很简单,但是我们也应该认识到,这个接口的核心实现就是它的内部类Stub和Stub的内部代理类Proxy,下面详细介绍针对这两个类的每个方法的含义。
- DESCRIPTOR
Binder的唯一标识,一般用当前Binder的类名表示,比如本例子中的“com.liuguil.multiProcess.IBookManager”
asInterface(android.os.IBinder obj)
用于将服务端的Binder对象转换成客户端所需的AIDL接口类型的对象,这种转换过程是区分进程的,如果客户端和服务端位于同一进程,那么此方法返回的就是服务端的Stub对象本身,否则返回的是系统封装后的Stub.proxy
asBinder
此方法用于返回当前Binder对象
onTransact
这个方法运行在服务端的Binder线程池中,当客户端发起跨进程请求时,远程请求会通过系统底层封装后交由此方法来处理。该方法的原型为public Boolean onTransact (int code,android.os.Pareel data,android.os.Pareel reply,int fiags),服务端通过code可以确定客户端所请求的目标方法是什么,接着从data中取出目标方法所需要的参数(如果目标方法中有参数的话),然后执行目标方法,当目标方法执行完毕后,就向reply中写入返回值(如果目标方法有返回值的话),onTransact方法的执行过程就是这样的。需要注意的是,如果此方法返回false,那么客户端的请求会失败,因此我们可以利用这个特性来做权限验证,毕竟我们也不希望随便一个进程都能远程调用我们的服务。
Proxy#getBookList
这个方法运行在客户端,当客户端远程调用此方法时,它的内部实现是这样的:首先创建该方法所需要的输入型Parcel对象_data、输出型Parcel对象_reply和返回值对象List然后把该方法的参数信息写入_data中(如果有参数的话):接着调用transact方法来发起RPC(远程过程调用)请求,同时当前线程挂起;然后服务端的onTransact方法会被调用。直到RPC过程返回后,当前线程继续执行,并从_reply中取出RPC过程的返回结果;最后返回_reply中的数据。
- Proxy#addBook
这个方法路行在客户端,它的执行过程和getBookList是一样的,addBook没有返回值,所以它不需要从.reply中取出返回值。
通过上面分析,读者应该已经理解到Binder工作机制,但是有两点还是需要额外说明一下,首先,当客户端发起远程请求时,由于当前线程会被挂起直至服务器进程返回数据,所以如果一个远程方法是很耗时的,那么不能再UI线程中发起此远程请求,其次,由于服务器的Binder方法运行在Binder的线程池中,所以Binder方法不管是否耗时都应该给出一个Binder的工作机制图
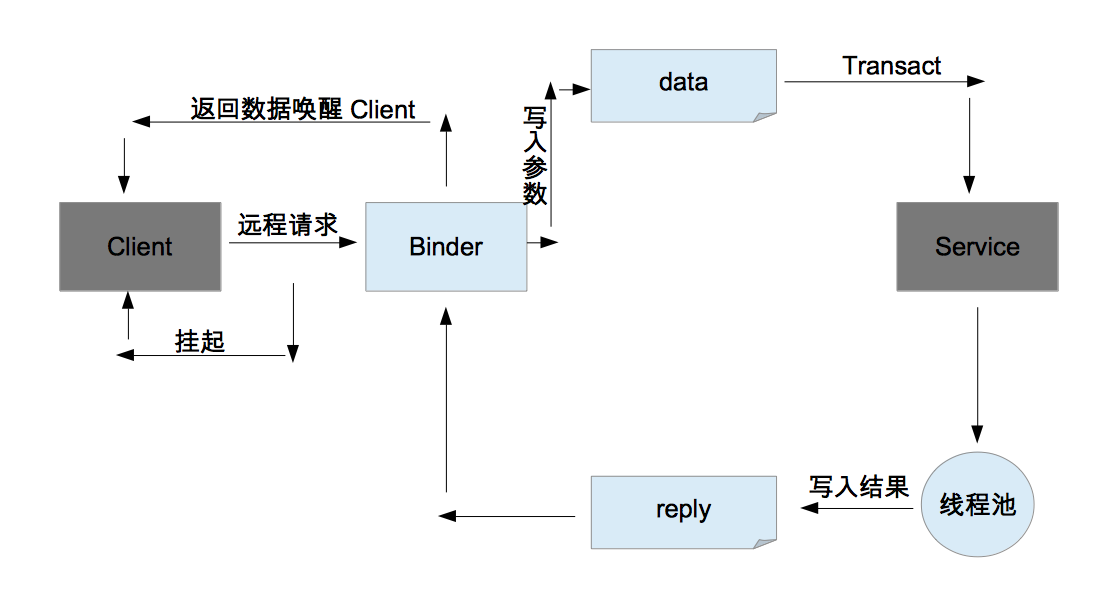
从上述分析过程来看,我们完全可以不提供AIDL文件即可实现Binder,之所以提供AIDL文件,是为了方便系统为我们生成代码。系统根据AIDL文件生成Java文件的格式是固定的,我们可以抛开AIDL文件直接写一个Binder出来,接下来我们就介绍如何手动写-个Binder。还是上面的例子,但是这次我们不提供AIDL文件。参考上面系统自动生成的IBookManager.java这个类的代码,可以发现这个类是相当有规律的,根据它的特点,我们完全可以自己写一个和它一模一样的类出来,然后这个不借助AIDL文件的Binder就完成了。但是我们发现系统生成的类看起来结构不清晰,我们想试着对它进行结构上的调整,可以发现这个类主要由两部分组成,首先它本身是一个Binder的接口(继承了IInterface),其次它的内部有个Stub类,这个类就是个Binder,还记得我们怎么写一个Binder的服务端吗?
private final IBookManager.Stub mBinder = new IBookManager.Stub(){
@Override
public List<com.liuguilin.multiprocesssample.Book> getBookList() throws RemoteException {
return mBookList;
}
@Override
public void addBook(com.liuguilin.multiprocesssample.Book book) throws RemoteException {
synchronized (mBookList){
if(!mBookList.contains(book)){
mBookList.add(book);
}
}
}
};
首先我们会实现一个创建了Stud对象并在内部实现了IBookManager的接口方法,并且在Service的onBind中返回这个Stud对象,因此,从这一点来看,我们完全可以把Stud类提取出来直接作为一个独立的Binder类来实现,这样IBookManager中就只剩下接口本身了,通过这种分离的方式可以让它的结构变得清晰点。
根据上面的思想,手动实现一个Binder可以通过如下步骤来完成。
- (1)声明一个AIDL性质的接口,只需要继承IInterface接口即可,IInterface接口中只一个asBinder方法。这个接口的实现如下:
/**
* Created by lgl on 16/9/25.
*/
public interface IBookManager extends IInterface {
static final String DESCRIPTOR = "com.liuguil.multiProcess.IBookManager";
static final int TRANSACTION_getBookList = IBinder.FIRST_CALL_TRANSACTION + 0;
static final int TRANSACTION_addBook = IBinder.FIRST_CALL_TRANSACTION + 1;
public List<Book> getBookList() throws RemoteException;
public void addBook(Book book)
throws RemoteException;
}
可以看到,在接口中声明了一个Binder描述符和另外两个id,这两个id分别表示的是getBookList和addBook方法,这段代码原本也是系统生成的,我们仿照系统生成的规则去手动书写这部分代码。如果我们有三个方法,应该怎么做呢?很显然,我们要再声明一个id,然后按照固定模式声明这个新方法即可,这个比较好理解,不再多说。
- (2)实现Stub类和Stub类中的Proxy代理类,这段代码我们可以自己写,但是写出来后会发现和系统自动生成的代码是一样的,因此这个Stub类我们只需要参考系统生成的代码即可,只是结构上需要做一下调整,调整后的代码如下所示。
/**
* Created by lgl on 16/9/25.
*/
public class BookManagerImpl extends Binder implements IBookManager {
public BookManagerImpl(){
this.attachInterface(this,DESCRIPTORS);
}
public static IBookManager asInterface(IBinder obj){
if (obj == null){
return null;
}
IInterface iin = obj.queryLocalInterface(DESCRIPTORS);
if((iin != null) && iin instanceof IBookManager){
return (IBookManager) iin;
}
return new BookManagerImpl.Proxy(obj);
}
@Override
public List<com.liuguilin.multiprocesssample.Book> getBookList() throws RemoteException {
return null;
}
@Override
public void addBook(com.liuguilin.multiprocesssample.Book book) throws RemoteException {
}
@Override
public IBinder asBinder() {
return this;
}
@Override
protected boolean onTransact(int code, Parcel data, Parcel reply, int flags) throws RemoteException {
switch (code){
case INTERFACE_TRANSACTION:
reply.writeString(DESCRIPTORS);
return true;
case TRANSACTION_getBookList:
data.enforceInterface(DESCRIPTORS);
List<com.liuguilin.multiprocesssample.Book> result = this.getBookList();
reply.writeNoException();
reply.writeTypedList(result);
return true;
case TRANSACTION_addBook:
data.enforceInterface(DESCRIPTORS);
Book book;
if(0!=data.readInt()){
book = Book.CREATOR.createFromParcel(data);
}else {
book = null;
}
this.addBook(book);
reply.writeNoException();
return true;
}
return super.onTransact(code, data, reply, flags);
}
private static class Proxy implements IBookManager{
private IBinder mRemote;
Proxy(IBinder remote){
mRemote = remote;
}
@Override
public List<com.liuguilin.multiprocesssample.Book> getBookList() throws RemoteException {
Parcel data = Parcel.obtain();
Parcel reply = Parcel.obtain();
List<Book>result;
try {
data.writeInterfaceToken(DESCRIPTORS);
mRemote.transact(TRANSACTION_getBookList,data,reply,0);
reply.readException();
result = reply.createTypedArrayList(Book.CREATOR);
}finally {
reply.recycle();
data.recycle();
}
return result;
}
@Override
public void addBook(com.liuguilin.multiprocesssample.Book book) throws RemoteException {
Parcel data = Parcel.obtain();
Parcel reply = Parcel.obtain();
try {
data.writeInterfaceToken(DESCRIPTORS);
if(book != null){
data.writeInt(1);
book.writeToParcel(data,0);
}else {
data.writeInt(0);
}
mRemote.transact(TRANSACTION_addBook,data,reply,0);
reply.readException();
}finally {
reply.recycle();
data.recycle();
}
}
@Override
public IBinder asBinder() {
return mRemote;
}
public String getInterfaceDescriptor(){
return DESCRIPTORS;
}
}
}
通过将上述代码和系统生成的代码对比,可以发现简直是一模一样的。也许有人会问,既然和系统生成的一模一样,那我们为什么要手动去写呢?我们在实际开发中完全可以通过AIDL文件让系统去自动生成,手动去写的意义在于可以让我们更加理解Binder的工作原理,同时也提供了一种不通过AIDL文件来实现Binder的新方式。也就是说,AIDL文件并不是实现Binder的必需品。如果是我们手写的Binder,那么在服务端只需要创建一个BookManagerImpl的对象并在Service的onBind方法中返回即可。最后,是否手动实现Binder没有本质区别,二者的工作原理完全一样,AIDL文件的本质是系统为我们提供了一种快速实现Binder的工具,仅此而已。
接下来,我们介绍Binder的两个很重要的方法linkToDeath和unlinkToDeath。我们知道,Binder运行在服务端进程,如果服务端进程由于某种原因异常终止,这个时候我们到服务端的Binder连接断裂(称之为Binder死亡),会导致我们的远程调用失败。更为关键的是,如果我们不知道Binder连接已经断裂,那么客户端的功能就会受到影响。为了解决这个问题,Binder中提供了两个配对的方法linkTopeath和unlinkTopeath,通过 linkToDeath我们可以给Binder设置一个死亡代理,当Binder死亡时,我们就会收到通知,这个时候我们就可以重新发起连接请求从而恢复连接。那么到底如何给Binder设置死亡代理成?也很简单:
首先,生命一个Deathleciient对象、Deathleciient是一个接口,其内部只有一个方法binderDied,我们需要实现这个方法,当Binder死亡的时候,系统就会回调binderDied方法,然后我们就可以移出之前绑定的binder代理并重新绑定远程服务;
private IBinder.DeathRecipient mDeathRecipient = new IBinder.DeathRecipient() {
@Override
public void binderDied() {
if(mBookManager == null){
return;
}
mBookManager.asBinder().unlinkToDeath(mDeathRecipient,0);
mBookManager = null;
//这个可以重新绑定远程service
}
};
其次,在客户端绑定远程服务成功之后,给binder设置死亡代理;
mService= IMessageBoxManager.Stub.asInterface(binder);
binder.linkToDeath(mDeathRecipient,0);
其次linkToDeath的第二个参数为标记位,我们直接设置为0即可,经过上述的步骤,我们就可以给Binder设置死亡代理了,当Binder死亡之后我们就可以收到通知了,另外。通过Binder的方法isBinderAlive也可以判断Binder是否死亡
到这里,IPC的基础知识就介绍完毕了,下面我们才是进入正题,直面形形色色的进程间通信;
这玩意实在是太长了,所以分开来写了;进程间通讯在下篇;
















 2583
2583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











