









线性回归算法
- 解决回归问题
- 思想简单,容易实现
- 许多强大的非线性模型的基础
- 结果具有很好的可解释性
- 蕴含机器学习中很多重要思想
1简单线性回归


分类问题的y周 为特征,颜色为类别,回归问题因为要预测连续的结果,所以需要一个轴来表示预测结果,y轴表示预测结果



2最小二乘法





import numpy as np
class SimpleLinearRegression1:
def __init__(self):
"""初始化Simple Linear Regression 模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x, y in zip(x_train, y_train): #使用循环方法
num += (x - x_mean) * (y - y_mean)
d += (x - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x,返回x的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression1()"以上代码实现性能较低,向量化后会变好
3.向量化
def fit(self, x_train, y_train):
"""根据训练数据集x_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1, \
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
#改进
#不使用for循环;使用向量化
self.a_ = (x_train - x_mean).dot(y_train - y_mean) / (x_train - x_mean).dot(x_train - x_mean)
self.b_ = y_mean - self.a_ * x_mean
return self4.线性回归算法的评测(不是训练时)
4.1均方误差 MSE (Mean Squared Error)
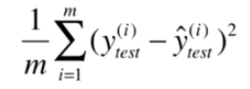
注意公式中是用的y_test ,前面乘以1/m,可以消除测试样本多少带来的差异(如测试时1000个样本误差为100,10个样本误差为80,并不能说第二次评测的效果好)
缺点:量纲问题。均方误差结果的量纲是原值量纲的平方倍,可以均方根误差解决这一问题
4.2均方根误差RMSE (Root Mean Squared Error)
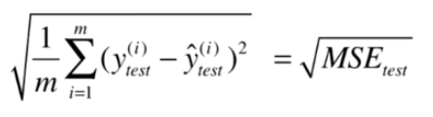
4.3 平均绝对误差MAE (Mean Absolute Error)
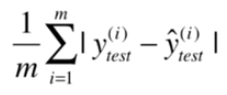
注意:我们在训练的时候没有将目标函数或者损失函数定义为这个,是因为绝对值不是一个处处可导的函数,不方便用来求极值。但是此方法完全可以用来最后评价线性回归算法。
换句话说,我们评价一个算法所使用的标准,和我们训练模型所使用的最优化目标函数,是可以完全不一致的

RMSE 与 MAE 量纲是相同的,但最终结果是rmse大于mae,因为rmse里的平方对于较大的误差,会有放大误差趋向。
所以尽量使rmse小, 表示最终预测结果最大的误差小
所以在训练时,目标函数选取带平方的有利于减小最终预测结果最大的误差。这也是不选绝对值的另一个原因(还有一个是不好求导)
而L1正则化也是绝对值,这样在目标函数求导时如何解决的?
4.4 R Squared 最好的衡量线性回归指标




5.多元线性回归




X表示原矩阵,X_b表示第一列加入1后的矩阵


问题:时间复杂度高:O(n^3) 优化后O(n^2.4)
解决办法:梯度下降法(本节使用公式法)
优点:不需要对数据做归一化处理。根据公式直接带入就行
而knn由于需要计算距离,需要考虑不同量纲的差别,所以knn要进行归一化处理

最终将结果报告给用户的时候,可能会将 截距与
-
系数分开,因为系数部分每一个
值都对应着原来样本中的一个特征,这些系数从某种程度上可以用来描述这些特征对最终样本的贡献程度是怎样的
X_b = np.hstack([np.ones((len(X_train),1)),X_train])#加一列1
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)#求theta
self.interception_ =self._theta[0] #截距
self.coef_ = self._theta[1:] #系数
6.线性回归的可解释性
import numpy as np
from sklearn import datasets
boston = datasets.load_boston() #导入波士顿房价数据
X = boston.data #导入数据
y = boston.target #导入标签
X = X[y < 50.0] #去除上限点 y=50的情况
y = y[y < 50.0] #去除上限点 y=50的情况
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression() #实例化对象
lin_reg.fit(X, y) #fit全部数据(没有做测试训练切分),因为只看一些线性关系
lin_reg.coef_ #查看线性回归前面对应的系数theta(不看截距)
#输出array([ -1.05574295e-01, 3.52748549e-02, -4.35179251e-02,
4.55405227e-01, -1.24268073e+01, 3.75411229e+00,
-2.36116881e-02, -1.21088069e+00, 2.50740082e-01,
-1.37702943e-02, -8.38888137e-01, 7.93577159e-03,
-3.50952134e-01])
np.argsort(lin_reg.coef_) #将系数按索引从小到大排序
#输出array([ 4, 7, 10, 12, 0, 2, 6, 9, 11, 1, 8, 3, 5])
boston.feature_names[np.argsort(lin_reg.coef_)] #将索引对应的特征提取出来
#输出array(['NOX', 'DIS', 'PTRATIO', 'LSTAT', 'CRIM', 'INDUS', 'AGE', 'TAX',
'B', 'ZN', 'RAD', 'CHAS', 'RM'], dtype='<U7')
print(boston.DESCR) #打印波士顿数据对应的特征描述信息由代码注释中的输出结果可知:
输出权值最大的正特征为RM,表示房间的数量 。表示房间数量越多价格越高 。
输出权重第二大的正特征为CHAS,表示房子是否临河,临河的价格高
输出最小的负特征为NOX 表示有毒气体的浓度,越高房价越低。
更重要的是当我们获得这种可解释性后,可以 有针对性的去采集更多的特征,来更好的描述房价。(比如:根据房间数量的正特征性,想到采集一些房间面积的数据等,或者根据有毒气体特征,采集一些房子周围是否有化工厂的特征等。进一步来看会不会产生更好的模型)
所以即使数据首先采用线性回归预测的结果不够好 ,但是我们通过这样的方式首先来看一看数据特征和最终结果的线性关系的相应系数 有多大,也是很有意义的。所以从某种角度来讲 ,拿到一组数据后 先使用线性 的方式试试看也是没有坏处的
7.线性回归总结
对数据有假设:线性
对比knn对数据没有假设
优点:对数据具有强解释性,是白盒算法(得到模型后,基于模型能真正学到一些知识,(比如房价和房间数量成正比))
















 4377
4377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









