







多项式回归完全使用线性回归的思路。关键在于我们为原来的数据样本添加新的特征,而得到这些新的特征的方式是原有特征的多项式组合,这样就可以解决一些非线性问题。
多项式阶数越高模型越复杂
所以训练过程 可以先添加特征,然后再调用线性回归
import numpy as np
import matplotlib.pyplot as plt
#生成数据
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, 100)
X2 = np.hstack([X, X**2]) #添加特征
#线性回归
from sklearn.linear_model import LinearRegression
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)
#绘制结果
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r') #注意此处直接绘制,y_predict2,图形是乱的,因为x是随机生成的是乱序的。绘制直线时即使是乱序的也没事
plt.show()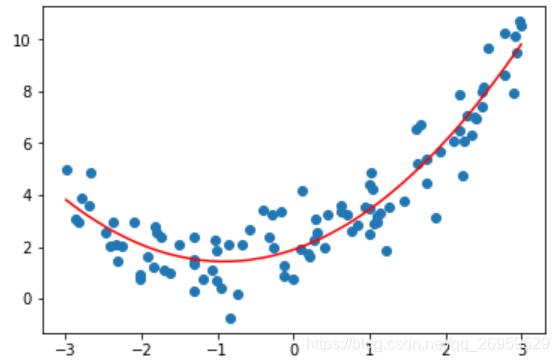
sklearn中的多项式回归
由于多项式回归主要是在调用线性回归之前改造了X,为X添加了特征,相当于数据预处理;所以在scikit-learn中对多项式的添加特征的过程封装在了sklearn.preprocessing包中(归一化也在这个包)
添加特征
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)#最多添加几次幂特征
poly.fit(X)
X2 = poly.transform(X) #PCA / 归一化也是用fit transform 的方式调用线性回归
from sklearn.linear_model import LinearRegression
lin_reg2 = LinearRegression()
lin_reg2.fit(X2, y)
y_predict2 = lin_reg2.predict(X2)绘图
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict2[np.argsort(x)], color='r')
plt.show()
关于PolynomialFeatures
当X数据有2列X(x1,x2),使用PolynomialFeatures(degree=2),后会变几列?(6列)
分别为 0次幂1列、1次幂2列(原X)、2次幂3列(x1^2,x1*x2,x2^2)
X = np.arange(1, 11).reshape(-1, 2)
poly = PolynomialFeatures(degree=2)
poly.fit(X)
X2 = poly.transform(X)
X2.shape #结果:(5,6)
X2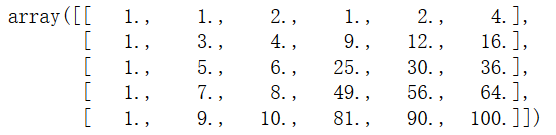
当degree等于3时 原X变为10列

PolynomialFeatures(degree=i)使原数据列数指数级增长
Pipeline
多项式回归过程:
- 将原始数据通过使用PolynomialFeatures(degree=i)这个类生成多项式特征样本的数据
- 如果degree的值比较大,样本经过degree次方后将变得特别大,和1次方差距很大。
- 在线性回归中使用梯度下降法,如果数据太不均衡,会使得搜索非常的慢,需要归一化
- 送入线性回归
pipeline 可以帮助我们将这几步合在一起,使得我们每一次调用时不需要不停的重复这几步。
sklearn并没有提供多项式回归这个类,使用pipeline方式可以方便的创建自己的多项式回归的类
使用Pipeline
1生成数据
#生成数据
x = np.random.uniform(-3, 3, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, 100)2使用pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# 三个步骤封装在一起,引号里的名字时自定义的
poly_reg = Pipeline([
("poly", PolynomialFeatures(degree=2)),
("std_scaler", StandardScaler()),
("lin_reg", LinearRegression())
])3直接使用pipeline训练预测多项式回归模型
poly_reg.fit(X, y)
y_predict = poly_reg.predict(X)4.绘制结果
plt.scatter(x, y)
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r')
plt.show()
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









