







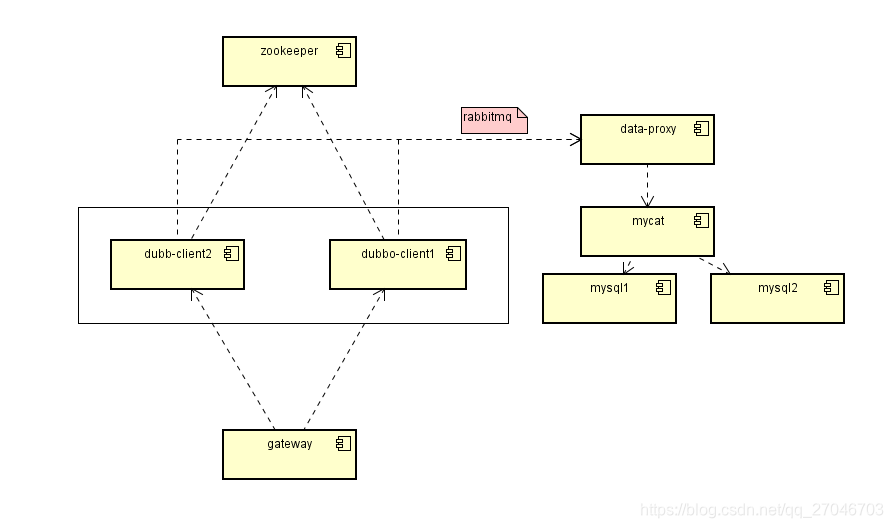
实验环境
- 两台双核4G的阿里云服务器,服务器上没有其他影响因子。(简单称呼为服务器A和服务器B)
- 在两台服务器上安装mysql数据库 (version: 5.7)。
- 使用mycat 进行分库切换(暂不进行分表)
- 消息中间件Rabbitmq,所以写入数据库的内容都会发送到队列,消费者取出后进行入库操作。(削峰)
- 注册中心zookeeper。(mycat的全局唯一id自己计算,不依赖zookeeper的ID算法)
- dubbo 快速多实例布置(这里先模拟2个实例,看情况增加)
- 压测工具 ab , 通过命令模拟大量的接口请求,同时接口只做一件事情,就是把构造好的随机内容进行入库,与真实环境略有差距,真实环境往往需要根据某个key查询到数据,再进行到下一步,可以实验结果下调10-20%之间(真实环境可能会使用redis记录一些缓存,避免频繁的查库,当然这也看命中率)。
- springboot + mybatis 中规中矩的常规操作,平平无奇。
数据库-Mysql
Linux上面安装mysql 就不展开介绍了,这里就简单给出实验环境的表,就一张
CREATE TABLE `tb_message` (
`message_id` bigint(20) NOT NULL COMMENT '消息主键',
`content` varchar(1024) NOT NULL COMMENT '消息内容',
`from_user` varchar(64) NOT NULL COMMENT '消息发送者用户编号',
`to_user` varchar(64) NOT NULL COMMENT '消息接收者用户编号',
`send_time` timestamp NULL DEFAULT NULL COMMENT '发送时间',
`remark` varchar(128) DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`message_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试消息数据表';
我在服务器A和服务器B都装好了mysql,并且创建了一样的database : db_test,同时向两个db中创建了tb_message表。为了方便直接使用root用户进行操作。到此数据库的操作先告一段落。
数据库中间件-Mycat
Mycat的历史可以到Mycat官方进行了解,这里直奔主题。Mycat是Java编写的,我们要从github把项目检下来,配置文件,然后运行。
- 将服务器A作为主环境。
- Mycat-server 源码下载: https://github.com/MyCATApache/Mycat-Server (这里只是让你了解源码,要到服务器上运行情况 README.md中的描述) 。
- Mycat Linux 快速可运行下载: https://github.com/MyCATApache/Mycat-download (我下载了最新的1.6版本,解压之后更换了config中的配置文件)
- 配置文件,主要是三个文件: schema.xml,rule.xml,server.xml,这三个文件描述了Mycat的服务信息(server.xml),逻辑库和物理库的映射关系(schema.xml),分库分表的规则(rule.xml)
schema.xml
这里我们需要把我们的物理数据库环境和mycat做个映射,简单来说就是告诉Mycat我的物理库在哪里,你要用哪个账号操作哪个表。
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--name="USER1DB" 为逻辑库的名字(具体来说就是一个虚拟的Database名称)-->
<!--checkSQLschema="true" 去掉逻辑库名作为sql语句的前缀-->
<!--sqlMaxLimit="100" 为了避免数据量过大,一下子跑死,设置此逻辑库的条目限制为1000条。 此处要小心内存溢出-->
<schema name="MESSAGEDB" checkSQLschema="true" sqlMaxLimit="1000">
<table name="tb_message" primaryKey="message_id" dataNode="dn1,dn2" rule="mod-long"></table>
</schema>
<!--dataNode 绑定到具体的实际的database中,也就是说我的mysql有一个库名为db1的database-->
<!--dataHost="localhost1" 执行连接信息的指向标签-->
<dataNode name="dn1" dataHost="dhost1" database="db_test" />
<dataNode name="dn2" dataHost="dhost2" database="db_test" />
<!--这里就是配置真是连接到物理数据的信息配置-->
<!--maxCon="1000" 每个读写连接池的最大连接数-->
<!--minCon="10" 每个读写连接池的最小连接数,初始化连接数的大小-->
<!--balance="0" 读写不分离,还有其他值 1, 2, 3 表示读写分离模式下的配置,详情查阅文档-->
<!--writeType="0" 负载均衡配置,0表示所有写操作发给第一个写节点,挂了就发给第二个,以此类推-->
<!--switchType="1" 1表示负载均衡自动切换,-1表示不切换,2基于Mysql主从同步状态切换-->
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!--定期心态检测连接-->
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="172.19.155.20:3306" user="root" password="root"></writeHost>
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!--定期心态检测连接-->
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="172.19.155.21:3306" user="root" password="root"></writeHost>
</dataHost>
</mycat:schema>
server.xml
mycat 也是一个服务,这里就是指明了服务的启动配置,可以把server当做是一个伪mysql,下面的user标签指明了连接此伪mysql的用户,8066为连接的端口,这点在持久层连接mycat的时候会进一步提现。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<!--MyCat 的系统配置-->
<system>
<!--mycat连接的端口8066和管理端口9066-->
<property name="serverPort">8066</property>
<property name="managerPort">9066</property>
<!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="nonePasswordLogin">0</property>
<!-- 0遇上没有实现的报文(Unknown command:),就会报错、1为忽略该报文,返回ok报文。在某些mysql客户端存在客户端已经登录的时候还会继续发送登录报文,mycat会报错,该设置可以绕过这个错误-->
<property name="ignoreUnknownCommand">0</property>
<!---->
<property name="useHandshakeV10">1</property>
<!---->
<property name="removeGraveAccent">1</property>
<!-- 1为开启实时统计、0为关闭 -->
<property name="useSqlStat">0</property>
<!---->
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<property name="subqueryRelationshipCheck">false</property>
<!---->
<property name="sequenceHanlderClass">io.mycat.route.sequence.handler.HttpIncrSequenceHandler</property>
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--字符集编码-->
<property name="charset">utf8</property>
<!--连接超时时间,超过30分钟无人使用的sql连接会关闭-->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<!--指定Mycat全局ID的生成算法, 0为本地文本,1数据库方式,2时间戳方式,3分布式ZK ID生成器,4为ZK 递增ID-->
<property name="sequenceHandlerType">1</property>
<!-- 1为开启全局一致性检测、0为关闭 -->
<property name="useGlobleTableCheck">0</property>
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--off heap for merge/order/group/limit 1开启 0关闭-->
<property name="useOffHeapForMerge">0</property>
<!--单位为m-->
<property name="memoryPageSize">64k</property>
<!--单位为k-->
<property name="spillsFileBufferSize">1k</property>
<!---->
<property name="useStreamOutput">0</property>
<!---->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
<!--如果为0的话,涉及多个DataNode的catlet任务不会跨线程执行-->
<property name="parallExecute">0</property>
</system>
<user name="user1">
<property name="password">123456</property>
<property name="schemas">MESSAGEDB</property>
<!--当整体connection达到多少时,开始降级处理(拒绝连接)-->
<property name="benchmark">5000</property>
<!--对库中的table进行精细化的DML权限控制,check=false不检查-->
<!--<privileges check="false"></privileges>-->
</user>
</mycat:server>
rule.xml
- 分库规则配置,tableRule指的规则的名称,以哪个col使用规则,function 标签则指向了具体的代码实现部分。直接用官方提供的,当然也可以自己写。
(注意 mod-long 这个tableRule的 columns的配置,跟实际表的主键名称要一致)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-date">
<rule>
<columns>createTime</columns>
<algorithm>partbyday</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>message_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="partbyday"
class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sNaturalDay">0</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sEndDate">2014-01-31</property>
<property name="sPartionDay">10</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
测试结果
其他模块就不再展开,搞了半天,终于按照设计的图把整个结构搞出来了,源码上传到github,像zookeeper和rabbitmq这种安装就不多累述,网上搜一下一大堆。
github测试源码
下面就贴出我压测的结果吧…
压测指令: ab -T ‘application/json;charset=UTF-8’ -n 50000 -c 500 http://localhost:8582/test
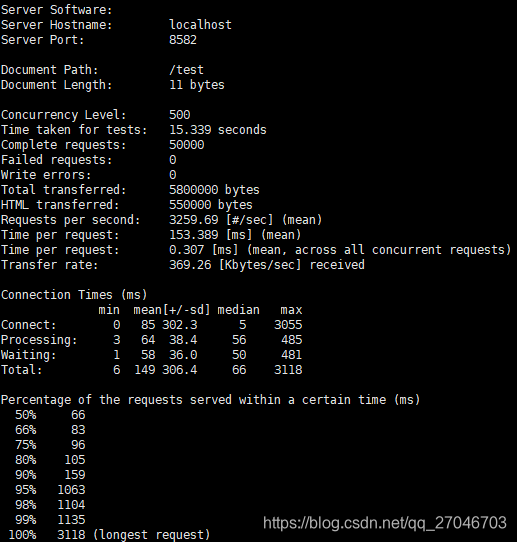
单个请求的大小是 11K,每秒平均并发写入是 3259.69/s , 也就说1秒钟3200+的写入,这个性能和我预期的还是有点差距的。。 虽然只有两台主机,但是我预期应该要到5000+的,下午再查查看哪里有问题, 总之现在就像吃了死老鼠一样的难受。
死磕后续
后续进行排查后,发现了几个问题,进行排查后重新进行测试。
问题:
- ID生成算法有bug,没有使用单例,导致请求疯狂的创建的实例,其中还有一些ID重复,从队列中取出来插入数据库失败,没有ACK,然后疯狂的循环,占用CPU。
- rabbimq 缓存了一些数据在队列中,所以无法比较清晰的明白数据库瓶颈在哪里,所以我直接把队列去掉了,直接从client那边连接到mycat。
- 压测的并发不够大,早上并发只有500,主要是一开始比较心虚,就设置小点,这可能也是导致TPS上不去的原因。
- 线程池开太大,一开始线程池设置初始 10个线程,队列1024,最大线程数50,后面仔细一想,线程数太多,会导致上下文频繁的切换,可能很多时间浪费在这里,于是修改初始线程5个,队列1024,最大线程10。效果上去了。
- JVM的内存太小,一开始gateway的内存设置了378M,client也是378M,运行后,我发现JVM内存变化比较明显,FGC也比较多,后续我把gateway和client的JVM内存都设置了1024M,测试后,FGC次数少了很多,效果上去了。
经过调整后,整个并发的情况稳定在4500~5000之间,前后测试了30多次,结果基本都没有太大的偏差。
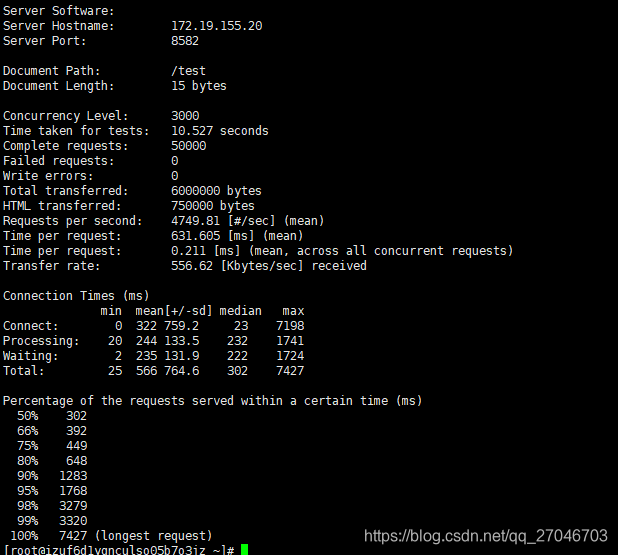
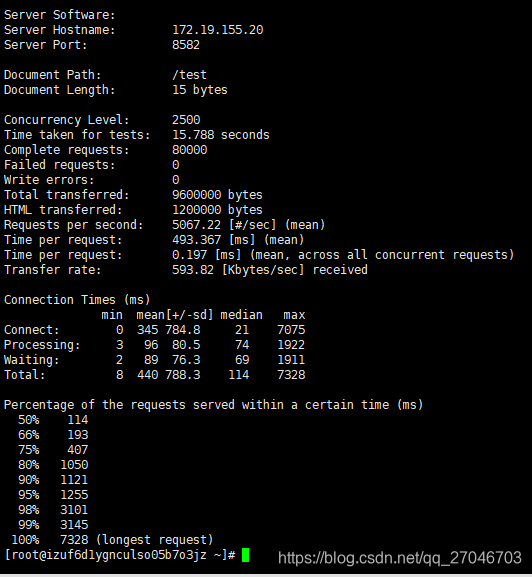
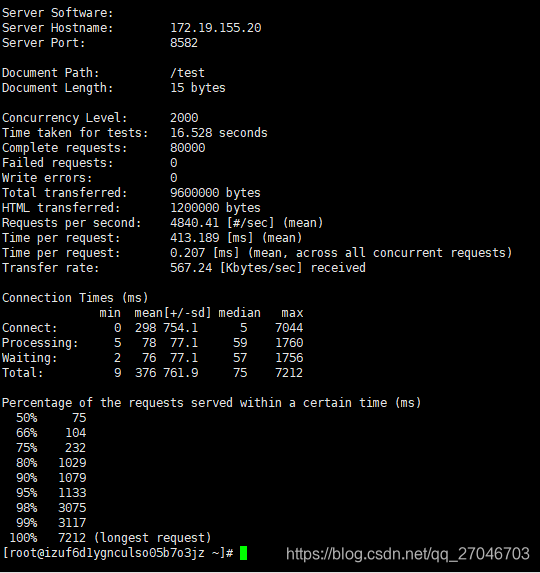
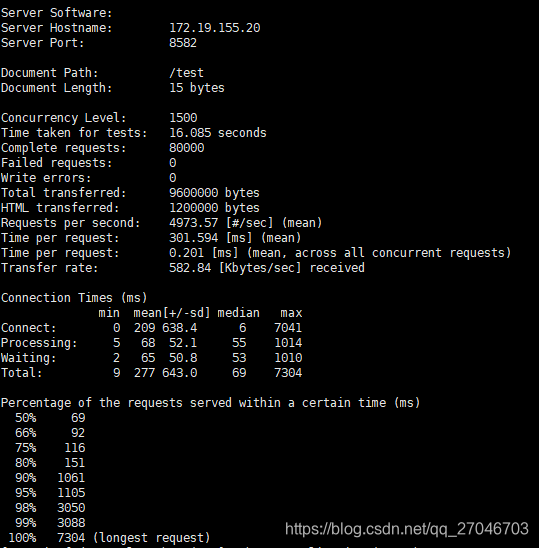
改进之后和预期的结果比较接近了,如果加上队列的缓冲,可能TPS还能再上去一些。不过实际环境业务比较复杂,一处小小的BUG都可能导致整个过程性能下降,所以写代码还是需要谨慎。 同时JVM对性能的影响也是很明显的,合理的调整JVM,使用垃圾收集器也是提升性能的关键手段。后续可能换一下G1垃圾收集器再测试下。














 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









