







 本文介绍了R语言中如何处理数据清洗的问题,包括计算缺失值比例、缺失值填充(均值、中位数、众数)、数据类型转化(如因子变量创建、哑变量生成)以及高相关性、低方差和共线性变量的诊断与剔除。使用了如`is.na()`、`complete.cases()`、`factor()`、`model.matrix()`等函数。
本文介绍了R语言中如何处理数据清洗的问题,包括计算缺失值比例、缺失值填充(均值、中位数、众数)、数据类型转化(如因子变量创建、哑变量生成)以及高相关性、低方差和共线性变量的诊断与剔除。使用了如`is.na()`、`complete.cases()`、`factor()`、`model.matrix()`等函数。
数据清洗是将原始的数据进行整理和规范,以达到数据分析人员使用要求的数据。这个过程很重要,也很花费时间。现将当前学到的方式总结,欢迎大家互相交流。
1.缺失值处理
在R中,当原始数据中存在缺失值时,该缺失值用NA表示,如下图有一个缺失值。
birth=read.csv("chds_births.csv",header = TRUE)
head(birth)

若某一列数据缺失过多(>30%),那么这一列实际上就已经丢掉了很多关键的信息,可以从数据集中直接去掉这一列。若缺失的不是很多数据,则需要对该列进行填充。
1.1 缺失率计算
1.查看某列缺失情况
#查看某列是否缺失
is.na(birth$gestation)
该函数返回一个BOOL类型的数组,若缺失,则对应位置为TRUE,否则为FALSE.
2.查看数据集缺失情况
#检查数据集内是否含有缺失值
anyNA(birth)
若填充完毕后,想要查看该数据集是否还有缺失值,则该函数可以进行检验。若还有缺失值,则返回TRUE,否则返回FALSE.
3.计算缺失率
#查看缺失率
sapply(birth,f unction(df){sum(is.na(df)/nrow(birth))})

如上图所示,计算了每列的缺失比率。我们发现fht这一列缺失率高达39.8%,这一列原则上可以删除。
4.缺失情况可视化
方法一:
#缺失率可视化
library(Rcpp)
library(Amelia)
missmap(birth,main="missing map")
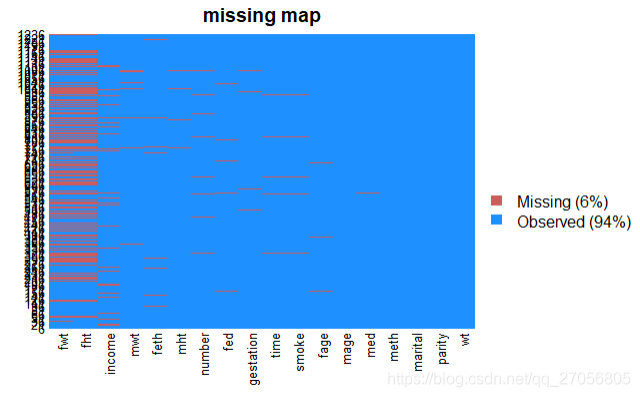
当然R也提供可视化缺失率的包,在可视化之前需要安装Rcpp包和Amelia包。先安装Rccp包,再安装Amelia包。如上面的代码可见。从
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









