







在使用集合的时候,我们有时候需要取两个集合的差集,这两个集合一般是List类型的集合。
一般情况下,要是我们自己去造轮子的话 ,那也简单。
只是。因人而异,造出来的轮子的质量也是参差不齐。
既如此,何不使用别人已经造好的,专业的轮胎呢?
下面的代码呢,是我自己实现的取list和map的差集的方法。主要是基于guava工具类的实现。
具体看代码吧。
package com.lxk.collectionTest;
import com.google.common.collect.Lists;
import com.google.common.collect.Maps;
import com.google.common.collect.Sets;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.Set;
/**
* 取两个集合的差集
* <p>
* Created by lxk on 2017/2/17
*/
public class GetDifferenceSet {
public static void main(String[] args) {
List<String> big = Lists.newArrayList("1", "2", "3", "4", "5", "6", "7", "8", "9");
List<String> small = Lists.newArrayList("1", "2", "3", "3", "2", "1");
long a=System.currentTimeMillis();
List<String> guava = getDifferenceSetByGuava(big, small);
System.out.println("\r<br> 执行耗时 : "+(System.currentTimeMillis()-a)/1000f+" 秒 ");
//为了显示一致,我给集合排个序,因为guava是按newHashSet集合来整的,newHashSet又是无序的,so ...
Collections.sort(guava);
a=System.currentTimeMillis();
List<String> my = getDifferenceSetByMyself(big, small);
System.out.println("\r<br> 执行耗时 : "+(System.currentTimeMillis()-a)/1000f+" 秒 ");
System.out.println(guava.toString());
System.out.println(my.toString());
Map<String, String> bigMap = Maps.newHashMap();
bigMap.put("1", "1");
bigMap.put("2", "2");
bigMap.put("3", "3");
bigMap.put("4", "4");
Map<String, String> smallMap = Maps.newHashMap();
smallMap.put("1", "1");
smallMap.put("2", "2");
a=System.currentTimeMillis();
Map<String, String> guavaMap = getDifferenceSetByGuava(bigMap, smallMap);
System.out.println("\r<br> 执行耗时 : "+(System.currentTimeMillis()-a)/1000f+" 秒 ");
System.out.println(guavaMap);
}
/**
* 使用guava工具类来取List集合的差集--专业轮子谷歌造
*
* @param big 大集合
* @param small 小集合
* @return 两个集合的差集
*/
private static List<String> getDifferenceSetByGuava(List<String> big, List<String> small) {
Set<String> differenceSet = Sets.difference(Sets.newHashSet(big), Sets.newHashSet(small));
return Lists.newArrayList(differenceSet);
}
/**
* 自己实现取List集合的差集--自制轮子大师兄造
*
* @param big 大集合
* @param small 小集合
* @return 两个集合的差集
*/
private static List<String> getDifferenceSetByMyself(List<String> big, List<String> small) {
Set<String> sameString = Sets.newHashSet();
for (String s : small) {
sameString.add(s);
}
List<String> result = Lists.newArrayList();
for (String s : big) {
if (sameString.add(s)) {
result.add(s);
}
}
return result;
}
/**
* 自己实现取Map集合的差集--站在巨人的肩膀上造轮子
*
* @param bigMap 大集合
* @param smallMap 小集合
* @return 两个集合的差集
*/
private static Map<String, String> getDifferenceSetByGuava(Map<String, String> bigMap, Map<String, String> smallMap) {
Set<String> bigMapKey = bigMap.keySet();
Set<String> smallMapKey = smallMap.keySet();
Set<String> differenceSet = Sets.difference(bigMapKey, smallMapKey);
Map<String, String> result = Maps.newHashMap();
for (String key : differenceSet) {
result.put(key, bigMap.get(key));
}
return result;
}
}
代码运行结果,如下图:
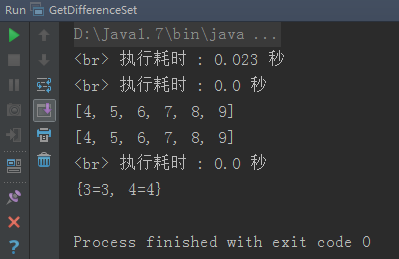
关于,后面去hashmap集合的差集的思路:
首先hashmap的不同都是跟key相关的,key不同,那就是不同的map。然后就根据这个key来处理,就可以取出差集啦。
关于,执行时间问题。
惊讶的发现,使用工具类执行时间反而有点慢,虽然只是0,023秒,估计是优化了吧,可能小数据量看不出来优劣。
就像,stringBuffer或者stringBuilder,在乍一看的时候,好像比直接使用字符串慢一样。但,他之所以存在,肯定是有好处的。
不然,谷歌那一帮人,干嘛整个这个出来。















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









