







 文章探讨了NoSQL数据库的兴起背景,包括解决传统关系型数据库的局限性和适应集群环境的需求。介绍了键值、文档、列族和图四种数据模型,强调了聚合在数据操作中的重要性。同时,讨论了数据库的分布式模型,如分片和复制,以及一致性问题,包括更新和读取一致性。映射-化简模式作为并发计算的工具也在文中得到阐述。
文章探讨了NoSQL数据库的兴起背景,包括解决传统关系型数据库的局限性和适应集群环境的需求。介绍了键值、文档、列族和图四种数据模型,强调了聚合在数据操作中的重要性。同时,讨论了数据库的分布式模型,如分片和复制,以及一致性问题,包括更新和读取一致性。映射-化简模式作为并发计算的工具也在文中得到阐述。
一、为什么使用NoSQL
1.NoSQL产生背景
1.1应用程序开源人员深受阻抗失谐问题的困扰
关系型数据库中,关系模型和内存中的数据结构之间存在差异,使得数据在存储前需要进行转译。
1.2 数据库领域迁移趋势改变
原来,各个应用程序都把同一份数据库当成共用的集成点,而现在各个应用程序都会封装自己的数据库,并通过服务彼此集成。
1.3 由于关系型数据库与集群不协调,促使数据存储方式发生变化
为了应对数据和流量的增加,必须有更多的计算机资源。采用由多个小型计算机组成的集群成为一种好的解决方案。它不仅能降低扩展所需的成本,也更有弹性(构建一个高度稳定的集群,就算其中的某些电脑经常发生故障,也不会影响整个集群的运行,不会影响到系统)。
2.NoSQL登场
在向集群迁移的过程中,产生了一个新的问题:关系型数据库并不是设计给集群用的。虽然Oracle RAC或Microsoft SQL Server 是支持集群的,但是在运行时存在技术问题,使用上也有许可费问题。由于关系型数据库与集群不协调,促使数据存储方式发生变化,在不断探索中NoSQL登场。NoSQL是偶然出现的新名词,没有一个明确的定义。我们只能描述此类数据库所共有的特征。
2.1共同特征
不使用关系模型
在集群中运行良好
开源
适用于21世纪的互联网公司
无模式
2.2什么时候选用NoSQL
待处理的数据量很大,或对数据访问的效率要求很高,从而必须将数据放在集群上
想采用一种更为方便的数据交互方式来提高应用程序开发效率。
二、聚合数据模型
NoSQL中广泛使用的模型分为四类:键值、文档、列族和图。 其中前三类数据模型都是“面向聚合”数据库。
聚合
聚合是“领域驱动设计”中的术语。把一组相互关联的对象视为一个整体单元来操作,这个单元就叫聚合。
关系模型与聚合模型
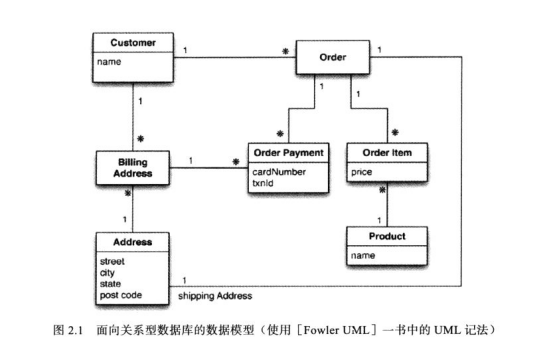
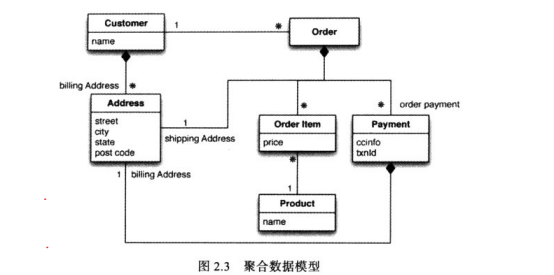

在聚合模型中对于如何划分聚合边界并没有标准答案,这完全取决于你打算怎么来操作数据,要做的更多是规划数据访问方式。
键值数据模型与文档数据模型
| 不同 | 优势 |
键值数据库 | 1.聚合不透明 2.访问聚合内容,只能通过键来查找 | 聚合中可以存储任意数据 |
文档数据库 (限制其中存放的内容,它定义了其允许的结构与数据类型) | 1.聚合透明 2.用聚合中的字段查询 | 可以看到其结构,能够更加灵活地访问数据。
|
键值数据库和文档数据库之间的界限有点模糊
列族存储
理解列族模型的最好方式也许就是将其视为两级聚合结构。列族数据库将列组织为列族。每一列都必须是某个列族的一部分,而且访问数据的单元也得是列。在列族数据库Cassandra中的“行”只能出现在一个列族中,然而列族可以包含“超列”(supercolumn),也就是列里可以再嵌套列。
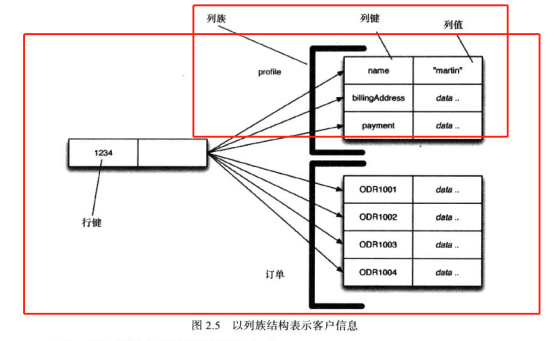
列族结构与“键值存储”的区别在于,其“行聚合”(row aggregate)本身又是一个映射,其中包含一些更为详细的值。这些“二级值”(second-level value)就叫做“列”。
总结
数据模型 | 特点 |
键值数据模型 | 将聚合看作不透明的整体这意味着只能根据键来查出整个聚合,而不能仅仅查询或获取其中的一部分 |
文档模型 |
|
列族模型 |
|
共同点是,它们都使用聚合这一概念,而且聚合中都有一个可以查找其内容的索引键 | |
三、数据库里的聚合模型
1.关系
聚合的有用之处在于它可以把经常访问的数据存放在一起。但在有些情况下,我们需要以不同方式来访问相互关联的数据。需要考虑一下客户和其全部订单之间的关系。
许多数据库都提供了描述这种关系的手段。面向聚合数据库获取数据时以聚合为单元,它只能保证单一聚合内部内容的原子性,面向聚合数据库在操作多个聚合时显得相当笨拙。
2.图数据库
图数据库它的基本数据模型很简单:由边(或称“弧”,arc)连接而成的若干节点。
以节点与边把图结构搭建好之后,就可以用专门为“图”而设计的查询操作来搜寻图数据库的网络了
图形数据库通常运行在单一的服务器上,而不是分布于集群中。
图数据库和其他一些“聚合无知式数据库”都支持与关系型数据库类似的ACID操作
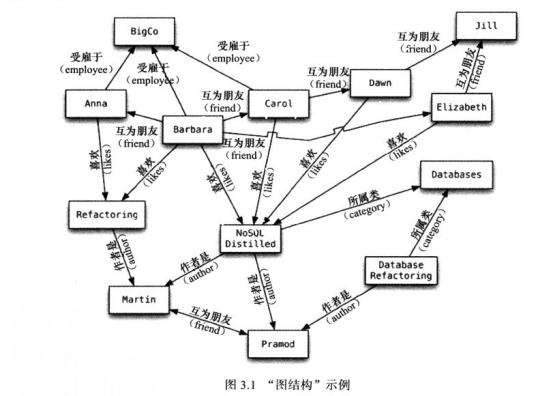
*这里的图是一种图形数据结构(graph data structure),其中含有连接节点(node)的边 (edge)。
3. 无模式数据库
3.1模式
“模式”,也就是用一种预定义结构向数据库说明:要有哪些表格,表中有哪些列,每一列都存放何种类型的数据。必须先定义好模式,然后才能存放数据.
3.2无模式数据库
键值数据库 | 可以把任何数据存放在一个“键”的名下 |
文档数据库 | |
列族数据库 | 任意列里面都可以随意存放数据 |
图数据库 | 新增边,也可以随意向节点和边中添加属性 |
好处:在数据更改方面更自由更灵活,更容易处理“格式不一致的数据” | |
存在的问题:处理数据时,程序通常要依赖于某种形式的“隐含模式”(它是指在编写数据操作代码时,对数据结构所做的一系列假设)、无法自行验证数据 | |
“无模式”的灵活性仅限于聚合内部,如果改动了聚合边界,那么其数据迁移工作与关系型数据库一样,都非常复杂。
本质上,无模式数据库是把模式交由访问其数据的应用程序代码来处理。
3.4 物化视图
3.4.1 定义
这是一种预先算好并缓存在磁盘中的视图。
3.4.2 适用场合
数据读取非常频繁,而访问者又不介意略显陈旧的数据,那么使用物化视图效率比较高。
3.4.3 NoSQL中构建物化视图
NoSQL数据库没有视图,但是它们可以预先计算查询操作的结果,并将其缓存起来。NoSQL借用”这个术语来表述此操作
构建物化视图的方法:
方法一:一旦基础数据(base data)有变动,那么立即更新物化视图。
方法二:定期通过批处理操作来更新它。你需要理解业务需求,据此判断物化视图可以使用多久以前的数据
3.5 构建数据存储模型
构建数据聚合模型时,既要考虑数据的读取方式,也要考虑模型对这些同聚合相关联的数据会产生何种副作用
先来看键值存储模型,应用程序可以通过“键”读出客户信息及其全部数据
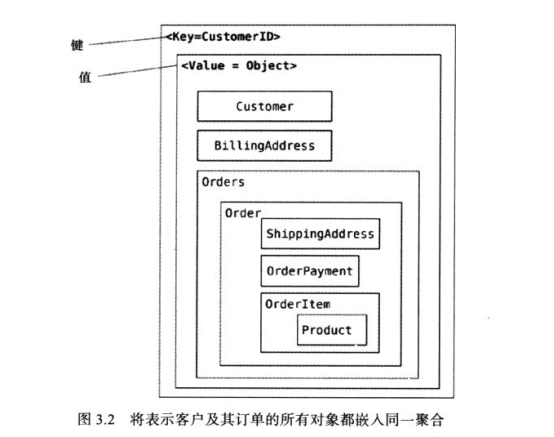
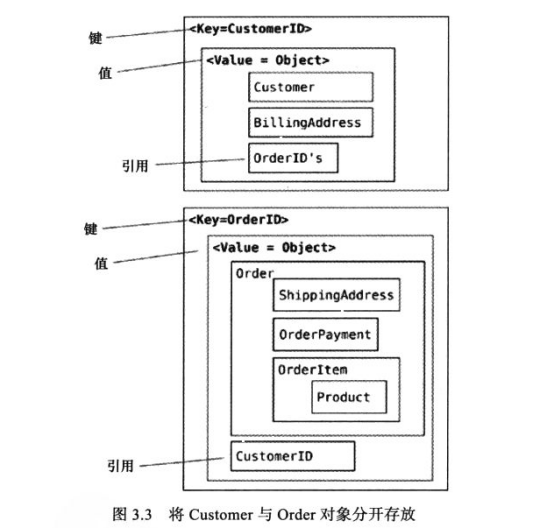
文档数据库中,由于在文档数据库中可按属性查询文档内容,可以把“键值存储”中的数据切分为Customer和Order两个对象,
以“列族存储”形式建模,那么就可以调整各列的次序了。我们可以给频繁用到的那些列起一个能够排在前面的名字,这样就能优先读取它们了。使用列族建模时,应该按照查询需求而非写入需求来做。
用图数据库来建模,则要将其中的对象做成节点,将对象之间的关系变成节点之间的关系。这些关系的类型与方向很重要
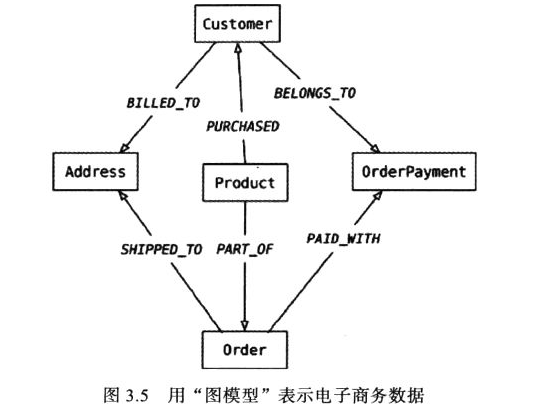
建模的通则是要便于查询,而且在写入数据时要对其“反规范化”(denormalize)操作
四、分布式模型
好处:
有些模型的数据存储能够处理大量数据
有些能够处理大量的网络读取或写入请求
还有些能够更好地应对网络速度慢或网络故障等状况
4.1单一服务器
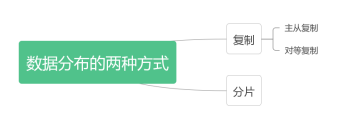
4.2分片
4.2.1定义
当不同用户需要访问数据集中的不同部分时,我们把数据的各个部分存放于不同的服务器中,以此实现横向扩展。该技术就叫分片
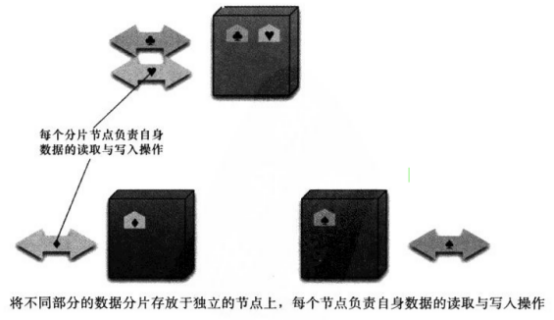
4.2.2性能改善:
把数据放得离访问者近一些
负载均衡。要把聚合数据均匀地分布在各个节点中,让他们需要处理的负载量相等。
4.2.3分片技术可能会降低数据库的错误恢复能力。
4.2.4单一节点向分片迁移
一开始就决定使用分片技术,则最好在开发伊始就将该数据库部署在集群上。
原来运行在单一服务器上的数据库要应用分片技术:最好是先使用一台服务器,等到现有服务能力已经明显无法应对负载量时,再改用分片。
4.3复制
4.3.1主从复制
定义
在“主从式分布”中,我们要把数据复制到多个节点上,其中一个节点叫做“主(master)节点”,存放权威数据,通常负责处理数据更新操作。其余节点都叫“从(slave)节点”。复制操作就是要让从节点与主节点同步。
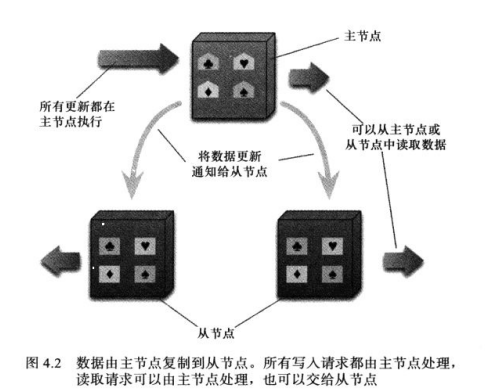
2.好处
在需要频繁读取数据集的情况下,“主从复制”最有助于提升数据访问性能了。
增强“读取操作的故障恢复能力”。拥有内容与主节点相同的从节点,在主节点出错后,可选举为新的主节点,可以提高数据库的恢复速度。(这个故障恢复能力,只有在)
指派新的主节点有两种
手动指派。
自动指派。集群可以自行指派新的主节点,减少停机时间。
3.复制的缺陷:数据的不一致性。
4.3.2 对等复制
“主从复制”减少了更新数据时的冲突几率,但它却会让主节点成为写入操作瓶颈,而“对等复制”则避免了这一点。
“对等复制”没有“主节点”这一概念,任何节点均可写入,节点间相互协调以同步其数据。
4.4技术结合使用
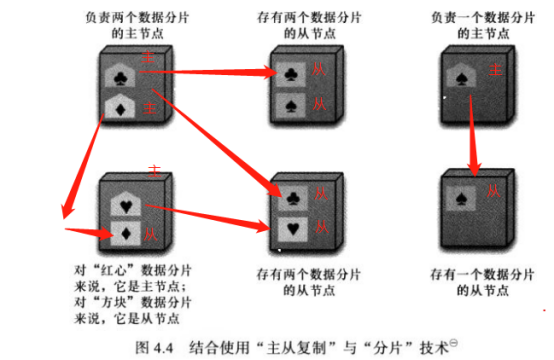
4.4.1主从+分片
意味着系统有多个主节点,对每片数据来说,负责它的主节点只有一个。根据配置需要,同一个节点既可以做某些数据的主节点,也可以充当其他数据的从节点。也可以指派全职的主节点或从节点。

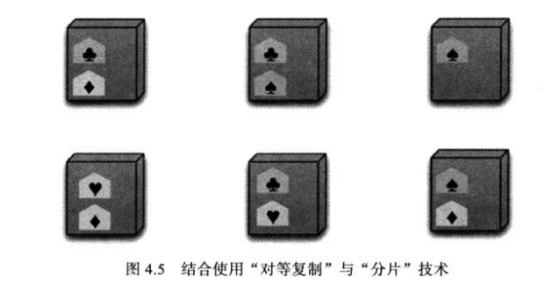
4.4.2对等+分片
数据可能分布于集群中的数十个或数百个节点上。在采用“对等复制”方案时,一开始可以用“3”作为复制因子,也就是把每个分片数据放在3个节点中,一单某个节点出错,那么它上面保存的哪些分片数据会由其他节点冲减
五、一致性
1. 更新一致性
写入冲突:当两个客户端试图同时修改一份数据时发生
处理“写冲突”
保持数据一致性的两种方式:悲观方式和乐观方式
(先决条件:更新操作的顺序必须一致。也就是所有节点都要保证以相同次序执行操作。)
悲观方式:避免发生冲突。采用“写入锁”,系统确保某一时刻只有一个客户能够获得这把锁。 此方式通常会大幅降低系统响应能力,还可能会导致“死锁”。
乐观方式:通常采用“条件更新”,也就是任意客户在执行更新操作之前,都要先测试数据的当前值和其上一次读入的值是否相同。
2. 读取一致性
读写冲突:当某客户端在另一个客户端执行写入操作的过程中读取数据发生的,可能出现“逻辑不一致性”问题。
*在执行影响多个聚合的更新操作时,会留下一段时间空挡,让客户端有可能在此刻读出逻辑不一致的数据。
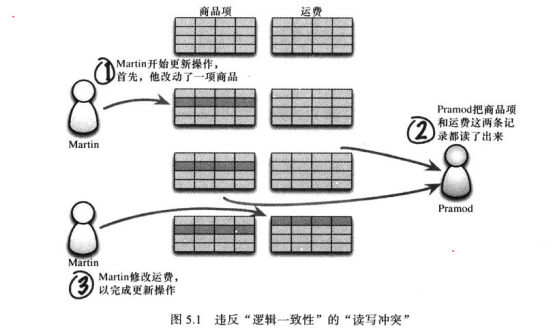
“不一致窗口”:存在不一致风险的时间长度。
另一种读取冲突:在“复制”机制中,违反“复制一致性”的“读取不一致”问题
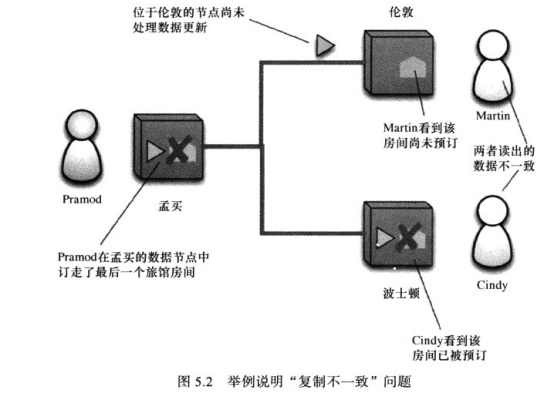
“复制一致性”:要求从不同副本中读取同一个数据项时,所得到的的值相同。
确保“照原样读出所写内容的一致性”:在执行完更新操作之后,紧接着必须能看到更新之后的值才行。在具备“最终一致性”的系统中,提供“会话一致性”可确保此性质。
确保“会话一致性”的方法
使用“黏性会话”,也就是绑定到某个节点的会话。它可以保证,只要某节点具备“照原样读出所写内容的一致性”,那么与之绑定的会话就都具备这种特性了。 缺点:会降低“负载均衡器”的效能
使用“版本戳”。并确保同数据库的每次交互操作中,都包含会话所见的最新版本戳。服务器节点在相应请求之前必须先保证,它所含有的更新数据包含此版本戳。
3.放宽“一致性”约束
“CAP定理”是需要放宽一致性约束的原因。
CAP定理的基本表述:给定“一致性”、“可用性”、“分区耐受性”这三个属性,我们只能同时满足其中两个属性。
“可用性”:如果客户可以同集群中的某个节点通信。那么该节点就必然能够处理读取及写入操作。~ 系统中某个无故障节点所接受的每一条请求,无论成功或失败,都必将得到相应。
“分区耐受性”:如果发生通信故障,导致整个集群被分割成多个无法互相通信的分区时,集群仍然可用。
集群必须要容忍“网络分区”状况,而这正是“CAP定理”的意义所在:当系统可能会遭遇“分区”状况时(比如分布式系统),我们需要在“一致性”与“可用性”之间进行权衡。通常,我们都会略微舍弃“一致性”,以获取某种程度的“可用性”。
4.放宽“持久性”约束
可以舍弃一部分“持久性”以减少延迟,如果想让数据库在复制数据出错的情况下依然可用,那么更应该考虑这种权衡方式。
5.仲裁
处理请求所用的节点越多,避免“不一致”问题的能力就越强。引出一个问题:要想保证“强一致性”,需要使用多少个节点才行?
写入仲裁:W > N/2 ,意思是,参与写入操作的节点数(W),必须超过副本节点数(N)的一般。副本个数又称为“复制因子”。
读取仲裁:执行读取操作时所需联系的节点数(R),确认写入操作时所需征询的节点数(W),以及复制因子(N). 当R+W>N时,才能保证读取操作的“强一致性”.
六、版本戳
定义
版本戳是一个字段,每当记录中的底层数据改变时,其值也随之改变。读取数据时可以记下版本戳,在写入数据之前,就可以先检查一下数据版本是否已经变了。
版本戳可用来检测并发冲突。读取并更新某份数据之后,可检测其版本戳,以确保在读取和写入之间操作,没有其他人更新过此数据。也有助于维护“会话一致性”
2.构建版本戳:
使用计数器。每当资源更新时,就把它的值加1.根据它的值很容易就能看出哪个版本比较新。需要服务器来生成该值,并且要有一个主节点来保证不同版本的计数器值不会重复。
创建GUID(一个值很大且保证唯一的随机数),可以将日期、硬件信息,以及其他一些随机出现的资源组合起来以构建此值。优点是,任何人都可以生成,不用担心重复。缺点是,数值比较大,而且无法通过直接比较来判断版本的新旧。
根据资源内容生成哈希码(hash)。好处是,哈希码的内容是确定的:只要资源数据相同,那么任何节点生成的“内容哈希码”都是一样的。缺点是,无法通过直接比较来看出版本新旧,而且比较冗长。
使用上一次更新时的时间戳(timestamp)。好处,可以直接通过比较其数值来确定版本先后。不需要由主节点来生成,可以由多台计算机生成,不过要保证计算机的时钟必须同步。有一个风险:精度过低则可能重复,并发量高的话毫秒的精度也不够。
复合版本戳。如:计数器+内容哈希码
3.最简单的版本戳:计数器
4.多节点中的版本戳:确保所有节点都有一份“版本戳记录”
5.数组式版本戳:
对等式NoSQL数据库系统 最长使用的一种版本戳形式。
它由一系列计数器组成,每个及数字都代表一个节点。用来检测不同节点之间是否发生了“相互冲突的更新操作”。假设有三个节点为:blue、green、black。 数组式版本戳为[ blue: 43 ,green: 54, black: 12 ]。
七、映射-化简模式
1.基本“映射-化简”
“映射-化简”是一种在集群上执行并发计算所用的模式
2. 执行过程:
“映射”,它是一个函数,其输入值是某个聚合,而输出值则是相应的键值对。映射操作每次只能读取一条记录,所以可在存放记录的节点上并发执行。

化简函数:可以接受多个关键字相同的映射操作输出值作为其输入参数,然后将它们简化为单一的输出值。每个“化简函数”只操作与单个键相关的映射结果。所以多个“化简函数”可以依据关键字执行并发化简。
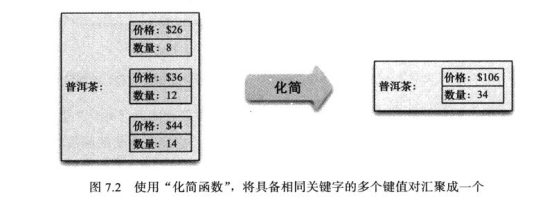
"映射函数"仅能操作于某个聚合内部的数据,而“化简函数”则可以操作所有具备同一关键字的数据。
3.分区与归并
为了提升“映射-化简”操作的并发能力并减少数据传输量
首先,将“映射函数”的输出数据分区,以提升并发处理能力。将映射结果发送给“化简函数”,并发执行多个化简函数。
输入数据与输出数据形式相同的多个“化简函数”可归并为“管道”,以提高并发执行能力,并减少所需传输的数据量。最后再把结果合并起来。
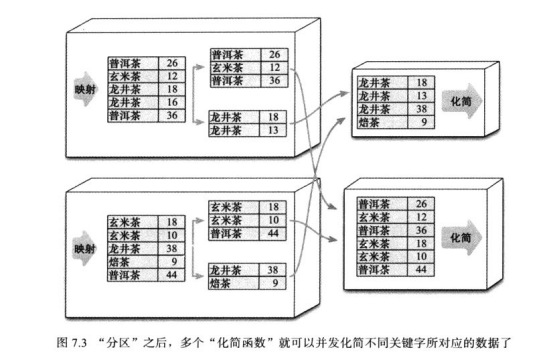
在进入化简阶段时,可以使用“归并函数”(可以把具备同一关键字的所有数据合并为一个值),减少传输的数据量。
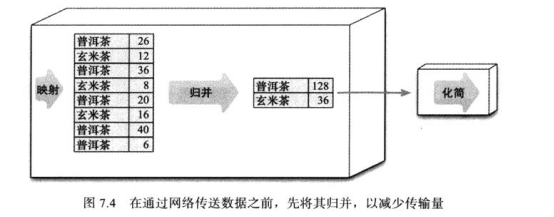
“归并函数”是“化简函数”的一种。
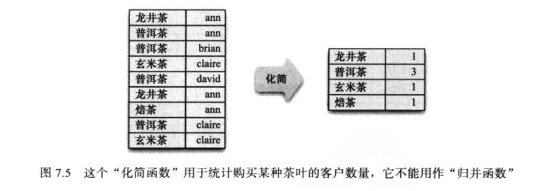
满足“输出值必须与输入值的形式相匹配”这个特性的“化简函数”,称为“可用作归并函数的化简函数”
并非所有“化简函数”都“可用作归并函数”,如下
4.组合“映射-化简”
若某个“化简操作”的输出是下一个“映射操作”的输入,那么就可以用“管道”组合“映射-化简操作”。
对计算结果的复用,既可以节省编码时间,也可以加快执行速度,但最好是有实际查询需要了再复用,不可凭空想象
如果需要广泛使用“映射-化简”计算的结果,那么可将其存储为“物化视图”。可用增量式“映射-化简”操作更新“物化视图”,这样只需计算视图中发生改变的那部分数据即可,不需要把全部数据都从头算一遍。
“映射-化简”模式可用任意编程语言实现。然而,受其风格所限,最好能使用一门转为“映射-化简”计算而设计的语言。如Hadoop项目的分值Apache Pig


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









