







这个本来在9月份就弄好了。太久了,已经忘了。所以晚上也闲着没事,反正通宵就想写着玩玩。发现好多已经忘了。等于又从头看一遍。
Solr全文搜索引擎,还是蛮实用的。很能提高查询的性能。而且在支持分词,这对于模糊查询有着极大的帮助。也不BB了。上代码。
1 . 搭建环境
MacBook pro 15款840
OS X 10.10.5
solr-5.2.1.tgz
apache-tomcat-8.0.26
2 . 解压压缩包
tar -zxf solr-5.2.1.tgz3 . 移动war包
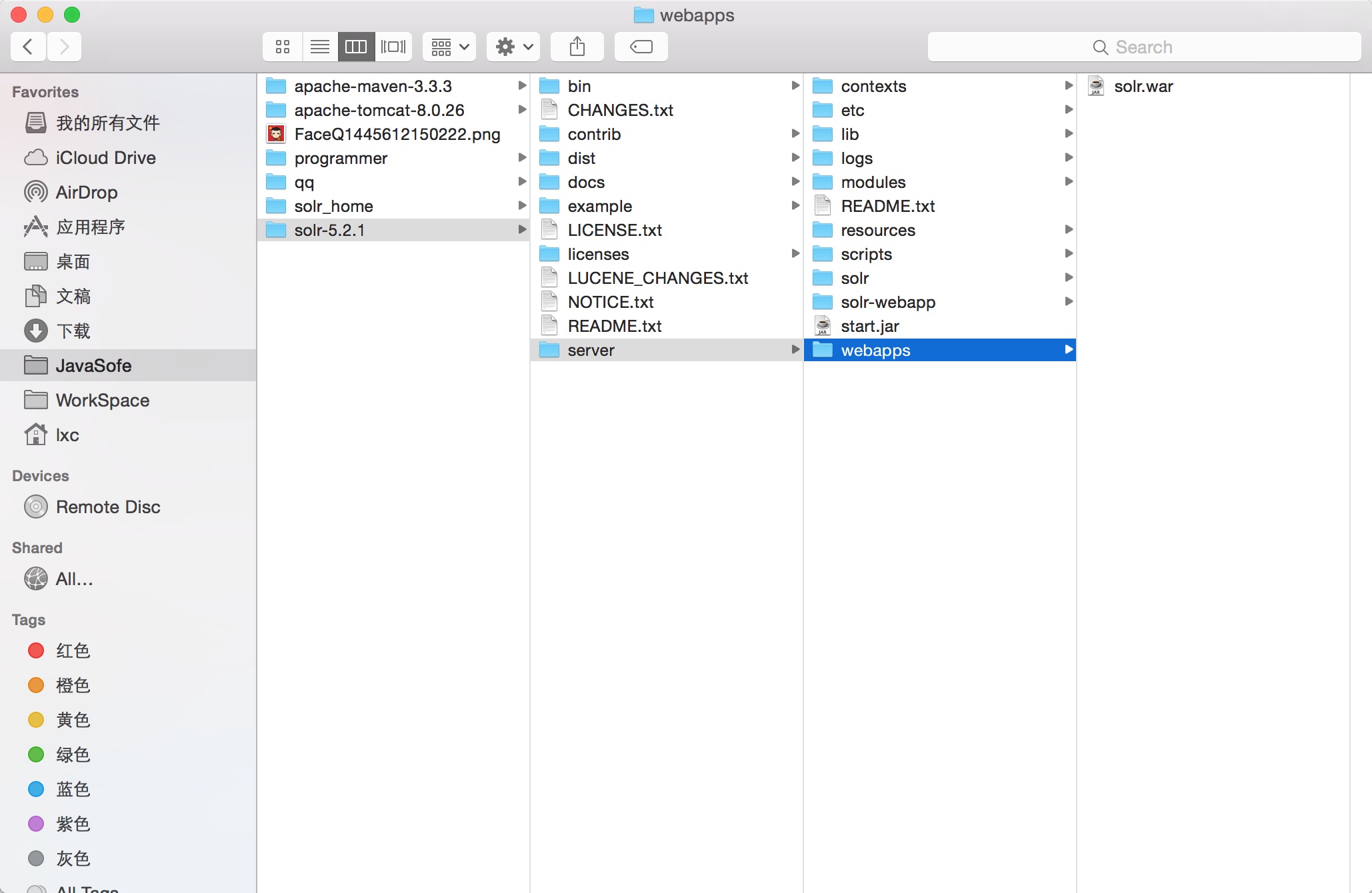
将这个war包,移动到 tomcat的webapps,然后启动或者解压war。
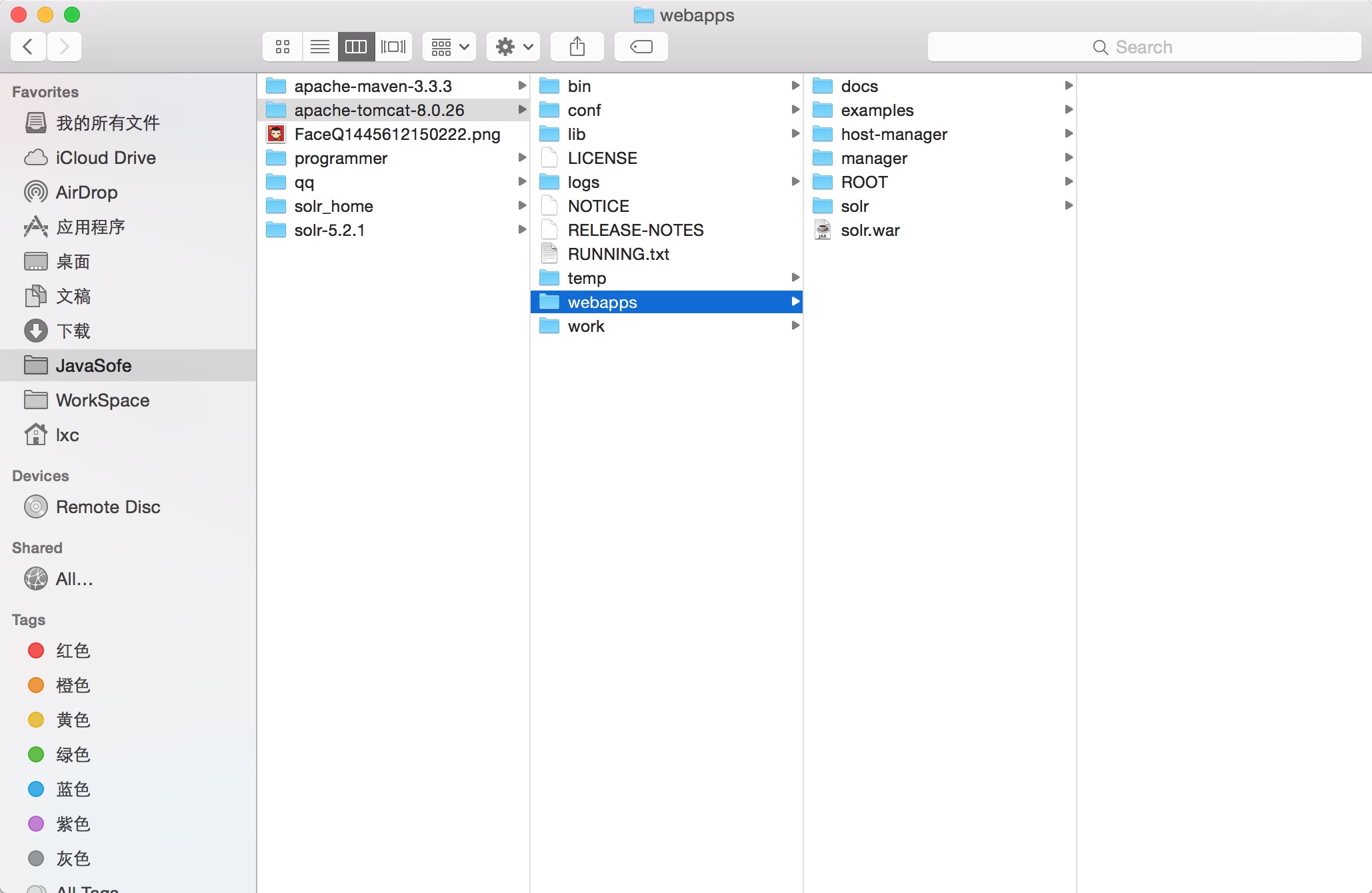
启动命令: 进入tomcat的bin下
./startup.sh4 .拷贝依赖需要的jar包
复制solr-5.2.1/dist/ solr-dataimporthandler-5.2.1.jar ,solr-dataimporthandler-extras-5.2.1.jar,solr-cell-5.2.1.jar,到tomcat中的solr/WEB-INF/lib下,将数据库驱动也需要放入这里。
复制solr-5.2.1\server\lib\ext下的jar包到solr/WEB-INF/lib下。这是打印日志所需要的jar包,然后在solr/WEB-INF 下新建classes文件夹 ,将solr-5.2.1/example/resources/log4j.properties 复制到 /usr/local/tomcat/webapps/solr/WEB-INF/classes/
这里使用smartcn作为中文分词组件,将solr-5.2.1/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-5.2.1.jar复制到tomcat/solr/WEB-INF/lib下
5 .创建Solr_Home
创建新的文件夹,solr_home,将solr-5.2.1/server/solr中的文件复制到/Users/lxc/JavaSofe/solr_home下。
6 .SOLR_HOME配置
将solr-5.2.1/server/solr中的文件复制到/Users/lxc/JavaSofe/solr_home下。
配置修改tomcat/webapps/solr/WEB-INF/web.xml
释放对这句话的注释。并且修改tomcat的server.xml
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/Users/lxc/JavaSofe/solr_home</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry> <Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
URLEncoding="UTF-8"/>7 .配置core目录
在solr_home下创建一个文件夹szss,并且复制solr-5.2.1/service/solr/configsets/basic_configs/conf 到 solr_home/szss下。
修改solrconfig.xml
修改solr_home/test/conf/solrconfig.xml
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>新建一个data-config.xml文件
<?xml version="1.0" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.microsoft.sqlserver.jdbc.SQLServerDriver"
url="jdbc:sqlserver://127.0.0.1:6372;databaseName=cs_szssapp"
user="sa"
password="szss" />
<document>
<entity name="solr_test" transformer="DateFormatTransformer"
query="select id,product_full_name,product_short_name,product_content,specification,taste_type,date_created,last_updated from product_b">
<field column='date_created' dateTimeFormat='yyyy-MM-dd HH:mm:ss' />
<field column='last_updated' dateTimeFormat='yyyy-MM-dd HH:mm:ss' />
</entity>
</document>
</dataConfig>8 .编辑schema.xml
<?xml version="1.0" encoding="UTF-8" ?>
//这个name要和你新建的solr_home文件下得那个文件名相同
<schema name="test" version="1.5">
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="_root_" type="string" indexed="true" stored="false"/>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
<dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="string" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_l" type="long" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="long" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_t" type="text_general" indexed="true" stored="true"/>
<dynamicField name="*_txt" type="text_general" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_en" type="text_en" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
<dynamicField name="*_bs" type="boolean" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_f" type="float" indexed="true" stored="true"/>
<dynamicField name="*_fs" type="float" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_d" type="double" indexed="true" stored="true"/>
<dynamicField name="*_ds" type="double" indexed="true" stored="true" multiValued="true"/>
<!-- Type used to index the lat and lon components for the "location" FieldType -->
<dynamicField name="*_coordinate" type="tdouble" indexed="true" stored="false" />
<dynamicField name="*_dt" type="date" indexed="true" stored="true"/>
<dynamicField name="*_dts" type="date" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_p" type="location" indexed="true" stored="true"/>
<!-- some trie-coded dynamic fields for faster range queries -->
<dynamicField name="*_ti" type="tint" indexed="true" stored="true"/>
<dynamicField name="*_tl" type="tlong" indexed="true" stored="true"/>
<dynamicField name="*_tf" type="tfloat" indexed="true" stored="true"/>
<dynamicField name="*_td" type="tdouble" indexed="true" stored="true"/>
<dynamicField name="*_tdt" type="tdate" indexed="true" stored="true"/>
<dynamicField name="*_c" type="currency" indexed="true" stored="true"/>
<dynamicField name="ignored_*" type="ignored" multiValued="true"/>
<dynamicField name="attr_*" type="text_general" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="random_*" type="random" />
<!-- uncomment the following to ignore any fields that don't already match an existing
field name or dynamic field, rather than reporting them as an error.
alternately, change the type="ignored" to some other type e.g. "text" if you want
unknown fields indexed and/or stored by default -->
<!--dynamicField name="*" type="ignored" multiValued="true" /-->
<!-- Field to use to determine and enforce document uniqueness.
Unless this field is marked with required="false", it will be a required field
-->
<uniqueKey>id</uniqueKey>
<fieldType name="text_cn" class="solr.TextField">
<analyzer type="index" class="org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer" />
<analyzer type="query" class="org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer" />
</fieldType>
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<!-- boolean type: "true" or "false" -->
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="tint" class="solr.TrieIntField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tfloat" class="solr.TrieFloatField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tlong" class="solr.TrieLongField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tdouble" class="solr.TrieDoubleField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
<!-- A Trie based date field for faster date range queries and date faceting. -->
<fieldType name="tdate" class="solr.TrieDateField" precisionStep="6" positionIncrementGap="0"/>
<!--Binary data type. The data should be sent/retrieved in as Base64 encoded Strings -->
<fieldType name="binary" class="solr.BinaryField"/>
<fieldType name="random" class="solr.RandomSortField" indexed="true" />
<!-- A text field that only splits on whitespace for exact matching of words -->
<fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_en_splitting" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Less flexible matching, but less false matches. Probably not ideal for product names,
but may be good for SKUs. Can insert dashes in the wrong place and still match. -->
<fieldType name="text_en_splitting_tight" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- this filter can remove any duplicate tokens that appear at the same position - sometimes
possible with WordDelimiterFilter in conjuncton with stemming. -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<!-- Just like text_general except it reverses the characters of
each token, to enable more efficient leading wildcard queries. -->
<fieldType name="text_general_rev" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory" withOriginal="true"
maxPosAsterisk="3" maxPosQuestion="2" maxFractionAsterisk="0.33"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- This is an example of using the KeywordTokenizer along
With various TokenFilterFactories to produce a sortable field
that does not include some properties of the source text
-->
<fieldType name="alphaOnlySort" class="solr.TextField" sortMissingLast="true" omitNorms="true">
<analyzer>
<!-- KeywordTokenizer does no actual tokenizing, so the entire
input string is preserved as a single token
-->
<tokenizer class="solr.KeywordTokenizerFactory"/>
<!-- The LowerCase TokenFilter does what you expect, which can be
when you want your sorting to be case insensitive
-->
<filter class="solr.LowerCaseFilterFactory" />
<!-- The TrimFilter removes any leading or trailing whitespace -->
<filter class="solr.TrimFilterFactory" />
<filter class="solr.PatternReplaceFilterFactory"
pattern="([^a-z])" replacement="" replace="all"
/>
</analyzer>
</fieldType>
<!-- lowercases the entire field value, keeping it as a single token. -->
<fieldType name="lowercase" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
<!-- since fields of this type are by default not stored or indexed,
any data added to them will be ignored outright. -->
<fieldType name="ignored" stored="false" indexed="false" multiValued="true" class="solr.StrField" />
<fieldType name="point" class="solr.PointType" dimension="2" subFieldSuffix="_d"/>
<!-- A specialized field for geospatial search. If indexed, this fieldType must not be multivalued. -->
<fieldType name="location" class="solr.LatLonType" subFieldSuffix="_coordinate"/>
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
geo="true" distErrPct="0.025" maxDistErr="0.001" distanceUnits="kilometers" />
<!-- Spatial rectangle (bounding box) field. It supports most spatial predicates, and has
special relevancy modes: score=overlapRatio|area|area2D (local-param to the query). DocValues is recommended for
relevancy. -->
<fieldType name="bbox" class="solr.BBoxField"
geo="true" distanceUnits="kilometers" numberType="_bbox_coord" />
<fieldType name="_bbox_coord" class="solr.TrieDoubleField" precisionStep="8" docValues="true" stored="false"/>
<fieldType name="currency" class="solr.CurrencyField" precisionStep="8" defaultCurrency="USD" currencyConfig="currency.xml" />
**<!-- general -->
<field name="product_full_name" type="text_cn" indexed="true" stored="true" />
<field name="product_short_name" type="text_cn" indexed="true" stored="true" />
<field name="product_content" type="text_cn" indexed="true" stored="true" />
<field name="specification" type="text_cn" indexed="true" stored="true" />
<field name="taste_type" type="text_cn" indexed="true" stored="true" />
<field name="date_created" type="date" indexed="true" stored="true" />
<field name="last_updated" type="date" indexed="true" stored="true" />
<defaultSearchField>product_full_name</defaultSearchField>
<solrQueryParser defaultOperator="OR"/>
</schema>**
主要加了查询的参数类型什么的。
9 .打开浏览器localhost:8080/solr
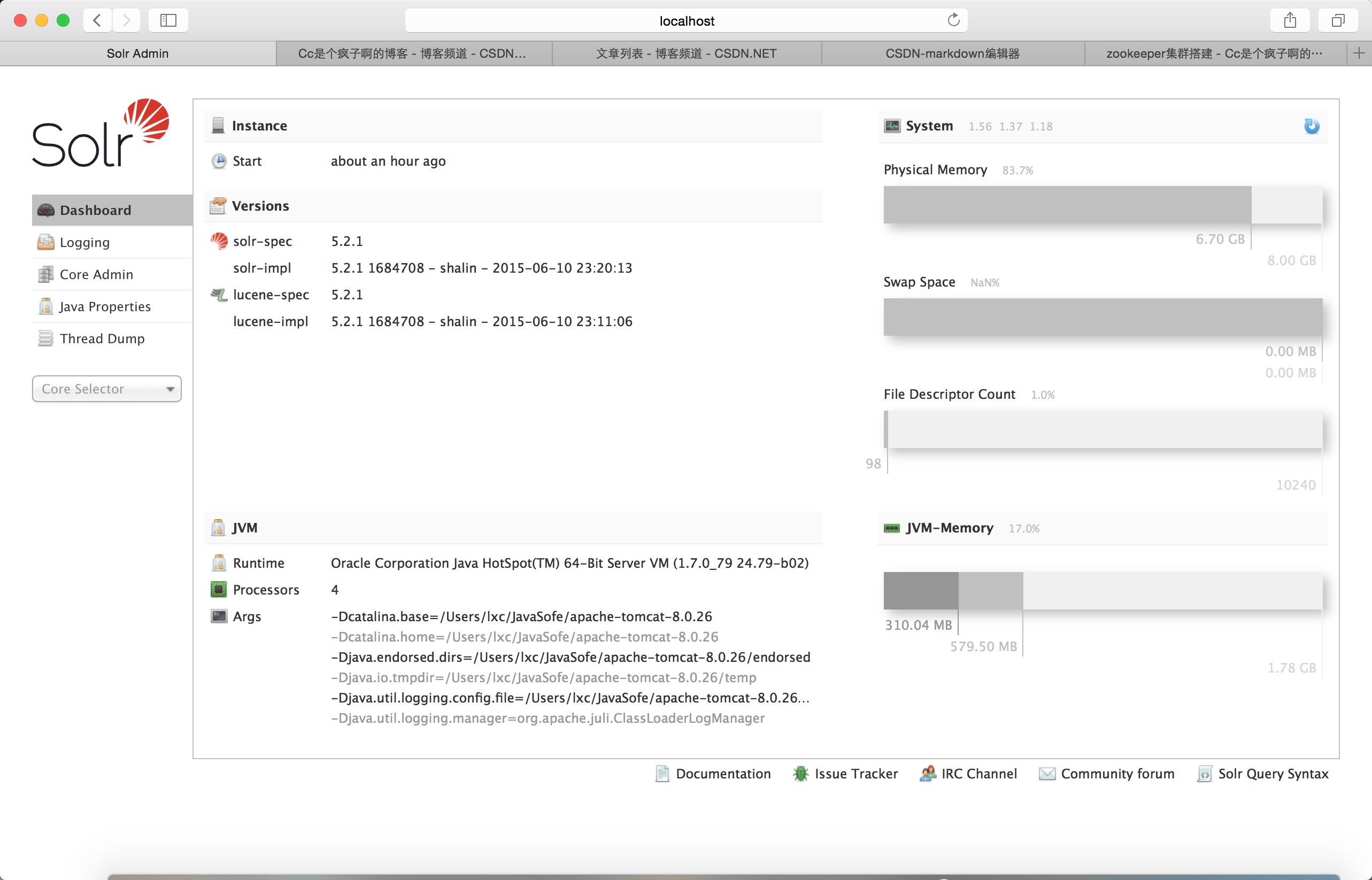
然后点击
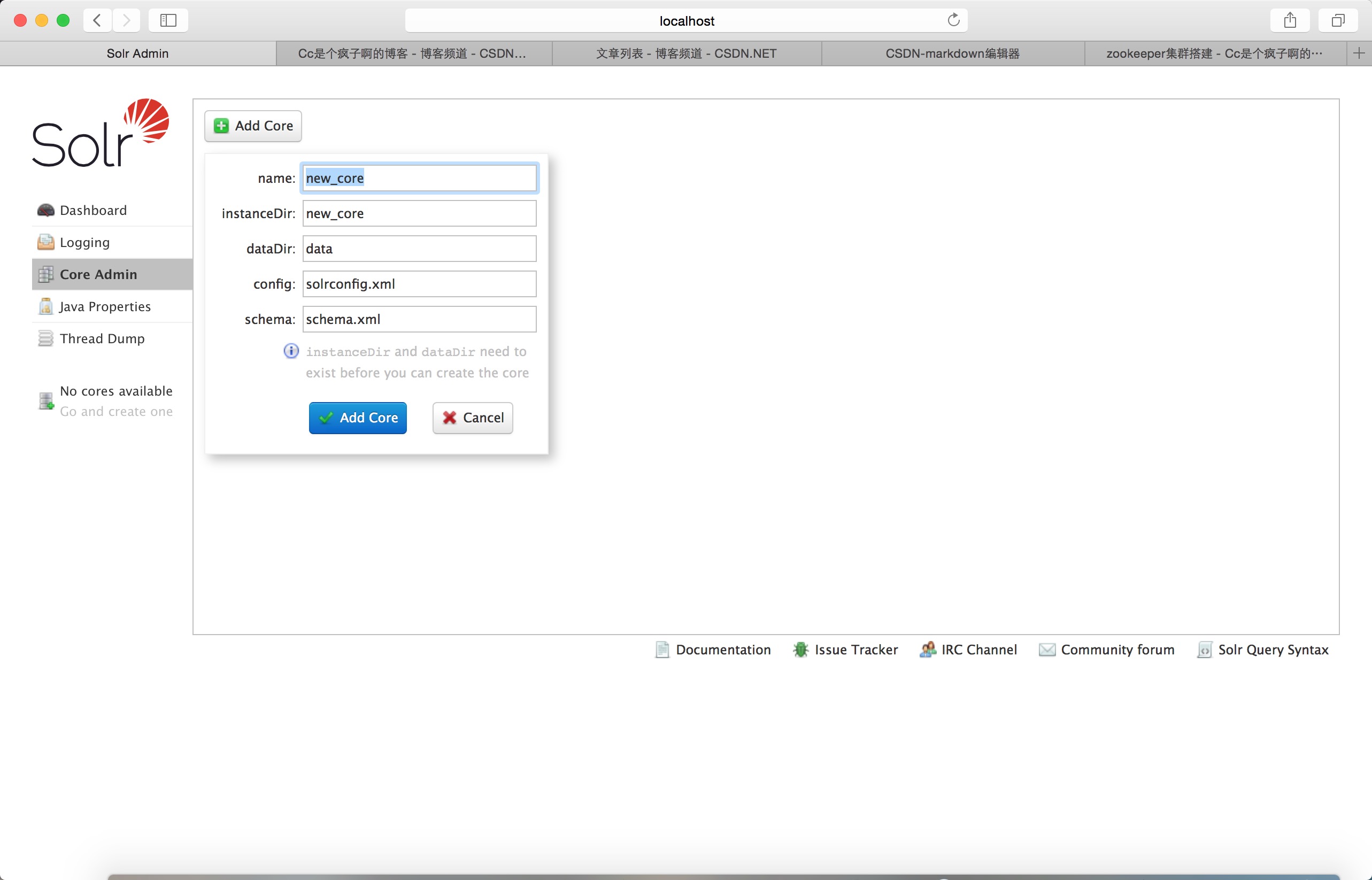
这个名字不能取成其他的 需要和你在solr_home下新建文件夹名相同。
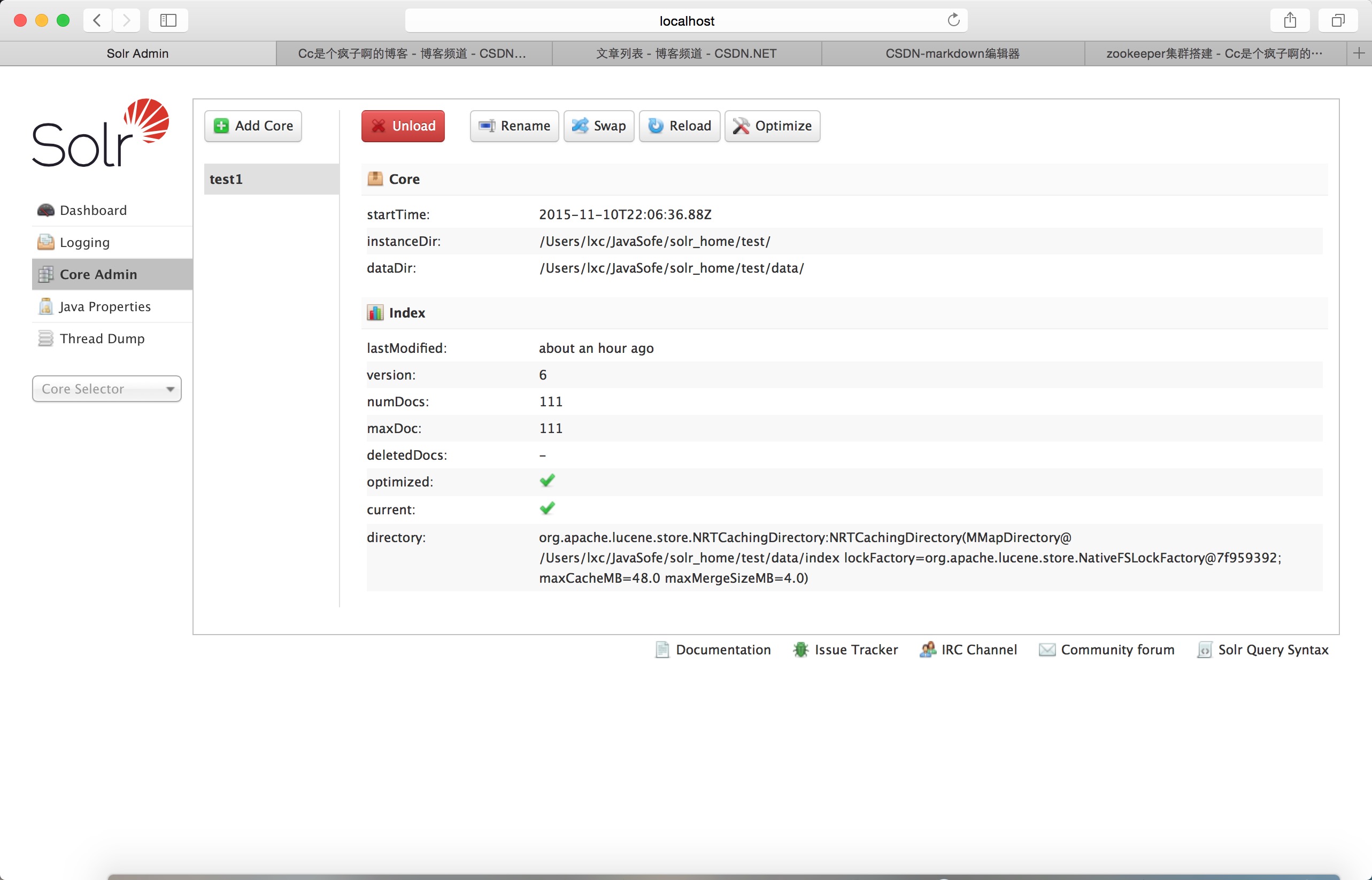
然后
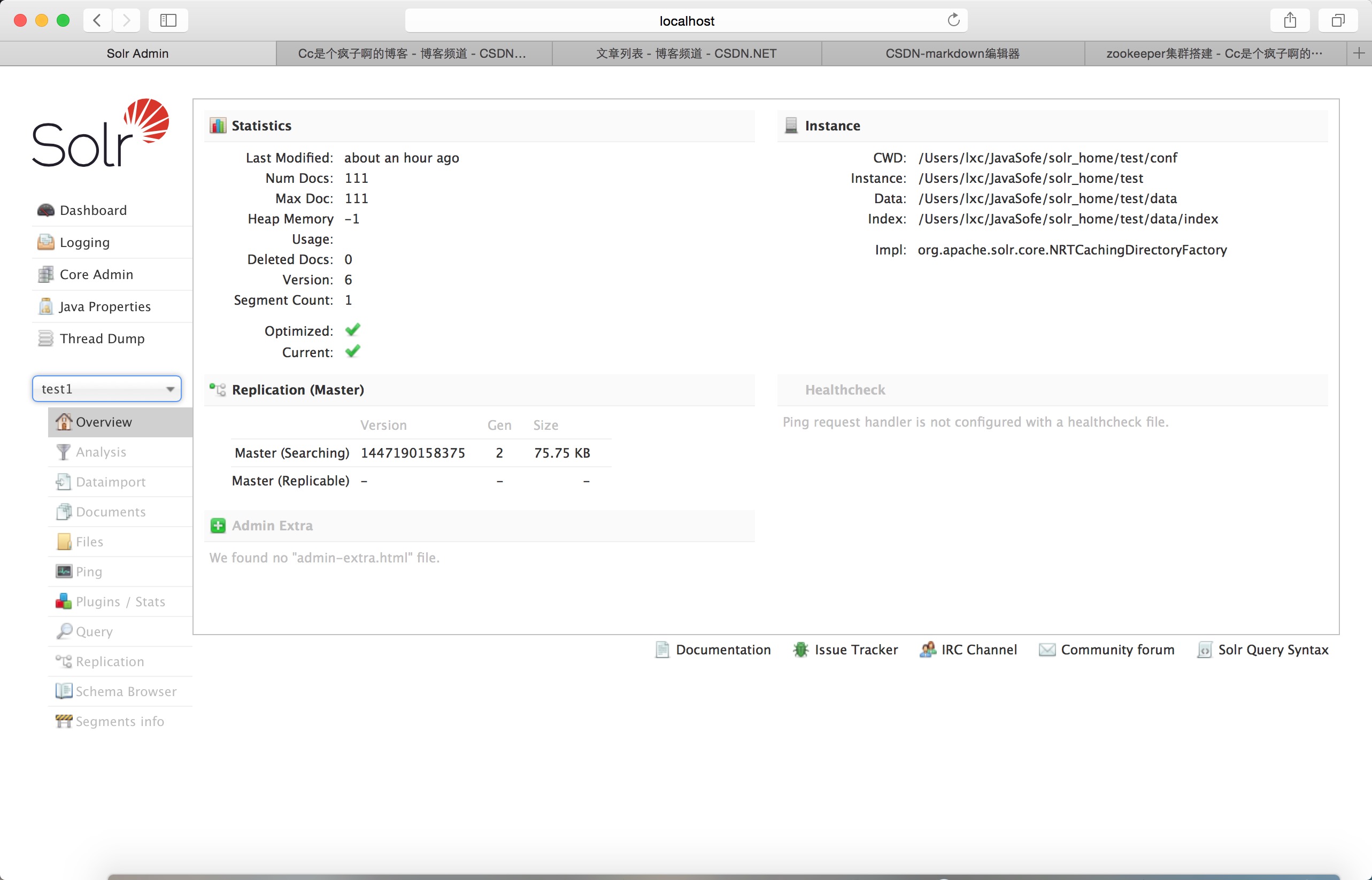
因为我之前新建过所以是test1
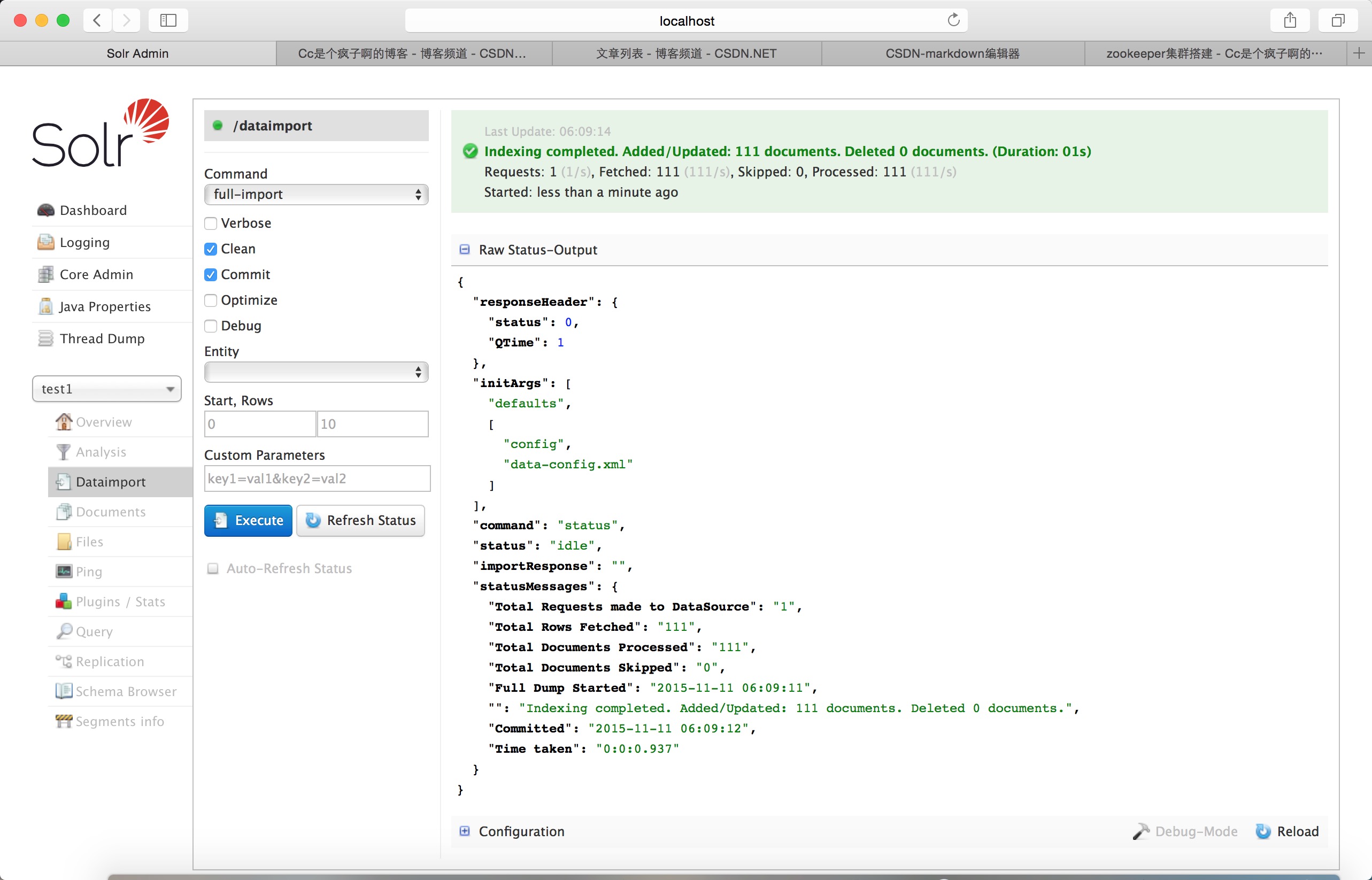
点击DataImport 引入数据 生成索引,
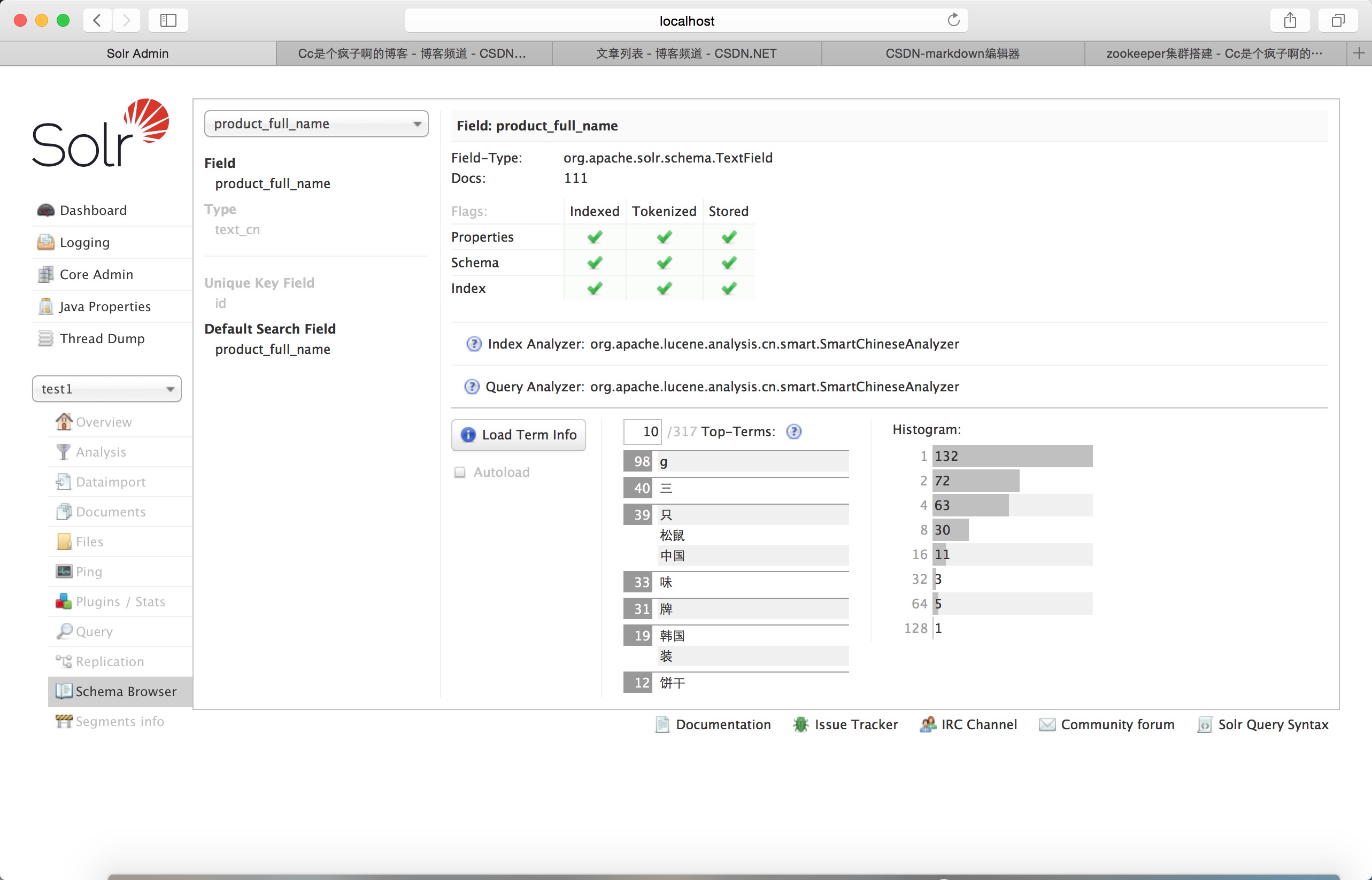
查询一个 试试
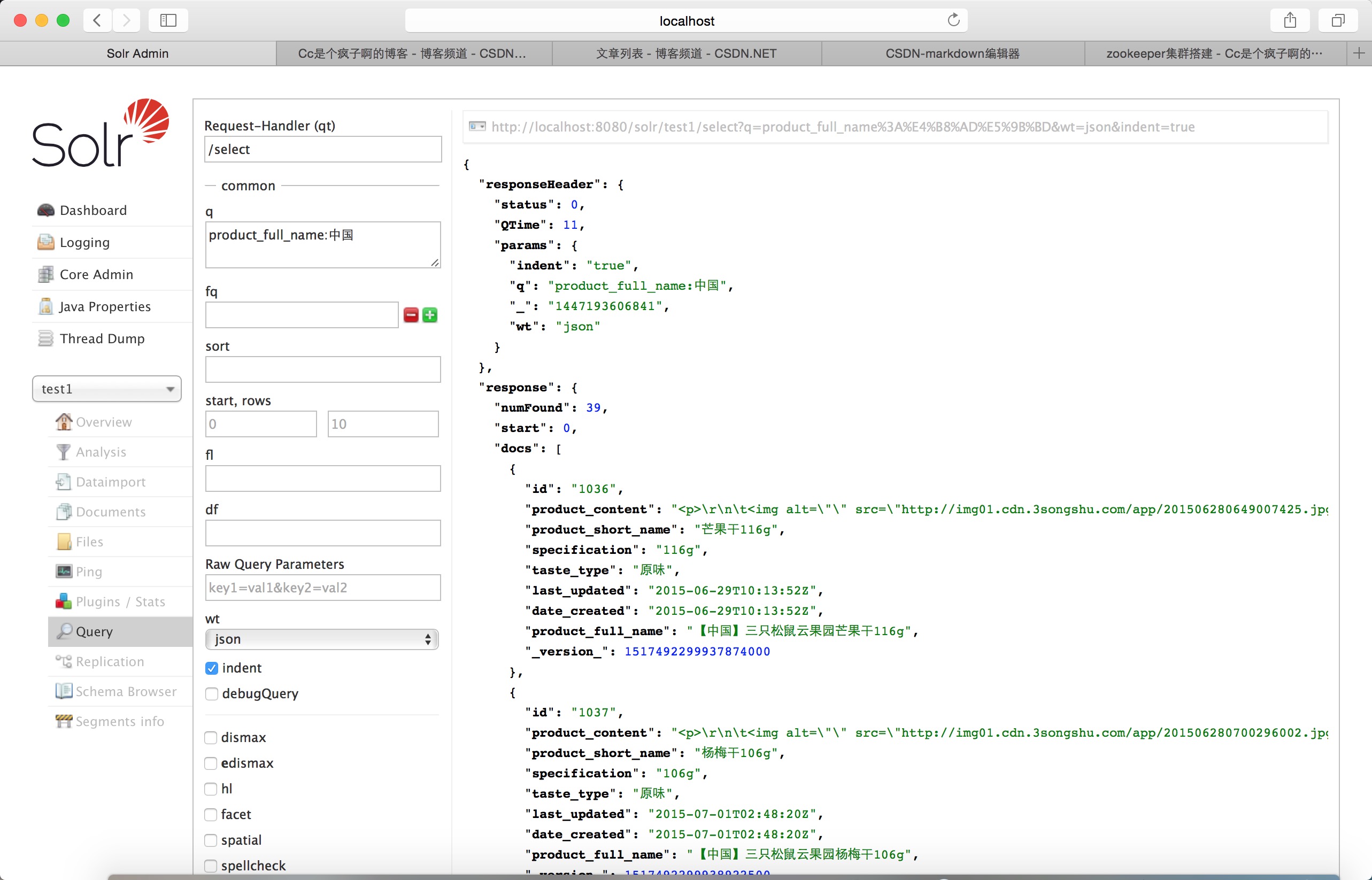
完毕。 肚子疼。等会回去休息了。 下午还是要回来。 双十一电商工作人员真是累成狗了。















 3713
3713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









