







背景介绍
前情提要: 在上一篇文章中,我介绍了配置 PaddleOCR 环境的方法,以及如何通过修改 PaddleOCR 源码,使用 PPOCR v3 模型为具有文本框标注的文本检测数据集(Text Detection Dataset)生成文本内容伪标签,得到伪文本提取数据集。
本文简介: 本文将继续上一篇文章的内容,介绍如何在前面工作的基础上,使用 PPOCRLabel 对生成的伪标签进行人工检查,以手动修改识别错误的部分。(若只是想参考 PPOCRLabel 如何使用,本文也将对你有所帮助!)具体将包含以下几部分内容:
- 将数据集标签格式转换为 MMOCR 格式。
- 将数据集分割到多个小文件夹中,并生成 PPOCRLabel 可以读取的伪标注文件。 数据集的标注将是一个非常耗费时间和体力的工作,PPOCRLabel 的使用并不算非常稳定,若对整个数据集进行标注,若出现软件问题导致前面标注内容的丢失将会让人非常难受,为了降低这一风险,我们首先将任务划分为多个小任务,最后再进行合并。
- 配置 PPOCRLabel 并对数据集进行手动检查。 这一部分将介绍如何处理 PPOCRLabel 的 Bug,以及如何快速上手使用 PPOCRLabel。
- 将标注好的内容合并到一起。 这一节将介绍如何将所有数据集的标注合并到一起,生成 MMOCR 格式的标签文件。
第一步:将数据集标签格式转换为 MMOCR 格式
不同的公开数据集具有不同的标签格式,为了便于对数据集进行统一处理,mmocr 约定了一个统一的数据格式。本节将提供一个脚本,用于将生成为文本提取数据集伪标签转化为 mmocr 标签格式,同时也可将上一节所说的文本检测数据集转化为 mmocr 格式。
为了让脚本代码和数据集分离,我们为 textRoot 创建一个兄弟目录 tools 以存放脚本代码,并创建一个 generate_mmocr_label.py 文件来写该步骤内容所需的脚本代码,创建后的目录结构如下:
- textRoot
- tools
- generate_mmocr_label.py
generate_mmocr_label.py 的内容如下,当 task_name = textspotting 则处理的是文本提取标签。
# 该脚本用于对 textRoot 数据集的文本检测标签进行预处理,转换为 mmocr 的 textdet 格式,以及 spotting 标签的预处理
# textdet 格式(4点框):
# 260,29,371,29,371,66,260,66,0,text
# textspotting 格式(n点框 |||| 文本):
# 260,29,371,29,371,66,260,66||||黄世德
import os
import json
import numpy as np
import cv2
# 数据集配置
dataset_root_path = '../textRoot' # 数据集根目录
task_name = 'textspotting' # 任务名称: textdet, textspotting
isTextSpotting = task_name == 'textspotting'
dataset_name = 'TextDet' if not isTextSpotting else 'TextSpotting'
# 分别处理训练集和测试集
phase = ['train', 'test']
for curPhase in phase:
# 开始处理标签
relative_img_path = f"images_{curPhase}"
relative_gt_path = f"label_{'spotting' if isTextSpotting else 'det'}_{curPhase}"
img_path = os.path.join(dataset_root_path, relative_img_path)
gt_path = os.path.join(dataset_root_path, relative_gt_path)
# 结果保存路径
transformed_gt_path = os.path.join(dataset_root_path, f'{task_name}_v1_{curPhase}.json')
# 获取图像名称列表
img_name_list = os.listdir(img_path)
# 用于存放转换后的数据
transformed_data_list = []
# 遍历所有的图像
for img_name in img_name_list:
# 读取图像信息
img = cv2.imread(os.path.join(img_path, img_name))
# 读取标签信息
gt_file_name = img_name.replace('.jpg', '.txt')
gt_file_path = os.path.join(gt_path, gt_file_name)
# 检查标签文件是否存在
instances = []
if os.path.exists(gt_file_path):
gt_lines = open(gt_file_path, 'r', encoding='utf-8').readlines()
for gt_line in gt_lines:
text = None
gt_line = gt_line.strip('\n\t')
if not isTextSpotting:
points = gt_line.split(',')[:8]
else:
tmpInstance = gt_line.split('||||')
points = tmpInstance[0].split(',')
text = tmpInstance[1]
npPoints = np.array(points, dtype=np.int32).reshape(-1, 2)
# 获取最小外接矩形
bbox = [np.min(npPoints[:, 0]), np.min(npPoints[:, 1]), np.max(npPoints[:, 0]), np.max(npPoints[:, 1])]
bbox = [int(x) for x in bbox]
points = [int(x) for x in points]
# 构建实例
item = {
"bbox_label": 0, # 表示文本,写死的
"bbox": bbox,
"polygon": points,
"ignore": False,
}
if isTextSpotting:
item["text"] = text
instances.append(item)
else:
print(f"path {gt_path} not exists, image {img_name} do not have gt, ignore it")
transformed_info = {
# "img_path": os.path.join(relative_img_path, img_name),
"img_path": relative_img_path + '/' + img_name,
"height": img.shape[0],
"width": img.shape[1],
"instances": instances
}
transformed_data_list.append(transformed_info)
# 构建最终的数据
transformed_gt = {
"metainfo": {
"dataset_type": f"{dataset_name}Dataset",
"task_name": task_name,
"category": [{"id": 0, "name": "text"}]
},
"data_list": transformed_data_list
}
# 保存最终的数据
json.dump(transformed_gt, open(transformed_gt_path, 'w', encoding='utf-8'), ensure_ascii=False)
处理完成后,textRoot 目录下将会出现两个 json 文件,目录结构变为
- textRoot
- textspotting_v1_train.json
- textspotting_v1_test.json
...
第二步:数据集细分到多个小文件夹中。
在上一节介绍到,我们数据集的根目录为 textRoot,目录下包含了训练集和测试集的图片以及生成的文本提取的伪标签。目录结构如下:
- textRoot
- images_train # 训练集图片文件夹
- xxx1.jpg
- xxx2.jpg
...
- label_spotting_train # 生成的文本提取标签文件夹
- xxx1.txt
- xxx2.txt
...
- images_test # 训练集图片文件夹
- yyy1.jpg
- yyy2.jpg
...
- label_spotting_test # 生成的文本提取标签文件夹
- yyy1.txt
- yyy2.txt
...
接下来,我们将把训练集和测试集分别进行划分,每 10 张图放在一个文件夹中,以便于使用 PPOCRLabel 进行标注。划分后的结果放在 textRoot\splited_images 里。
使用 PPOCRLabel 进行数据标注时,PPOCRLabel 将会把整个文件夹内的所有图片加载进去,标注结果将会放在文件夹下的名为 Label.txt 的文件夹中,为了能让 PPOCRLabel 读取我们生成的伪标签,所以还需要首先生成这个文件。转换后的目录结构如下:
- textRoot
- images_train # 训练集图片文件夹
- label_spotting_train # 生成的文本提取标签文件夹
- images_test # 训练集图片文件夹
- label_spotting_test # 生成的文本提取标签文件夹
- splited_images # 使用 PPOCRLabel 进行处理的根目录
- train # 训练集目录
- 1 # 第一个工作目录,每个目录 10 张图
- Label.txt # 该目录下所有图片的标签
- xxx1.jpg # 图片
- xxx2.jpg
...
- 2
...
- test # 与 train 目录同理
- 1
- 2
...
Label.txt 为 PPOCRLabel 格式的标签,该文件内,每一行表示一个图片的标注结果,格式为 图片路径\t[{"transcription": "xxxx", "points": [[x1,y1], [x2, y2], ...], "difficult": false}, ...],其中 transcription 表示该文本实例的标签,points 表示文本框,difficult 表示是否为困难样本 。以下为一个例子:
10/1408.jpg [{"transcription": "第九回", "points": [[21, 58], [107, 58], [107, 93], [21, 93]], "difficult": false}, {"transcription": "三箭贯雁双美逐鹿", "points": [[196, 300], [479, 300], [479, 360], [196, 360]], "difficult": false}, {"transcription": "全身运力一石化烟", "points": [[192, 361], [473, 361], [473, 417], [192, 417]], "difficult": false}]
10/1413.jpg [{"transcription": "时候,市场上节日的气复已经很明显了,面且随看时同的推移变得", "points": [[32, 16], [524, 16], [524, 35], [32, 35]], "difficult": false}, {"transcription": "愈来愈浓。小陈和霁月这次的分工与合作都如前两次相同,所不同", "points": [[32, 45], [529, 45], [529, 63], [32, 63]], "difficult": false}, {"transcription": "的是小陈临走时是这样说的:", "points": [[30, 74], [241, 74], [241, 90], [30, 90]], "difficult": false}, {"transcription": "\"你一个人留下来可千万要小心啊,我尽量快点回来。\"", "points": [[65, 102], [458, 102], [458, 118], [65, 118]], "difficult": false}, {"transcription": "霁月看看小陈无比担忧的神情,便十分感微地点了一下头,同", "points": [[63, 127], [529, 127], [529, 149], [63, 149]], "difficult": false}, {"transcription": "时也领略到了某种异样的情愫。为了让小陈放心,霁月很自信地说:", "points": [[31, 158], [527, 158], [527, 175], [31, 175]], "difficult": false}, {"transcription": "\"段同题,你快去吧,我会小心的。\"然后就转身没然决然地向市场", "points": [[31, 186], [531, 186], [531, 204], [31, 204]], "difficult": false}, {"transcription": "头走去。霁月刚刚走了过去,就看见李四推看自行车吃喝着走了过", "points": [[31, 215], [529, 215], [529, 236], [31, 236]], "difficult": false}, {"transcription": "来,霁月知道刚才在掉位上检疫的时候李四的摊位是空的,这头猪", "points": [[31, 244], [533, 244], [533, 262], [31, 262]], "difficult": false}, {"transcription": "良该是他今天上市的第一头。吸取了上次的检验教训,霁月没给他", "points": [[29, 273], [533, 273], [533, 292], [29, 292]], "difficult": false}, {"transcription": "提前检疫,想等他把店内放在摊位上以后再给他检。于是就一路跟", "points": [[29, 302], [537, 302], [537, 321], [29, 321]], "difficult": false}, {"transcription": "值走了回来。其实李四早就发现了霁月、那双淫亵的眼晴已经不知", "points": [[29, 332], [535, 332], [535, 349], [29, 349]], "difficult": false}, {"transcription": "道在霁月的身上扫荡多少回了。等他放好了猪肉,霁月就拿起检疫", "points": [[27, 361], [535, 361], [535, 380], [27, 380]], "difficult": false}, {"transcription": "刀按照检疫程序,给他的猪肉进行检查。细心的霁月没有动刀检验", "points": [[27, 390], [536, 390], [536, 410], [27, 410]], "difficult": false}, {"transcription": "之前,就明显地感觉到他今天的猪肉外观有些异常。前则和后丘都", "points": [[26, 419], [537, 419], [537, 441], [26, 441]], "difficult": false}, {"transcription": "有被刮过的迹象,一检,果然不出所料,这是一头息有囊虫病的", "points": [[27, 452], [538, 452], [538, 470], [27, 470]], "difficult": false}]
10/1418.jpg [{"transcription": "暗算", "points": [[254, 212], [327, 212], [327, 240], [254, 240]], "difficult": false}, {"transcription": "下午上班以后,站长又来到了市场。一进屋就对霁月和小陈说:", "points": [[75, 302], [543, 302], [543, 320], [75, 320]], "difficult": false}, {"transcription": "\"你们猜上午关大海那头是怎么盖上的章?一起先我还以为是他偷", "points": [[40, 334], [548, 334], [548, 353], [40, 353]], "difficult": false}, {"transcription": "了霁月上次丢的那个检疫章自己盖的呢,结果经过我和工商所同志", "points": [[40, 363], [548, 363], [548, 381], [40, 381]], "difficult": false}, {"transcription": "的反复审问,他才说出了事情的真相,原来他是用这头猪肉的肉皮,", "points": [[40, 393], [546, 393], [546, 411], [40, 411]], "difficult": false}, {"transcription": "在霁月给他检的第一头猪肉的肉皮上的检疫章粘了一下,这样这头", "points": [[40, 424], [546, 424], [546, 442], [40, 442]], "difficult": false}, {"transcription": "老母的肉皮上也就印上了检疫章的痕迹,所以这头老母猪也就像", "points": [[41, 455], [547, 455], [547, 474], [41, 474]], "difficult": false}]
10/142.jpg [{"transcription": "一卡通有效期延期", "points": [[60, 193], [240, 193], [240, 217], [60, 217]], "difficult": false}, {"transcription": "教职工校园卡首次办卡后的有效期为3年,到期后请您持本", "points": [[101, 238], [551, 238], [551, 264], [101, 264]], "difficult": false}, {"transcription": "人有效证件和卡到卡务部办理延期,每次延长3年。", "points": [[65, 269], [459, 269], [459, 294], [65, 294]], "difficult": false}, {"transcription": "一卡通在线查询", "points": [[68, 336], [221, 336], [221, 360], [68, 360]], "difficult": false}, {"transcription": "请访问信息门户http://portal.uestc.edu.cn,通过统一", "points": [[104, 381], [550, 381], [550, 404], [104, 404]], "difficult": false}, {"transcription": "身份认证的账号和密码登录,选择“一卡通进入查询界面。", "points": [[66, 410], [546, 410], [546, 439], [66, 439]], "difficult": false}]
10/1423.jpg [{"transcription": "夜袭", "points": [[257, 240], [328, 240], [328, 265], [257, 265]], "difficult": false}, {"transcription": "看完了电影往家走的路上,李刚故意和她挨得很近。霁月心里", "points": [[70, 326], [541, 326], [541, 347], [70, 347]], "difficult": false}, {"transcription": "明白,他这是想找机会和她说说话。霁月只管低头走看,并没有理", "points": [[40, 358], [546, 358], [546, 376], [40, 376]], "difficult": false}, {"transcription": "他的意思。就在他们沉默不语只顾赶路的时候,忽然问霁月感到从", "points": [[40, 388], [545, 388], [545, 409], [40, 409]], "difficult": false}, {"transcription": "后面迅速地冲上来了一个人,照着李刚就狠狠地轮了一拿,嘴里", "points": [[37, 416], [548, 416], [548, 436], [37, 436]], "difficult": false}, {"transcription": "还说:", "points": [[40, 448], [83, 448], [83, 469], [40, 469]], "difficult": false}]
10/1428.jpg [{"transcription": "特别地害怕,真希望哥哥能够早点出现。她一边心惊胆战地往前走", "points": [[45, 68], [535, 68], [535, 89], [45, 89]], "difficult": false}, {"transcription": "一边想:那该死的李四千万别知道我来看电影、但愿他别再报复我", "points": [[45, 97], [537, 97], [537, 118], [45, 118]], "difficult": false}, {"transcription": "了。哥哥怎么还不来呀?莫非妈妈忘记告诉他了,要不就是加班?", "points": [[46, 125], [536, 125], [536, 145], [46, 145]], "difficult": false}, {"transcription": "哥哥加班妈妈也应该让爸爸来接我啊……", "points": [[45, 155], [346, 155], [346, 177], [45, 177]], "difficult": false}, {"transcription": "正在她胡思乱想的时候,就听到身后响起一阵若有若无的脚步", "points": [[75, 184], [538, 184], [538, 203], [75, 203]], "difficult": false}, {"transcription": "声。她屏住呼吸凝神细听、脚步声教来越近。她惊恐地向后看了一", "points": [[42, 212], [540, 212], [540, 232], [42, 232]], "difficult": false}, {"transcription": "眼,朦胧之中就见一个人影跟在自己的后边,凭知觉霁月知道这个", "points": [[44, 241], [540, 241], [540, 260], [44, 260]], "difficult": false}, {"transcription": "人不是哥哥,也不是小陈。于是她赶紧加快了脚步,身后那人也跟", "points": [[42, 270], [544, 270], [544, 290], [42, 290]], "difficult": false}, {"transcription": "着加快了脚步。霁月的心都快院出嗓子眼了,她什么也顾不得了,", "points": [[42, 299], [544, 299], [544, 319], [42, 319]], "difficult": false}, {"transcription": "撒腿就跑。她想,这是从电影院回家的时候最偏僻最黑暗的一段路,", "points": [[43, 329], [543, 329], [543, 348], [43, 348]], "difficult": false}, {"transcription": "只要我跑出了这段路,有了路灯就不怕了。", "points": [[42, 360], [353, 360], [353, 379], [42, 379]], "difficult": false}, {"transcription": "让她万万没有想到的是,她刚跑了几步就被身后的那个人追上", "points": [[76, 388], [544, 388], [544, 407], [76, 407]], "difficult": false}, {"transcription": "了。那人上前一步跃到霁月的前边、伸开双手便栏住了她的去路,", "points": [[41, 419], [546, 419], [546, 436], [41, 436]], "difficult": false}, {"transcription": "趁他一楞,就一把将她抱住。“你要干什么?快放开我!”霁月拼命", "points": [[41, 447], [549, 447], [549, 468], [41, 468]], "difficult": false}]
10/1433.jpg [{"transcription": "说:“别生那么大的气好吗?今天我找你是正式向你求婚的。既然咱", "points": [[32, 66], [522, 66], [522, 90], [32, 90]], "difficult": true}, {"transcription": "俩都已经那样了,你就嫁给我算了,其实我是真心喜欢你的。你如", "points": [[29, 96], [523, 96], [523, 117], [29, 117]], "difficult": false}, {"transcription": "果同意,明天我就请媒人到你家求亲……\"看着他那厚颜无耻的样", "points": [[29, 123], [524, 123], [524, 144], [29, 144]], "difficult": false}, {"transcription": "子,霁月又不由得息起那个鬼魅一般的夜晚,一想到他凌辱自己的", "points": [[31, 152], [525, 152], [525, 176], [31, 176]], "difficult": false}, {"transcription": "那些丑恶行径,她真恨不得上前一把抓住他把他碎户万段。她强忍", "points": [[30, 181], [525, 181], [525, 203], [30, 203]], "difficult": false}, {"transcription": "住心中地怒火,大声地说:“住嘴!你别白日做了,我还是那句", "points": [[29, 211], [526, 211], [526, 230], [29, 230]], "difficult": false}, {"transcription": "话,我就是死了也不会嫁给你的,快让开,否则我去报警了!我", "points": [[29, 240], [527, 240], [527, 261], [29, 261]], "difficult": false}, {"transcription": "说你这人怎么这么死心眼呀,你想想啊,你已经不是处女了,以后", "points": [[27, 271], [528, 271], [528, 289], [27, 289]], "difficult": false}, {"transcription": "你再嫁给谁谁会喜欢你呀,还不如干脆嫁给我算了、我保证一辈子", "points": [[27, 300], [530, 300], [530, 321], [27, 321]], "difficult": false}, {"transcription": "都会爱你对你好的不知道为什么,霁月一听他说自己已经不是处", "points": [[26, 331], [533, 331], [533, 350], [26, 350]], "difficult": false}, {"transcription": "女了这话,顿时泪如雨下。是明,贞操是一个女孩家多么宝贵的东", "points": [[26, 359], [534, 359], [534, 380], [26, 380]], "difficult": false}, {"transcription": "西,意然就这样经导地被眼前这个恶棍毁于一旦,可她却只能忍气", "points": [[24, 388], [530, 388], [530, 407], [24, 407]], "difficult": false}, {"transcription": "吞声,这怎能不让她心疼万分呢,此时的雾月直被他气得脸色煞白", "points": [[25, 418], [531, 418], [531, 438], [25, 438]], "difficult": false}, {"transcription": "嘴唇颤抖,眼前一黑险些我倒在地上。她极力地稳住了自己的身体,", "points": [[25, 448], [535, 448], [535, 470], [25, 470]], "difficult": false}]
10/1438.jpg [{"transcription": "倾诉", "points": [[205, 85], [264, 85], [264, 106], [205, 106]], "difficult": false}, {"transcription": "一位非常优秀的爱尔兰作家给一群初涉文坛的作家开了个写", "points": [[62, 186], [443, 186], [443, 206], [62, 206]], "difficult": false}, {"transcription": "作研习讲座,是女作家。他是这行的翘楚之一。翘楚共有十二", "points": [[32, 216], [443, 216], [443, 236], [32, 236]], "difficult": false}, {"transcription": "位。M心包、幸运的是,十二位中有四位是女性:面不幸的是", "points": [[30, 244], [442, 244], [442, 266], [30, 266]], "difficult": false}, {"transcription": "(因为当时她认为决定事态的仅仅是运气,毫无计谋可言),没人", "points": [[26, 274], [441, 274], [441, 294], [26, 294]], "difficult": false}, {"transcription": "知道十二位中有四位是女性。她为自己能与这位作家共处一室而", "points": [[29, 303], [444, 303], [444, 321], [29, 321]], "difficult": false}, {"transcription": "高兴,并非因为觉得自己真能从他那里学到点儿什么。倒不是说", "points": [[28, 334], [445, 334], [445, 351], [28, 351]], "difficult": false}, {"transcription": "此人没啥可传授的,面是因为她并不想从他的所知中有所收获。", "points": [[28, 361], [446, 361], [446, 383], [28, 383]], "difficult": false}, {"transcription": "她在写作上算是半路出家,目的是想从更高处看到更好的风景,", "points": [[27, 391], [447, 391], [447, 412], [27, 412]], "difficult": false}, {"transcription": "不过她还是很开心,因为他真的在对她们发言,尽管关系遥远,", "points": [[28, 420], [447, 420], [447, 442], [28, 442]], "difficult": false}, {"transcription": "并不针对始个人,面且他的谦卑令地大为惊讶。", "points": [[25, 455], [328, 455], [328, 471], [25, 471]], "difficult": false}]
10/1443.jpg [{"transcription": "人都自有喜好。我遇到了一个特别的姑娘,是一位爱尔兰女子。", "points": [[20, 7], [525, 7], [525, 34], [20, 34]], "difficult": false}, {"transcription": "其实我更偏好外国女人,可世事难料。她是一位救援人员,当时", "points": [[19, 45], [525, 45], [525, 70], [19, 70]], "difficult": false}, {"transcription": "正在休假。她像所有从事救援工作的人一样,尽情享受着假期,", "points": [[19, 78], [527, 78], [527, 102], [19, 102]], "difficult": false}, {"transcription": "显然,越是经历过恐惧,就越能纵情畅饮。我迷上了她。她的身", "points": [[20, 116], [524, 116], [524, 141], [20, 141]], "difficult": false}, {"transcription": "材、举止、科克郡口音、蓬松的头发,全都十分迷人。她说她也", "points": [[21, 153], [527, 153], [527, 174], [21, 174]], "difficult": false}, {"transcription": "爱上了我。可是在我们第四次约会时,她甩了我,说我太严肃", "points": [[20, 187], [524, 187], [524, 212], [20, 212]], "difficult": false}, {"transcription": "了,没啥乐趣。我认为她更喜次奔波在旅途中,而不是到达目的", "points": [[21, 225], [527, 225], [527, 247], [21, 247]], "difficult": false}, {"transcription": "地。我把这话告诉了她,她说:“你懂我的意思了吗?”", "points": [[17, 262], [440, 262], [440, 281], [17, 281]], "difficult": false}, {"transcription": "不知这女人对我做了什么,此后我和其他人相处起来就不", "points": [[57, 299], [524, 299], [524, 317], [57, 317]], "difficult": false}, {"transcription": "同了。也许我变得优柔寡断,也许别人从我身上感到了恐惧和挫", "points": [[21, 333], [525, 333], [525, 355], [21, 355]], "difficult": false}, {"transcription": "败,我也不知道,总之我一定有了变化。一定是运气变了,因为", "points": [[20, 369], [523, 369], [523, 389], [20, 389]], "difficult": false}, {"transcription": "我还是同样的举止仪态,外表也没变。我越挫越败,每况愈下。", "points": [[21, 406], [523, 406], [523, 426], [21, 426]], "difficult": false}, {"transcription": "尽管我愈发理智清醒,却还是倾听电台里的情歌,想由此获得点", "points": [[23, 439], [526, 439], [526, 461], [23, 461]], "difficult": false}]
10/1448.jpg [{"transcription": "“比不上诺拉·丁金。”", "points": [[44, 16], [218, 16], [218, 42], [44, 42]], "difficult": false}, {"transcription": "“你什么意思,比不上诺拉·丁金,谁是诺拉·丁金?", "points": [[44, 48], [464, 48], [464, 77], [44, 77]], "difficult": false}, {"transcription": "“哦,只是我当年学校的女同学。她可厉害了,不光让男人", "points": [[44, 83], [514, 83], [514, 112], [44, 112]], "difficult": false}, {"transcription": "只是亲吻、所以,如果有人问起前一天晚上在舞会上表现如何,", "points": [[12, 122], [512, 122], [512, 147], [12, 147]], "difficult": false}, {"transcription": "大伙儿就常说‘比不上诺拉·丁金。", "points": [[10, 161], [304, 161], [304, 182], [10, 182]], "difficult": false}, {"transcription": "“那个学校在哪里?", "points": [[47, 195], [199, 195], [199, 219], [47, 219]], "difficult": false}, {"transcription": "“奥法利邵的。”", "points": [[46, 233], [163, 233], [163, 254], [46, 254]], "difficult": false}, {"transcription": "“奥法利,奥法利的哪里?”", "points": [[46, 269], [255, 269], [255, 289], [46, 289]], "difficult": false}, {"transcription": "“比尔,奥法利的比尔。”", "points": [[48, 305], [236, 305], [236, 326], [48, 326]], "difficult": false}, {"transcription": "“真的啊,老天,果然。”", "points": [[48, 340], [236, 340], [236, 361], [48, 361]], "difficult": false}, {"transcription": "“真的,确实如此。”", "points": [[49, 374], [204, 374], [204, 396], [49, 396]], "difficult": false}, {"transcription": "“那诺拉·丁金现在在哪里,你知道吗?”", "points": [[50, 408], [362, 408], [362, 429], [50, 429]], "difficult": false}, {"transcription": "“哦,她在都柏林嫁人了,一般都这样。”", "points": [[54, 444], [359, 444], [359, 466], [54, 466]], "difficult": false}]
在 tools 目录下创建一个 split_dataset.py 文件来写该步骤内容所需的脚本代码,创建后的目录结构如下:
- textRoot
- tools
- split_dataset.py
...
split_dataset.py 的内容如下
import os
import cv2
import json
import numpy as np
# 基本配置
dataset_root_path = '../textRoot' # 数据集根目录
img_per_dir = 10 # 每个子目录中的图像数量
# 创建输出目录
output_dir_root = os.path.join(dataset_root_path, 'splited_images')
if not os.path.exists(output_dir_root):
os.mkdir(output_dir_root)
# 分别处理训练集和测试集
phase = ['test', 'train']
for curPhase in phase:
img_path = os.path.join(dataset_root_path, f'images_{curPhase}')
img_name_list = os.listdir(img_path)
img_name_list.sort()
# 读取 spotting 标签
spotting_label_path = os.path.join(dataset_root_path, f'textspotting_v1_{curPhase}.json')
hasSpottingLabel = os.path.exists(spotting_label_path)
img_to_label = {}
if hasSpottingLabel:
with open(spotting_label_path, 'r', encoding='utf-8') as f:
spotting_label = json.load(f)
labels = spotting_label['data_list']
for labelItem in labels:
img_name = labelItem['img_path'].split('/')[-1]
img_to_label[img_name] = labelItem
# 创建保存当前子集的目录
output_dir = os.path.join(output_dir_root, curPhase)
if not os.path.exists(output_dir):
os.mkdir(output_dir)
# 将图像分组
dirIdx = 1
for idx in range(0, len(img_name_list), img_per_dir):
img_group_list = img_name_list[idx:min(idx+img_per_dir, len(img_name_list))]
# 创建子目录
cur_output_dir = os.path.join(output_dir, f'{dirIdx}')
if not os.path.exists(cur_output_dir):
os.mkdir(cur_output_dir)
# LabelTxt path
cur_label_path = os.path.join(cur_output_dir, f'Label.txt')
file_state_path = os.path.join(cur_output_dir, f'fileState.txt')
# fs = open(file_state_path, 'w', encoding='utf-8')
with open(cur_label_path, 'w', encoding='utf-8') as f:
# 读取图像并保存
for img_name in img_group_list:
# 获取图片的绝对路径
# fs.write(f'{os.path.join(img_path, img_name)}\t0\n')
img = cv2.imread(os.path.join(img_path, img_name))
cv2.imwrite(os.path.join(cur_output_dir, img_name), img)
f.write(f'{dirIdx}/{img_name}\t')
labelInstances = []
if img_name in img_to_label:
for labelItem in img_to_label[img_name]['instances']:
print(labelItem['text'])
labelInstances.append({
"transcription": labelItem['text'],
"difficult": labelItem['ignore'],
"points": np.array(labelItem['polygon']).reshape(-1, 2).tolist()
})
f.write(json.dumps(labelInstances, ensure_ascii=False))
f.write('\n')
dirIdx += 1
至此,数据集将被划分为 10 张图一个文件夹的形式。
第三步:配置 PPOCRLabel 并对数据集进行手动检查
配置 PPOCRLabel
PPOCRLabel 的源码和 PaddleOCR 在一起,就在 PaddleOCR\PPOCRLabel 目录下。
首先,为了避免程序运行出错,需要将 PPOCRLabel/data/paddle.png 文件删除。(因为该图像为样例图像,png 图片为四通道图片,程序加载时会报错。PS:若您的数据集为 PNG 图片,可能也会出现同样的错误,需要修改源码在读图时,去掉透明通道即可)。
随后将命令行目录切换到 PPOCRLabel 文件夹为工作目录,执行 python ppocrlabel.py --lang ch 即可打开软件。
python ppocrlabel.py --lang ch
界面如下图所示:
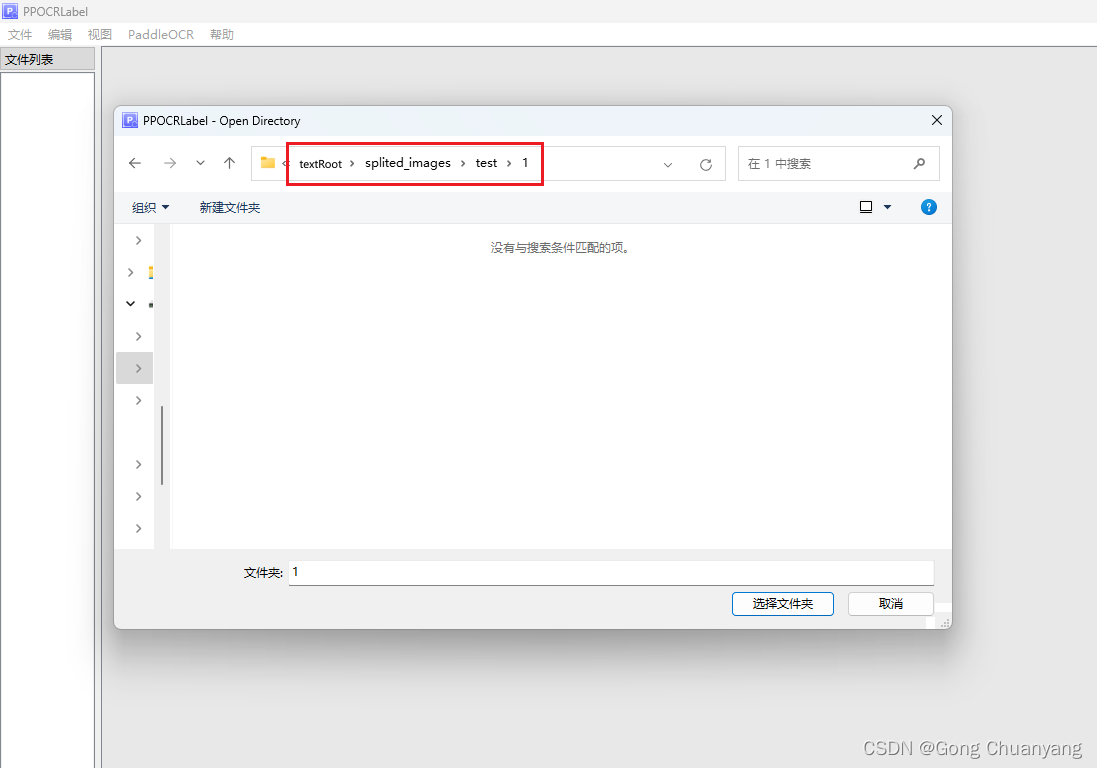
点击左上角 文件 ,选择 打开目录,选择 textRoot\splited_images\test\1 目录,即打开了一个工作目录。
打开后的界面如下图所示,左侧为文件列表,中间为图片和标注框,右侧为文本内容。若打开后图像中没有上一篇生成的伪标签内容,则说明前面的步骤有错,请检查 Label.txt 文件内容是否符合 PPOCRLabel 的格式。

至此,即可使用 PPOCRLabel 进行数据集检查以及纠错。
PPOCRLabel 使用
- 在右侧选中想要更改的文本框,按
Ctrl + E即可打开编辑框对文本内容进行修改。 - 拖动文本框的点即可对框的形状进行修改。框有两种类型水平矩形框 和 多点标注框。(若拖动框发现并不能追随鼠标的位置移动,则可以按一下
Ctrl键,再继续调整框) - 右侧可以添加新框,有两种方式添加,添加框后,可以选中框,按下
Ctrl + R进行自动文本内容识别。该方法也可对框内内容进行重新识别。 - 当该图所有内容都检查完毕,按
Ctrl + V可确认该图,并跳转到下一张。注意:确认后的图片,在左侧前面会有个绿色的√,×表示没确认! - 若想要对该图片进行全图的重新自动检测 + 识别,可先继续标注别的图片,最后选择上面的
PaddleOCR - 自动标注进行自动标注,该功能将会把所有未确认的图片进行自动标注,所以需要留到最后执行。 - 将所有图像都确认完后,按
Ctrl + S进行保存,建议一次将所有图标完再保存关闭。对于新手,保存后一定去 Label.txt 看看自己的修改是否成功保存,再继续下一个文件夹。这是泪的教训!

第四步:将标注好的内容合并到一起
这一步,将会把 splited_dataset 下的标签合并到一个 mmocr 格式的标签文件中,只标记了一部分也可以运行,因为将会读取原来生成的 Label.txt 文件内的内容。
同样,在 tools 文件夹下创建一个 merge_dataset.py 文件,内容如下:
# 该脚本与 splite_dataset 进行相反的操作,读取 splited_images 目录下的子目录,合并成一个 mmocr 的标签格式
import os
import json
import numpy as np
# 基本配置
dataset_root_path = '../textRoot' # 数据集根目录
# 分别处理训练集和测试集
phase = ['test', 'train']
for curPhase in phase:
# 读取原始的 spotting 标签
origin_spotting_path = os.path.join(dataset_root_path, f'textspotting_v1_{curPhase}.json')
if not os.path.exists(origin_spotting_path):
print(f'Warning: {origin_spotting_path} not exists, skip it.')
continue
spotting_labels = json.load(open(origin_spotting_path, 'r', encoding='utf-8'))
imgName_to_label = {}
for labelItem in spotting_labels['data_list']:
imgName_to_label[labelItem['img_path'].split('/')[-1]] = labelItem
spotting_labels['data_list'] = [] # 清空原始的标签
# 读取子目录
splited_dir_path = os.path.join(dataset_root_path, 'splited_images', curPhase)
if not os.path.exists(splited_dir_path):
print(f'Warning: {splited_dir_path} not exists, skip it.')
continue
# 获取子目录的文件夹列表
dirList = os.listdir(splited_dir_path)
for subDir in dirList:
# 获取子目录下的标签文件
label_txt_path = os.path.join(splited_dir_path, subDir, 'Label.txt')
if not os.path.exists(label_txt_path):
print(f'Warning: {label_txt_path} not exists, skip it.')
continue
# 读取标签文件
with open(label_txt_path, 'r', encoding='utf-8') as f:
for line in f.readlines():
line = line.strip()
if len(line) == 0:
continue
img_name, label = line.split('\t')
img_name = img_name.split('/')[-1]
labelItem = imgName_to_label[img_name]
# 清空原始的 instances
labelItem['instances'] = []
labelInstances = json.loads(label)
for curInstance in labelInstances:
# 读取 instance 的信息
points = np.array(curInstance['points'])
bbox = [np.min(points[:, 0]), np.min(points[:, 1]), np.max(points[:, 0]), np.max(points[:, 1])]
bbox = [int(x) for x in bbox]
polygon = points.reshape(-1).tolist()
polygon = [int(x) for x in polygon]
# 构造新的 instance
instance = {
'bbox': bbox,
'polygon': polygon,
'text': curInstance['transcription'],
'ignore': curInstance['difficult'],
'bbox_label': 0
}
labelItem['instances'].append(instance)
spotting_labels['data_list'].append(labelItem)
# 保存新的标签
new_spotting_path = os.path.join(dataset_root_path, f'textspotting_{curPhase}.json')
json.dump(spotting_labels, open(new_spotting_path, 'w', encoding='utf-8'), ensure_ascii=False)
执行完成后,将会生成 textspotting_test.json 和 textspotting_train.json。
总结
至此,该系列的所有内容全部更新完毕,由于代码片段为从我自己的工程文件中截取的代码,在写这篇文章时并没有按照文章顺序运行验证过,若存在错误,请在评论区告诉我,我将进行检查并重新运行一遍,谢谢大家!
联系方式
欢迎大家点赞、评论我的文章,你们的支持将是我继续分享的最大动力!也可以联系我获得技术支持,联系方式包括:
- 评论(可能看不见)
- 站内私信(可能看不见)
- 邮箱:cygong@foxmail.com(反馈会更快哦)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









