









1.MYSQL的两种存储引擎
区别
1事务
InnoDB支持事务,回滚,事务安全和崩溃恢复,二MyIsam不支持,当查询的速度比innodb更快
2.主键
InnoDB规定,如果没有设置主键,就会自动生成一个6字节的主键,而myisam允许没有任何索引和主键的存在,索引就是行的地址
3.外键
innodb支持外键,而myisam不支持
4.表锁
Innodb支持行锁和表锁,而myisam只支持表锁
5.全文索引
innodb不支持全文索引,但是可以用插件来实现相对应的功能,二myisam本身就就支持全文索引
6.行数
innodb获取行数是,需要扫全表,而myisam保存了当前表的总行数,直接读取即可
3.MYSQL介绍innodb引擎
innodb内存架构分为三大块:缓冲池,重做缓冲池,额外内存池
4.MYSQL四种隔离级别举例,幻读,乐观锁和悲观锁
5.为什么MYSQL默认是可重复读,是怎么实现的
扩展一下:
mysql 默认可重复读
oracle 默认已提交读
mysql binlog的三种格式 statement ,row ,mixed
为什么oracle选择已提交读呢原因有三
1.read repeatable 存在间隙锁会使死锁的概率增大
2.在可重复读隔离级别下,条件列未命中索引会锁表!而在已提交读级别下,只锁行
3.因为读已提交会先走聚簇索引,然后mysql进行优化吧不符合的记录释放,但是在可重复读级别下,走聚簇索引后会锁住整张表,更重要的是不可重复读问题再开发中是可以接受的,毕竟数据都已经提交了,读出来本身就没有太大问题
那感觉默认选择已提交读更好
那为什么mysql用的是可重复读而不是read committed
因为历史原因:从主从复制开始讲起,主从复制是基于binlog复制的,有三种格式,分别是,statement:记录的是修改sql语句
row:记录的是每行实际数据的变更
mixed:statement和row模式的混合
而mysql在5.0以前 binlog只支持statemnet这种格式,而这种格式在已提交读这个隔离级别下主从复制是有bug的,因此mysql将可重复度作为默认的隔离级别
存在什么bug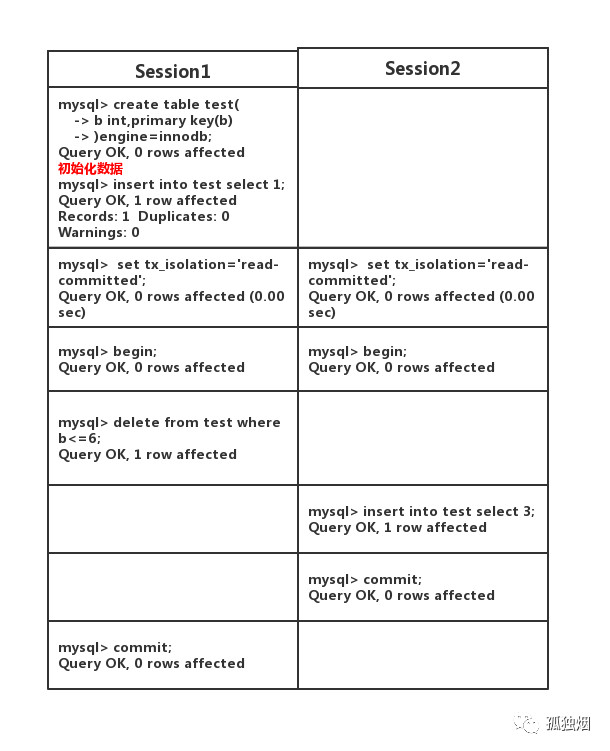
这个时候实际上在已提交读的情况下数据库中是有一条数据的
可是binlog文件却是不存在的,因为insert 先提交 而 delete后提交
故写入binlog里的是先insert 后delete 导致主从复制后数据不存在
如果是可重复读,就会进行delete的时候会加上间隙锁,导致后面的insert执行不了,自然也就不会导致上述bug了
简单来说:先删后插会造成binlog文件丢失数据
因为读已提交不存在间隙锁,而默认使用的statement会先记录
https://blog.csdn.net/ChaoticNg/article/details/115197622
详细看这里吧,太多字懒得打了
7.MYSQL索引讲一下,为什么B+树更好?B+树与B树的差别在哪里?
8.b+树的特点:
1.有k个元素的中间节点的包含k个元素(b树中是k个元素),中间节点的每个元素不保存数据,数据存储在叶子上面
2.叶子节点包含了全部元素的信息,以及指向含这些元素记录的指针。
3.所有的叶子接点都同时存在于子接点,在子接点中是最大(或最小)的元素
8.B+树相对于B树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少;
2.所有查询都要查找到叶子节点,查询性能稳定;
3.所有叶子节点形成有序链表,便于范围查询。
9,mysql各个数据类型有什么需要注意的地方
10.mysql的隔离级别
读未提交(会产生脏读)
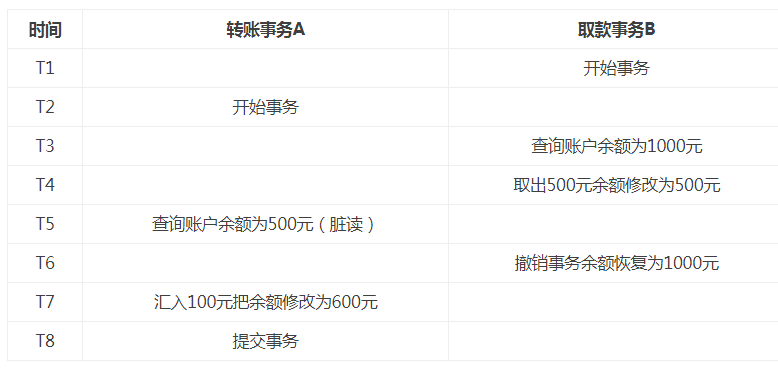
(A事务读取了B事务未提交的数据)
解决方法:在事务提交前,不允许读取其修改后的数据
读已提交(会产生不可重复读)
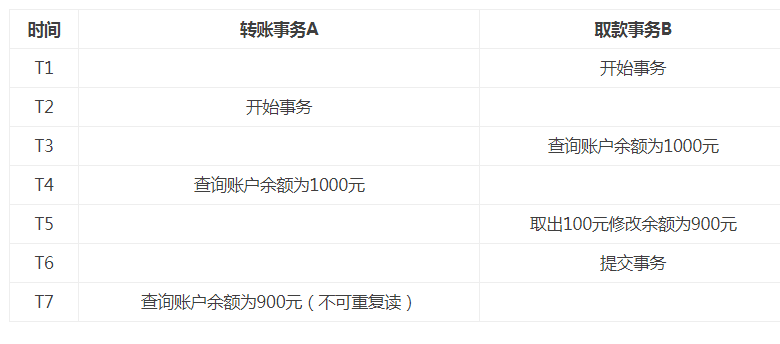
修改事务完全提交后,才可以读取数据,就可以解决不可重复读
可重复读(会产生幻读)
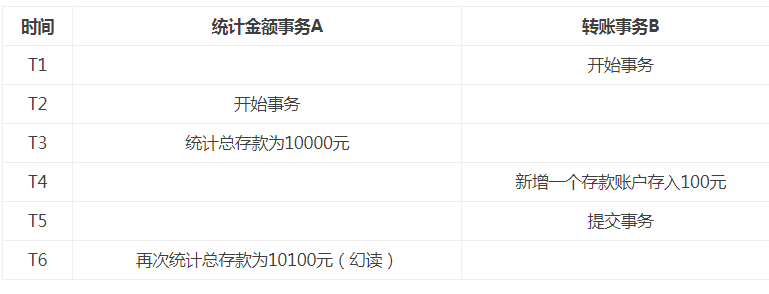
解决方法:在其他操作事务完成数据处理之前,任何其他新事务都不可以添加新数据,可以避免该问题(只允许一个事务进行)
序列化
(一次只运行一个事务进行)
11.mysql事务的使用
先设置 set global autocommit=0;
rollback回滚
commit提交
12.索引结构(b+树)
1.b+树的特点
1.中间节点会在子节点中冗余一份,而且在子节点中是最大(或最小的)
2.叶子结点存的数据,而且数据之间有双向指针把数据连接在一起
2.b+树的增删改查?
3.索引失效的情况
索引列运算:
在索引列上进行运算操作,索引将失效
字符串不加引号:
字符串类型字段使用时,不加引号,索引将失效
模糊查询:
如果仅仅是尾部模糊匹配,索引不会失效,如果是头部模糊查询,索引失效
or连接条件:
用or分割开的条件,如果or前的条件中有索引,后面的列中没有索引,那么涉及的索引都不会被用到。
数据分布影响:
在MYSQL查询时,会评估使用索引的效率和走全表扫描的效率,如果走全表扫描更快,则放弃索引,走全表扫描,因为索引是用来索引少量数据的,如果索引查询放回大批量的数据,还不如走全表扫描来的快,此时索引会失效
14.存储引擎知道哪些,有哪些索引,底层是什么实现的
1从数据结构角度
hash索引(memory索引支持)
b+树索引
FULLTEXT索引
R-TREE索引
2.逻辑角度
主键索引
单列索引
多列索引
唯一索引
空间索引(针对空间的数据结构建立的索引)
3.物理存储角度
1聚簇索引
2非聚簇索引
15mysql优化(索引,分表分库)
索引应该怎么建立
分表分库?
16.acid的含义,mysql是如何保证的
acid
A(Atomicity)原子性
原子性是指一个事务是一个不可分割的整体,内部的操作要么都做,要么都不做,所以说,实现原子性的核心就在于如何实现回滚
C(Consistency)一致性
事务执行的结果是数据库从一个一致性状态变到另一个一致状态,即数据库完整性没有被破坏,事务执行的前后都是合法的状态
(数据完整性包括但不限于,实体完整性,如行的主键存在且唯一,列完整性如字段的类型,大小,长度要符合要求,外键约束,用户自定义完整性)
I(Isolation)隔离性
事物内部的操作与其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
D(Durability)持久性
持久性是指事务一旦提交,他对数据库的改变就是永久的,接下来的其他操作不对应该对其有任何影响,并且不能回滚
MYSQL中如何保证事务的ACID
A(原子性):
undo log
C(一致性)
1.保证原子性,持久性,隔离性,如果这些无法保证,事务的一致性也无法保证
2.数据库本身提供保障,例如不运行向整行列插入字符串值,字符串长度不能超过列的限制等
3.应用层面进行保障,例如如果转账操作只扣除转账者的劲儿,二没有增加接收者的余额,无论数据库实现的多么完美,也无法保证状态的一致性
I(隔离性)
实现分为两方面
1.一个事务写操作对另外一个事务写操作的影响:锁机制保证隔离性
2.一个事务写操作对另外一个事务读操作的影响:MVVC保证隔离性
D(持久性)
redo log
存在的背景
数据是放在磁盘的,但是如果每次读写数据都需要磁盘io,效率会很低,为此,Innodb提供了缓存,bp中包含了部分数据页的映射,作为访问数据库的缓冲,当从数据库读取数据时,会首先写入BP,BP中修改的数据会定期刷新到磁盘中(这一过程称为刷脏)
BP的使用打打提高了读写数据的效率,但是也带来了新的问题,如果MYSQL宕机,而此时BP中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性就无法保证。
redo log就被引入来解决这个问题(宕机导致BP中的数据没有刷新磁盘,造成数据丢失)当数据被修改时,除了修改BP中的数据,还会在redo log中记录这次操作
当事务提交是,会调用fsync接口对redo log 进行刷盘,如果MYSQL宕机,重启时可以读取redo log 中的数据,对数据库进行恢复,redo log 采用的是 WAL(write-ahead logging,预写式日志)所有修改先写入日志,在更新到BP,保证了数据不会因为MYSQL宕机而丢失,从而满足了持久性的要求。
17mysql分布式id
1数据库多主模式
将数据库设定为多主模式,这样每次新增数据都会去做同步这样避免生成一样的iad
2号段模式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pgSyy3Wk-1605837443017)(en-resource://database/714:0)]](https://img-blog.csdnimg.cn/20201120095737278.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3poYW9oYW5fX18=,size_16,color_FFFFFF,t_70#pic_center)
3.雪花算法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YNTzYXti-1605837443021)(en-resource://database/716:0)]](https://img-blog.csdnimg.cn/20201120095805659.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3poYW9oYW5fX18=,size_16,color_FFFFFF,t_70#pic_center)
4.自动增长列(也被称为升级版本号段模式)
设置起始值和步长(缺点是需要规定数据库个数)
18mysql索引慢分析:线上开启slowlog,提取慢查询,然后仔细分析explain中type字段以及extra字段,发生的具体场景以及mysql是怎么做的?
19mysql分表分库平滑扩容方案
1流程
1.先进行双主同步
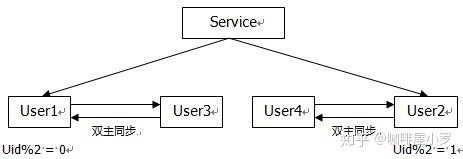
2.同步完成后进行主主双写
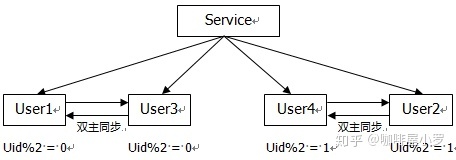
3.删除双主同步,修改数据库配置并重启(秒级)
4.清空数据库中多余数据
2.需要考虑分布式id的问题见问题17,避免数据库id重复
20隔离级别,sql慢查询
1.读未提交
2.读已提交
3.可重复读
4.序列化
set global slow_query_log =1
21对mysql的设计掌握如何(应该是范式那些东西)
22mysql默认的存储引擎
innodb
23.存储引擎了解哪些?
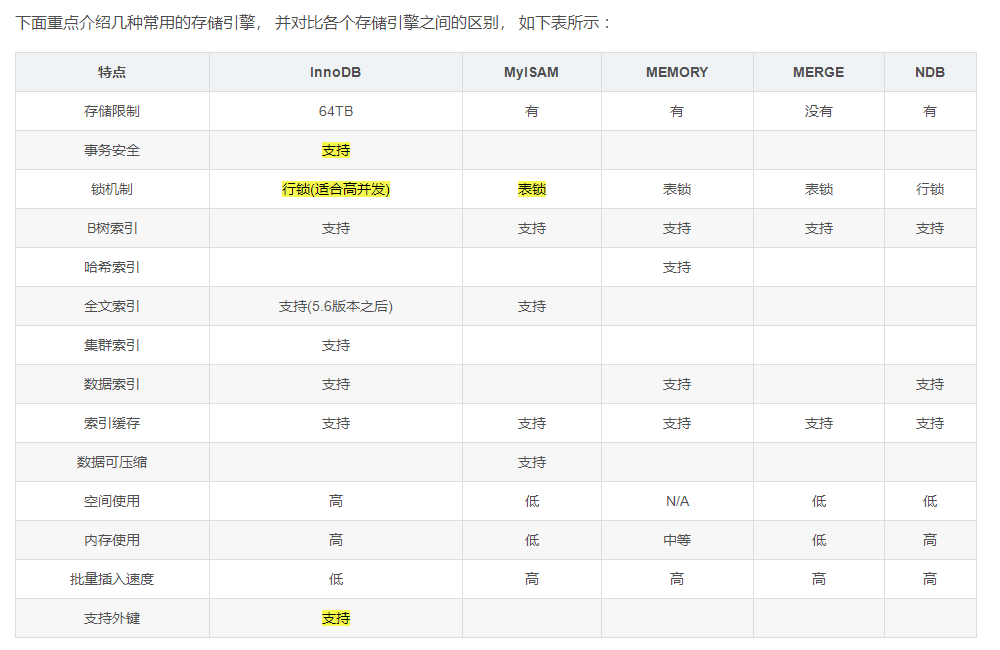
| 功 能 | MYISAM | Memory | InnoDB | Archive |
|---|---|---|---|---|
| 存储限制 | 256TB | RAM | 64TB | None |
| 支持事物 | No | No | Yes | No |
| 支持全文索引 | Yes | No | No | No |
| 支持数索引 | Yes | Yes | Yes | No |
| 支持哈希索引 | No | Yes | No | No |
| 支持数据缓存 | No | N/A | Yes | No |
| 支持外键 | No | No | Yes | No |
24mysql索引用过哪些?
25mysql主键索引和非主键索引在搜索和检索的过程中有什么区别吗
在innodb中普通索引只包含主键id需要回表查询,而myisam则不需要,因为存的都是数据
26mysql如何实现事务的?(复习)
通过回答mysql中的acid是怎么保证的(见16)
27.mysql主从同步过程了解吗?
bin-log?
28mysql的索引结构(复习)
B+树
1.中间节点只保存索引,并且在子节点中冗余一份,而且是子节点数据中的最小(或最大)值
2.叶子节点存储的是数据,并且通过双向链表链接起来
29mysql事务的隔离级别(复习)
30mysql事务的四个特性(复习)
31mysql事务的隔离级别,分别解决了什么问题
读未提交(最菜)
读已提交(脏读)
可重复读(不可重复读)
序列化(幻读)
32知道mysql innodb是什么数据结构吗?
34mysql索引结构(复习)
35mysql数据库引擎(复习)
37对mysql索引了解哪些(复习)
39mysql根据多列构造索引(实践题吧…)
40mysql索引结构为什么不用跳表(这个因为上面一个问题问到的是zset为什么用的是跳表)
41mysql有哪些存储引擎,你用到的是什么存储引擎,区别是什么
42.mysql表锁有哪些
43.mysql索引,联合索引,索引失效,左连接
1.mysql索引(复习题12)
1.按数据结构分类
2.按索引结构分类
3.从逻辑角度分类
2.索引失效(复习题12)
1.索引列运算
2.字符串不加引号
3.模糊查询
4.or连接条件
5.数据分布影响(如果全表更快的话就不走索引)
44索引B+树(复习)
45.为什么项目的数据库要用到mysql innodb特性底层了解吗数据分区,怎么加快读写效率
46.mysql的存储引擎,innodb和myisam底层数据结构区别
47.什么时候用redis,什么时候用mysql
48.mysql索引
50.redis 和mysql 可以用binlog 同步全量数据,也可以更新mysql后删除redis更新缓存(?)
53mysql索引
55mysql ab 两个分别建立索引会更快吗
56.mysql主从复制以及好处,工作原理和机制
好处:
1.数据更安全:做了数据冗余,不会因为单台服务器的宕机而丢失数据
2.性能大大提升:一主多从,不同用户从不同数据库读取,性能提升
3.扩展性更优:流量增大时,可以方便的增加从服务器,不影响系统使用
4.负载均衡:一主多从相当于分担了主机任务,做了负载均衡
主从方案的主要作用
1.读写分离
2.发扬不同表引擎的优点
3.热备( slave和master的数据“准实时”同步)
主从复制原理
1.slave端的io线程链接上master端,并请求从制定binlog日志文件指定的pos节点位置(或则从最开始)开始复制之后的日志内容
2.master端在接受到来自slave端的io线程请求后,通知负责复制线程的io线程,根据slave端io线程的请求信息,读取制定binlog日志指定pos节点位置之后的日志信息,然后放回给slave端的io线程。该放回信息中除了binlog日志所包含的信息之外,还包括本次返回信息在master端的binlog文件名以及在binlog日志中的pos节点位置(便于下次同步)
3.slave端的io线程在接受到master端io放回的信息后,将接收到的binlog日志内容依次写入到slave端的relaylog文件(mysql-reply-bin.xxx)的最末端,并将读取到的master端的binlog文件名和pos节点的位置记录到master-info(该文件存在slave端)文件中,以便在下一次读取的时候能够qingchude告诉masrer,我需要从那个binlog文件的哪个pos节点位置开始,请把此节点后的日志内容发给我。
4.slave的sql线程在检测到relaylog文件中新增内容后,会马上解析该log文件中的内容。然后还原成在master端真正执行的那些sql语句,并在自身按顺序依次执行这些sql语句。这样实际上就是master端真正执行的那些sql语句,并在自身按顺序执行这些sql语句。这样,实际上就是master端和slave端执行了同样的sql语句,所以master端和slave端是完全一样的
缺点
1.主从间的数据库不是实时同步,就算网络连接正常,也能存在主从数据不一致的情况
2.如果主从的网络断开,则从库会在网络恢复正常后,批量进行同步。
3.如果对从库进行修改数据,那么如果此时从库正在执行主库的binlog时,则会出现错误而停止同步,这是一个很危险的操作,所以一般情况下,我们要非常小心的修改从库上的数据。
57.mysql引擎,索引数据结构,为什么用b+树不用别的(复习)
58.mysql索引底层数据结构(复习)
59.mysql索引为什么要用b+树(复习)
60.说下mysql的索引结构?b+树和红黑对比下
61.mysql聚簇索引?(复习)联合索引?为什么会有最左匹配原则?
联合索引本质,创建(a,b,c) 的时候,相当于创建了(a)单列索引(a,b)联合索引以及(a,b,c)联合索引,想要索引生效的话,只能使用a和a,b和a,b,c三种组合当然,我们上面测试过,a,c也会走索引但是实际上只用到了a的索引,c并没有用到
为什么会有最左匹配
如图
仅仅看a是有顺序的(1,1,2,2,3,3)
而仅仅看b是没有顺序的(1,2,1,4,1,2)
但是如果在a相同的情况下,b也是有顺序的
62.mysql的三大log?
redo log
undo log
bin log
64.mysql索引相关(复习)
65.mysql索引知道哪些,底层是怎么实现的(复习)
66.mysql索引,隔离级别(复习)
67.mysql的事务隔离级别,mysql acid 回表,普通索引和唯一索引的区别;mysql最左匹配原则
68.聊聊mysql,索引,sql优化
70.mysql的两种引擎
71mysql索引重建的问题
72zookeeper,mysql,redis怎么实现分布式锁,各有什么优缺点,生产中一般用哪个
73mysql查询速度慢如何优化,如何添加索引(覆盖索引/前缀匹配)
74mysql的锁?
75mysql默认使用哪个隔离级别
76mysql的存储引擎
77mysql怎么存储时间
78mysql把时间戳转化成日常格式时间的函数
79mysql中innodb引擎
80mysql怎么去查询的,什么时候走索引,什么时候不走
81mysql了解什么…
82mysql索引(重复几百次了)
84mysql索引原理
85redis和mysql存储数据的区别
86mysql有哪些索引,介绍一下b+树具体的结构
87mysql索引分类分别说一下
88mysql两种引擎的对比
89mysql主从复制
91mysql的存储引擎
92聚簇索引和非聚簇索引有什么区别
93查询 a in () and b in ()时是怎么利用索引的?
94加入查询a in ()时,mysql是怎么利用索引的?
96mysql的两个引擎及使用场景
97怎么查看优化mysql语句耗时操作
98mysql的索引,为什么是b+树而不是平衡二叉树
99mysql的io过高怎么优化,分库分表以及分区
100mysql的索引结构,myisam的索引结构,innodb索引结构,innodb为什么必须要有主键索引
101请说一下mysql的事务隔离级别
102mysql聚簇和非聚簇
103什么情况下会导致索引失效
104mysql底层有几种实现方式
105mysql为什么要使用b+树
106mysql性能评测
107mysql常见引擎的区别,mvvc机制是干嘛的
108索引失效的几个场景
109.mysql引擎
110mysql两个引擎的比较
111mysql各种日志的作用
分为两种层面
MYSQL4层面
错误日志
很好理解,就是服务运行过程中发生的严重错误日志。但我们的数据库无法启动时,就可以来这里看看具体不能启动的原因是什么
二进制文件
它有另外一个名字你应该熟悉,叫Binlog,其记录了对数据库所有的更改
查询日志
记录了来自客户端的所有语句
慢查询日志
这里记录了所有响应时间超过阈值的SQL语句,这个阈值我们可以自己设置,参数为long_query_time,其默认值为10s,且默认是关闭的状态,需要手动的打开。
innodb层面
undo log
redo log
113延时双删
114mysql主键使用uuid的坏处
115mysql索引
116mysql联合索引
117如何解决mysql高并发的问题
118mysql设计表会考虑那些因素,varchar和char有什么区别
119mysql多事务操作会有哪些问题,具体解释一下,对应的有哪些事务隔离级别,怎么实现的(MVCC,版本链+undo log+read view)
120通过慢查询(explain)哪些字段可以判断优化
121mysql为什么往往以集群提供服务,扩容会有什么问题
122mysql的表级锁和行级锁是悲观锁还是乐观锁
123mysql的分表是怎么处理的
124如何用mysql实现队列 kafka什么的
125mysql建索引的原则
126查看mysql死锁用什么命令
127mysql binlog
128mysql查找为什么快
129select count在mysql的哪个存储引擎中最快
myisam
130一亿人中怎么找身份证
它有另外一个名字你应该熟悉,叫Binlog,其记录了对数据库所有的更改
查询日志
记录了来自客户端的所有语句
慢查询日志
这里记录了所有响应时间超过阈值的SQL语句,这个阈值我们可以自己设置,参数为long_query_time,其默认值为10s,且默认是关闭的状态,需要手动的打开。
innodb层面
undo log
redo log
113延时双删
114mysql主键使用uuid的坏处
115mysql索引
116mysql联合索引
117如何解决mysql高并发的问题
118mysql设计表会考虑那些因素,varchar和char有什么区别
119mysql多事务操作会有哪些问题,具体解释一下,对应的有哪些事务隔离级别,怎么实现的(MVCC,版本链+undo log+read view)
120通过慢查询(explain)哪些字段可以判断优化
121mysql为什么往往以集群提供服务,扩容会有什么问题
122mysql的表级锁和行级锁是悲观锁还是乐观锁
123mysql的分表是怎么处理的
124如何用mysql实现队列 kafka什么的
125mysql建索引的原则
126查看mysql死锁用什么命令
127mysql binlog
128mysql查找为什么快
129select count在mysql的哪个存储引擎中最快
myisam














 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









