






背景:
为了快速且规范的实现ai应用,可使用LangChain框架,便于后期维护。虽然deepseek异军突起,在终端用户占有率很高,但是仔细查阅相关api接口,尤其是自有知识库需要使用的文本向量化模型方面,openai仍无法被替代。目前国内仍无法付费使用openai接口,需要迂回使用azure版的openai相关模型。
目前,ai类应用处于快速迭代期,很多一年前的教程已经过时,因此记录下2025年最新的ai应用使用方法。
一、开通azureopenai需要注册azure.microsoft.com微软云服务,并绑定visa功能的信用卡。
openai.com不支持国内信用卡:

在azure的主页左上角下拉菜单,找到“成本管理 + 计费”:
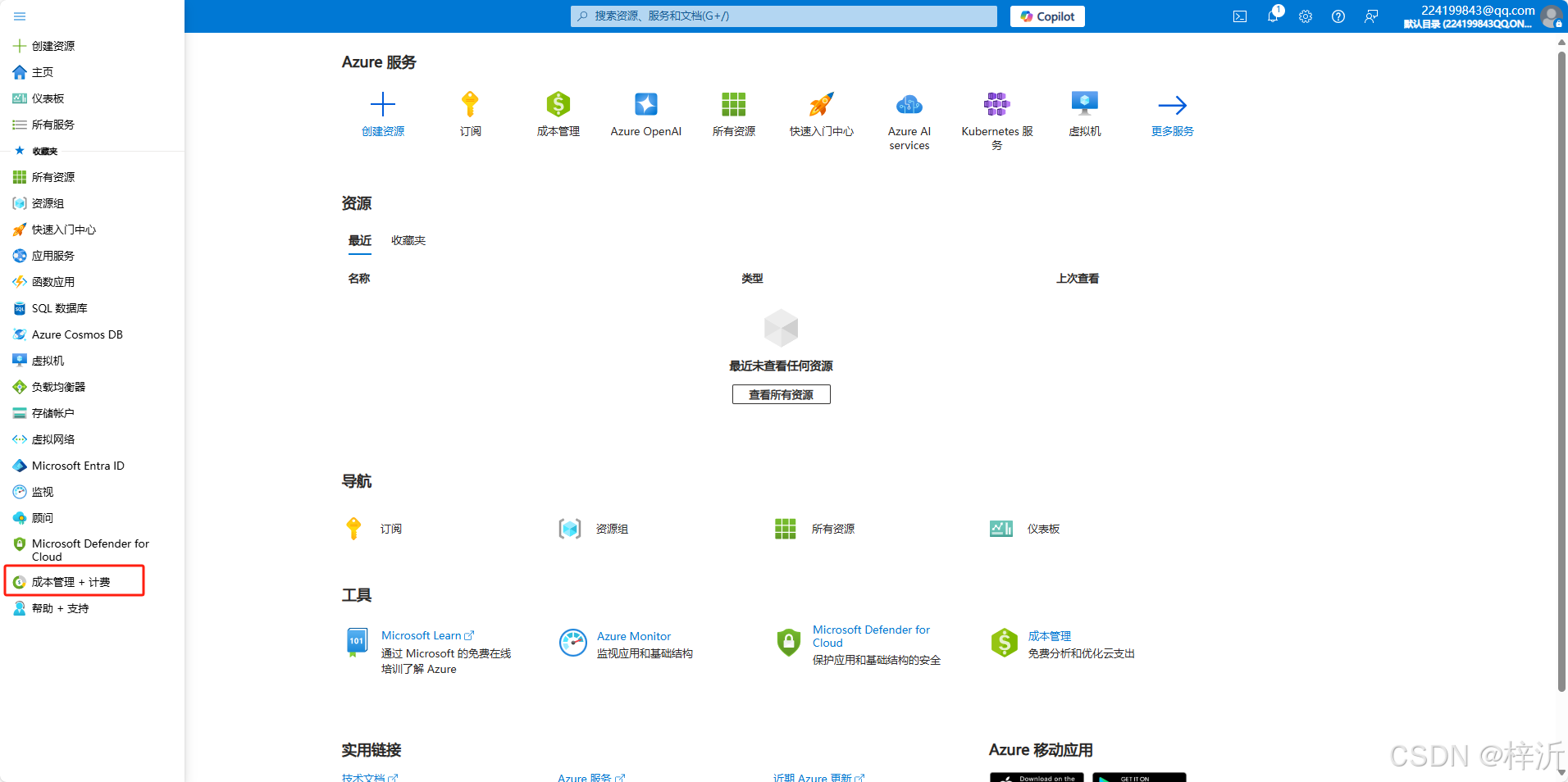
在“成本管理 + 计费”窗口左侧导航栏,打开“计费-》付款方式”:
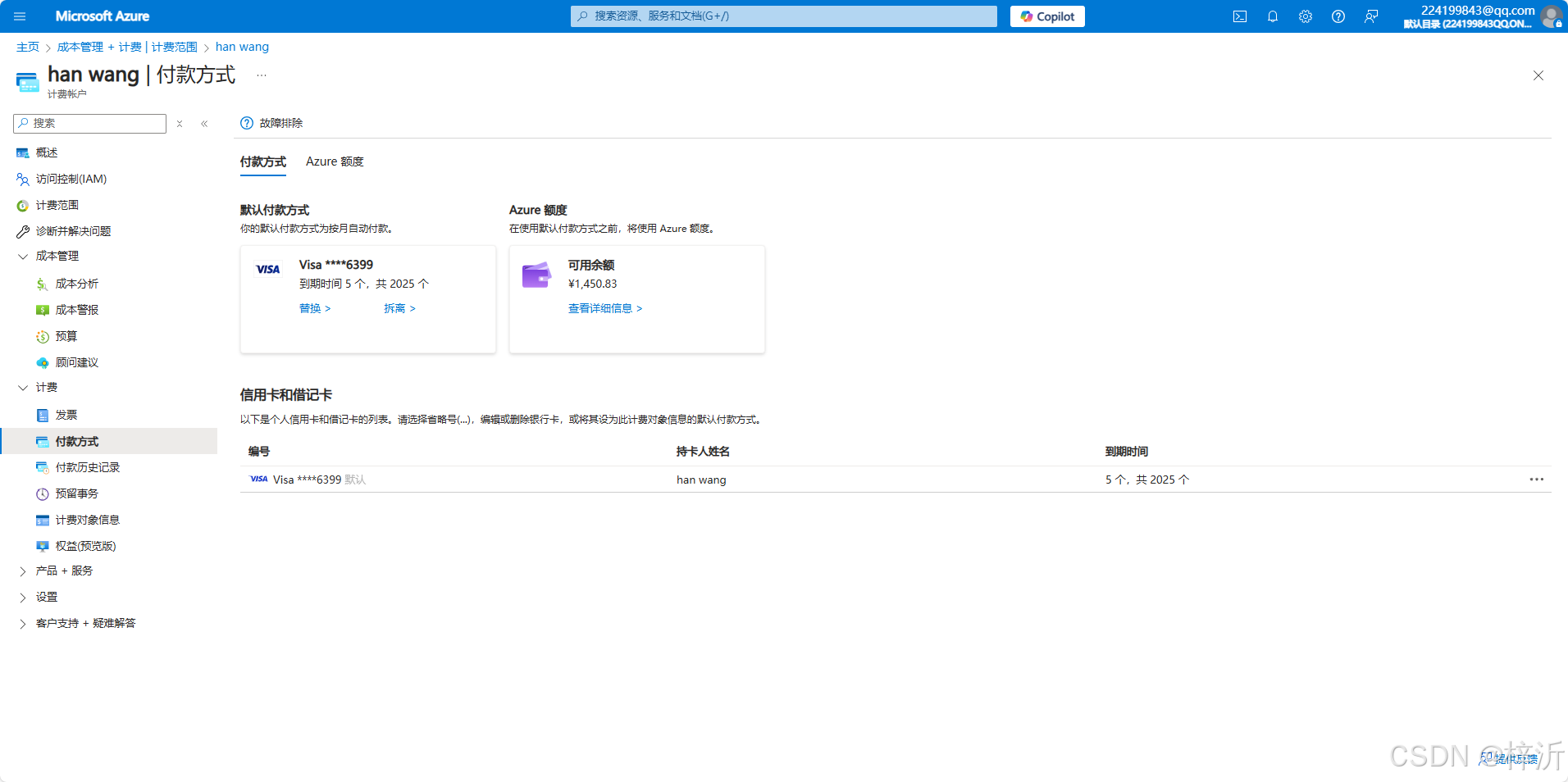
添加visa卡即可。
二、进入Azure AI Foundry,创建ai容器
访问新版的ai地址:Azure AI Foundry![]() https://ai.azure.com/
https://ai.azure.com/
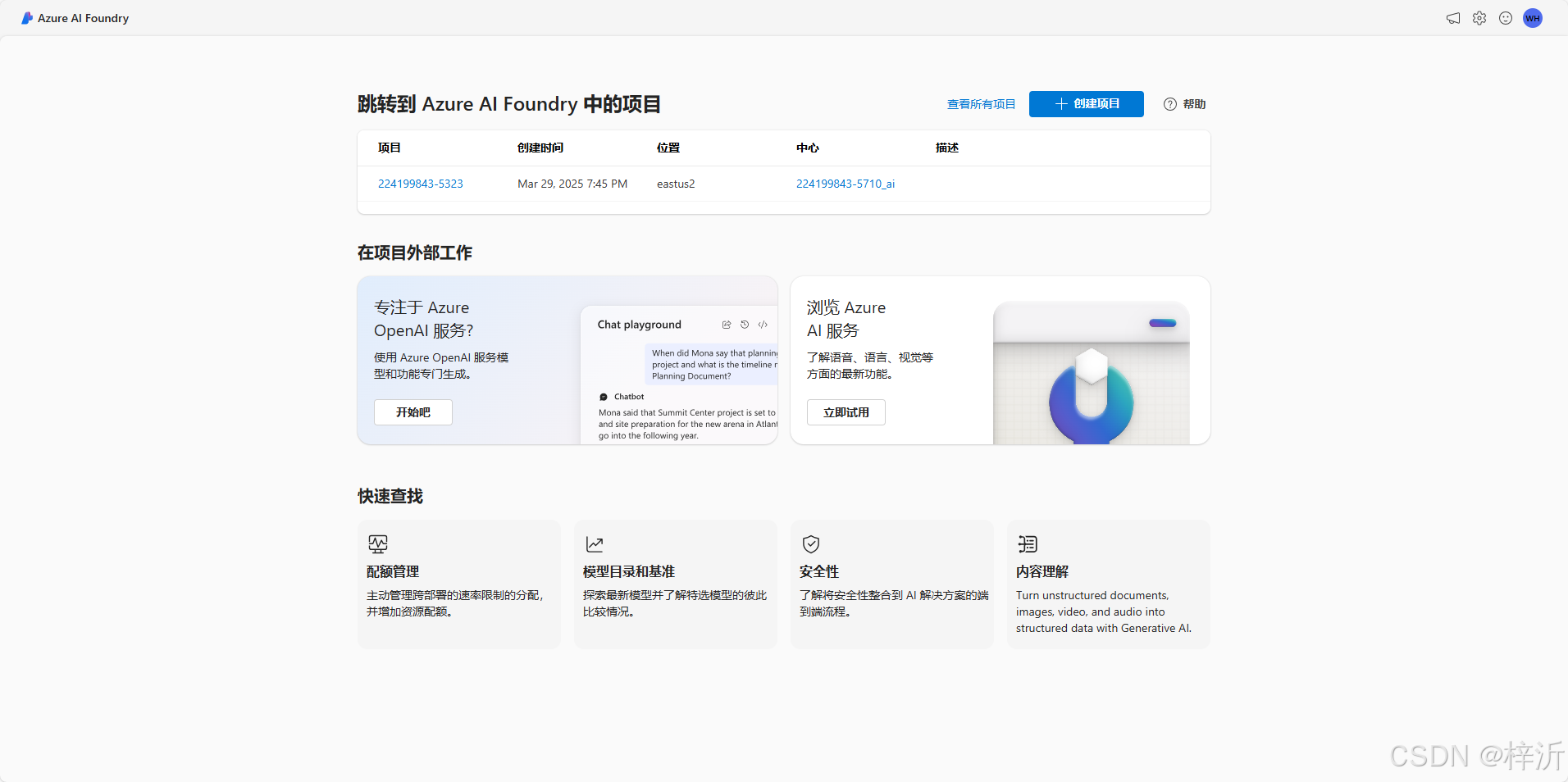
然后通过顶部“+创建项目”按键一键完成openai容器创建。
注意:我也试过旧版的创建容器方式,也许是访问地址没有搞对,使用api访问总是报404错误。
用新版创建容器后,点击项目名称,直接进入项目。
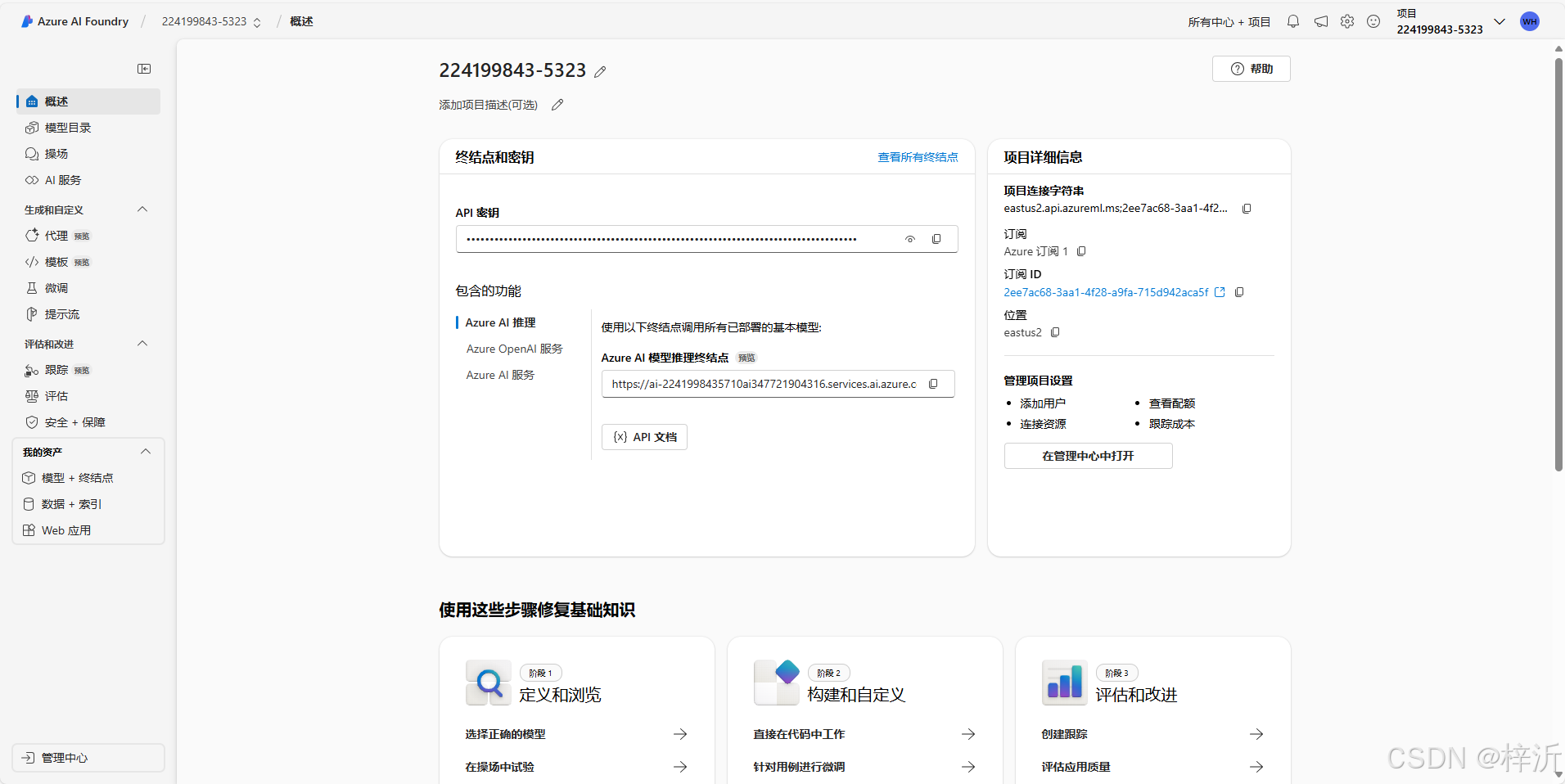
点击操场即可测试当前容器是否运行正常:
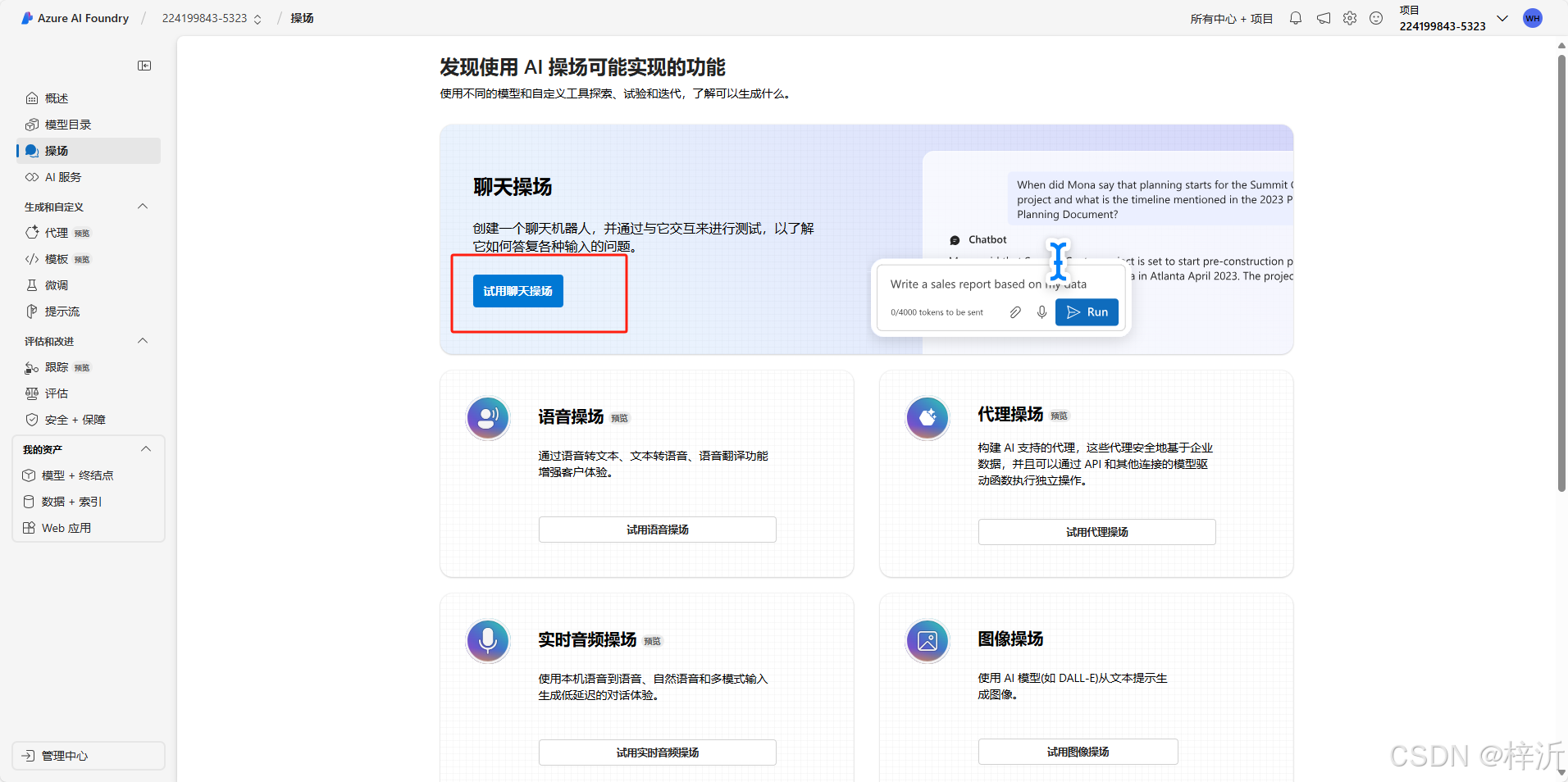
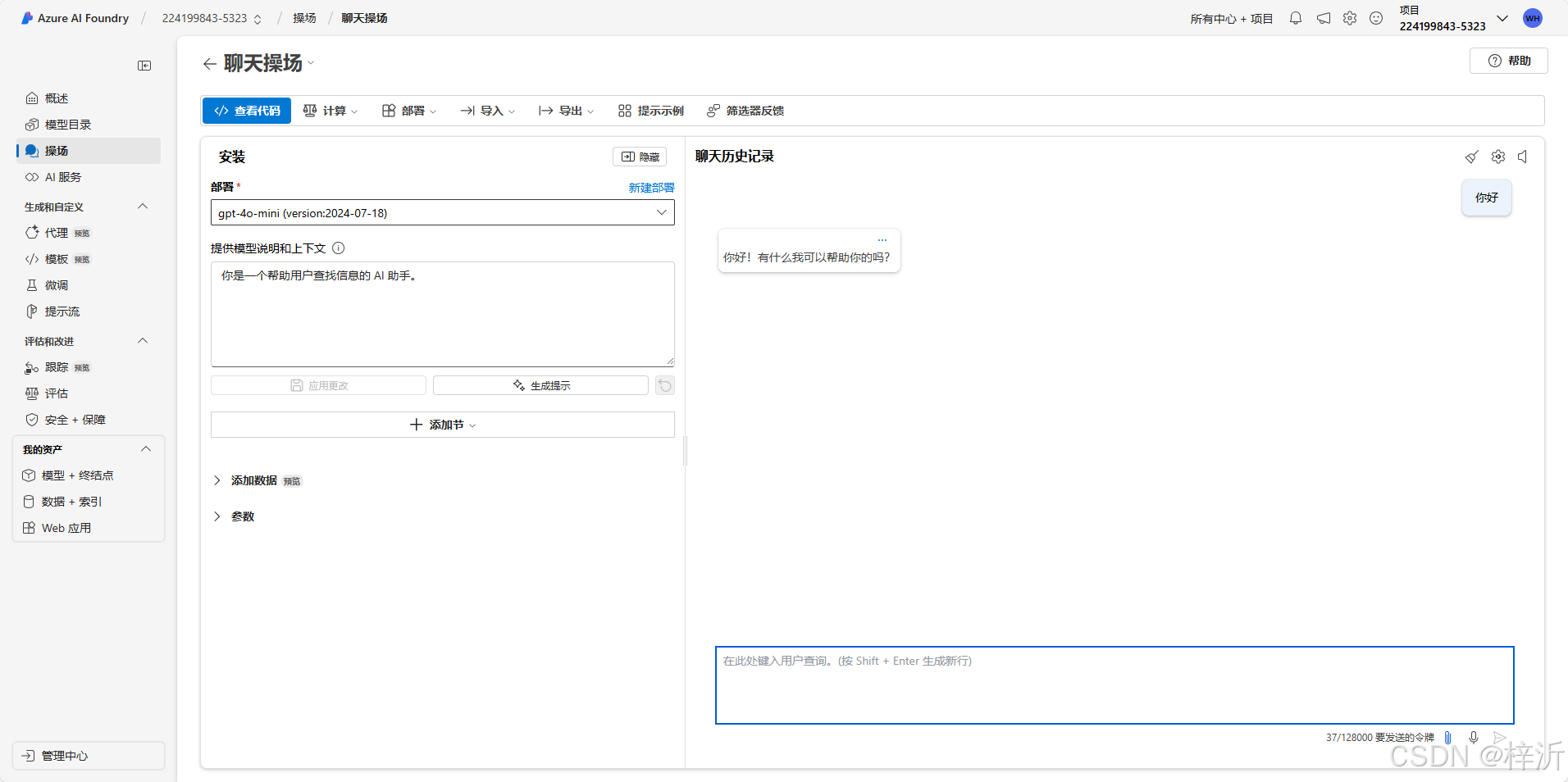
在旧版的azure openai容器没有找到类似功能。也许有,但是新版更好找。推荐小白初学者用新版
Azure AI Foundry![]() https://ai.azure.com/
https://ai.azure.com/
三、测试python接入azure openai
点击聊天操场的“查看代码”功能
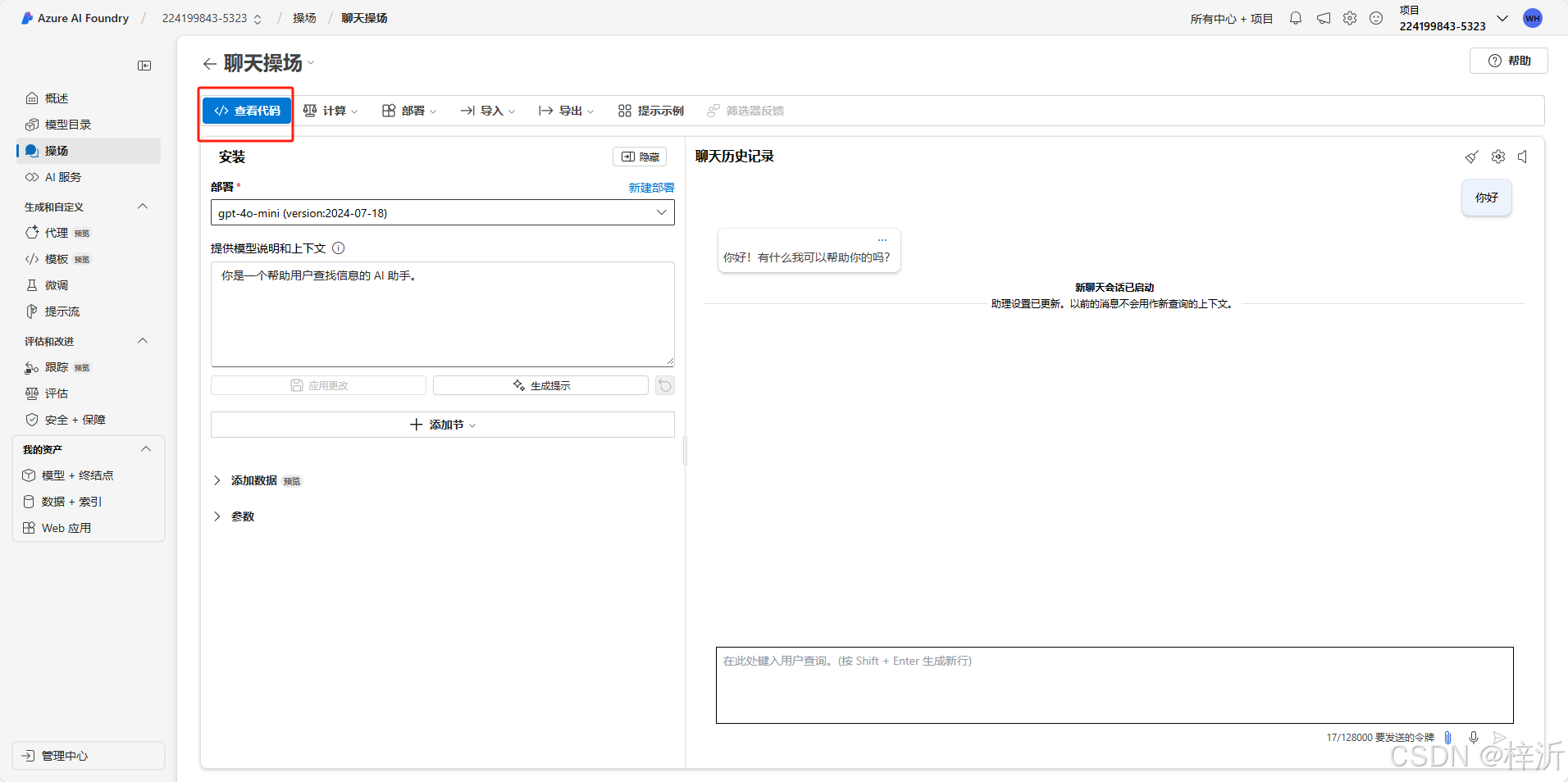
可以看到完整的python运行代码:

粘贴到https://colab.research.google.com/或者jupyter notebook中稍加改动(加入api key和endpoint)即可运行:
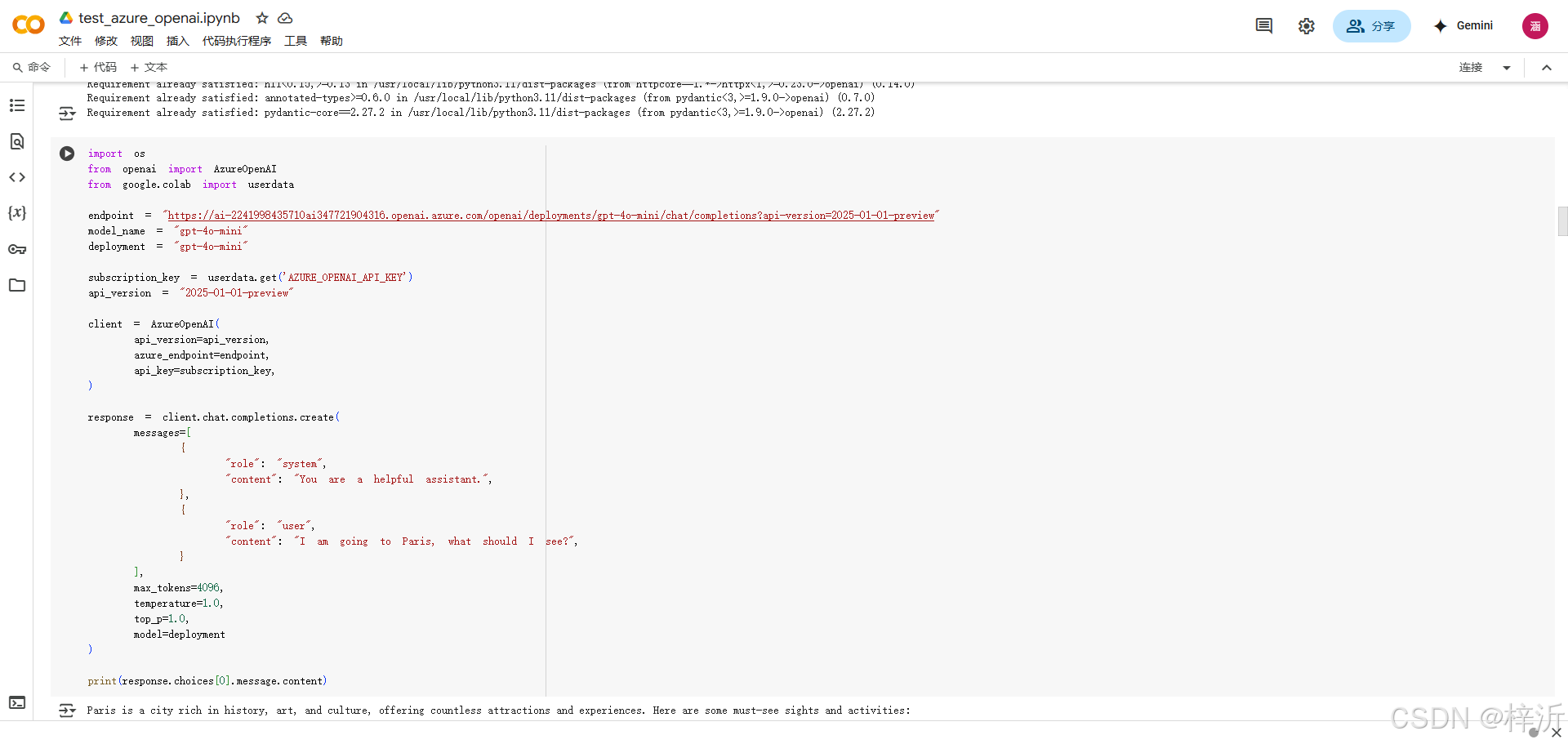
api key在 Azure AI Foundry / 224199843-5323 / 概述 页可以找到
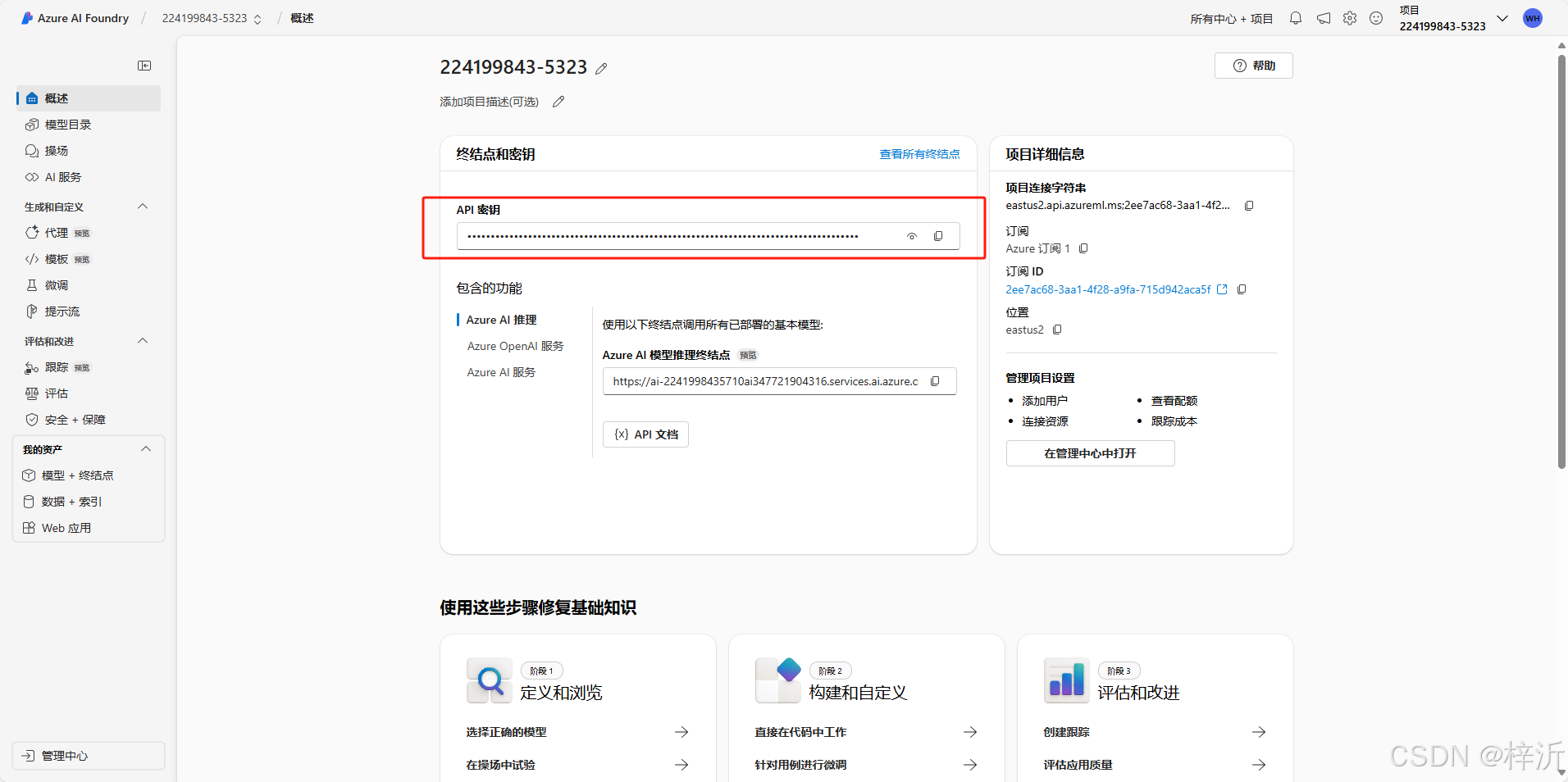
endpoint在示例代码上方的文本框中能找到:

注意:在使用langchain_openai框架时,endpoint不填全,api接口无法访问,会报404错误。比如只填域名部分:
https://ai-2241998435710ai347721904316.openai.azure.com/https://ai-2241998435710ai347721904316.openai.azure.com/

被这个问题困惑了一天,最后填写了正确的url地址才解决。
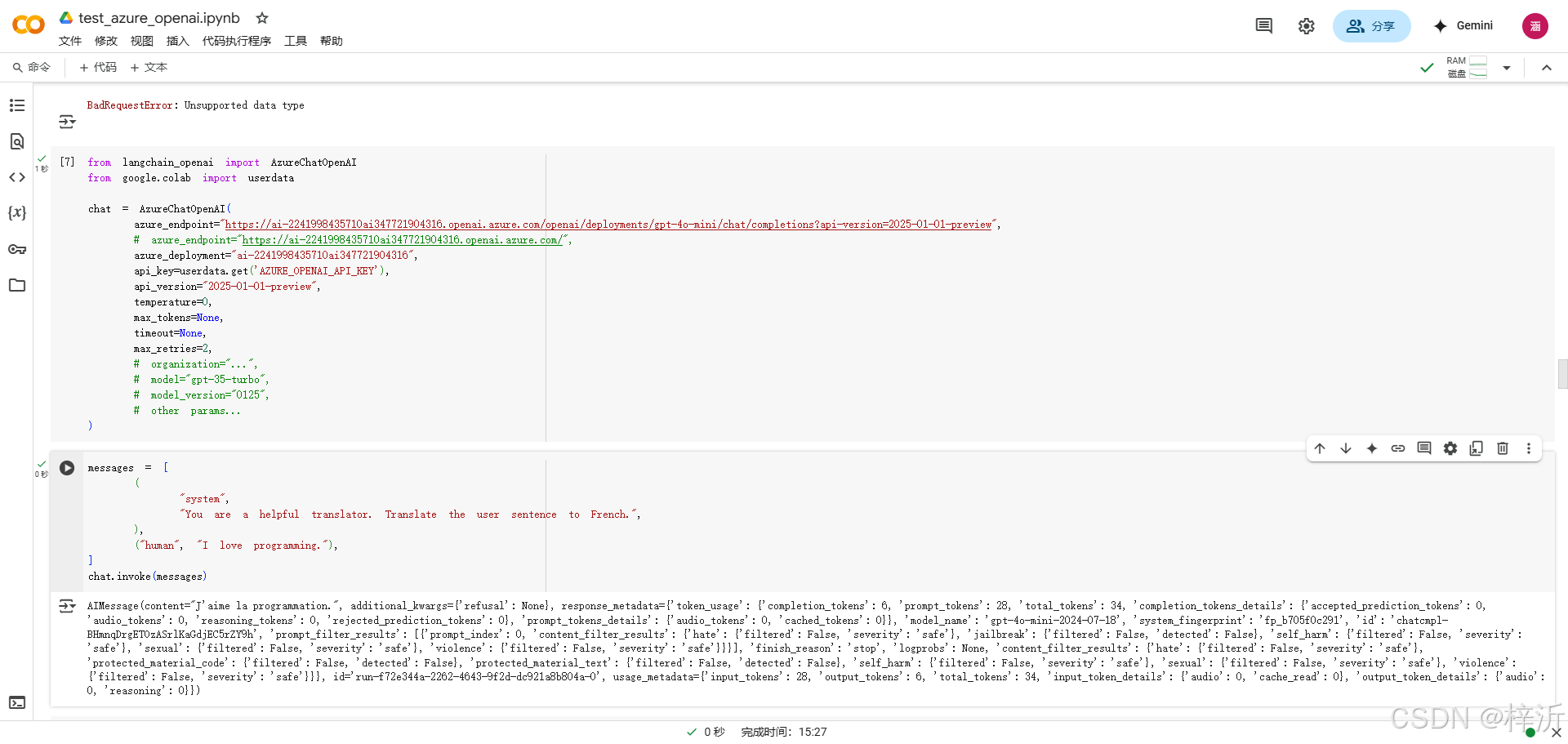
!pip install -U langchain_openai
from langchain_openai import AzureChatOpenAI
from google.colab import userdata
chat = AzureChatOpenAI(
azure_endpoint="https://ai-2241998435710ai347721904316.openai.azure.com/openai/deployments/gpt-4o-mini/chat/completions?api-version=2025-01-01-preview",
# azure_endpoint="https://ai-2241998435710ai347721904316.openai.azure.com/", 错误url
azure_deployment="ai-2241998435710ai347721904316",
api_key=userdata.get('AZURE_OPENAI_API_KEY'),
api_version="2025-01-01-preview",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# organization="...",
# model="gpt-35-turbo",
# model_version="0125",
# other params...
)
messages = [
(
"system",
"You are a helpful translator. Translate the user sentence to French.",
),
("human", "I love programming."),
]
chat.invoke(messages)四、学会使用langchain的 提示词模板(ChatPromptTemplate)和 输出解析器(JsonOutputParser)
虽然吴恩达的课程已经过时,但是可以结合deepseek的提示和最新的langchain api文档来学习,我觉得吴恩达的讲课思路非常清晰,很适合看了一堆视频,越看越没有头绪的初学者。
from langchain_openai import AzureChatOpenAI
from google.colab import userdata
chat = AzureChatOpenAI(
azure_endpoint="https://ai-2241998435710ai347721904316.openai.azure.com/openai/deployments/gpt-4o-mini/chat/completions?api-version=2025-01-01-preview",
# azure_endpoint="https://ai-2241998435710ai347721904316.openai.azure.com/",
azure_deployment="ai-2241998435710ai347721904316",
api_key=userdata.get('AZURE_OPENAI_API_KEY'),
api_version="2025-01-01-preview",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# organization="...",
# model="gpt-35-turbo",
# model_version="0125",
# other params...
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
# from langchain_core.pydantic_v1 import BaseModel, Field, HttpUrl
# langchain_core.pydantic_v1 已淘汰,langchain可以直接导入pydantic 2的对象
from pydantic import BaseModel, Field, HttpUrl
from typing import List, Optional, Union
from datetime import date
# 1.1 创建含有动态字段的简历结构
# 动态字段的基类
class DynamicSection(BaseModel):
section_name: str = Field(description="模块名称")
content: Union[str, List[str], dict] = Field(description="模块内容")
# 教育经历、工作经历、技能、项目经验
class Education(BaseModel):
"""教育背景条目(所有字段可选)"""
sections: List[DynamicSection] = Field(default_factory=list, description="动态项或动态列表")
class WorkExperience(BaseModel):
"""工作经历条目(所有字段可选)"""
sections: List[DynamicSection] = Field(default_factory=list, description="动态项或动态列表")
class Skill(BaseModel):
"""技能条目(所有字段可选)"""
sections: List[DynamicSection] = Field(default_factory=list, description="动态项或动态列表")
class ProjectExperience(BaseModel):
sections: List[DynamicSection] = Field(default_factory=list, description="动态项或动态列表")
class Resume_dynamic(BaseModel):
"""简历数据模型(所有字段可选)"""
# 基础信息
seq_num: Optional[int] = Field(None, description="序号", gt=0)
file_name: Optional[str] = Field(None, description="文件名", max_length=255) # 允许字母数字/下划线/点/横线 regex=r"^[\w\-\.]+$"
is_resume: Optional[bool] = Field(None, description="该文件是否是简历")
# 个人信息
name: Optional[str] = Field(None, description="姓名", min_length=2, max_length=50)
gender: Optional[str] = Field(None, description="性别", examples=["男", "女", "其他"])
birthday: Optional[date] = Field(None, description="生日")
ethnicity: Optional[str] = Field(None, description="民族")
political_affiliation: Optional[str] = Field(None, description="政治面貌")
marital_status: Optional[str] = Field(None, description="婚姻状况")
native_place: Optional[str] = Field(None, description="籍贯或户口所在地")
address: Optional[str] = Field(None, description="现住址")
id_number: Optional[str] = Field(None, description="身份证号码", pattern=r"^\d{17}[\dXx]$")
phone: Optional[str] = Field(None, description="手机号", pattern=r"^1[3-9]\d{9}$")
email: Optional[str] = Field(None, description="邮箱", pattern=r"^[\w\.-]+@[\w\.-]+\.\w{2,4}$")
# 教育信息
highest_degree: Optional[str] = Field(None, description="最高学历", examples=["高中", "专科", "本科", "硕士", "博士"])
major: Optional[str] = Field(None, description="最高学历专业", max_length=50)
# 求职信息
job_target: Optional[str] = Field(None, description="求职意向职业", max_length=100)
# 结构化信息
education_background: Optional[List[Education]] = Field(None, description="教育背景")
work_experience: Optional[List[WorkExperience]] = Field(None, description="工作经历")
skills: Optional[List[Skill]] = Field(None, description="特殊技能或资格证书")
project_experience: Optional[List[ProjectExperience]] = Field(None, description="项目经历")
# 2.1 创建简历结构json解析器
resume_output_parser = JsonOutputParser(pydantic_object=Resume_dynamic)
# 3. 创建简历解析提示模板
prompt = ChatPromptTemplate.from_template(
"解析以下简历:{question}\n"
"请按照指定格式返回:\n"
"{format_instructions}"
)
# 4. 组合成链
chain = prompt | chat | resume_output_parser
resume_text = '''
应聘人员信息表
姓名 ...
电话 ...
... ...
'''
# 5. 调用
result = chain.invoke({
"question": resume_text,
"format_instructions": resume_output_parser.get_format_instructions()
})
result输出结果:
{'seq_num': None,
'file_name': None,
'is_resume': None,
'name': '',
'gender': '男',
'birthday': '1900-00-00',
'ethnicity': '汉',
'political_affiliation': '群众',
'marital_status': '未婚',
'native_place': '吉林省长春市',
'address': '高新技术开发区,保利罗兰香谷',
'id_number': '221100000000000000',
'phone': '15922334455',
'email': None,
'highest_degree': '硕士',
'major': '建筑与土木工程',
'job_target': '市政道路、排水设计',
'education_background': [{'sections': [{'section_name': '教育经历',
'content': {'起止年月': '2012.09-2015.07',
'毕业院校及系名称': '吉林建筑大学',
'专业': '建筑与土木工程',
'学位': '硕士'}},
{'section_name': '教育经历',
'content': {'起止年月': '2008.09-2012.07',
'毕业院校及系名称': '长春工程学院',
...
{'section_name': '项目经历',注意:langchain_core.pydantic_v1 已淘汰,langchain可以直接导入pydantic 2的对象
例子来自deepseek,在本例中class Resume_dynamic(BaseModel):对象即用于提示词中对生成格式的要求,又用于将ai生成结果解析为dict对象,一箭双雕。其余代码非常直观,链式编程也符合一般人的认知。这样编写的代码即简洁又高效。

















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









