






在复习JavaSE时看到泛型方面的东西,觉得当时草率的学习完这一部分的内容后,并没有真正体会到java真正的伟大和美好,遂在此进行记录。
泛型的出现是为了应对我们传入的参数类型多变的情况,在泛型出现之前,我们可以使用Object来暂时解决这一问题,但是后来发现,Object类型虽然可以接收多种参数类型,但是无法对参数类型进行判断,如果我们用Object来拟定了参数,那么就无法做到甚至判断传入的参数是int还是String。当我们的取值出现问题时,就只能通过强制类型转换来实现。这样会导致我们程序的代码量大大增加,并且程序的健壮性也会有所缺陷
健壮性(知识复习):是指程序对于规范要求以外的输入,能够判断这个输入不符合规范要求,并且能够做出合理的反应。
这时泛型就出现了,他比Object要好点,其好的地方就在于他可以在被给定数据之后,知道是什么数据类型。
泛型的基础语法
一般由一个<>加上内部包裹的参数类型来组成,例如:<T> ,<E> 并且泛型一般需要跟在对象的后面,才能被我们的编译器识别
例:public class Person<T>{
T name;
}
当我们需要使用时:
Person<String> person=new Person<>();
如果我们定义了多个不同的泛型,就按照顺序来指定参数类型
例:public class Person<T,E>{
T name;
E age;
}
当我们需要使用时:
Person<String,Integer> person=new Person<>();
泛型无法在静态方法中使用,其原因在于泛型将对于数据类型的确定控制在了编译阶段,如果类型不符合,将无法通过编译(因为静态方法属于类而不是对象,他会在类加载阶段就被分配,那时我们还没有给定类型,所以无法使用)。
我们还可以在接口中定义方法时使用泛型
public interface Test<T>{
T test();
}
在定义普通方法时,我们也可以使用泛型
Public <T> T test(T t){
return t;
}
泛型会在我们使用这些方法时自动确认参数类型,一个方法中的T,如果在参数类型被确定后,他们的参数类型都是一样的。
泛型还存在界限
所谓界限,在泛型中被分为上界和下界,也就是传入参数类型的允许范围。例如我们现在出现一个新的需求。定义一个功能,该功能要求做到用户除数字类型以外的参数都不可用被传入,而数字类型又有Integer,double,float,long。这时我们就需要用到泛型的界限。语法如下:
public class Score<T extends Number>//number类型为所有数据类型的父类
public class Score<? super Object>
界限思想如下图
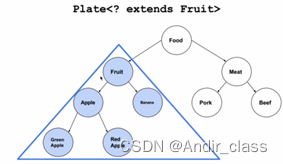
(此图中,food为fruit的上界,apple为fruit的下界)
通过界限我们就可以更灵活的控制泛型的类型了。
泛型的实现原理
我们查看设定泛型的程序被编译后的内容后发现:
一个泛型被编译后,实际上会直接变成object类型,如果设置了界限,那么就会直接变成界限类型。
因此我们说,泛型只会在编译阶段进行类型检查,而在程序运行时就不会。
所以哪怕我们在使用时不去为泛型指定类型,也是可以使用的

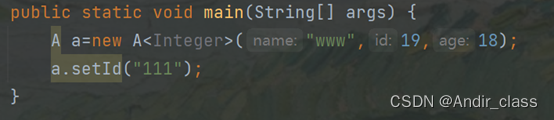
(这里会提示形参化A的原始使用,说明了泛型在被编译后并不会对数据类型进行检查)
在原始引用的情况下,我们发现set方法提示我们传入的参数类型是Object。使用原始类型,就可以绕过设置泛型后的编译过程中的检查,因为他的底层本质上存储的是Object类型。
只有当我们在代码前面也指定了参数类型,才会开始检查
A<Integer> a=new A<Integer>();
我们查看以下程序的编译后内容
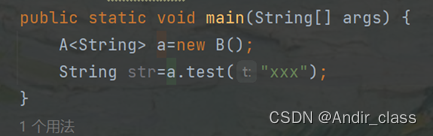
编译后:
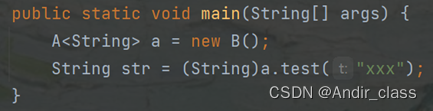
再次说明了他底层存入的是上界类型的数据
@override为什么不会出现数类型的错误呢?
重写的条件是需要和父类的方法返回值类型一样,而泛型默认的原始类型是Object,子类在明确后变为其他类型(在继承后就不可使用泛型了,只能指定为明确的类型),这显然不满足重写的条件,但编译却能够通过
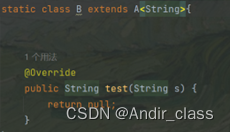
我们对B类进行反编译后显示:

他最终还是满足重写的规则的!B类中自动出现了一个object类型的方法。这是编译器为我们自动生成的桥接方法来支持重写
以上为大致内容,记录于此。新人小白,还请大佬指教














 2588
2588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









