







关于InputStream.read()方法,我今天发现了这样一段代码。
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
ServletInputStream in=req.getInputStream();
String filePath=getServletContext().getRealPath("/body.out");
FileOutputStream out=new FileOutputStream(filePath);
int total_len=req.getContentLength();
byte[] buf=new byte[total_len];
for(int read_len=0,reading_len=0;read_len<total_len;read_len+=reading_len)
{
reading_len=in.read(buf,read_len,total_len-read_len);
}
out.write(buf,0,total_len);
in.close();
out.close();
}也许会有疑惑,这个循环是拿来做什么的,据我所了解的几种read返回的情况如下
- 当读到EOF时,返回-1;
- 当读取到指定字节的长度时,返回指定字节的长度
- 当未读取到指定字节长度,但已经读取完缓冲区,返回读取到的长度
在这个代码片段中,如果按照正常想法而言,读取一次刚好能把数据读完,那么这个循环的作用在什么地方?书上讲了这样一个数据的读取模型,如下:
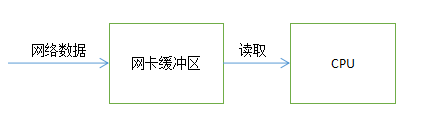
网络数据经过网络传输后先存在网络缓冲区,cpu在到缓冲区内取数据,在这样一个数据读取的模型中,可能存在这样一种情况,如果网络传输速度较慢,那么cpu读取数据的速度会大于网络数据传输的速度,导致数据未传完,但缓冲区内没有数据,使读取端误认为数据已经读完。因此一个循环来保证一直读取到指定字节长度为止可以避免这种情况。当然,如果数据量过大,如100M,则缓冲区的大小也会变大,可能发生内存溢出的情况,这时就得考虑用计数判断的形式。
对于常规I/O流而言,这种可能不好判断到底读完还是未读取完,但对于Request对象而言,可以根据头字段的设置值来进行判断。















 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









