






目录
4. 配置/var/log/snmptrap/snmptrap.log日志分割
一、snmptrap所需软件安装
sudo apt install libperl-dev snmptrapd snmpd snmp build-essential libsnmp-perl snmp-mibs-downloader
此处可以在如下链接下载net-snmp备用,
Net-SNMPNet-SNMPhttp://www.net-snmp.org/download.html![]() http://www.net-snmp.org/download.html
http://www.net-snmp.org/download.html
二、Perl trap 接收器文件获取
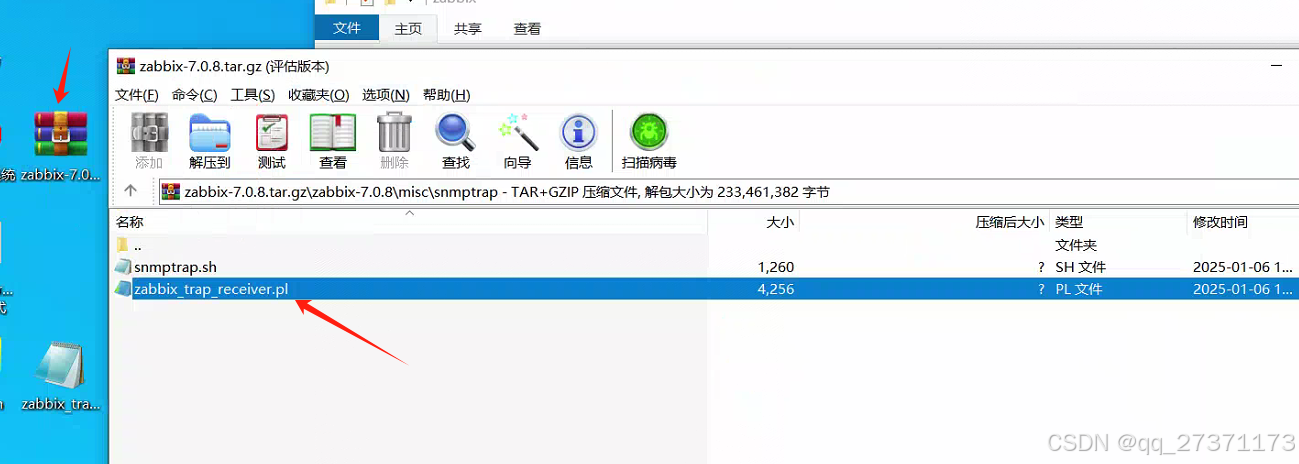
下载下图文件解压(需要使用安装的版本的文件),拷贝出路径下文件稍后使用: misc/snmptrap/zabbix_trap_receiver.pl

三、配置文件修改
1. zabbix_server.conf修改
编辑配置文件
vim /etc/zabbix/zabbix_server.conf
修改如下选项:
# 启用snmptrap
StartSNMPTrapper=1
# 日志存放路径,文件和文件夹均需要单独创建,
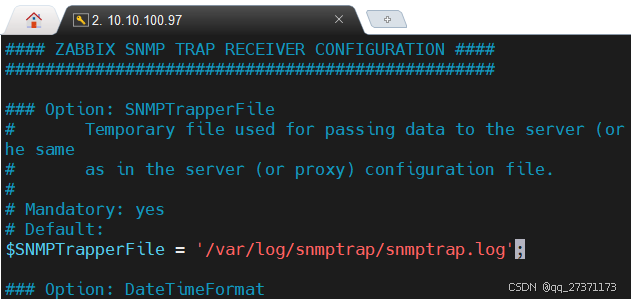
SNMPTrapperFile=/var/log/snmptrap/snmptrap.log
赋予创建的文件权限 chmod 777 /var/log/snmptrap/snmptrap.log
zabbix_server参数优化参考如下链接:
2. 配置 Perl trap 接收器
# 将之前获取的接收器文件拷贝到/usr/bin/目录
cp zabbix_trap_receiver.pl /usr/bin/
# 赋予执行权限
chmod +x /usr/bin/zabbix_trap_receiver.pl
# 修改脚本 $SNMPTrapperFile参数必须和zabbix_server.conf中SNMPTrapperFile值一致
vim /usr/bin/zabbix_trap_receiver.pl
$SNMPTrapperFile = '/var/log/snmptrap/snmptrap.log';
3. 配置snmptrapd
snmp v1,v2c使用的是团体字,按下图修改即可接收信息,v3版本需要额外添加命令
# 修改配置文件
vim /etc/snmp/snmptrapd.conf
# 添加如下参数
disableAuthorization yes
perl do "/usr/bin/zabbix_trap_receiver.pl"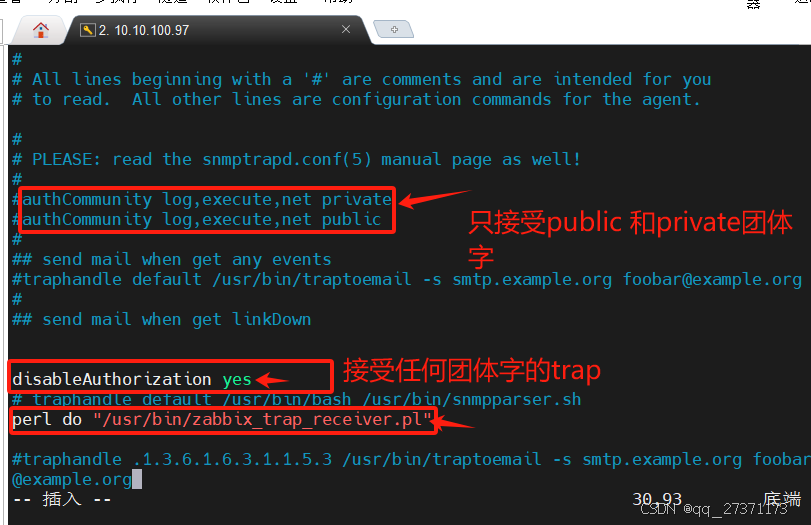
在snmptrapd中snmptrap v3版本创建的用户必须与发送陷阱的EngineID绑定。为此,您可以在snmptrapd.conf文件中创建如下:
createUser -e ENGINEID myuser SHA“我的身份验证通行证” AES“我的加密通行证”
在上一行中,需要设置以下内容:
ENGINEID :
将要发送陷阱的应用程序的EngineID。在华为交换机中,display cu 可以在snmp-agent配置的开头看到
myuser :
将要发送陷阱的USM用户名。
SHA:
身份验证类型(SHA或MD5,SHA更好)
“我的认证通行证”:
认证密码短语,用于生成秘密认证密钥。如果包含空格,请用引号引起来。
AES
使用的加密类型(AES或DES,AES更好)
“我的加密通行证”
用于生成秘密加密密钥的加密密码短语。如果包含空格,请用引号引起来。如果不选择它,它将被设置为与身份验证密码相同的密码。
具体可参考如下连接
https://blog.51cto.com/u_13858192/25320124. 配置/var/log/snmptrap/snmptrap.log日志分割
随便找一个复制一份改改名字和路径
5. 可上传mib文件用于将oid解析为英文名称
将从厂商处下载的文件上传到 /usr/share/snmp/mibs
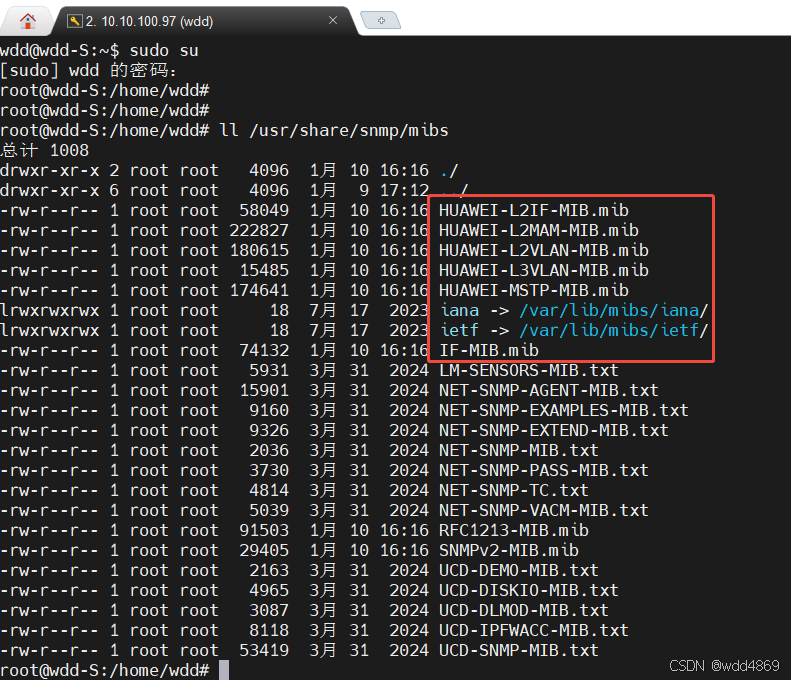
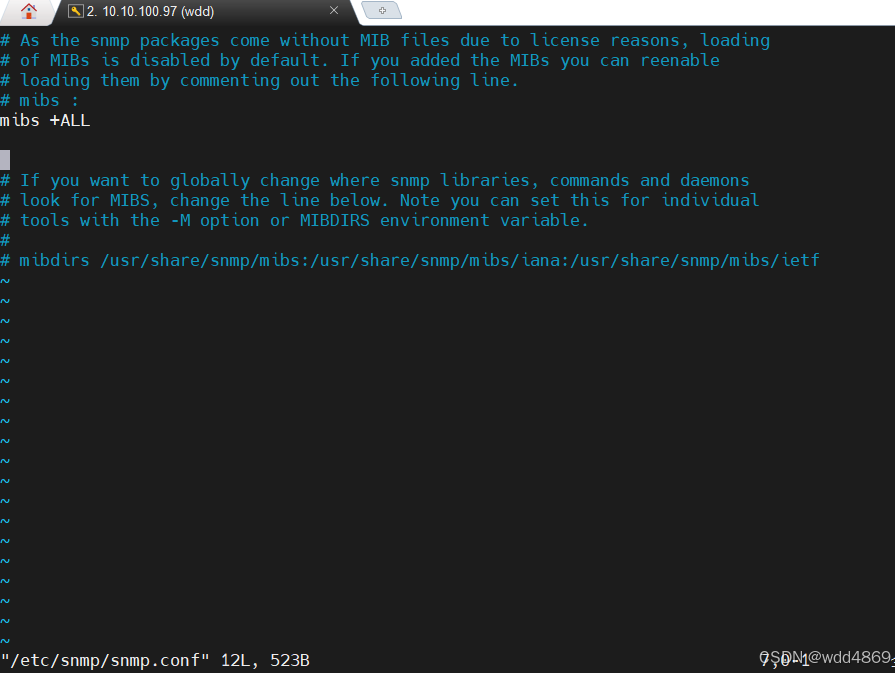
修改配置文件 vim /etc/snmp/snmp.conf
四、验证配置生效情况
4.1.重启服务
systemctl restart snmptrapd snmpd zabbix-server
systemctl enable snmptrapd
4.2.验证
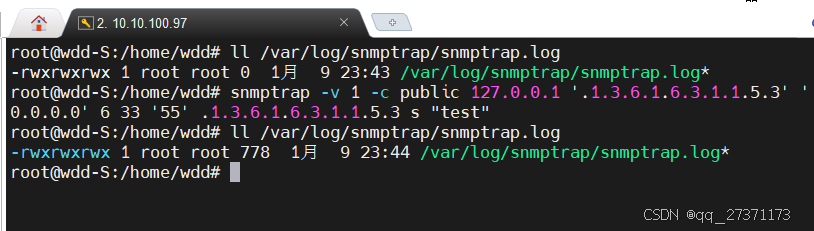
输入如下命令:
snmptrap -v 1 -c public 127.0.0.1 '.1.3.6.1.6.3.1.1.5.3' '0.0.0.0' 6 33 '55' .1.3.6.1.6.3.1.1.5.3 s "test"可以看到数据已经写入,如果没有数据,试试安装net-snmp在排查试试。
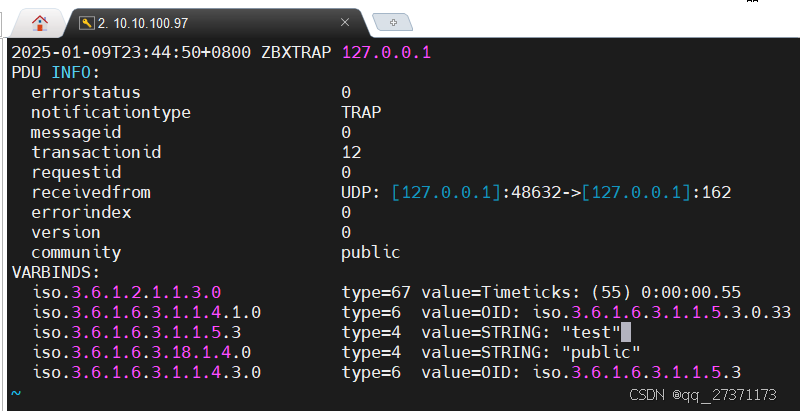
五、新增主机监控
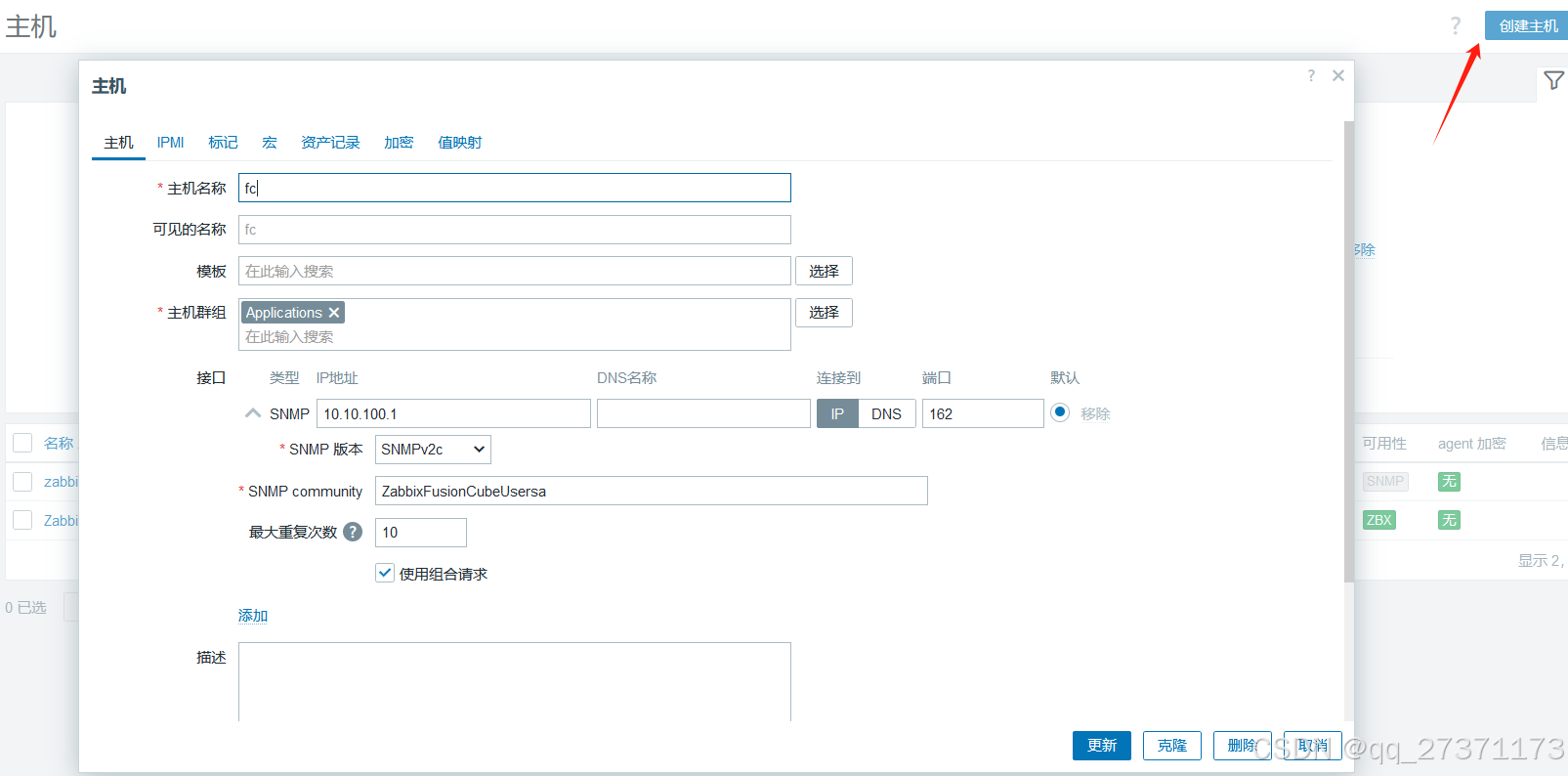
5.1 创建Fusion主机
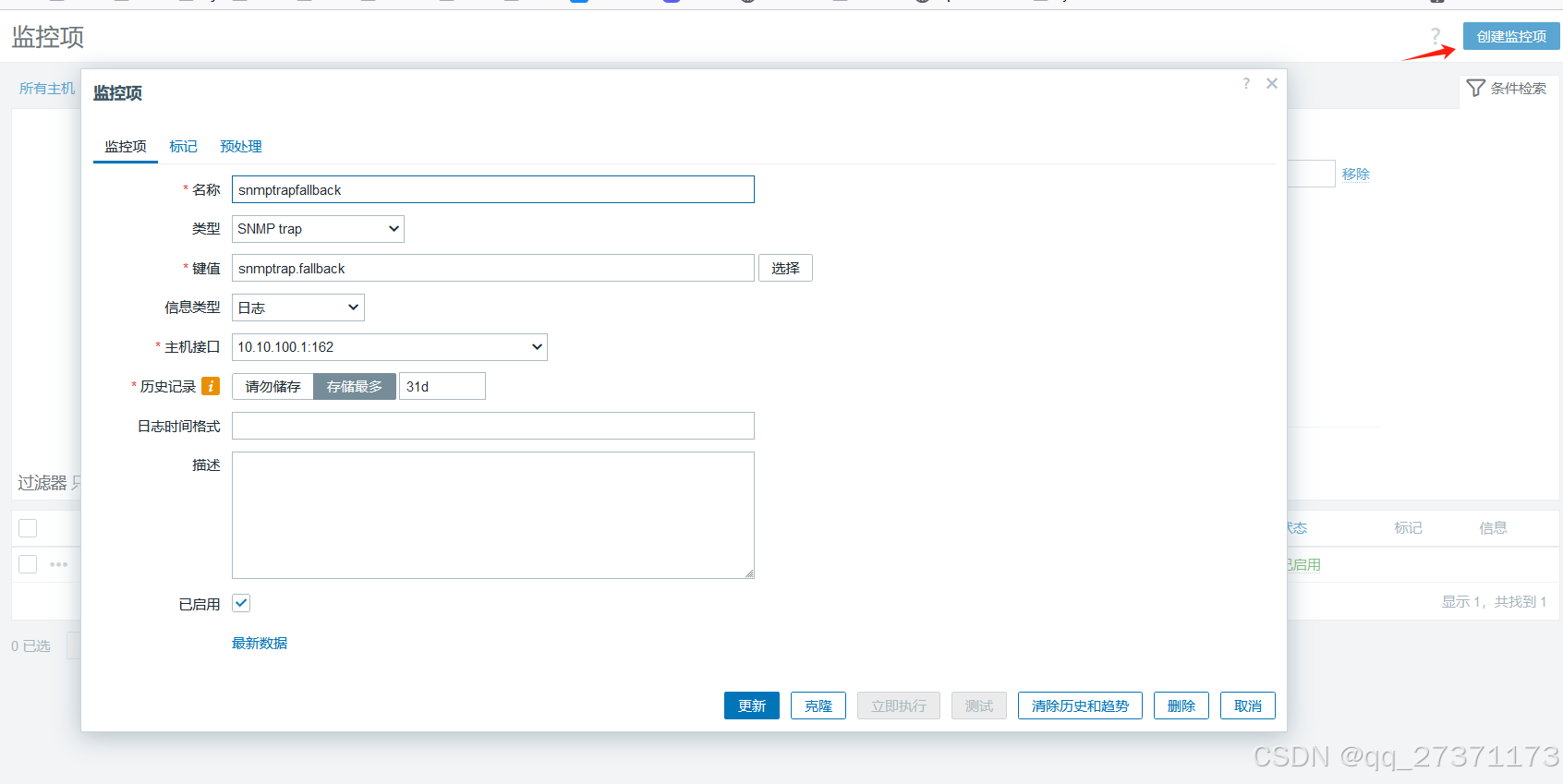
新增监控项
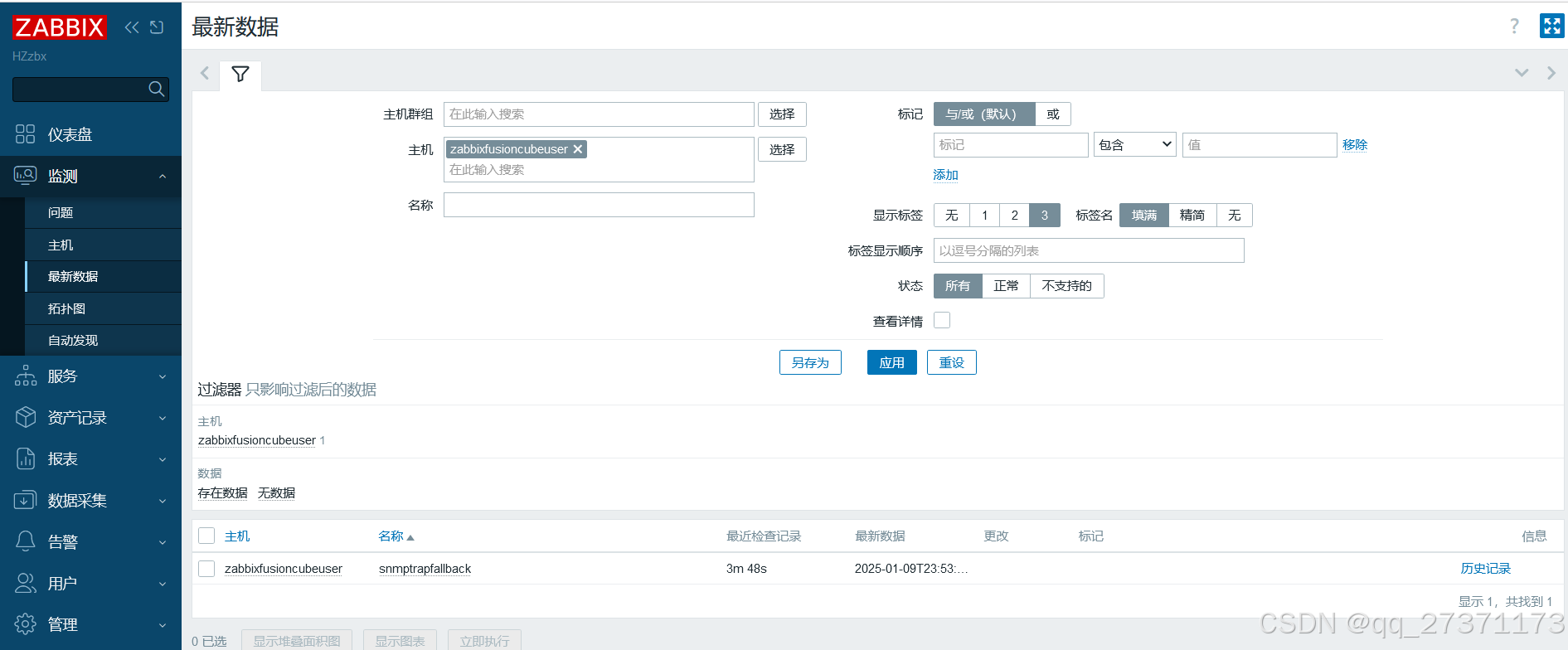
结果检查
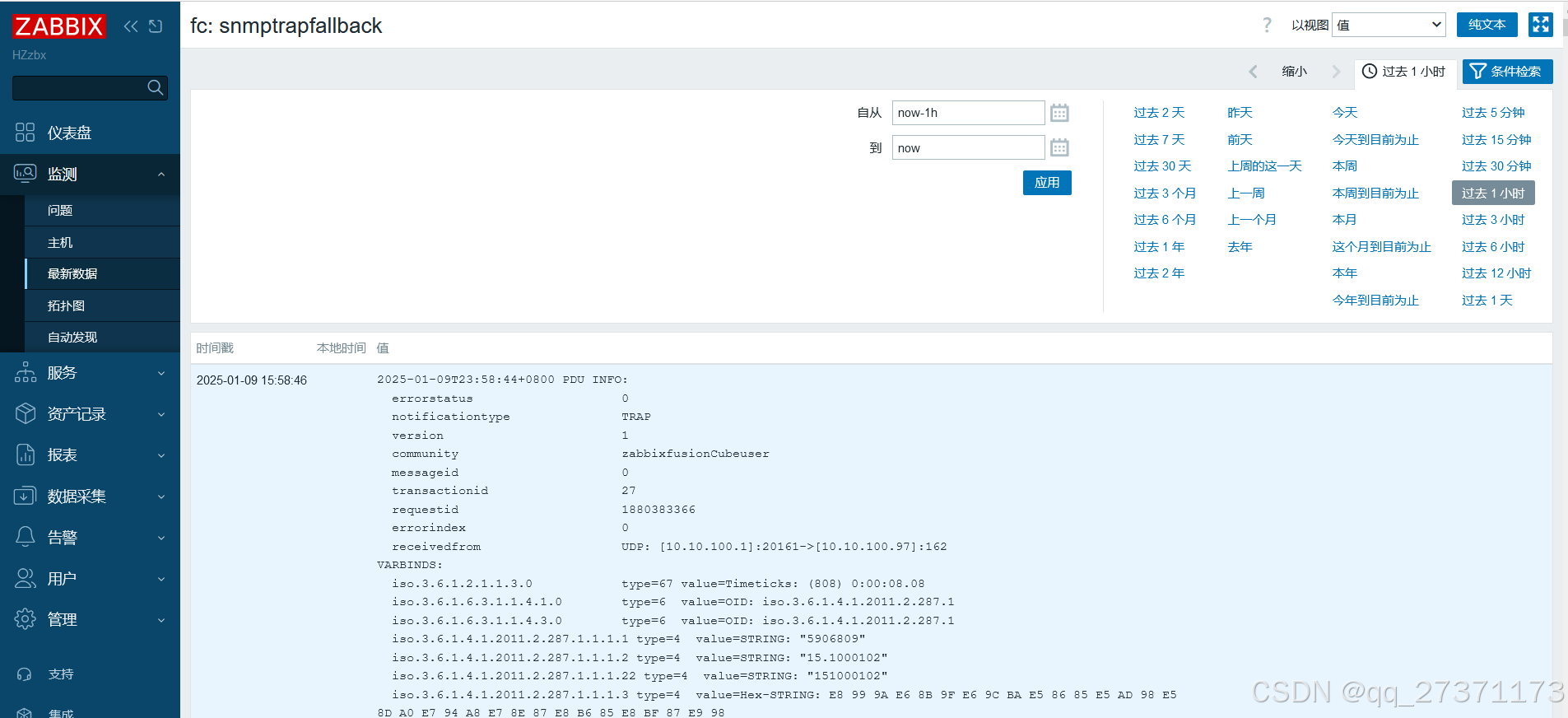
5.2 华为交换机配置可参考如下:
# 必须开启信息中心
info-center enable
# snmp配置 组zabbix,10.10.100.97,yourpassword 替换为你自己的组,snmp服务站,验证密码
snmp-agent sys-info version v3
snmp-agent group v3 zabbixgroup privacy read-view ViewDefault notify-view ViewDefault
snmp-agent usm-user v3 zabbixusers1
snmp-agent usm-user v3 zabbixusers1 group zabbixgroup
snmp-agent usm-user v3 zabbixusers1 authentication-mode sha 回车输入yourpassword
snmp-agent usm-user v3 zabbixusers1 privacy-mode aes128 回车输入yourpassword
# trap主机配置 如果选v3 snmptrapd里需要对每台交换机额外加一条命令
snmp-agent target-host trap address udp-domain 10.10.100.97 params securityname zabbixusers1 v2c ext-vb
#启用trap告警功能,enable后可以跟指定的模块,我这里是开所有的模块trap
snmp-agent trap enable
#有些交换机没这个命令,zabbix获取不到信息
snmp-agent protocol source-status all-interface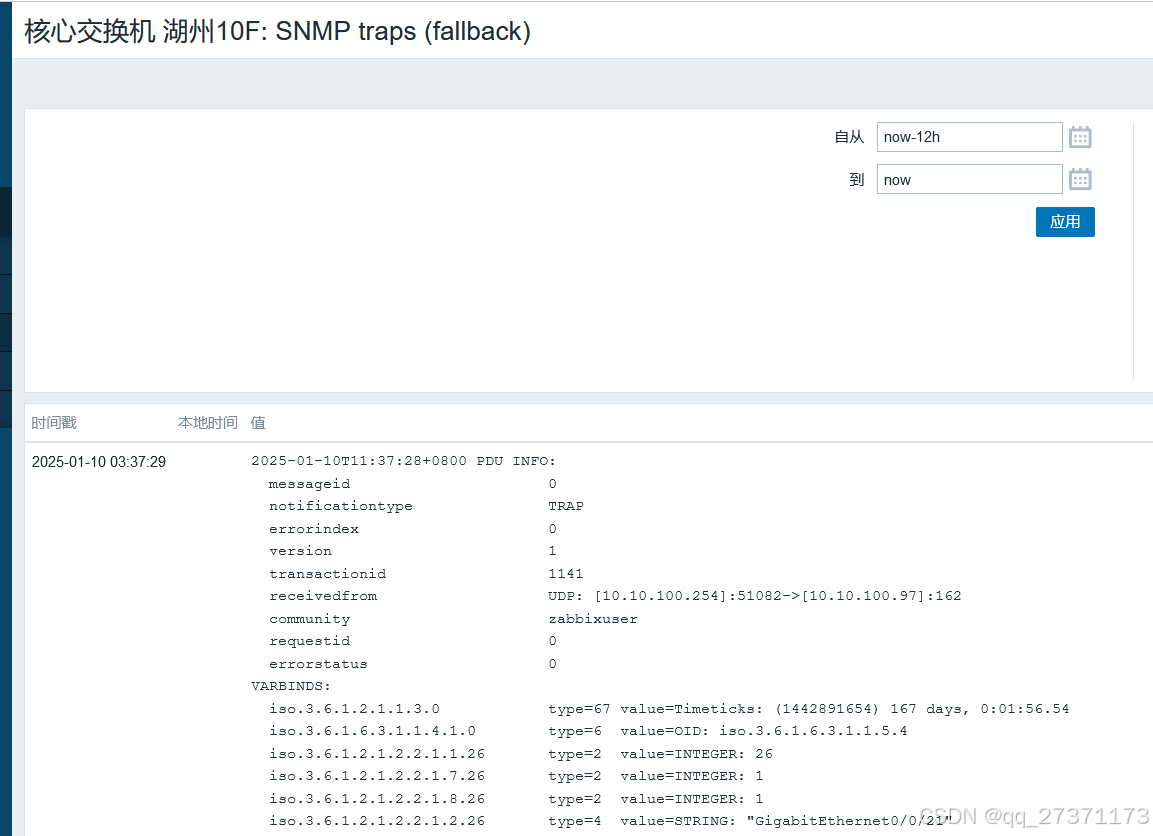
华为交换机官方trap无法获取信息异常排错参考连接:
https://support.huawei.com/enterprise/zh/doc/EDOC1100339648?section=j01y
六、mysql优化
编辑mysql配置文件(数据库推荐使用postgresql+timescaledb)
vim /etc/mysql/mysql.conf.d/mysqld.cnf
log-bin = mysql-bin
server-id = 97
innodb_buffer_pool_size = 6G
innodb_flush_log_at_trx_commit = 0
innodb_log_file_size = 256M
event_scheduler = ON
重启mysql
systemctl restart mysql
表分区我使用了如下两个链接的脚本,:
MariaDB mysql zabbix分区_zabbix mysql和mariadb-CSDN博客
PostgreSQL TimescaleDB zabbix分区_zabbix postgresql timescaledb-CSDN博客
分区脚本我已经在链接里弄下来了,如下创建个.sql文件复制进去并执行比如zbx.sql:
mysql -u 'zabbix' -p'zabbixDBpass' zabbix < zbx.sql
DELIMITER $$
CREATE PROCEDURE `partition_create`(SCHEMANAME varchar(64), TABLENAME varchar(64), PARTITIONNAME varchar(64), CLOCK int)
BEGIN
/*
SCHEMANAME = The DB schema in which to make changes
TABLENAME = The table with partitions to potentially delete
PARTITIONNAME = The name of the partition to create
*/
/*
Verify that the partition does not already exist
*/
DECLARE RETROWS INT;
SELECT COUNT(1) INTO RETROWS
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_description >= CLOCK;
IF RETROWS = 0 THEN
/*
1. Print a message indicating that a partition was created.
2. Create the SQL to create the partition.
3. Execute the SQL from #2.
*/
SELECT CONCAT( "partition_create(", SCHEMANAME, ",", TABLENAME, ",", PARTITIONNAME, ",", CLOCK, ")" ) AS msg;
SET @sql = CONCAT( 'ALTER TABLE ', SCHEMANAME, '.', TABLENAME, ' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', CLOCK, '));' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_drop`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), DELETE_BELOW_PARTITION_DATE BIGINT)
BEGIN
/*
SCHEMANAME = The DB schema in which to make changes
TABLENAME = The table with partitions to potentially delete
DELETE_BELOW_PARTITION_DATE = Delete any partitions with names that are dates older than this one (yyyy-mm-dd)
*/
DECLARE done INT DEFAULT FALSE;
DECLARE drop_part_name VARCHAR(16);
/*
Get a list of all the partitions that are older than the date
in DELETE_BELOW_PARTITION_DATE. All partitions are prefixed with
a "p", so use SUBSTRING TO get rid of that character.
*/
DECLARE myCursor CURSOR FOR
SELECT partition_name
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND CAST(SUBSTRING(partition_name FROM 2) AS UNSIGNED) < DELETE_BELOW_PARTITION_DATE;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
/*
Create the basics for when we need to drop the partition. Also, create
@drop_partitions to hold a comma-delimited list of all partitions that
should be deleted.
*/
SET @alter_header = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " DROP PARTITION ");
SET @drop_partitions = "";
/*
Start looping through all the partitions that are too old.
*/
OPEN myCursor;
read_loop: LOOP
FETCH myCursor INTO drop_part_name;
IF done THEN
LEAVE read_loop;
END IF;
SET @drop_partitions = IF(@drop_partitions = "", drop_part_name, CONCAT(@drop_partitions, ",", drop_part_name));
END LOOP;
IF @drop_partitions != "" THEN
/*
1. Build the SQL to drop all the necessary partitions.
2. Run the SQL to drop the partitions.
3. Print out the table partitions that were deleted.
*/
SET @full_sql = CONCAT(@alter_header, @drop_partitions, ";");
PREPARE STMT FROM @full_sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, @drop_partitions AS `partitions_deleted`;
ELSE
/*
No partitions are being deleted, so print out "N/A" (Not applicable) to indicate
that no changes were made.
*/
SELECT CONCAT(SCHEMANAME, ".", TABLENAME) AS `table`, "N/A" AS `partitions_deleted`;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_maintenance`(SCHEMA_NAME VARCHAR(32), TABLE_NAME VARCHAR(32), KEEP_DATA_DAYS INT, HOURLY_INTERVAL INT, CREATE_NEXT_INTERVALS INT)
BEGIN
DECLARE OLDER_THAN_PARTITION_DATE VARCHAR(16);
DECLARE PARTITION_NAME VARCHAR(16);
DECLARE OLD_PARTITION_NAME VARCHAR(16);
DECLARE LESS_THAN_TIMESTAMP INT;
DECLARE CUR_TIME INT;
CALL partition_verify(SCHEMA_NAME, TABLE_NAME, HOURLY_INTERVAL);
SET CUR_TIME = UNIX_TIMESTAMP(DATE_FORMAT(NOW(), '%Y-%m-%d 00:00:00'));
SET @__interval = 1;
create_loop: LOOP
IF @__interval > CREATE_NEXT_INTERVALS THEN
LEAVE create_loop;
END IF;
SET LESS_THAN_TIMESTAMP = CUR_TIME + (HOURLY_INTERVAL * @__interval * 3600);
SET PARTITION_NAME = FROM_UNIXTIME(CUR_TIME + HOURLY_INTERVAL * (@__interval - 1) * 3600, 'p%Y%m%d%H00');
IF(PARTITION_NAME != OLD_PARTITION_NAME) THEN
CALL partition_create(SCHEMA_NAME, TABLE_NAME, PARTITION_NAME, LESS_THAN_TIMESTAMP);
END IF;
SET @__interval=@__interval+1;
SET OLD_PARTITION_NAME = PARTITION_NAME;
END LOOP;
SET OLDER_THAN_PARTITION_DATE=DATE_FORMAT(DATE_SUB(NOW(), INTERVAL KEEP_DATA_DAYS DAY), '%Y%m%d0000');
CALL partition_drop(SCHEMA_NAME, TABLE_NAME, OLDER_THAN_PARTITION_DATE);
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_verify`(SCHEMANAME VARCHAR(64), TABLENAME VARCHAR(64), HOURLYINTERVAL INT(11))
BEGIN
DECLARE PARTITION_NAME VARCHAR(16);
DECLARE RETROWS INT(11);
DECLARE FUTURE_TIMESTAMP TIMESTAMP;
/*
* Check if any partitions exist for the given SCHEMANAME.TABLENAME.
*/
SELECT COUNT(1) INTO RETROWS
FROM information_schema.partitions
WHERE table_schema = SCHEMANAME AND table_name = TABLENAME AND partition_name IS NULL;
/*
* If partitions do not exist, go ahead and partition the table
*/
IF RETROWS = 1 THEN
/*
* Take the current date at 00:00:00 and add HOURLYINTERVAL to it. This is the timestamp below which we will store values.
* We begin partitioning based on the beginning of a day. This is because we don't want to generate a random partition
* that won't necessarily fall in line with the desired partition naming (ie: if the hour interval is 24 hours, we could
* end up creating a partition now named "p201403270600" when all other partitions will be like "p201403280000").
*/
SET FUTURE_TIMESTAMP = TIMESTAMPADD(HOUR, HOURLYINTERVAL, CONCAT(CURDATE(), " ", '00:00:00'));
SET PARTITION_NAME = DATE_FORMAT(CURDATE(), 'p%Y%m%d%H00');
-- Create the partitioning query
SET @__PARTITION_SQL = CONCAT("ALTER TABLE ", SCHEMANAME, ".", TABLENAME, " PARTITION BY RANGE(`clock`)");
SET @__PARTITION_SQL = CONCAT(@__PARTITION_SQL, "(PARTITION ", PARTITION_NAME, " VALUES LESS THAN (", UNIX_TIMESTAMP(FUTURE_TIMESTAMP), "));");
-- Run the partitioning query
PREPARE STMT FROM @__PARTITION_SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END$$
DELIMITER ;
DELIMITER $$
CREATE PROCEDURE `partition_maintenance_all`(SCHEMA_NAME VARCHAR(32))
BEGIN
CALL partition_maintenance(SCHEMA_NAME, 'history', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_log', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_str', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_text', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'history_uint', 7, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'trends', 365, 24, 3);
CALL partition_maintenance(SCHEMA_NAME, 'trends_uint', 365, 24, 3);
END$$
DELIMITER ;
创建每12小时执行一次的事件
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "CREATE EVENT zbx_partitioning ON SCHEDULE EVERY 12 HOUR DO CALL
partition_maintenance_all('zabbix');"检查是否成功
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "SELECT * FROM INFORMATION_SCHEMA.events\G"修改管家天数和分区脚本的一致,框里的都可以改

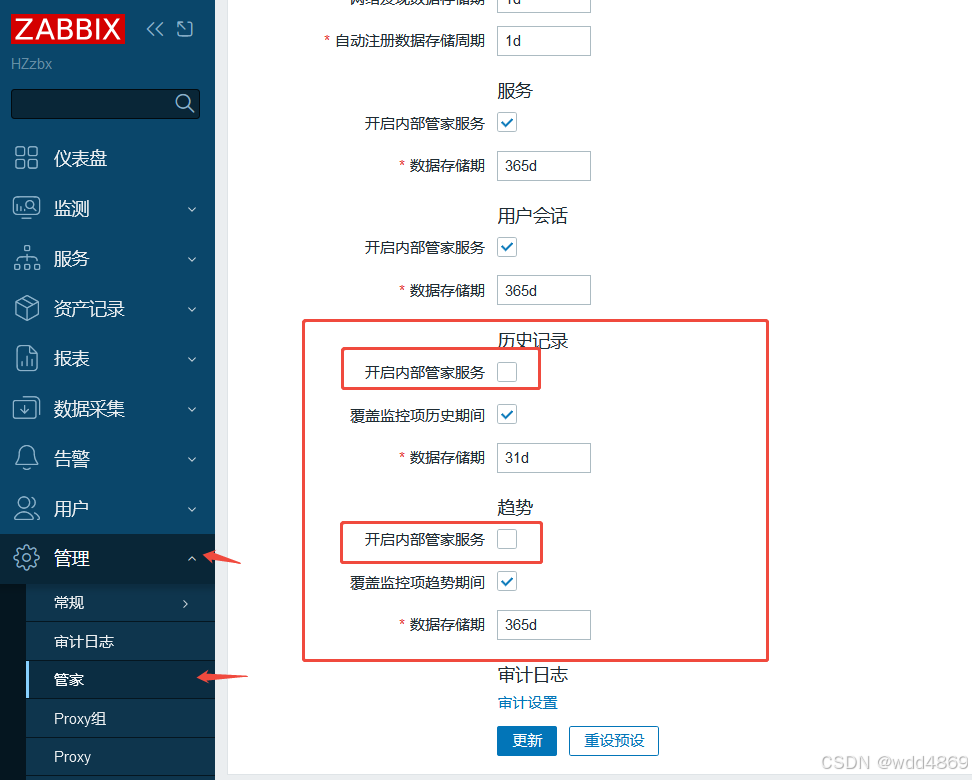
mysql -u 'zabbix' -p'zabbixDBpass' zabbix -e "ALTER EVENT zbx_partitioning ON SCHEDULE EVERY 12 HOUR DO CALL
partition_maintenance_all_30and400('zabbix');"
七、postgresql+timescledb 一主一从
7.1 postgresql和timescledb安装
参考链接:
https://docs.timescale.com/self-hosted/latest/install/installation-linux/
http://www.postgres.cn/docs/current/warm-standby.html#FILE-STANDBY-SIGNAL
安装最新的PostgreSQL软件包
sudo apt install gnupg postgresql-common apt-transport-https lsb-release wget
运行PostgreSQL包设置脚本
sudo /usr/share/postgresql-common/pgdg/apt.postgresql.org.sh
添加TimescaleDB包
echo "deb https://packagecloud.io/timescale/timescaledb/ubuntu/ $(lsb_release -c -s) main" | sudo tee /etc/apt/sources.list.d/timescaledb.list
安装TimescaleDB GPG密钥
wget --quiet -O - https://packagecloud.io/timescale/timescaledb/gpgkey | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/timescaledb.gpg
更新本地存储库列表
sudo apt update
安装TimescaleDB
sudo apt install timescaledb-2-postgresql-17 postgresql-client-17
为TimescaleDB调优PostgreSQL实例
sudo timescaledb-tune
重启并登录到PostgreSQL
sudo systemctl restart postgresql
sudo -u postgres psql
将TimescaleDB添加到数据库
CREATE EXTENSION IF NOT EXISTS timescaledb;
您可以看到已安装的扩展列表
\dx7.2 主库设置
vim /etc/postgresql/17/main/postgresql.conf
# 启用WAL日志归档
wal_level = replica
# 允许最多5个从库连接
max_wal_senders = 5
#所有ip可远程登陆
listen_addresses = '*'
#主数据库上保留的 WAL 日志的最小大小,以MB为单位
wal_keep_size = 1GB
# 开启同步提交,off是异步提交
synchronous_commit = on
#同步提交必须配置,异步提交不需要,同步提交建议2个备库
synchronous_standby_names = 'wdd1'
shared_preload_libraries = 'timescaledb'vim /etc/postgresql/17/main/pg_hba.conf
# 允许从库复制的ip和用户
host replication zabbix 192.168.11.12/32 md5
host all zabbix 192.168.11.12/32 scram-sha-256创建用户
创建具有复制权限的用户
CREATE USER zabbix WITH REPLICATION ENCRYPTED PASSWORD 'admin';
在主库执行以下 SQL 检查用户是否有复制权限(userepl 应为 t(表示有复制权限):
SELECT usename, userepl FROM pg_user WHERE usename = 'zabbix';
权限不对可以 修改用户赋予复制权限
ALTER USER zabbix WITH REPLICATION; 重启服务
systemctl restart postgresql
7.3 从库设置
停止服务
systemctl stop postgresql
删除数据文件夹
rm -rf /var/lib/postgresql/17/main
初始备份
sudo -u postgres
pg_basebackup -h 192.168.11.11 -D /var/lib/postgresql/17/main -U zabbix -P -R --wal-method=stream --create-slot --slot=copyslot1
可以看到standby.signal文件
ll /var/lib/postgresql/17/main
同步提交需设置application_name=wdd1
vim /var/lib/postgresql/17/main/postgresql.auto.conf

vim /etc/postgresql/17/main/postgresql.conf
设置只读
hot_standby = on
#所有ip可远程登陆
listen_addresses = '*'
重启服务
systemctl restart postgresql7.4 检查
主库检查状态,能看到从库信息
SELECT client_addr,application_name, sync_state FROM pg_stat_replication;
判断数据库是否为主库 f 表示是主库,t 表示属于备库角色
select pg_is_in_recovery();
执行以下命令,检查WAL发送进程的状态:应该能看到一个或多个WAL发送进程正在运行。
ps aux | grep wal_sender
检查日志槽
SELECT slot_name,plugin,slot_type,database,active,restart_lsn FROM pg_replication_slots;
7.5 zabbix表转换为超表
zabbix手册页:
6 TimescaleDB 配置
在导入初始架构和数据后通过执行以下命令为特定的数据库启用 TimescaleDB 扩展
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix对于新安装,运行 postgresql/timescaledb/schema.sql 脚本。 该脚本必须在使用初始模式/数据创建常规 PostgreSQL 数据库之后运行
cat /usr/share/zabbix/sql-scripts/postgresql/timescaledb/schema.sql | sudo -u zabbix psql zabbix登录数据库查看是否有超表
sudo -su postgres psql
\c zabbix
SELECT hypertable_name FROM timescaledb_information.hypertables; 查看是否超表
7.6 pgpool4.6配置
vim /etc/pgpool2/pgpool.conf
listen_addresses = '*'
port = 9999
logging_collector = on
log_directory = '/var/log/pgpool2'
log_filename = 'pgpool.log'
log_file_mode = 0600
log_line_prefix = '%m: %a pid %p: '
log_connections = on
log_disconnections = on
log_pcp_processes = on
log_hostname = on
log_client_messages = on
log_min_messages = warning
backend_hostname0 = '192.168.11.11'
backend_port0 = 5432
backend_weight0 = 0
backend_data_directory0 = '/var/lib/postgresql/17/main'
backend_flag0 = 'ALWAYS_PRIMARY'
backend_application_name0 = 'master1'
backend_hostname1 = '192.168.11.12'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/var/lib/postgresql/17/main'
backend_flag1 = 'DISALLOW_TO_FAILOVER'
backend_application_name0 = 'slave1'
enable_pool_hba = on
pool_passwd = 'pool_passwd'
authentication_timeout = 1min
load_balance_mode = on
# 流复制检查,延迟检查用户和密码
sr_check_user = 'pgpool'
sr_check_password = ''
# 健康检查
health_check_user = 'pgpool'
health_check_password = ''
health_check_period = 10
health_check_timeout = 30
health_check_max_retries = 3
pcp_listen_addresses = '*'
pcp_port = 9898
ssl = off
# 创建日志文件,可以使用自带的日志轮转或linux的
mkdir /var/log/pgpool2
touch /var/log/pgpool2/pgpool.log
chmod 777 /var/log/pgpool2/pgpool.log
# 使用的加密协议需要和数据库一样比如都是scram-sha-256
vim /etc/pgpool2/pool_hba.conf
host all all 192.168.11.0/24 scram-sha-256
host all all 192.168.11.0/24 scram-sha-256
#创建解密密钥文件 scram-sha-256加密需要
[root@server1 ~]# su - postgres -c "echo 'some string' > ~/.pgpoolkey"
[root@server1 ~]# su - postgres -c "chmod 600 ~/.pgpoolkey"
下面两个命令分别写入md5 和scram-sha-256加密密码
pg_enc -m -k /var/lib/postgresql/.pgpoolkey -u zbx -p
pg_md5 -m -u scopy -p
cat /etc/pgpool-II/pool_passwd
vim /etc/pgpool2/pool_passwd
systemctl restart pgpool2
创建健康检查和流复制状态检查用户
CREATE USER pgpool WITH PASSWORD 'admin';
GRANT pg_monitor TO pgpool;
创建zabbix连接数据库用户
sudo -u postgres createuser --pwprompt zabbix
创建postgresql流复制用户
CREATE USER zbx WITH REPLICATION ENCRYPTED PASSWORD 'admin';
















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









