





xarray数据结构之Dataset
xarray.Dataset 是的多维xarray,等效于DataFrame. 它是类似于字典的具有对齐维度的标记数组 (DataArray 对象) ,被设计为netCDF文件格式的数据模型的内存表示形式。
除了数据集本身类似于字典的接口界面(用于访问数据集中的任何变量)外,数据集还具有四个关键属性:
dims: 从维度名称到每个维度的固定长度的映射字典(例如,{‘x’: 6, ‘y’: 6, ‘time’: 8})data_vars:类似于字典的DataArrays容器,对应于变量coords: 另一个类似dict的DataArray容器,用于标记data_vars中使用的点(例如,数字,日期时间对象或字符串形式的数组)attrs: 包含任意元数据的字典
变量(variables)是落入数据还是坐标(从CF conventions中借用)之间的区别主要是语义上的,如果愿意,完全可以忽略它:在任一类别中像字典一样访问数据集都可以找到变量。 但是,xarray确实将区别用于索引和计算。 坐标(Coordinates)表示恒定/固定/独立的量,与数据中变化/测量/独立的量不同。
下图为一个示例,可以说明如何构建天气预报的数据集(dataset):
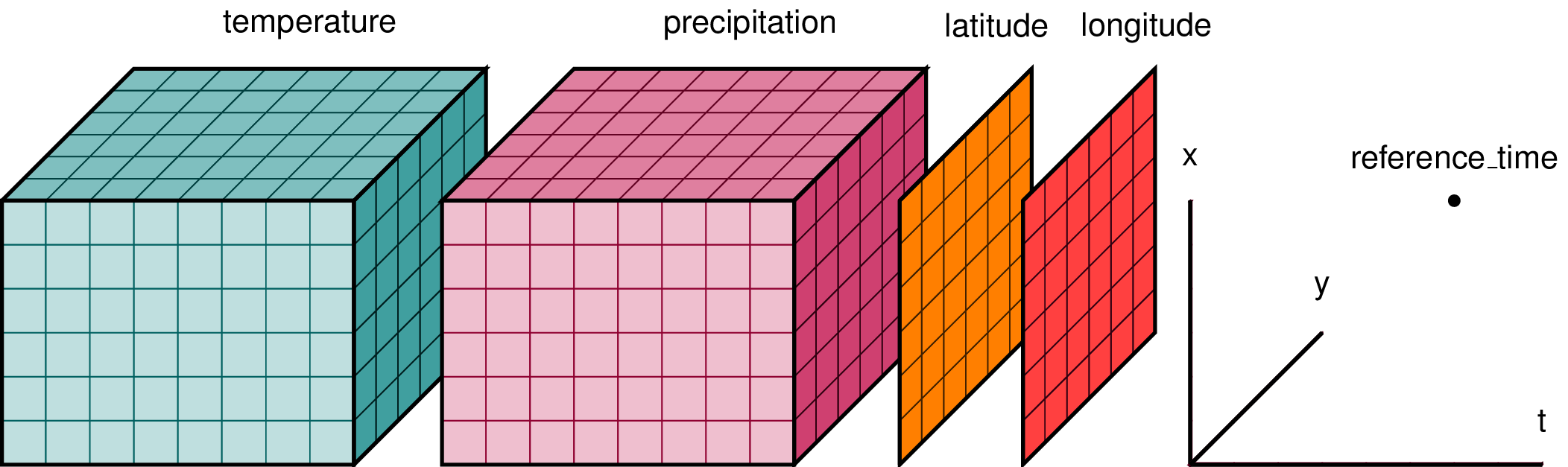
在上图示例中,很自然地将temperature 和 precipitation 称为“数据变量”,将所有其他数组称为“坐标变量”,因为它们沿维度标注了点。(有关此示例的更多背景信息,请参见1)。
创建Dataset
要从头开始创建数据集(Dataset),需要提供所有变量(data_vars),坐标(coords)和属性(attrs)的字典。
data_vars应该是一个字典,每个键为变量的名称,每个值为以下之一:- 一个
DataArray或Variable - 格式为
(dims, data[, attrs])的元组,将会将其转换为Variable的参数 - 一个pandas的对象,将会转化为
DataArray - 一维数组或列表,被解释为一维坐标变量的值,及与其对应的维度名称
- 一个
coords需是与data_vars格式相同的字典。attrs: 需为一个字典。
让我们为上图所展示的示例,创建一些虚假数据:
In [32]: precip = 10 * np.random.rand(2, 2, 3)
In [33]: lon = [[-99.83, -99.32], [-99.79, -99.23]]
In [34]: lat = [[42.25, 42.21], [42.63, 42.59]]
# for real use cases, its good practice to supply array attributes such as
# units, but we won't bother here for the sake of brevity
In [35]: ds = xr.Dataset({'temperature': (['x', 'y', 'time'], temp),
....: 'precipitation': (['x', 'y', 'time'], precip)},
....: coords={'lon': (['x', 'y'], lon),
....: 'lat': (['x', 'y'], lat),
....: 'time': pd.date_range('2014-09-06', periods=3),
....: 'reference_time': pd.Timestamp('2014-09-05')})
....:
In [36]: ds
Out[36]:
<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 11.04 23.57 20.77 ... 6.301 9.61 15.91
precipitation (x, y, time) float64 5.904 2.453 3.404 ... 3.435 1.709 3.947
在这里,我们将xarray.DataArray对象或pandas对象作为字典中的值传递:
In [37]: xr.Dataset({'bar': foo})
Out[37]:
<xarray.Dataset>
Dimensions: (space: 3, time: 4)
Coordinates:
* time (time) datetime64[ns] 2000-01-01 2000-01-02 2000-01-03 2000-01-04
* space (space) <U2 'IA' 'IL' 'IN'
Data variables:
bar (time, space) float64 0.127 0.9667 0.2605 ... 0.543 0.373 0.448
In [38]: xr.Dataset({'bar': foo.to_pandas()})
Out[38]:
<xarray.Dataset>
Dimensions: (space: 3, time: 4)
Coordinates:
* time (time) datetime64[ns] 2000-01-01 2000-01-02 2000-01-03 2000-01-04
* space (space) object 'IA' 'IL' 'IN'
Data variables:
bar (time, space) float64 0.127 0.9667 0.2605 ... 0.543 0.373 0.448
如果将·pandas·对象作为值提供,则将其索引的名称将用作维度的名称,并将其数据与任何现有维对齐。
还可以创建数据集通过:
- 一个
pandas.DataFrame或pandas.Panel分别沿其列和项目放置,将其直接传递到数据集(Dataset)中。 Dataset.from_dataframe格式的pandas.DataFrame,它将另外处理MultiIndexes,请参阅Working with pandas- 以
open_dataset()打开的磁盘上的netCDF文件。 请参阅读Reading and writing files.。
Dataset内容(contents)
Dataset实现了Python映射接口,其值由xarray.DataArray对象给出:
In [39]: 'temperature' in ds
Out[39]: True
In [40]: ds['temperature']
Out[40]:
<xarray.DataArray 'temperature' (x: 2, y: 2, time: 3)>
array([[[11.041, 23.574, 20.772],
[ 9.346, 6.683, 17.175]],
[[11.6 , 19.536, 17.21 ],
[ 6.301, 9.61 , 15.909]]])
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
Dimensions without coordinates: x, y
有效键包括列出的每个坐标和数据变量。
数据和坐标变量也分别包含在data_vars和coords的类似字典的属性中:
In [41]: ds.data_vars
Out[41]:
Data variables:
temperature (x, y, time) float64 11.04 23.57 20.77 ... 6.301 9.61 15.91
precipitation (x, y, time) float64 5.904 2.453 3.404 ... 3.435 1.709 3.947
In [42]: ds.coords
Out[42]:
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
最后,像数据数组一样,数据集还以属性的形式存储任意元数据:
In [43]: ds.attrs
Out[43]: {}
In [44]: ds.attrs['title'] = 'example attribute'
In [45]: ds
Out[45]:
<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 11.04 23.57 20.77 ... 6.301 9.61 15.91
precipitation (x, y, time) float64 5.904 2.453 3.404 ... 3.435 1.709 3.947
Attributes:
title: example attribute
xarray对属性没有任何限制,但是如果您使用的对象不是字符串,数字或numpy.ndarray对象,则序列化为某些文件格式可能会失败。
作为非常有用的快捷方式,您可以使用属性样式访问来读取(但不能设置)变量和属性:
In [46]: ds.temperature
Out[46]:
<xarray.DataArray 'temperature' (x: 2, y: 2, time: 3)>
array([[[11.041, 23.574, 20.772],
[ 9.346, 6.683, 17.175]],
[[11.6 , 19.536, 17.21 ],
[ 6.301, 9.61 , 15.909]]])
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
Dimensions without coordinates: x, y
这在探索性上下文中特别有用,因为可以使用IPython之类的工具,将这些变量名通过制表符(tab键)填充完整。
类似字典的方法
我们可以使用Python的标准字典语法就地更新数据集。 例如,要从头开始创建此示例数据集,我们可以这样写:
In [47]: ds = xr.Dataset()
In [48]: ds['temperature'] = (('x', 'y', 'time'), temp)
In [49]: ds['temperature_double'] = (('x', 'y', 'time'), temp * 2 )
In [50]: ds['precipitation'] = (('x', 'y', 'time'), precip)
In [51]: ds.coords['lat'] = (('x', 'y'), lat)
In [52]: ds.coords['lon'] = (('x', 'y'), lon)
In [53]: ds.coords['time'] = pd.date_range('2014-09-06', periods=3)
In [54]: ds.coords['reference_time'] = pd.Timestamp('2014-09-05')
要更改数据集(Dataset)中的变量,可以使用所有标准的字典方法,包括values, items, __delitem__, get 和 update()。 请注意,使用__setitem__或update将DataArray或pandas对象分配给Dataset变量将自动(automatically align)使数组与原始数据集的索引对齐。
可以通过调用copy()方法来复制数据集(Dataset)。 默认情况下,副本是浅拷贝,因此将只复制容器:数据集(Dataset)中的数组仍将存储在相同的numpy.ndarray对象中。 可以通过调用ds.copy(deep=True)复制所有数据。
转换数据集
除了类似字典的方法(如上所述)之外,xarray还有其他方法(类似pandas)用于将数据集转换为新对象。
要删除变量,可以通过使用名称列表建立索引或使用drop_vars()方法返回新的Dataset,来选择和丢弃一个显式的列表变量。 这些操作会保留坐标:
In [55]: ds[['temperature']]
Out[55]:
<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 11.04 23.57 20.77 ... 6.301 9.61 15.91
In [56]: ds[['temperature', 'temperature_double']]
Out[56]:
<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 11.04 23.57 20.77 ... 9.61 15.91
temperature_double (x, y, time) float64 22.08 47.15 41.54 ... 19.22 31.82
In [57]: ds.drop_vars('temperature')
Out[57]:
<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
Dimensions without coordinates: x, y
Data variables:
temperature_double (x, y, time) float64 22.08 47.15 41.54 ... 19.22 31.82
precipitation (x, y, time) float64 5.904 2.453 3.404 ... 1.709 3.947
要删除维度,可以使用drop_dims()方法。 使用该维度的所有变量都会被删除:
In [58]: ds.drop_dims('time')
Out[58]:
<xarray.Dataset>
Dimensions: (x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
reference_time datetime64[ns] 2014-09-05
Dimensions without coordinates: x, y
Data variables:
*empty*
作为类似字典修改的替代方法,可以使用assign()和assign_coords()。 这些方法返回具有其他(或替换)值的新数据集:
In [59]: ds.assign(temperature2 = 2 * ds.temperature)
Out[59]:
<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 11.04 23.57 20.77 ... 9.61 15.91
temperature_double (x, y, time) float64 22.08 47.15 41.54 ... 19.22 31.82
precipitation (x, y, time) float64 5.904 2.453 3.404 ... 1.709 3.947
temperature2 (x, y, time) float64 22.08 47.15 41.54 ... 19.22 31.82
还有pipe()方法,允许使用带有外部函数的方法调用(例如,ds.pipe(func)),而不是简单地调用它(例如,func(ds))。 这使您可以编写管道(使用“方法链”)进行转换数据,而不需费力地以遵循嵌套函数的方式进行调用:
# these lines are equivalent, but with pipe we can make the logic flow
# entirely from left to right
In [60]: plt.plot((2 * ds.temperature.sel(x=0)).mean('y'))
Out[60]: [<matplotlib.lines.Line2D at 0x7fc31240ad50>]
In [61]: (ds.temperature
....: .sel(x=0)
....: .pipe(lambda x: 2 * x)
....: .mean('y')
....: .pipe(plt.plot))
....:
Out[61]: [<matplotlib.lines.Line2D at 0x7fc307e5d210>]
管道(pipe)和分配(assign)都复制具有相同名称(DataFrame.pipe和DataFrame.assign)的pandas方法。
使用xarray,即使从磁盘上的文件延迟加载变量,创建新数据集也不会降低性能。 创建新对象而非去对现有对象进行改造,通常会使代码更易于理解,因此我们鼓励使用这种方法。
重命名变量
另一个有用的选项是rename()方法,来重命名数据集变量:
Out[62]:
<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
Dimensions without coordinates: x, y
Data variables:
temp (x, y, time) float64 11.04 23.57 20.77 ... 9.61 15.91
temperature_double (x, y, time) float64 22.08 47.15 41.54 ... 19.22 31.82
precip (x, y, time) float64 5.904 2.453 3.404 ... 1.709 3.947
相关的swap_dims()方法允许您交换维度和非维度变量:
In [63]: ds.coords['day'] = ('time', [6, 7, 8])
In [64]: ds.swap_dims({'time': 'day'})
Out[64]:
<xarray.Dataset>
Dimensions: (day: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
time (day) datetime64[ns] 2014-09-06 2014-09-07 2014-09-08
reference_time datetime64[ns] 2014-09-05
* day (day) int64 6 7 8
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, day) float64 11.04 23.57 20.77 ... 9.61 15.91
temperature_double (x, y, day) float64 22.08 47.15 41.54 ... 19.22 31.82
precipitation (x, y, day) float64 5.904 2.453 3.404 ... 1.709 3.947


















 4225
4225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









