






写了这么久的公众号,关于python这一块还是比较少的。以后有空再更新编程这一块吧,短期内都是以算法思想和实现为主。今天小编就补充一些,话不多说,进入正题。

迭代器&生成器
迭代器和生成器是一种节省内存的对象,它是指具备next()方法的可迭代对象(可用于for循环)。迭代器创建有两种方法,第一种是推导式生成:
ge = (i for i in range(10))
第二种是使用关键字yield创建:
def my_ge(num):
i = 0
while i < num:
yield(i) # 也可以写成 yield i
i += 1
a = my_ge(8)
try:
while True:
# r = next(a)
r = a.__next__()
print(r)
except StopIteration as e:
print('loop over')
pass
上面的函数遇到yield后,说明这个函数是生成器,关键字yield的作用,与return功能相当。上面生成器的执行逻辑是:
step1:遇到yield,暂停函数的执行
step2:返回yield的值
step3:等待下一次激活(遇到next方法)
当前,生成器直接使用for循环也是可以的。

装饰器
装饰器本质是函数,它的作用是不改变原函数的代码和调用方式的前提下,给函数添加附加功能。
用一个例子就能说明白装饰器的内涵:
def a(fun):
def pig():
print('-----111-----')
fun()
print('-----222-----')
return pig
@a #相当b=a(b)
def b():
print('-----000-----')
b()
这里,我们要对函数b添加一些功能——在打印函数b内容的前后打印其他内容。我们引进函数a来打印这些内容,然后利用关键词@在函数b上面添加a。这样在执行函数b时,把b传进fun函数执行了。可以看到执行效果:
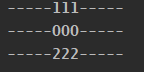
这就是装饰器的作用。装饰器用得最多的是在类方法里面,主要有三个:
@property 将类方法变成属性
@classmethod 返回的值传给初始化方法
@staticmethod 使得可以被类内其他实例调用
举个例子就能明白了:
class A():
def __init__(self,a,b):
self.a = a
self._b = b
@classmethod
def G(cls,n): #该函数想调用类内其他函数,必须使用静态方法staticmethod
print(cls.H(n))
return cls(n,n*n) #返回的参数传给__init__函数的参数
@staticmethod #可以被类内其他实例调用,包括cls
def H(m):
return 2*m
def K(self,k): #不可以被cls调用
return k+1
@property
def P(self):
return 0
对于类A,要传入初始化对象a和b,但可以延迟传入,通过@classmethod装饰的函数返回结果传入:
a = A
r = a.G(6)
print(r._b) #结果是12
print(r.a) #结果是36
print(r.P) #结果是0
类内方法P原本引用需要加括号,因为声明为属性,所有不用加属性即可完成调用。

魔术方法
在类中,前后带有双下划线的函数称为魔术方法——__名字__
随便举几个例子:
__init__:初始化方法
__call__:实例对象调用时触发方法
__getitem__:索引化方法
__len__:实例长度方法
class A():
def __init__(self,a,b):
self.a = a
self.b = b
def __str__(self):
return '干嘛打印我'
def __repr__(self):
return '你在打印实例'
def __call__(self):
return '实例调用了'
def __getitem__(self, item):
return item+1
def __len__(self):
return 8
执行下面语句:
a = A(1,2)
print('打印实例方法str or repr:') #先调用str方法,没有调用repr方法,否则打印地址
print(a)
print('调用实例化方法call:',a())
print('调用长度方法len:',len(a))
print('调用索引方法getitem:',a[2])
结果为:

最后还要说一下super().__init__()方法的作用,它表示继承父类的初始化方法,把里面的内容都继承过来
class A():
def __init__(self):
self.a = 5
self.b = 3
class B(A):
def __init__(self,c):
super().__init__()
self.c = c
实例化B后,实例有a,b,c的三个属性;如果不带super().__init__,类A的初始化方法会被B覆盖,也即只有c属性。

多进程&多线程训练模型
在训练模型或者批量生成一些数据时,需要提高效率。这时候需要用到多线程和进程,在2018年更新的一篇文章中,小编详细介绍了两者的区别和用法。
传送门:线程、进程与并发通信
这里介绍一个例子,把线程和进程结合起来,以便最大限度利用做多的资源去更新所需要的任务:
from multiprocessing import Pool #导入进程池
from threading import Thread #导入线程
class Mythreading(Thread):
def __init__(self, a):
super().__init__()
self.a = a
def run(self):
self.P = self.a + 1
def get_result(self):
return self.P
def Process_train(m, batch, a):
print('进程',m)
user_recommand = dict()
Th_li = [] # 接收线程实例
for user in range(batch):
t = Mythreading(a)
Th_li.append(t)
t.start()
for n, user in enumerate(batch):
Th_li[n].join()
user_recommand[user] = Th_li[n].get_result()
return user_recommand
if __name__ == '__main__':
pool = Pool(5) # 进程数
n_count = 10 # 线程数
a = 1
for m in range(1000):
pool.apply_async(func=Process_train, args=(m, n_count,a,))
pool.close()
pool.join()
















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











