







MongDB 综合概述
什么是NoSql
NoSQL:Not Only SQL ,本质也是一种数据库的技术,相对于传统数据库技术,它不会遵循一些约束,比如:sql标准、ACID属性,表结构等。
Nosql优点
l 满足对数据库的高并发读写
l 对海量数据的高效存储和访问
l 对数据库高扩展性和高可用性
l 灵活的数据结构,满足数据结构不固定的场景
Nosql缺点
l 一般不支持事务
l 实现复杂SQL查询比较复杂
l 运维人员数据维护门槛较高
l 目前不是主流的数据库技术
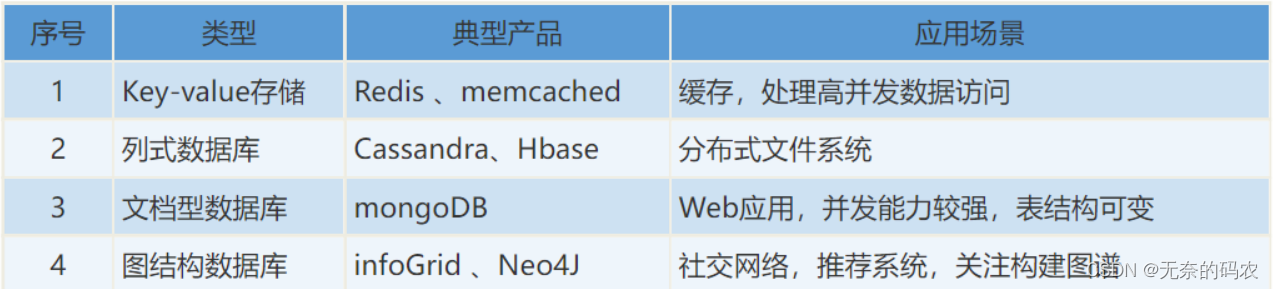
NoSql分类
MongoDb概念
什么是MongoDB
MongoDB:是一个数据库 ,高性能、无模式、文档性,目前nosql中最热门的数据库,开源产品,基于c++开发。是nosql数据库中功能最丰富,最像关系数据库的。
特性
l 面向集合文档的存储:适合存储Bson(json的扩展)形式的数据;
l 格式自由,数据格式不固定,生产环境下修改结构都可以不影响程序运行;
l 强大的查询语句,面向对象的查询语言,基本覆盖sql语言所有能力;
l 完整的索引支持,支持查询计划;
l 支持复制和自动故障转移;
l 支持二进制数据及大型对象(文件)的高效存储;
l 使用分片集群提升系统扩展性;
l 使用内存映射存储引擎,把磁盘的IO操作转换成为内存的操作;
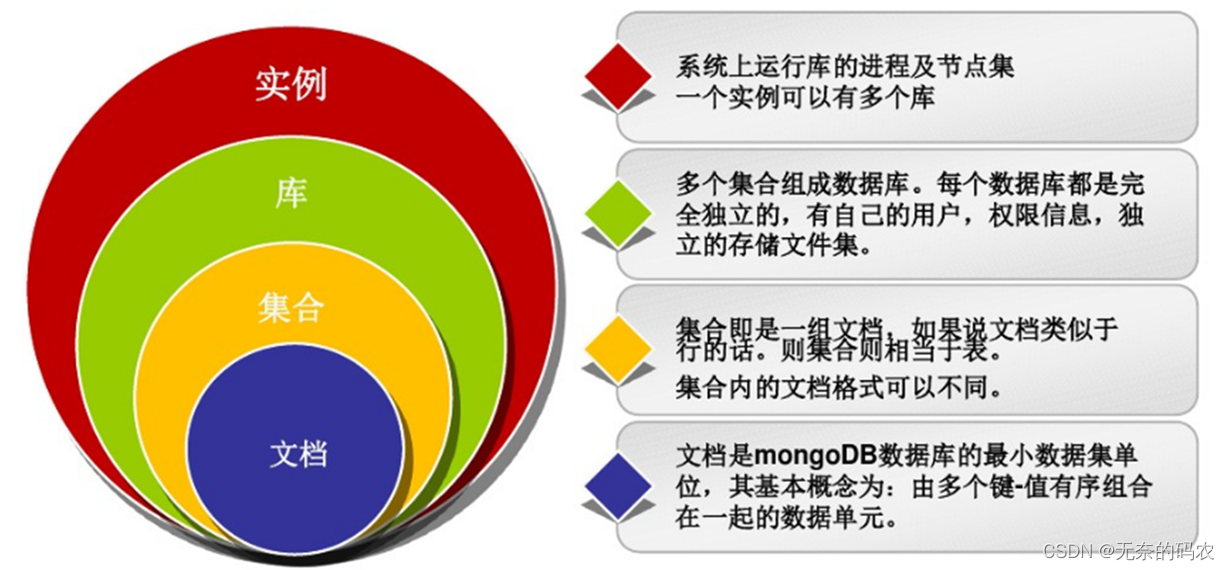
MongoDB核心概念
MongoDb应用与开发
Mongodb安装
l 官网下载安装介质:
Try MongoDB Atlas Products | MongoDB
选择对应的版本
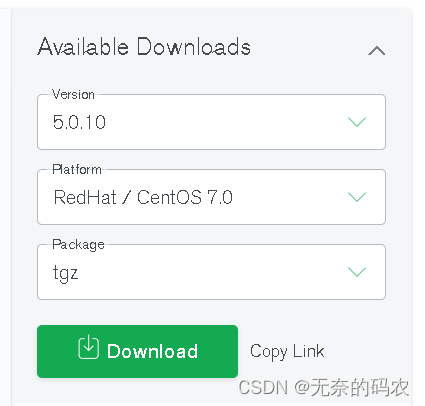
查找对应的小版本
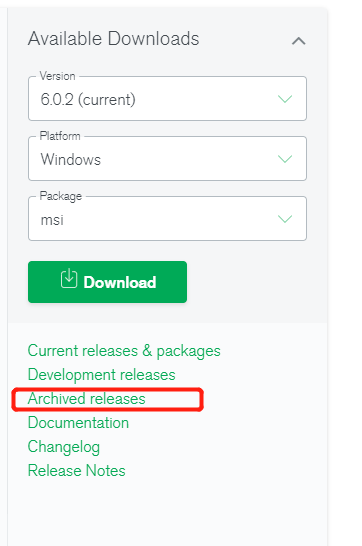
选择对应的linux系统和archive的tar包
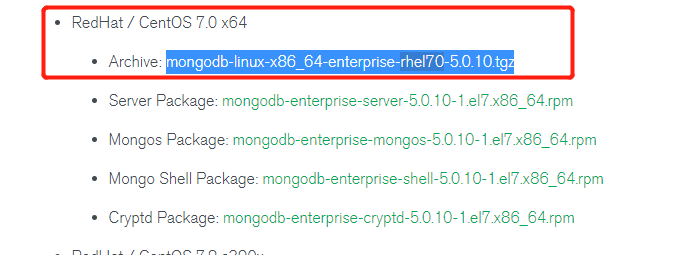
wget 获取mongo的安装包
- 右键复制上一步的连接地址,如https://downloads.mongodb.com/linux/mongodb-linux-x86_64-enterprise-rhel70-5.0.10.tgz?_ga=2.209676306.1008716324.1664500691-1752158045.1649669493
- 把问号后面无用的删掉 如:https://downloads.mongodb.com/linux/mongodb-linux-x86_64-enterprise-rhel70-5.0.10.tgz
- 使用wget获取,如
wget https://downloads.mongodb.com/linux/mongodb-linux-x86_64-enterprise-rhel70-5.0.10.tgz
上传到服务器上
对压缩包进行解压
tar -zxvf mongodb-linux-x86_64-rhel70-5.0.10.tgz
然后开始配置环境变量,追加环境变量以冒号隔开:
PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin:/opt/common/mongodb/bin
vi /etc/profile

配置好环境变量之后,再mongo本目录,新建mongo-home 文件夹,用来存放数据和日志
mkdir mongo-home
#进入mongo-home
cd mongo-home
#继续创建data数据存放和log日志文件
mkdir data
mkdir logs
创建好文件之后,启动mongo
mongod --dbpath /opt/common/mongodb/mongo-home/data/ --logpath /opt/common/mongodb/mongo-home/logs/mongodb.log --fork
启动后查看,ps -ef | grep mongo 查看是否启动成功
启动成功后,直接输入mongo
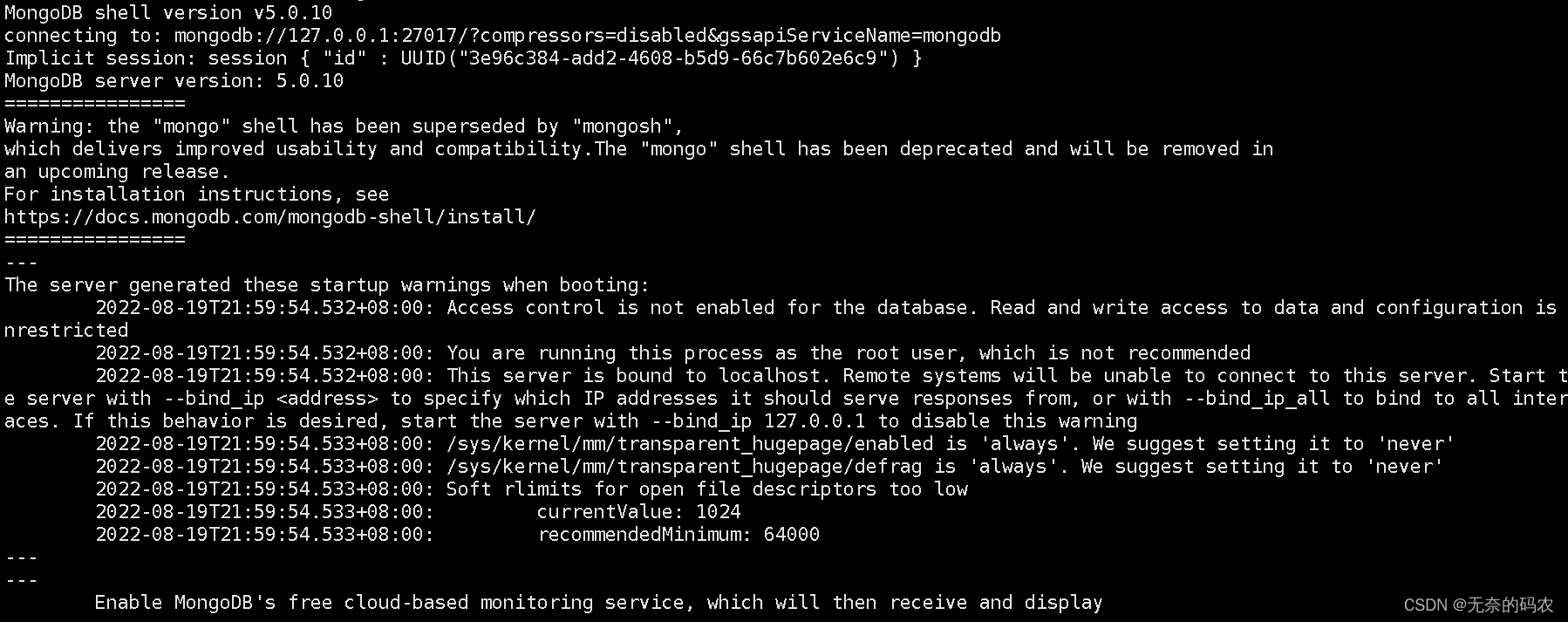
到这里mongodb就安装成功了
Mongodb 配置文件启动
进入到mongodb的根目录下面,创建conf文件夹
mkdir /opt/common/mongodb/conf
创建mongo.conf文件,进去conf文件夹
cd /opt/common/mongodb/conf
vi mongo.conf
配置文件内容
bind_ip=0.0.0.0
logpath=/opt/common/mongodb/mongo-home/log/mongo.log
#logappend=true
port=27017
fork=true
dbpath=/opt/common/mongodb/mongo-home/data
auth=true
| 参数 | 解释 |
|---|---|
| bind_ip | 支持远程ip访问,默认为localhost |
| logpath | 日志存放路径 |
| logappend | true:为日志追加 false:为重新写入日志 |
| port | 端口 |
| fork | 进程守护,true为进程守护启动,false不守护 |
| dbpath | 数据存放路径 |
| auth | 鉴权,是否需要账号密码才能登陆 |
| 配置文件配置好之后 | |
| 进入mongodb的conf文件夹下启动mongodb |
mongod -f mongo.conf
mongodb安装到这里就可以用了
使用MongoDB脚本实现增删查改
基本操作
选择和创建数据库的语法格式:
use 数据库名称
查看有权限查看的所有的数据库命令
show dbs
或
show databases
admin : 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config : 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
集合的操作
新增:
db.createCollection(name)
隐式的方式
db.test_d.insert({u_id:1,goods_id:1});
集合的查询
show tables;
集合的命名规范:
集合名不能是空字符串 “”。
集合名不能含有 \0字符(空字符),这个字符表示集合名的结尾。
集合名不能以 "system."开头,这是为系统集合保留的前缀。
用户创建的集合名字不能含有保留字符。另外千万不要在名字里出现$。
文档的插入
db.test.insert("")
批量插入
db.comment.insertMany([{"id" : 110, "name" : "lijin", "createdatetime" : new Date(), "content" : "今天下雨,天气不好"},{"id" : 110, "name" : "lijin", "createdatetime" : new Date(), "content" : "今天下雨,天气不好"},{"id" : 110, "name" : "lijin", "createdatetime" : new Date(), "content" : "今天下雨,天气不好"},{"id" : 110, "name" : "lijin", "createdatetime" : new Date(), "content" : "今天下雨,天气不好"}
]);
文档的基本查询
查询数据的语法格式如下:
db.collection.find(<query>, [projection])
文档的更新
db.collection.update(query, update, options)
文档的删除
db.collection.remove(条件)
db.collection.remove({_id:"1"})
db.comment.remove({}) 删除全部
复杂操作
统计查询
db.collection.count(query, options)
db.note.count(); --统计所有记录
db.note.count({name:"king"}); --统计name为king的记录条数
分页列表查询
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据
db.note.find().limit(3)
db.note.find().skip(3)
分页查询:需求:每页5个
db.note.find().skip(0).limit(5) //第一页
db.note.find().skip(5).limit(5) //第二页
db.note.find().skip(10).limit(5) //第三页
排序查询
db.集合名称.find().sort(排序方式) 1升序、-1降序
db.note.find().sort({name:-1,id:-1})
skip(), limit(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关
db.note.find().skip(0).limit(5).sort({name:-1,id:-1})
正则表达式
db.集合.find({字段:/正则表达式/}) 正则表达式是 js的语法
db.note.find({content:/下雨/}) content包含'下雨'的
db.note.find({name:/^k/}) name是k开头的
比较查询
db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value
db.集合名称.find({ "field" : { $lt: value }}) // 小于: field < value
db.集合名称.find({ "field" : { $gte: value }}) // 大于等于: field >= value
db.集合名称.find({ "field" : { $lte: value }}) // 小于等于: field <= value
db.集合名称.find({ "field" : { $ne: value }}) // 不等于: field != value
db.note.find({id:{$gt:252}})
db.note.find({$and:[{id:{$gt:252}},{id:{$lt:256}}]})
条件连接查询
$and:[ { },{ },{ } ]
包含查询
db.note.find({id:{$in: [252,254]}})
索引-Index
索引(Index)是帮助MongoDB高效获取数据的数据结构,索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引的基础知识
B-树索引的构造类似于二叉树,根据键值(Key Value)快速找到数据。注意B-树中的B不是代表二叉(binary),而是代表平衡(balance),因为B-树是从最早的平衡二叉树演化而来,但是B-树不是一个二叉树。
在讲二叉树之前,我们必须了解一下二分查找:
二分查找法(binary search) 也称为折半查找法,用来查找一组有序的记录数组中的某一记录。
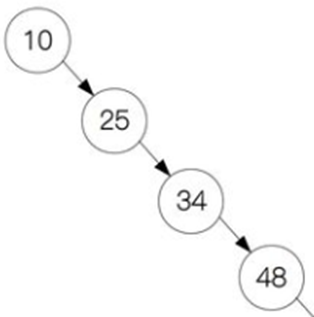
在以下数组中找到数字48对应的下标

通过3次二分查找 就找到了我们所要的数字,而顺序查找需8次。
对于上面10个数来说,顺序查找平均查找次数为(1+2+3+4+5+6+7+8+9+10)/10=5.5次。而二分查找法为(4+3+2+4+3+1+4+3+2+3)/10=2.9次。在最坏的情况下,顺序查找的次数为10,而二分查找的次数为4。
所以为了索引查找的高效性,我们引入了二叉查找树。
MongoDB索引使用B树数据结构(确切的说是B-Tree,MySQL是B+Tree)
二叉树
树(Tree)
N个结点构成的有限集合。
- 树中有一个称为”根(Root)”的特殊结点
- 其余结点可分为M个互不相交的树,称为原来结点的”子树”
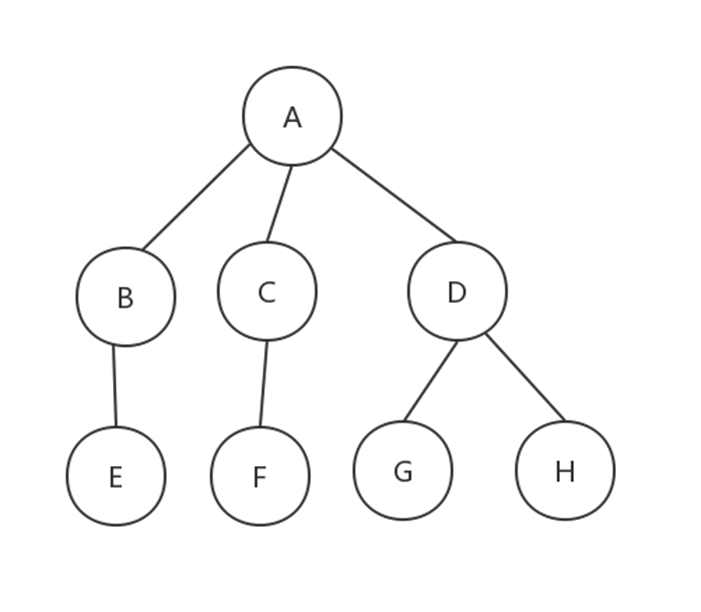
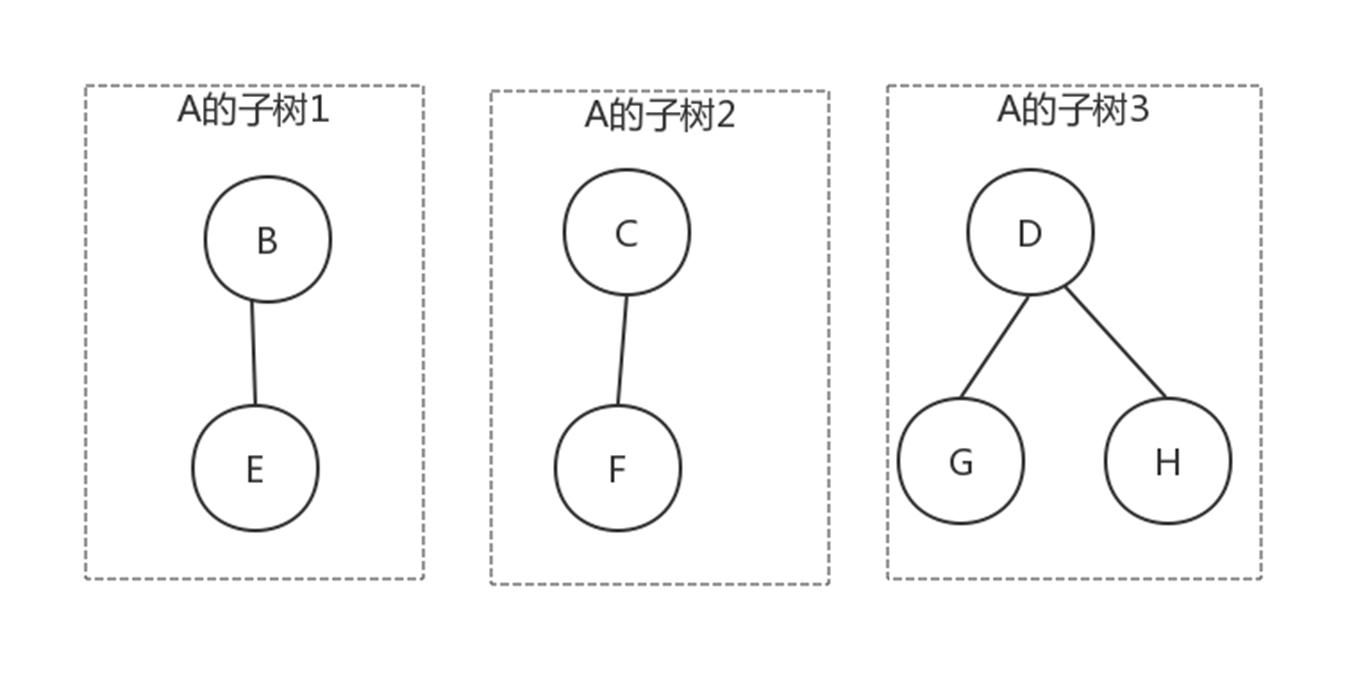
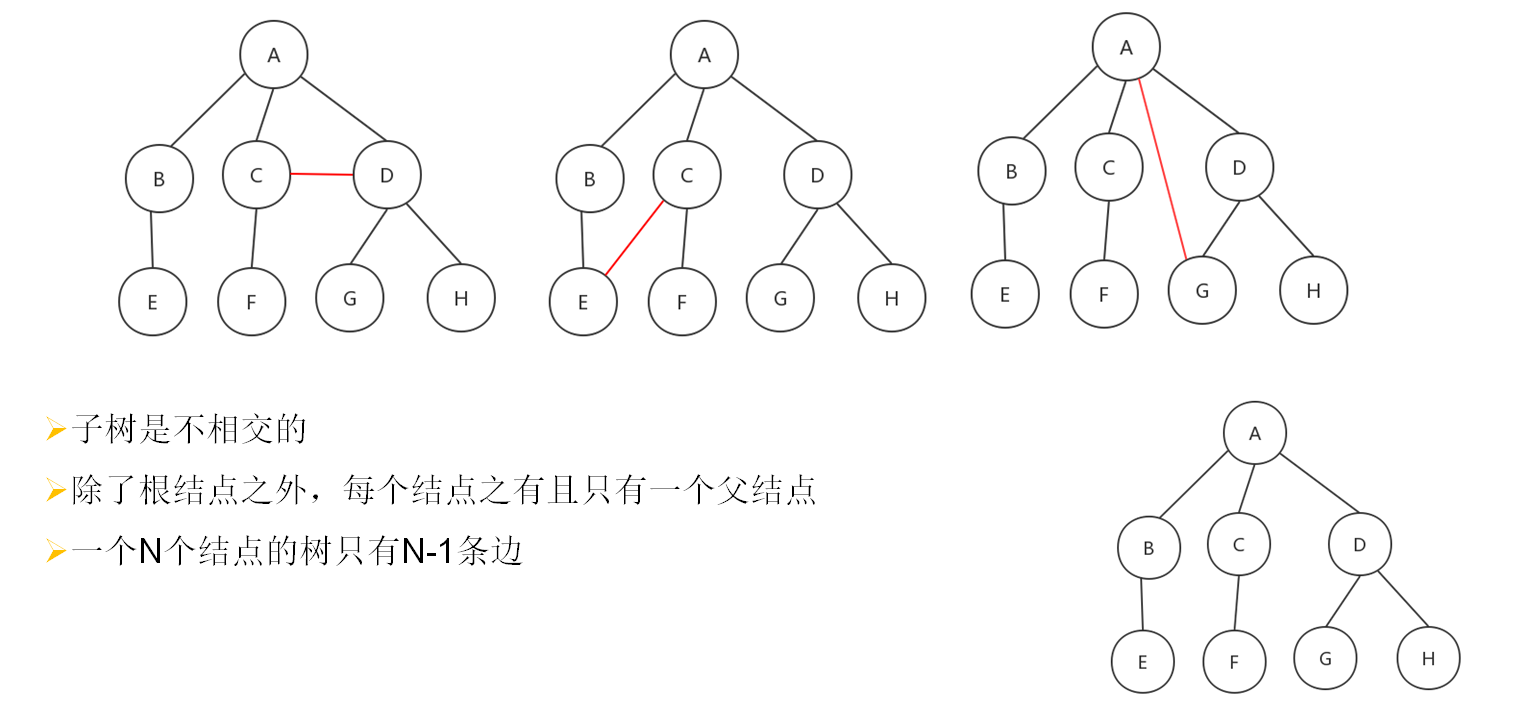
树与非树
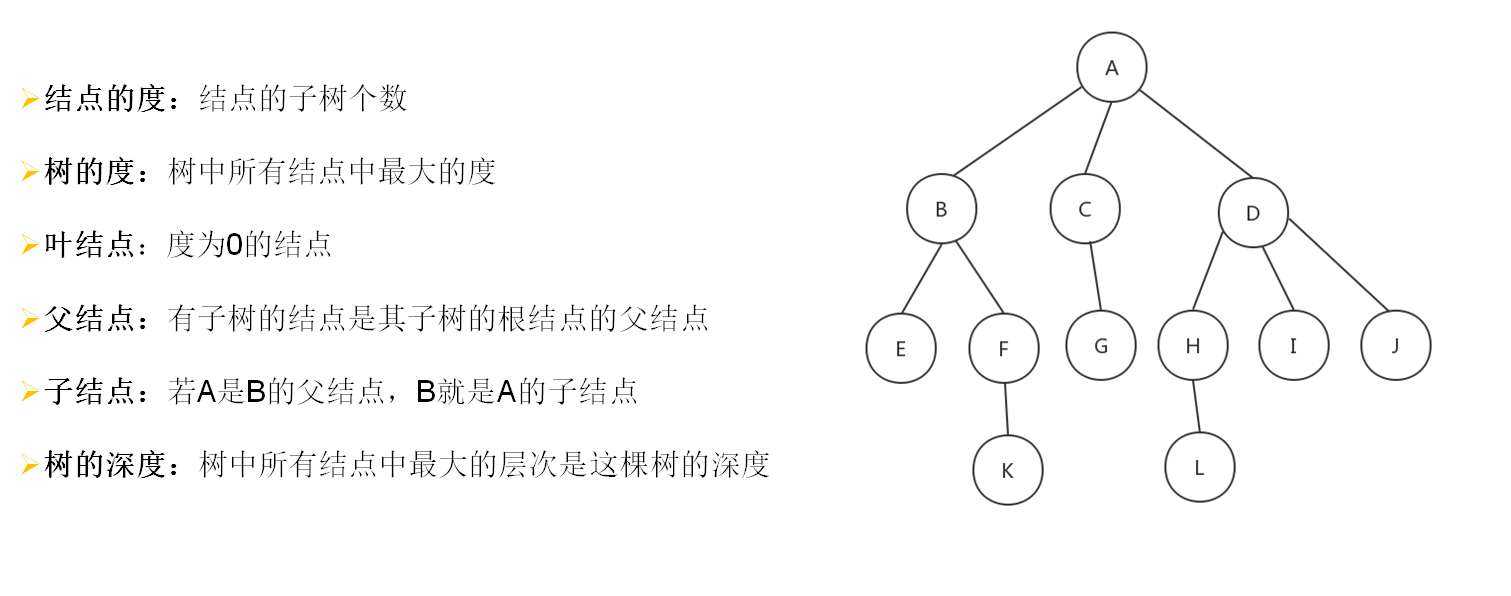
树的一些基本术语
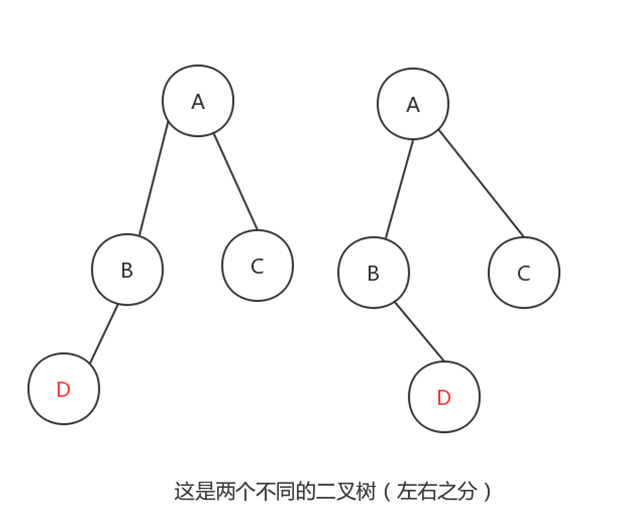
二叉树
度为2的树(也可称之为阶):(树的度:树中所有结点中最大的度。结点的度:结点的子树个数)
子树有左右顺序之分:
二叉查找(搜索)树
二叉查找树首先肯定是个二叉树,除此之外还符合以下几点:
- 左子树的所有的值小于根节点的值
- 右子树的所有的值大于或等于根节点的值
- 左、右子树满足以上两点
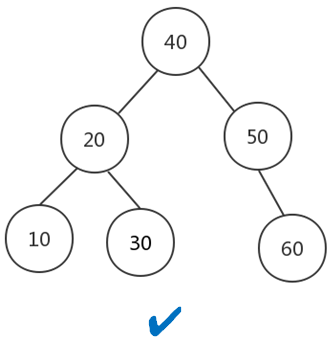
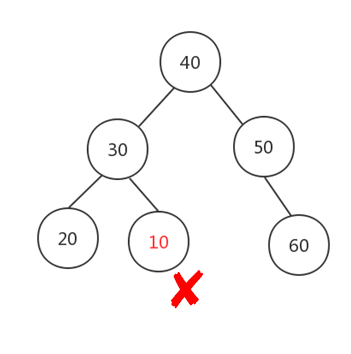
但是二叉查找树,如果设计不良,完全可以变成一颗极不平衡的二叉查找树:
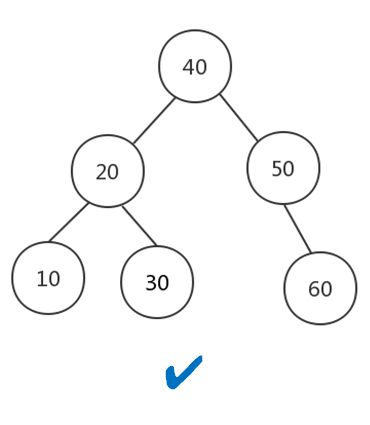
因此若想最大性能地构造一棵二叉查找树,需要这棵二叉查找树是平衡的,从而引出了新的定义——平衡二叉树,或称为AVL树。
平衡二叉树(AVL-树)
它是一棵二叉排序树,它的左右两个子树的高度差(平衡因子)的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
目的:使得树的高度最低,因为树查找的效率决定于树的高度
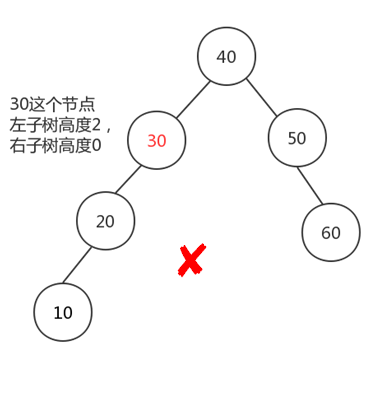
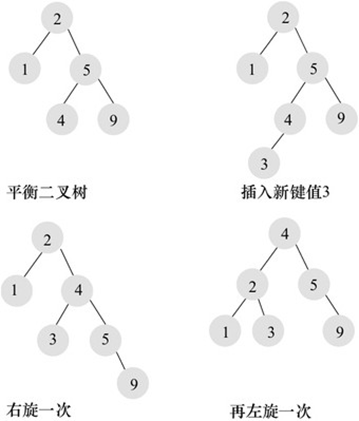
平衡二叉树的查找性能是比较高的,但是维护一棵平衡二叉树的代价是非常大的。通常来说,需要1次或多次左旋和右旋来得到插入、更新和删除后树的平衡性。
B-树
B- 树是从平衡二叉查找树演化而来(但B+树不是二叉树,而是一个多叉查找平衡树)。
下图就是一颗平衡二叉查找树
借助网页工具:Data Structure Visualization (usfca.edu)
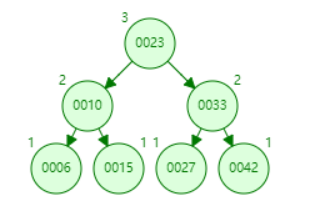
现在我们将其改造成 B- 树
树的阶数表示一个节点最多能有多少个子节点。
每个节点存储了实际的数据,所有的节点都按照排序二叉树来进行排列;
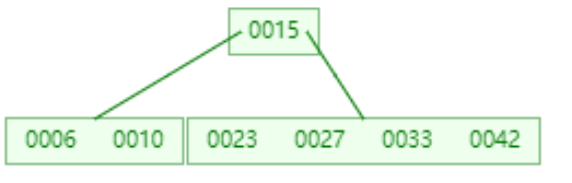
从AVL到B-树的变化可知,如果节点特别多的话,AVL树的高度远远高于B+树。
下图是一颗实际情况下的B-树
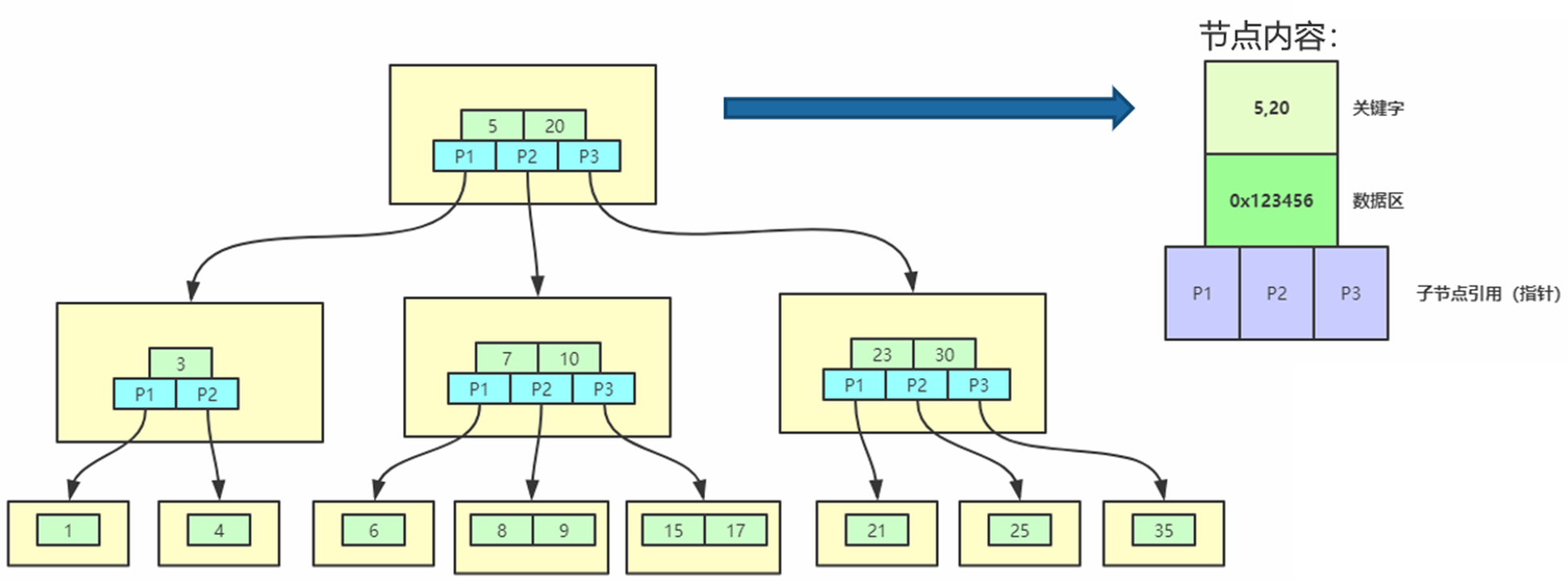
索引的类型
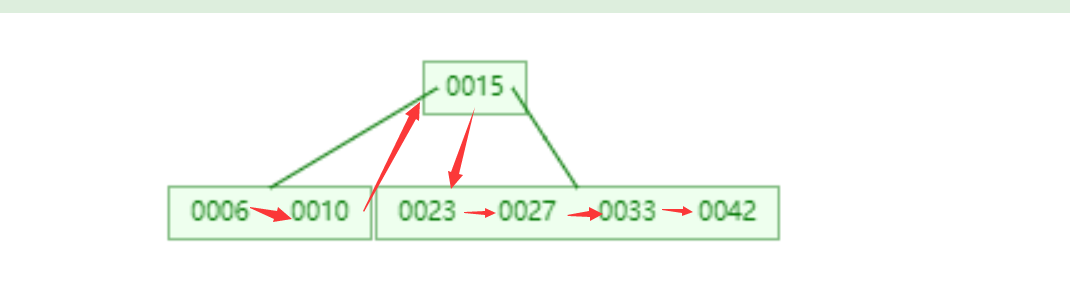
单字段索引
MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,称为单字段索引(Single Field Index)。
对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以在任何方向上遍历索引。
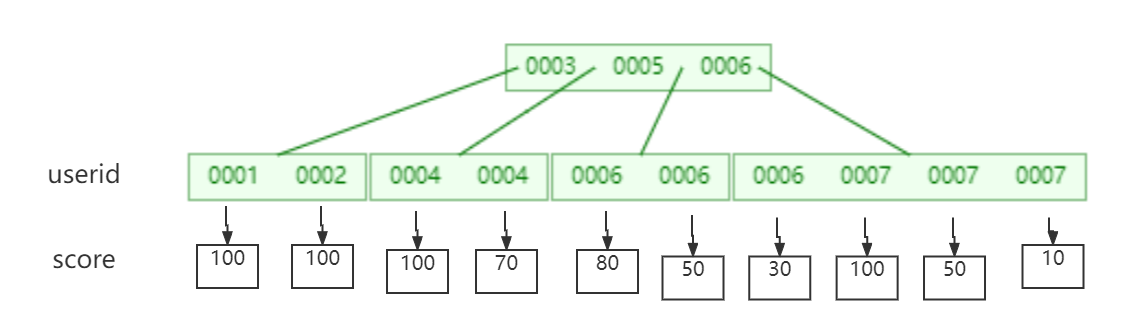
复合索引
MongoDB还支持多个字段的用户定义索引,即复合索引(Compound Index)。
复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由 { userid: 1, score: -1 } 组成,则索引首先按userid正序排序,然后在每个userid的值内,再在按score倒序排序。
索引的管理
索引的创建
db.collection.ensureIndex() --3.0.0 版本前
db.collection.createIndex(keys, options) --3.0.0 版本及之后
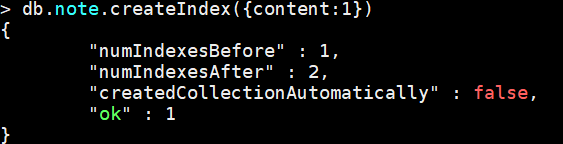
案例:对 note的content字段建立索引
db.note.createIndex({content:1}) --1是按照指定按升序创建索引 -1按降序来创建索引
查看索引
db.note.getIndexes(); --查看索引
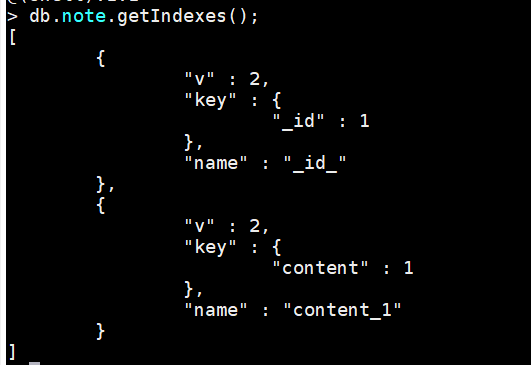
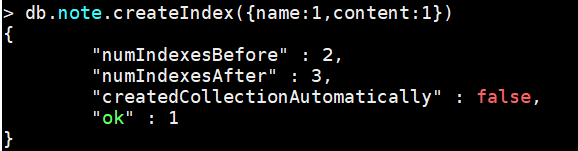
复合索引:对name 和content 同时建立复合(Compound)索引:
db.note.createIndex({name:1,content:1})
索引的移除
db.collection.dropIndex(index) --移除指定索引
db.collection.dropIndexes() --移除所有索引
案例:删除note的的content索引
db.note.dropIndex({content:1})
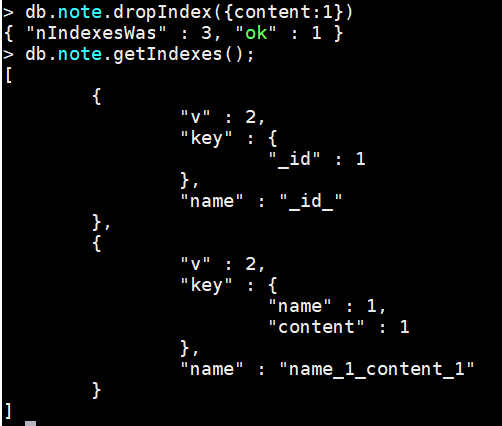
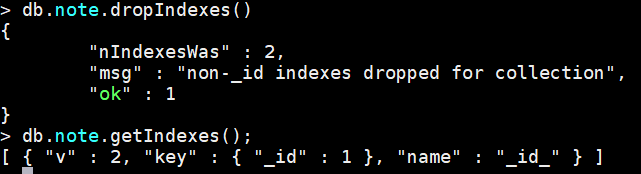
案例:删除note的所有索引
db.note.dropIndexes()
后续还会添加mongo进阶教程和mongo的分片集群搭建使用















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











