






来自:CodeFuse
语义搜索任务的主要挑战是创建既准确又高效的模型来精准定位与用户查询相关的句子。基于BERT风格的双编码器因为可以使用预先计算的嵌入表示时效率很高,但它们往往会错过句子对的微妙关系。相反,基于 GPT 风格的大语言模型(LLM)采用交叉编码器的设计且能够捕捉到这些微妙关系,但它们的计算量通常很大,阻碍了实际应用。
我们提出了一种结合了以上两者的优点的用于语义搜索的分解和蒸馏大型语言模型 D2LLM 。我们将交叉编码器分解为一个高效的双编码器,双编码器集成了多头注意力池化模块,另外,通过一个交互模拟模块,模型实现了对细微语义关系的理解。我们使用对比、排序和特征模仿技术将LLM的知识蒸馏到该模型中。实验表明,D2LLM 在三项任务的指标上超过了五个领先的基准模型,特别是在自然语言推理(NLI)任务的性能至少提高了6.45%。
🔎TLDR
我们提出了一种混合型语义搜索模型,通过分解大语言模型和从大语言模型中蒸馏知识,实现了双编码器的运行效率与交叉编码器的理解准确性的折中。
01
简介
本文源于蚂蚁集团与华东师范大学的校企合作项目,目前已被ACL 2024 main会议接收。ACL(Association for Computational Linguistics)会议是自然语言处理领域的顶级国际会议之一,是自然语言处理领域唯一的 CCF-A 类会议。
arXiv:http://arxiv.org/abs/2406.17262
github:https://github.com/codefuse-ai/D2LLM

语义搜索是自然语言处理的关键组成部分,它通过挖掘文本的底层语义关联对大量文本进行筛选,以找到与用户查询最匹配的内容。这种技术超越了传统的非语义方法如TF-IDF和BM25,解决了词汇不匹配问题,提供了更准确的文本匹配,对信息检索[1]、问答系统[2]、推荐系统[3]等多个领域产生了深远影响。
表1:双编码器与交叉编码器的对比
— | 优点 | 缺点 |
双编码器 | 效率高,表示可预计算 | 忽略句子对间的关系 |
交叉编码器 | 关注句子对间的关系 | 效率低,表示不可预计算 |
表2:Bert式双编码器与LLM式交叉编码器的对比
— | 优点 | 缺点 |
Bert式双编码器 | 效率高,表示可预计算 | 忽略句子对间的关系,泛化性弱 |
LLM式交叉编码器 | 准确性高,泛化性强 | 效率低,表示不可预计算 |
语义搜索方法大体上分为两种:双编码器和交叉编码器。前者分别对查询和段落进行表征提取,然后再计算它们之间的联系,这种方法效率高,且表示可预计算。后者将查询和段落联系起来,将它们构成一个整体,再分析两者之间的联系,这种方法往往能更好地建模句子对的关系(表1)。以这两种方法作为基础,目前表现较为优秀的方法包括BERT式双编码器[4,5,6],以及基于大语言模型(LLM)的交叉编码器。BERT式双编码器可以对查询和段落转换成向量并快速比较相似度,但这种方法可能牺牲准确度,忽略了句子对间细微的语义联系。此外,双编码器通常需要经过一个复杂的、分阶段的训练过程[7],并且在新领域的泛化能力有限。LLM式交叉编码器可以联合处理查询和段落,提供更细致的文本关系分析,并表现出优异的零样本学习能力[8,9],且不需要在特定领域训练就能迅速适应新任务,但带来的高准确性通常以牺牲效率为代价。此外,由于不能预先缓存段落向量,该方法需要对每个查询都和每个段落都进行重新推理(表2)。
为了结合双编码器的速度和交叉编码器的准确性,我们引入了D2LLM解决方案(图1)。D2LLM通过先进的蒸馏技术,将交叉编码器的复杂性分解为更简单的模型—一个双编码器、一个多头注意力池(PMA)和一个交互模拟模块(IEM)。这使得查询和段落的嵌入向量可以高效生成并存储,同时确保了模型能够适应各种搜索任务。通过从教师模型(LLM)中蒸馏知识,D2LLM兼具了高速和高准确率。
本文提出了三点主要改进,并进行了相关实验:
我们引入了 D2LLM,这是一种新的语义搜索解决方案,它将双编码器的速度与基于 LLM 的交叉编码器的准确性相结合。该方法将复杂的交叉编码器分解为更易于管理的学生模型。
我们通过全面的知识蒸馏策略将教师的专业知识迁移给学生模型,包括对比模仿、排序模仿和特征模仿技术。
实验结果表明,D2LLM 在三个基准任务中的表现优于五种领先方法,尤其显著地比排名第二的 LLaRA 提高了 14.39%,在 NLI 任务中比经过大量微调的基准模型 BGE 模型领先 6.45%。
02
算法
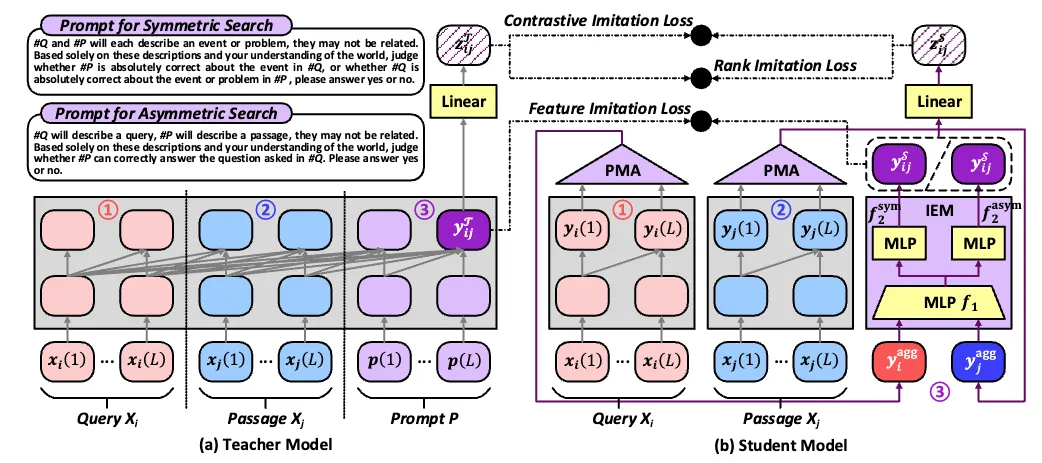
图1:我们的语义搜索解决方案
我们的算法整体框架如图1所示,主要包括教师模型、学生模型、以及三种知识蒸馏策略。以下对每一个模块进行详细说明。
教师模型
教师模型的目标是准确判断一个查询![]() 和一个段落
和一个段落 ![]() 是否匹配。我们充分利用 LLM 的零样本学习能力,通过提示工程设计提示
是否匹配。我们充分利用 LLM 的零样本学习能力,通过提示工程设计提示 ![]() 来引导LLM对查询-段落对进行分析。如图1左上角所示,我们为对称和非对称搜索设计了提示
来引导LLM对查询-段落对进行分析。如图1左上角所示,我们为对称和非对称搜索设计了提示![]() 和
和![]() 。选择的提示与查询-段落对
。选择的提示与查询-段落对![]() 结合在一起,促使 LLM 生成“是”或“否”的回答。LLM 为回应生成了一个表示
结合在一起,促使 LLM 生成“是”或“否”的回答。LLM 为回应生成了一个表示 ![]() 以及通过对“是”和“否”词元的logits值进行softmax计算,得到LLM的预测概率
以及通过对“是”和“否”词元的logits值进行softmax计算,得到LLM的预测概率 ![]() 。
。
学生模型
学生模型以双编码器的架构分别处理查询和段落,并通过Pooling by Multihead Attention (PMA) 和Interaction Emulation Module (IEM) 模拟提示信息和查询-段落-提示的关系。
PMA模块通过聚合来自查询$X_i$和文段$X_j$的信息,为每个 token 生成一个独特的嵌入向量。PMA 以可学习向量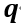 作为锚点,根据它与查询$\bm q$的相似度从
作为锚点,根据它与查询$\bm q$的相似度从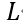 个token中提取信息,实现了基于注意力的聚合,这种方法比传统的聚合方法更灵活。PMA部分的形式化定义如下:
个token中提取信息,实现了基于注意力的聚合,这种方法比传统的聚合方法更灵活。PMA部分的形式化定义如下:
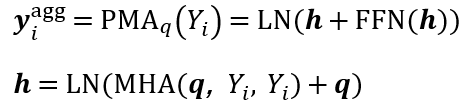
其中 LN 为层归一化操作,FFN 为前馈神经网络。MHA 为多头自注意力机制。IEM 在 PMA 生成查询和文段的独立向量后,隐式编码提示信息,并计算查询和段落的交互分数。具体而言,IEM 先将查询和段落嵌入拼接并输入到多层感知器(MLP)进行处理,MLP 设计有两个分支以处理不同类型的提示,从而获得学生模型的logits![]() 和分数
和分数![]() 。形式化定义为:
。形式化定义为:
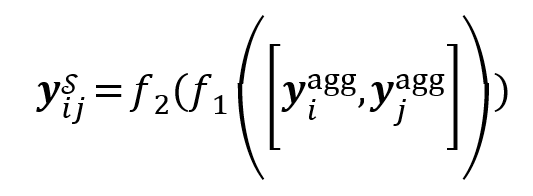
蒸馏策略
知识蒸馏旨在将教师模型的能力传授给学生模型。为此,我们专注于三项训练目标:对比学习、排名学习和特征模仿。
对比模仿
针对特定查询 $\tX_i$ ,我们准备了一组正样本 ![]() (相关段落)和负样本
(相关段落)和负样本 ![]() (非相关段落)。负样本集包括批次内负样本和基于 BM25 与现有双编码器评估得到的困难负样本,
(非相关段落)。负样本集包括批次内负样本和基于 BM25 与现有双编码器评估得到的困难负样本,![]() 。对比模仿(CI)损失函数为:
。对比模仿(CI)损失函数为:
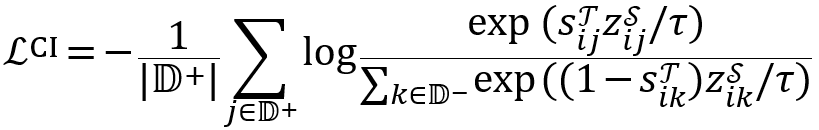
其中![]() 是温度参数,
是温度参数,![]() 是教师模型对于样本对
是教师模型对于样本对 ![]() 评估为“是”的概率分数,
评估为“是”的概率分数,![]() 是学生模型对应的分数。与传统对比损失不同的是,该损失利用教师模型的分数
是学生模型对应的分数。与传统对比损失不同的是,该损失利用教师模型的分数![]() 来处理样本间的相关性差异,给较易的负样本分配更高的训练权重。尽管一些困难负样本可能是潜在的正样本,但该改进后的损失可以有效应对这种情况,相比传统对比学习提供了一个更稳健的训练环境。
来处理样本间的相关性差异,给较易的负样本分配更高的训练权重。尽管一些困难负样本可能是潜在的正样本,但该改进后的损失可以有效应对这种情况,相比传统对比学习提供了一个更稳健的训练环境。
排序模仿
排序模仿旨在让学生模型区分正样本与困难负样本,以及简单负样本与困难负样本,使得学生能够具备教师模型的排序能力。
首先,为了让学生和教师对正样本及困难负样本的排序同步,我们的目标是最大化它们logits之间的皮尔逊相关系数。损失定义如下:
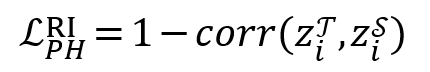
该损失函数的输入为教师和学生模型对正样本和困难负样本的预测 logits 构成的向量。由于 LLM 对批次内的简单负样本之间的相关性排序通常不具有意义,因此这一部分我们没有将它们考虑在内。
另一方面,具备区分困难负样本和简单负样本也是重要的。事实上,困难负样本往往与查询有一定语义联系,而简单负样本没有。为了强调这点,我们引入了针对这两组样本的附加损失:
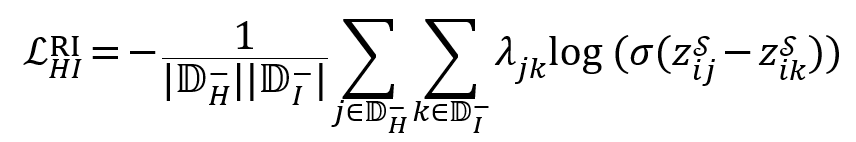
其中![]() 是使用归一化折扣累积增益(NDCG)来确定的权重。该损失确保学生模型会对困难负样本相比简单负样本拥有更高的得分。此外,即使在批次内负样本中混有难负样本,该损失仍能让学生模型在教师的指导下稳定训练。
是使用归一化折扣累积增益(NDCG)来确定的权重。该损失确保学生模型会对困难负样本相比简单负样本拥有更高的得分。此外,即使在批次内负样本中混有难负样本,该损失仍能让学生模型在教师的指导下稳定训练。
特征模仿
特征模仿强调从特征的角度让学生模型去模仿教师模型。首先,我们为一个批次内的所有查询-段落对计算教师的相似度矩阵:
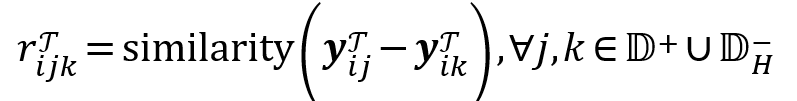
其中 similarity 表示余弦相似度,然后对学生模型进行相同的过程以获得![]() 。该损失的目标是最小化教师和学生的相似度矩阵之间的差异的L2范数,损失定义为:
。该损失的目标是最小化教师和学生的相似度矩阵之间的差异的L2范数,损失定义为:
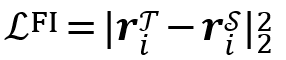
这种方法指导学生模仿教师表示的关系模式,实现更深层次的知识迁移。
03
实验
我们以Qwen-7B-Chat作为模型底座,主要在自然语言处理数据的自然语言推断(NLI)、语义相似度检测(STS)、信息检索(IR)任务上验证我们的算法。使用的数据集包括:SNLI-zh、NLI-zh、T2Ranking、DuReader、cMedQAv2、mMarco数据集。我们使用六个评测指标来评估性能:准确率(ACC)、平均精确率)(AP)、精确率(Prec.)、召回率(Recall)、皮尔逊相关系数(Pear.)、斯皮尔曼相关系数(Spear.)。我们在8张80G A100上运行训练。
实验结果
表1:NLI任务实验结果
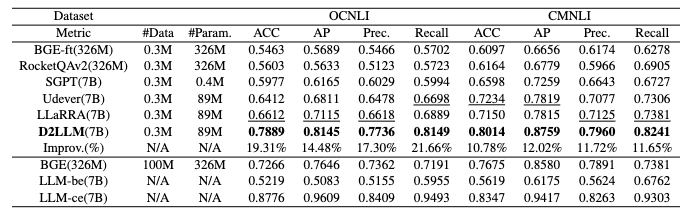
表2:STS任务实验结果
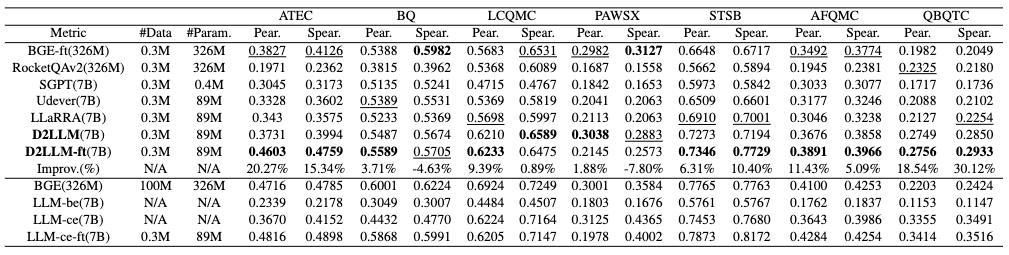
表3:IR任务实验结果
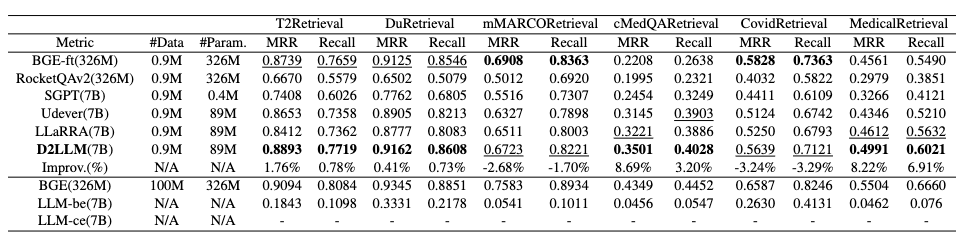
我们首先对所有方法在自然语言推理(NLI)任务的表现进行了研究。D2LLM 模型在所有指标和所有测试数据集上均超越了在 0.3M 样本集上训练的所有竞争对手。值得注意的是,它的平均表现比排名第二的 LLaRA 方法高出14.39%,比在1亿个相关样本上微调的 BGE 高出 6.45%。此外,D2LLM 有效地缩小了完整的双编码器LLMs(LLM-be)和交叉编码器LLMs(LLM-ce)之间的差距。尽管原始的 LLM-be 作为双编码器由于文本生成和嵌入之间的不匹配而表现不佳,基于交叉编码器的教师模型 LLM-ce 却能够通过利用 LLMs 从句子对中合成信息来发挥出色的表现。我们的蒸馏方法成功地将知识从教师转移到学生,将原先效果不佳的 LLM-be 转变为精通 NLI 的工具。在语义文本相似性(STS)和信息检索(IR)任务上,D2LLM 在大多数情况下(超过了在相同数据集上训练的其他方法。原始BGE则保持着稳定的领先地位。
值得注意的是,即使是教师模型 LLM-ce,也落后于BGE,这凸显了 D2LLM 在某些情况下的欠佳表现。但重要的是,教师模型 LLM-ce 并没有为 STS 特别微调。为了解决这个问题,我们使用 LoRA 方法对教师模型在 STS 领域进行了微调,仅使用 0.3M 数据进行微调就为教师带来了平均 7.17% 的提升。在 LLM-ce-ft 的基础上,我们训练了学生模型,即D2LLM-ft,相比原始 D2LLM 增长了1.69%。此外,现在的 D2LLM-ft 显着优于其他在相同0.3M 样本集上训练的方法,至少平均高出 17.42%。这证实了,尽管在任务的初始表现欠佳,LLMs 强大的适应能力意味着通过相对较小的数据集进行微调可以显著提升教师和随后的学生的性能。总结而言,无论是在自然语言推理还是语义文本相似性及信息检索任务中,D2LLM 都展示出了卓越的性能,即使是在数据量较少的情况下也能通过微调取得显著成效,这体现了大型语言模型的强大适应力和潜力。
总结
本研究提出了D2LLM,一种创新的模型蒸馏方法,从大型语言模型(LLM)中提炼知识,构建一个用于语义搜索的高效的学生模型。D2LLM 通过深入地理解其教师模型,并运用专门设计的模块与损失函数,将教师模型的能力以更紧凑的形式封装。实验结果显示,D2LLM 成功地结合了交叉编码器的高准确性和双编码器的操作效率。
关于我们
我们是蚂蚁集团的AI native团队,负责蚂蚁蚂蚁集团平台工程的智能化,团队成立3年以来,在在ICLR、NeurIPS、KDD 等顶会论发表论文 20 余篇,参与获得两次蚂蚁技术最高奖T-Star,1次蚂蚁集团最高奖 SuperMA。团队常年招聘研究型实习生,同时现在也有社招 HC,有做 NLP,大模型,多模态,图神经网络的同学欢迎联系👉lijg.zero@antgroup.com
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦
参考文献
[1] Zhu, Yutao, et al. "Large language models for information retrieval: A survey." arxiv preprint arxiv:2308.07107 (2023).
[2] Allam, Ali Mohamed Nabil, and Mohamed Hassan Haggag. "The question answering systems: A survey." International Journal of Research and Reviews in Information Sciences (IJRRIS) 2.3 (2012).
[3] Hu, Linmei, et al. "Graph neural news recommendation with unsupervised preference disentanglement." Proceedings of the 58th annual meeting of the association for computational linguistics. 2020.
[4] Wang, Liang, et al. "Text embeddings by weakly-supervised contrastive pre-training." arxiv preprint arxiv:2212.03533 (2022).
[5] Xiao, Shitao, et al. "C-pack: Packaged resources to advance general chinese embedding." arxiv preprint arxiv:2309.07597 (2023).
[6] Li, Zehan, et al. "Towards general text embeddings with multi-stage contrastive learning." arxiv preprint arxiv:2308.03281 (2023).
[7] Wang, Liang, et al. "Improving text embeddings with large language models." arxiv preprint arxiv:2401.00368 (2023).
[8] Wei, Jason, et al. "Finetuned language models are zero-shot learners." arxiv preprint arxiv:2109.01652 (2021).
[9] Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." Advances in neural information processing systems 35 (2022): 22199-22213.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









