







网络结构
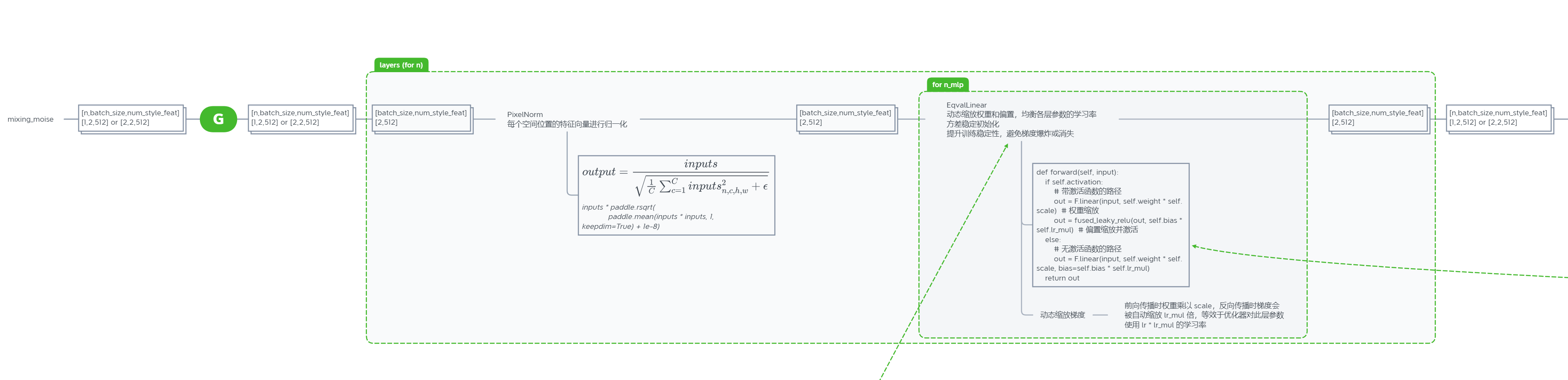
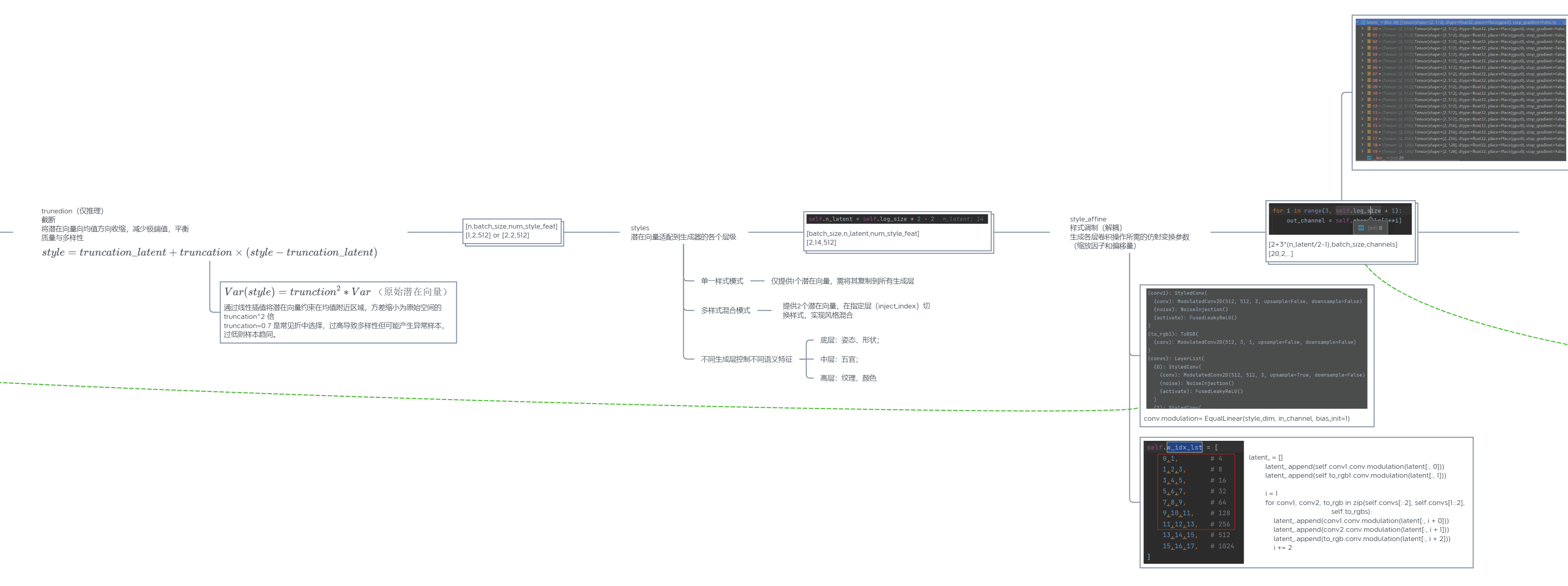
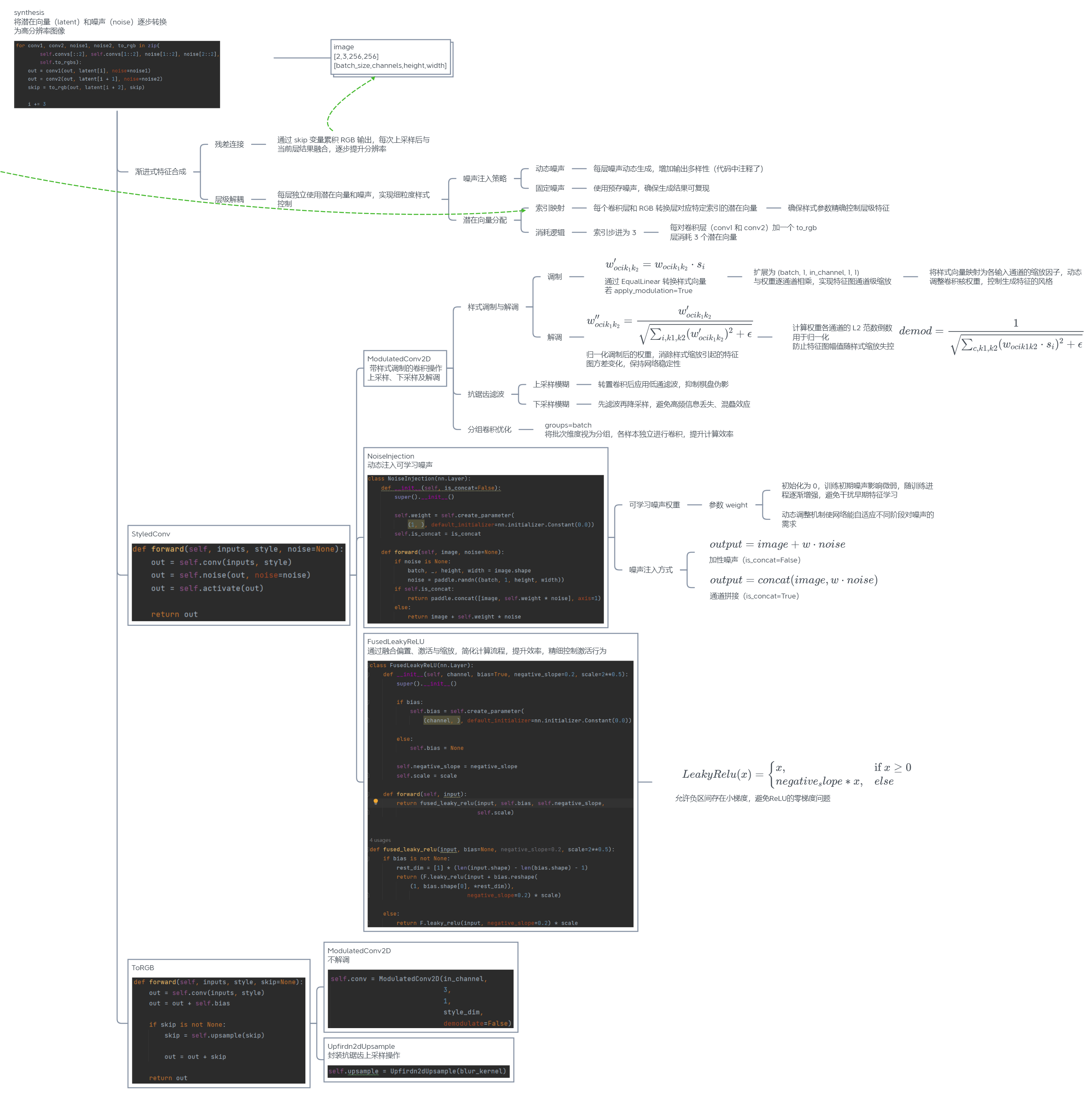
生成器G结构
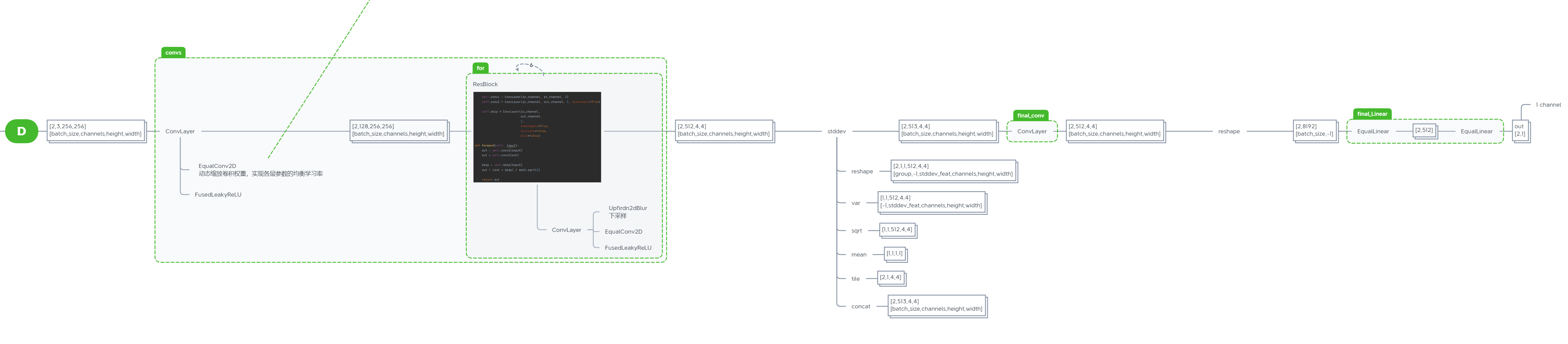
判别器D结构
代码简析
训练入口./ppgan/engine/trainer.py
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import sys
import time
import copy
import logging
import datetime
import paddle
from paddle.distributed import ParallelEnv
from ..datasets.builder import build_dataloader
from ..models.builder import build_model
from ..utils.visual import tensor2img, save_image
from ..utils.filesystem import makedirs, save, load
from ..utils.timer import TimeAverager
from ..utils.profiler import add_profiler_step
class IterLoader:
def __init__(self, dataloader):
self._dataloader = dataloader
self.iter_loader = iter(self._dataloader)
self._epoch = 1
self._inner_iter = 0
@property
def epoch(self):
return self._epoch
def __next__(self):
try:
if sys.platform == "Windows" and self._inner_iter == len(
self._dataloader) - 1:
self._inner_iter = 0
raise StopIteration
data = next(self.iter_loader)
except StopIteration:
self._epoch += 1
self.iter_loader = iter(self._dataloader)
data = next(self.iter_loader)
self._inner_iter += 1
return data
def __len__(self):
return len(self._dataloader)
class Trainer:
"""
# trainer calling logic:
#
# build_model || model(BaseModel)
# | ||
# build_dataloader || dataloader
# | ||
# model.setup_lr_schedulers || lr_scheduler
# | ||
# model.setup_optimizers || optimizers
# | ||
# train loop (model.setup_input + model.train_iter) || train loop
# | ||
# print log (model.get_current_losses) ||
# | ||
# save checkpoint (model.nets) \/
"""
def __init__(self, cfg):
# base config
self.logger = logging.getLogger(__name__)
self.cfg = cfg
self.output_dir = cfg.output_dir
self.max_eval_steps = cfg.model.get('max_eval_steps', None)
self.local_rank = ParallelEnv().local_rank
self.world_size = ParallelEnv().nranks
self.log_interval = cfg.log_config.interval
self.visual_interval = cfg.log_config.visiual_interval
self.weight_interval = cfg.snapshot_config.interval
self.start_epoch = 1
self.current_epoch = 1
self.current_iter = 1
self.inner_iter = 1
self.batch_id = 0
self.global_steps = 0
# build model
self.model = build_model(cfg.model)
# build metrics
self.metrics = None
self.is_save_img = True
validate_cfg = cfg.get('validate', None)
if validate_cfg and 'metrics' in validate_cfg:
self.metrics = self.model.setup_metrics(validate_cfg['metrics'])
if validate_cfg and 'save_img' in validate_cfg:
self.is_save_img = validate_cfg['save_img']
self.enable_visualdl = cfg.get('enable_visualdl', False)
if self.enable_visualdl:
import visualdl
self.vdl_logger = visualdl.LogWriter(logdir=cfg.output_dir)
# build train dataloader
self.train_dataloader = build_dataloader(cfg.dataset.train)
self.iters_per_epoch = len(self.train_dataloader)
# build lr scheduler
# TODO: has a better way?
if 'lr_scheduler' in cfg and 'iters_per_epoch' in cfg.lr_scheduler:
cfg.lr_scheduler.iters_per_epoch = self.iters_per_epoch
self.lr_schedulers = self.model.setup_lr_schedulers(cfg.lr_scheduler)
# build optimizers
self.optimizers = self.model.setup_optimizers(self.lr_schedulers,
cfg.optimizer)
# setup amp train
self.scalers = self.setup_amp_train() if self.cfg.amp else None
# multiple gpus prepare
if ParallelEnv().nranks > 1:
self.distributed_data_parallel()
# evaluate only
if not cfg.is_train:
return
self.epochs = cfg.get('epochs', None)
if self.epochs:
self.total_iters = self.epochs * self.iters_per_epoch
self.by_epoch = True
else:
self.by_epoch = False
self.total_iters = cfg.total_iters
if self.by_epoch:
self.weight_interval *= self.iters_per_epoch
self.validate_interval = -1
if cfg.get('validate', None) is not None:
self.validate_interval = cfg.validate.get('interval', -1)
self.time_count = {
}
self.best_metric = {
}
self.model.set_total_iter(self.total_iters)
self.profiler_options = cfg.profiler_options
def setup_amp_train(self):
""" decerate model, optimizer and return a list of GradScaler """
self.logger.info('use AMP to train. AMP level = {}'.format(
self.cfg.amp_level))
# need to decorate model and optim if amp_level == 'O2'
if self.cfg.amp_level == 'O2':
nets, optimizers = list(self.model.nets.values()), list(
self.optimizers.values())
nets, optimizers = paddle.amp.decorate(models=nets,
optimizers=optimizers,
level='O2',
save_dtype='float32')
for i, (k, _) in enumerate(self.model.nets.items()):
self.model.nets[k] = nets[i]
for i, (k, _) in enumerate(self.optimizers.items()):
self.optimizers[k] = optimizers[i]
scalers = [
paddle.amp.GradScaler(init_loss_scaling=1024)
for i in range(len(self.optimizers))
]
return scalers
def distributed_data_parallel(self):
paddle.distributed.init_parallel_env()
find_unused_parameters = self.cfg.get('find_unused_parameters', False)
for net_name, net in self.model.nets.items():
self.model.nets[net_name] = paddle.DataParallel(
net, find_unused_parameters=find_unused_parameters)
def learning_rate_scheduler_step(self):
if isinstance(self.model.lr_scheduler, dict):
for lr_scheduler in self.model.lr_scheduler.values():
lr_scheduler.step()
elif isinstance(self.model.lr_scheduler,
paddle.optimizer.lr.LRScheduler):
self.model.lr_scheduler.step()
else:
raise ValueError(
'lr schedulter must be a dict or an instance of LRScheduler')
def train(self):
reader_cost_averager = TimeAverager()
batch_cost_averager = TimeAverager()
iter_loader = IterLoader(self.train_dataloader)
# set model.is_train = True
self.model.setup_train_mode(is_train=True)
while self.current_iter < (self.total_iters + 1):
self.current_epoch = iter_loader.epoch
self.inner_iter = self.current_iter % max(self.iters_per_epoch, 1)
add_profiler_step(self.profiler_options)
start_time = step_start_time = time.time()
data = next(iter_loader)
reader_cost_averager.record(time.time() - step_start_time)
# unpack data from dataset and apply preprocessing
# data input should be dict
self.model.setup_input(data)
if self.cfg.amp:
self.model.train_iter_amp(self.optimizers, self.scalers,
self.cfg.amp_level) # amp train
else:
self.model.train_iter(self.optimizers) # norm train
batch_cost_averager.record(
time.time() - step_start_time,
num_samples=self.cfg['dataset']['train'].get('batch_size', 1))
step_start_time = time.time()
if self.current_iter % self.log_interval == 0:
self.data_time = reader_cost_averager.get_average()
self.step_time = batch_cost_averager.get_average()
self.ips = batch_cost_averager.get_ips_average()
self.print_log()
reader_cost_averager.reset()
batch_cost_averager.reset()
if self.current_iter % self.visual_interval == 0 and self.local_rank == 0:
self.visual('visual_train')
self.learning_rate_scheduler_step()
if self.validate_interval > -1 and self.current_iter % self.validate_interval == 0:
self.test()
if self.current_iter % self.weight_interval == 0:
self.save(self.current_iter, 'weight', keep=-1)
self.save(self.current_iter)
self.current_iter += 1
def test(self):
if not hasattr(self, 'test_dataloader'):
self.test_dataloader = build_dataloader(self.cfg.dataset.test,
is_train=False)
iter_loader = IterLoader(self.test_dataloader)
if self.max_eval_steps is None:
self.max_eval_steps = len(self.test_dataloader)
if self.metrics:
for metric in self.metrics.values():
metric.reset()
# set model.is_train = False
self.model.setup_train_mode(is_train=False)
for i in range(self.max_eval_steps):
if self.max_eval_steps < self.log_interval or i % self.log_interval == 0:
self.logger.info('Test iter: [%d/%d]' %
(i * self.world_size,
self.max_eval_steps * self.world_size))
data = next(iter_loader)
self.model.setup_input(data)
self.model.test_iter(metrics=self.metrics)
if self.is_save_img:
visual_results = {
}
current_paths = self.model.get_image_paths()
current_visuals = self.model.get_current_visuals()
if len(current_visuals) > 0 and list(
current_visuals.values())[0].shape == 4:
num_samples = list(current_visuals.values())[0].shape[0]
else:
num_samples = 1
for j in range(num_samples):
if j < len(current_paths):
short_path = os.path.basename(current_paths[j])
basename = os.path.splitext(short_path)[0]
else:
basename = '{:04d}_{:04d}'.format(i, j)
for k, img_tensor in current_visuals.items():
name = '%s_%s' % (basename, k)
if len(img_tensor.shape) == 4:
visual_results.update({
name: img_tensor[j]})
else:
visual_results.update({
name: img_tensor})
self.visual('visual_test',
visual_results=visual_results,
step=self.batch_id,
is_save_image=True)
if self.metrics:
for metric_name, metric in self.metrics.items():
self.logger.info("Metric {}: {:.4f}".format(
metric_name, metric.accumulate()))
def print_log(self):
losses = self.model.get_current_losses()
message = ''
if self.by_epoch:
message += 'Epoch: %d/%d, iter: %d/%d ' % (
self.current_epoch, self.epochs, self.inner_iter,
self.iters_per_epoch)
else:
message += 'Iter: %d/%d ' % (self.current_iter, self.total_iters)
message += f'lr: {
self.current_learning_rate:.3e} '
for k, v in losses.items():
message += '%s: %.3f ' % (k, v)
if self.enable_visualdl:
self.vdl_logger.add_scalar(k, v, step=self.global_steps)
if hasattr(self, 'step_time'):
message += 'batch_cost: %.5f sec ' % self.step_time
if hasattr(self, 'data_time'):
message += 'reader_cost: %.5f sec ' % self.data_time
if hasattr(self, 'ips'):
message += 'ips: %.5f images/s ' % self.ips
if hasattr(self, 'step_time'):
eta = self.step_time * (self.total_iters - self.current_iter)
eta = eta if eta > 0 else 0
eta_str = str(datetime.timedelta(seconds=int(eta)))
message += f'eta: {
eta_str}'
if paddle.device.is_compiled_with_cuda():
max_mem_reserved_str = f" max_mem_reserved: {
paddle.device.cuda.max_memory_reserved() // (1024 ** 2)} MB"
max_mem_allocated_str = f" max_mem_allocated: {
paddle.device.cuda.max_memory_allocated() // (1024 ** 2)} MB"
message += max_mem_reserved_str
message += max_mem_allocated_str
# print the message
self.logger.info(message)
@property
def current_learning_rate(self):
for optimizer in self.model.optimizers.values():
return optimizer.get_lr()
def visual(self,
results_dir,
visual_results=None,
step=None,
is_save_image=False):
"""
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









