









提示:以下是本篇文章正文内容,下面案例可供参考(适用于flink1.13+)
一、flink join维表案例
- 背景:flink sql join 维表。job业务不复杂,job写入性能比较差。维表数据大约每天100w条数据(有其他job实时生成维表数据),维表数据只保存近5天数据。
- job 资源使用情况:TM 1cpu,4Gb内存,1个并行度
- 性能问题:job每秒写数据慢(已检查:checkpoint生成很快,生成的文件也小)
- 开始优化
优化思路:对维表参数的优化参数配置
对定义维表参数的优化参数配置(下面定义维表参数flink官网有参数或类似的参数。提供思路)
'cache' = 'LRU' --缓存策略
'async' = 'true',
'cacheEmpty' = 'false',
'cacheSize'='5000000', --缓存条数500万条(思路:希望将所有维表数据全部缓存到内存中)
'cacheTTLMs' = '10800000' --缓存维表时间(缓存3小时,不希望缓存过段或过长导致查源数据库表)
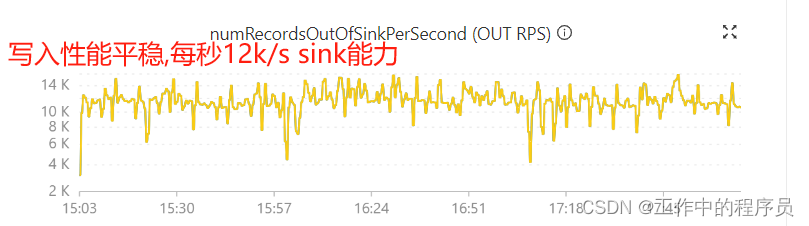
运行后性能比之前没有添加参数要快(相同资源下由4k/s->提升到6k/s)
当以为调优成功时,发现运行一段时间job开始下降。由处理能力6k/s下降到几百条/s,数据有挤压,延时数据开始增大。
之前cpu不变的情况下4Gtaskmanager 内存 30分钟后性能开始下降;
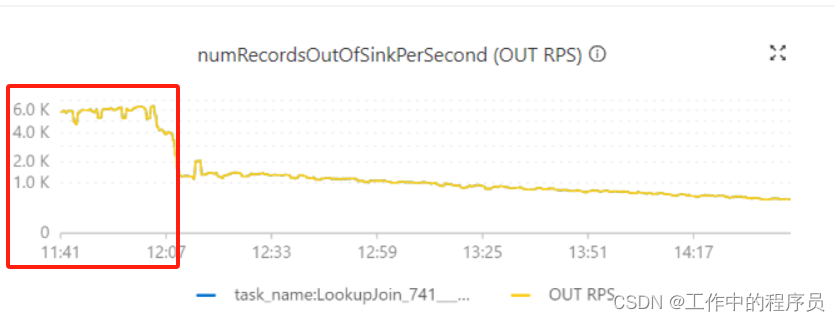
现在cpu不变的情况下8Gtaskmanager 内存 60分钟后性能开始下降(处理性能下降导致数据开始有堆积);
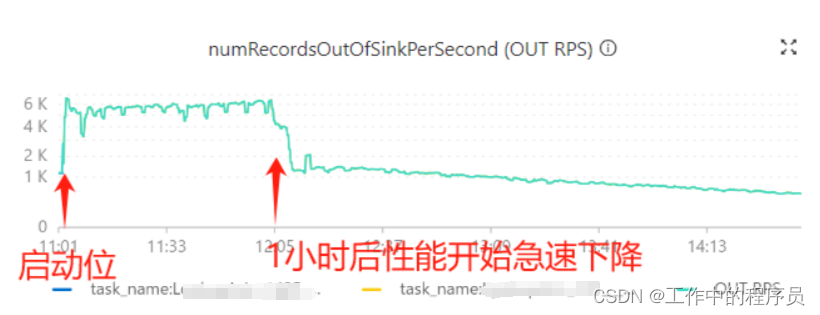
后面开始直接对job tm 增加CPU,增加内存都是运行一小段时间,性能还是开始下降.
观察生成的DAG图发现有节点一直处于busy

继续各种尝试。开始对busy的节点增加并行度(阿里云flink有专家模式支持,flink开源版不支持此功能)
table.exec.split-slot-sharing-group-per-vertex=false
(作业链与处理槽共享组(默认为false),开启后在针对某个操作算子增加并行度和cu等资源时,不与其他槽位共享资源,单独增加额外资源 ###有用的参数)
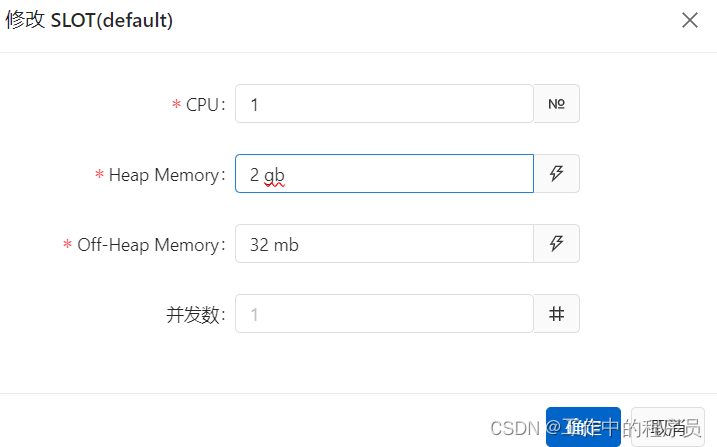

总结:a.先优化维表参数,当优化完维表参数后增加资源运行一段时间性能还是下降,开始对节点单独做调整(某个节点性能较弱,单独增加并行度和资源)。如果对整体job添加资源也是可以解决问题,但比较浪费资源。建议针对性能节点单独处理比较好。
二、flink 双流join案例
背景:flink 双流join,处理完后写表,业务逻辑不复杂
问题现象:job 处理性能差,消费数据有大量堆积延时。
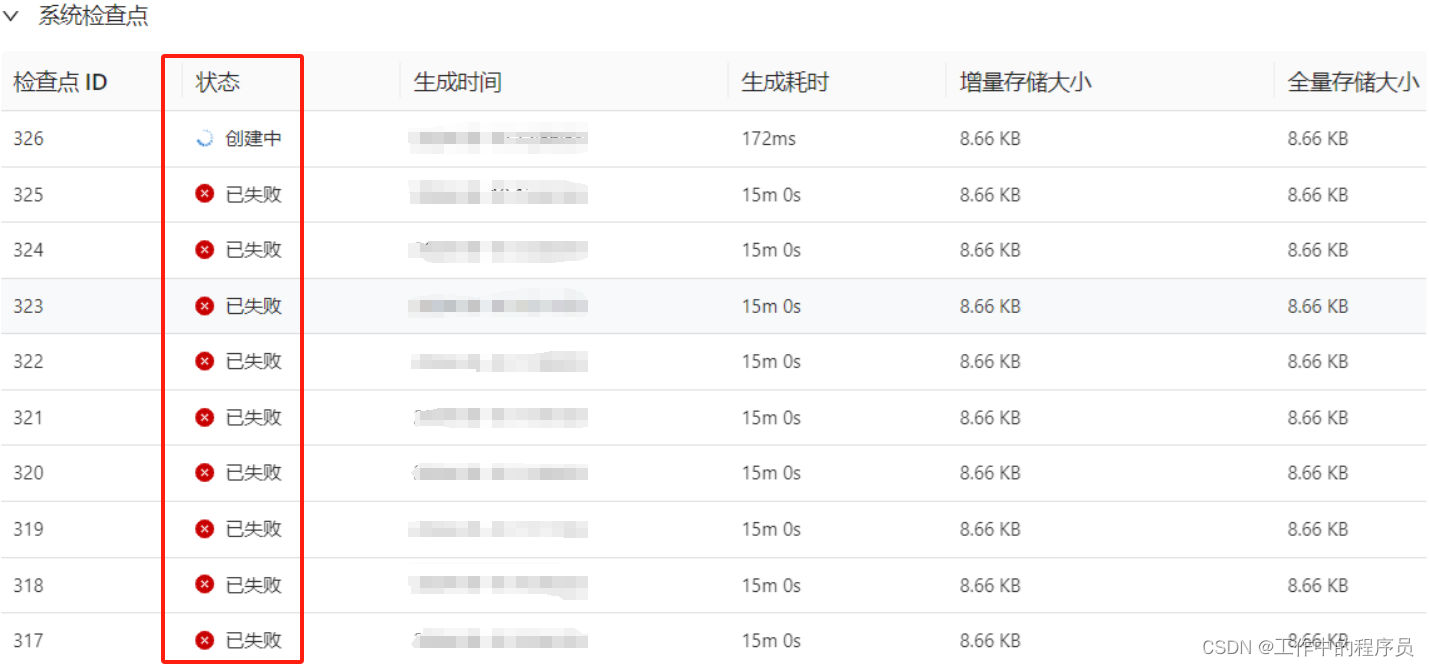
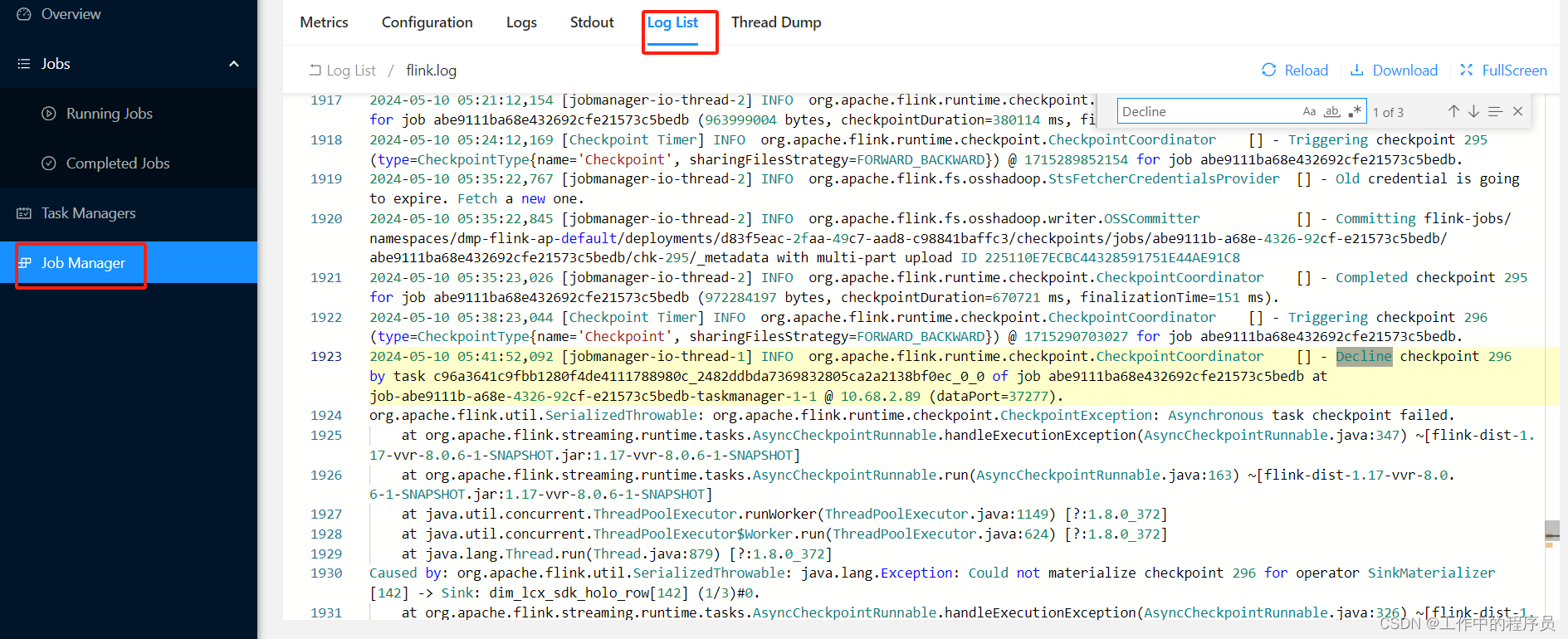
表现问题现象:checkpoint 生成很久后失败(或全部失败或频繁失败)
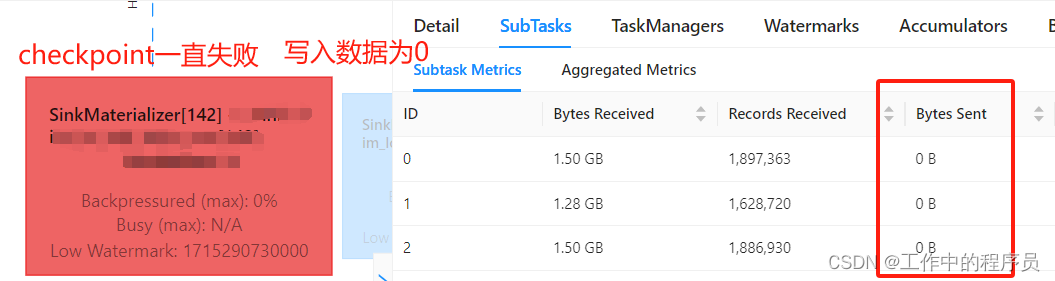
可以看下面flink生成的DAG图末尾的sink写表节点已经完全处于卡住状态(0条写入)
后面对这个job增加资源增加并行度(当分配很少资源时,job运行半天后CP开始一直失败)时,整个job刚开始只能成功创建一个CP后面创建CP全部失败。
- 调查发现:作业DAG有个SinkMaterializer算子节点(一般双流join会有这个节点,其他操作没有这个节点。且这个节点一直处于busy 如上图),而且检查checkpoint历史时发现该算子state越来越大。
- SinkMaterializer的算子节点作用:这个算子将输入的记录以upsert key作区分保存到state中,
并为下游算子提供一个upsert视图。目的:为了解决changelog流事件乱序造成了结果不正确的问题. - 问题解决:根据上面查的资料,在根据自己的业务情况(晚来的右表数据大部分是一样的,可以理解一对多,同时即使右表同一个Key下有少量个别字段有少表不一样对业务也不会造成影响)。是可以接受极少异常情况晚来的相同key的值数据。
- 做法:对job添加参数:table.exec.sink.upsert-materialize=NONE (此参数开源flink,阿里云flink都通用)
运行后作业DAG就没有SinkMaterializer算子节点,且job处理性能极强(tm:1cpu,4Gb 每秒sink接近30k/s)
- 参数描述 : 由于分布式系统中的 shuffle 会造成 Changelog 数据的乱序,所以 sink 接收到的数据可能在全局的 upsert 中乱序,所以要在 upsert sink 之前添加一个 upsert 物化算子。该算子接收上游 changelog
数据,并且给下游生成一个 upsert 视图。这个参数用于控制物化算子的添加- 注意事项 : A. 默认情况下,在唯一 key 遇到分布式乱序时,该物化算子会被添加,也可以选择不物化(NONE),或者是强制物化(FORCE) B.
可选值有:NONE、AUTO、FORCE
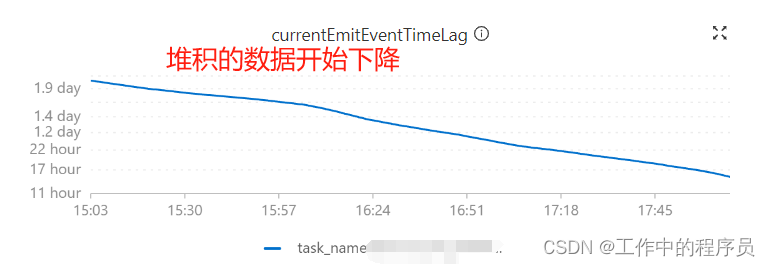
10分钟内将延时6个小时数据给全部追上(之前没有加那个参数,tm比这个资源配置高,每秒几十条数据,运行半天后job卡住最后0写入)
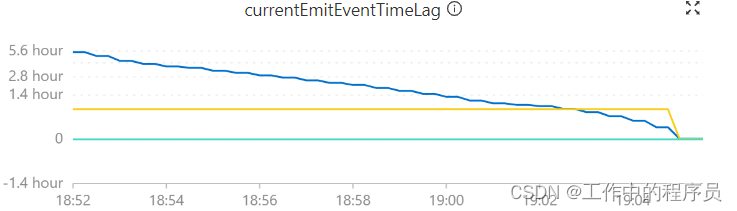
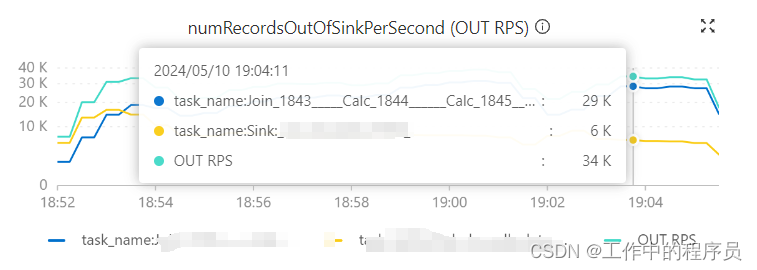
-
添加完那个参数后CP生成很快很稳定,CP也大幅度变小。再无失败CP.
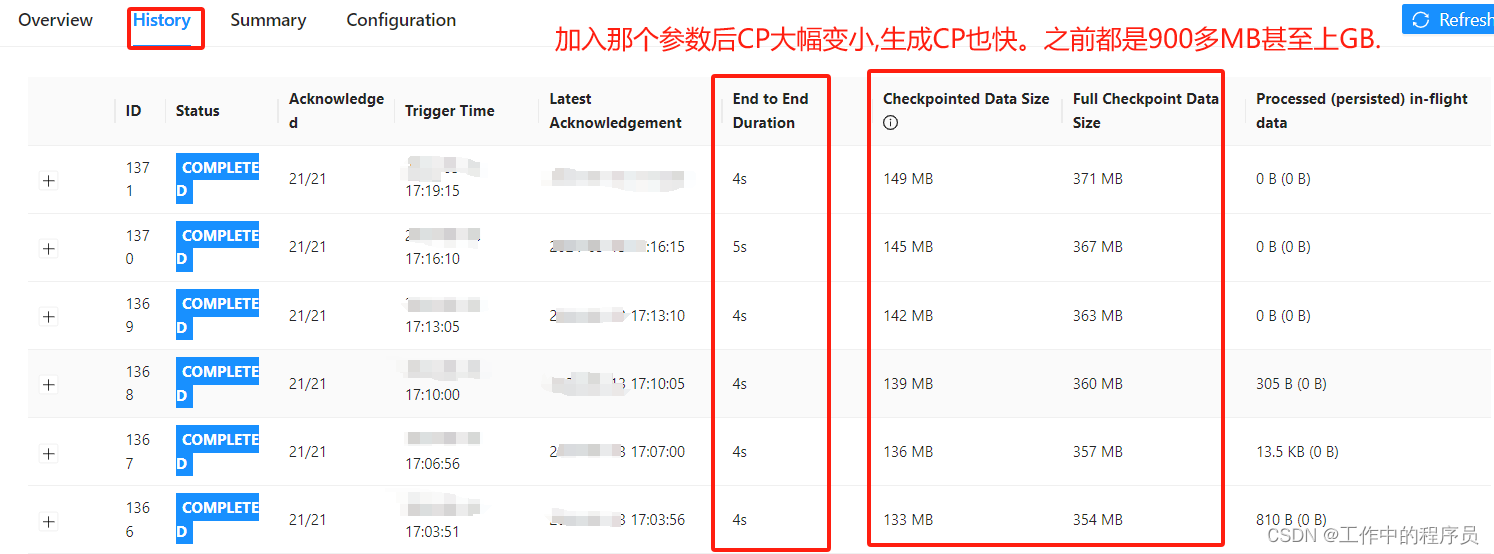
-
小总结:不加那个参数就不会有sink matertilizer那个节点。之前那个节点State比较大,不加的话不会有排序操作,加上的话会把数据缓存下来,修正乱序的问题,所以State会大。
三、总结
- 上面是两个真实优化案例。优化的方向不同,应该是普通job的优化(维表属性定义和节点调优),一个是有job的写运行机制优化(结合自身业务提升job性能)
CheckPoint说明:
每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个CheckpointCoordinator,CheckpointCoordinator全权负责本应用的快照制作。
- CheckpointCoordinator周期性的向该流应用的所有source算子发送barrier;
- 当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状 态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告 自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理;
- 下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身 快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理;
- 每个算子按照上面步骤不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
- 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败 ;
- 一旦发生了错误,Flink的JobManager会告诉 task需要从最新的checkpoint中恢复,它可以是全量的或者是增量的。之后TaskManager从分布式系统中下载checkpoint文件, 然后从中恢复状态。














 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









