







1.基本概念
满二叉树
满二叉树:如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。
如图所示:
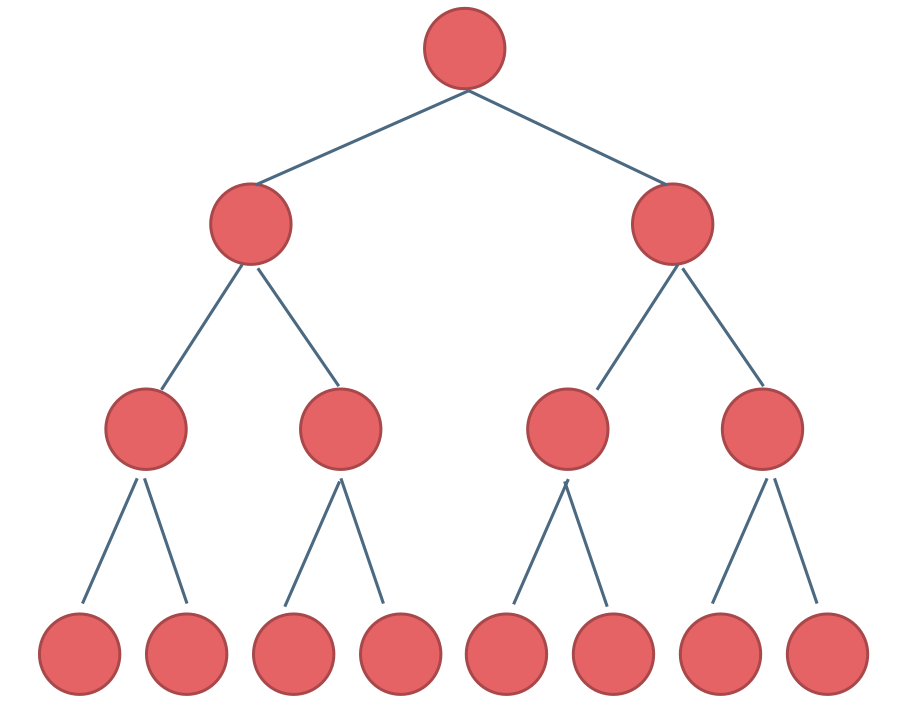
这棵二叉树为满二叉树,也可以说深度为k,有2^k-1个节点的二叉树。
完全二叉树
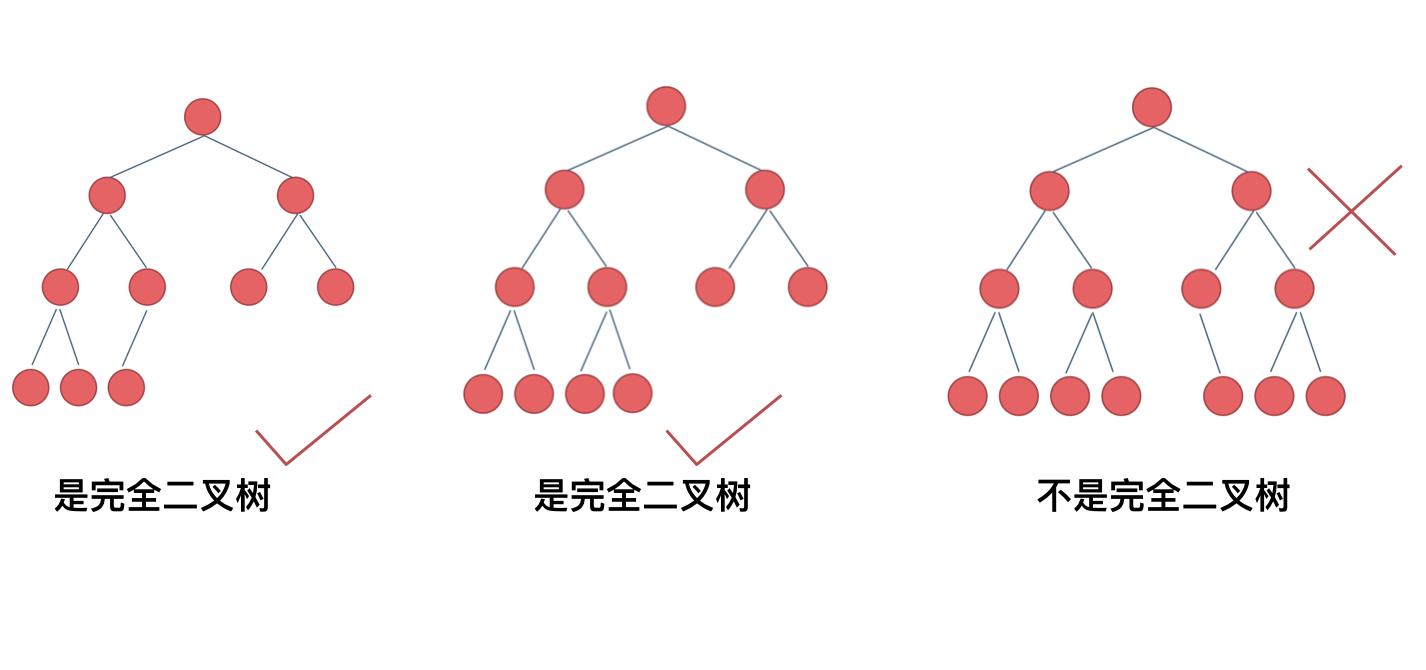
什么是完全二叉树?
完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层(h从1开始),则该层包含 1~ 2^(h-1) 个节点。
大家要自己看完全二叉树的定义,很多同学对完全二叉树其实不是真正的懂了。
我来举一个典型的例子如题:
二叉搜索树
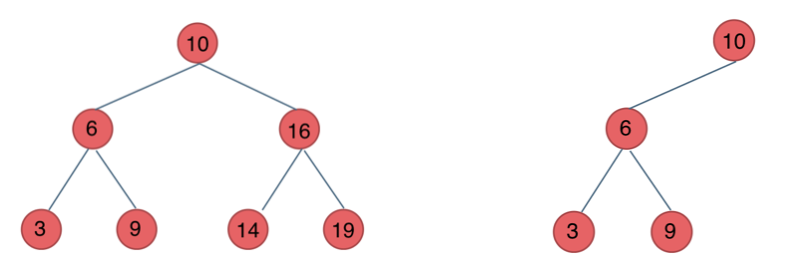
前面介绍的树,都没有数值的,而二叉搜索树是有数值的了,二叉搜索树是一个有序树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
下面这两棵树都是搜索树
平衡二叉搜索树
平衡二叉搜索树:又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
如图:
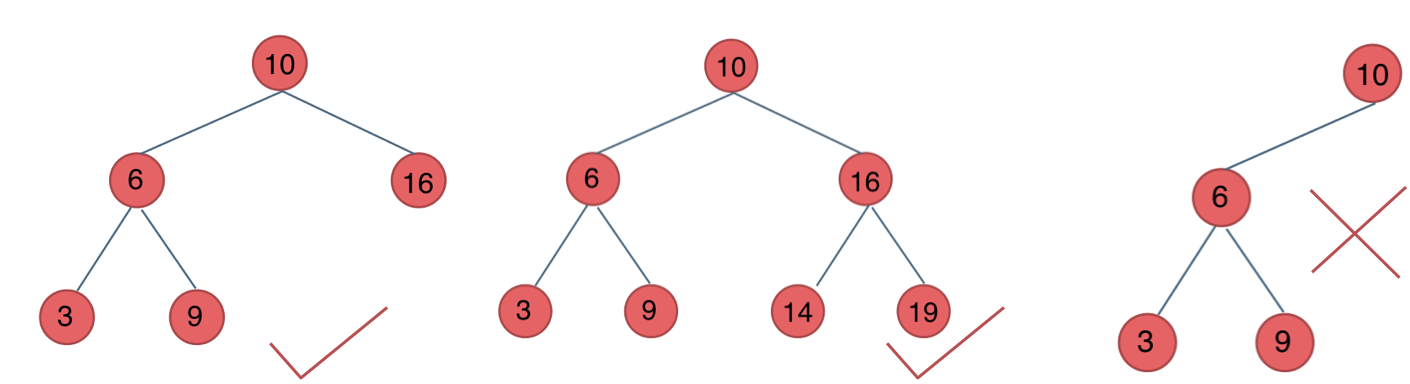
最后一棵 不是平衡二叉树,因为它的左右两个子树的高度差的绝对值超过了1。
C++中map、set、multimap,multiset的底层实现都是平衡二叉搜索树,所以map、set的增删操作时间时间复杂度是logn,注意我这里没有说unordered_map、unordered_set,unordered_map、unordered_set底层实现是哈希表。
二叉树的存储方式
二叉树可以链式存储,也可以顺序存储。
那么链式存储方式就用指针, 顺序存储的方式就是用数组。
顾名思义就是顺序存储的元素在内存是连续分布的,而链式存储则是通过指针把分布在各个地址的节点串联一起。
链式存储如图:
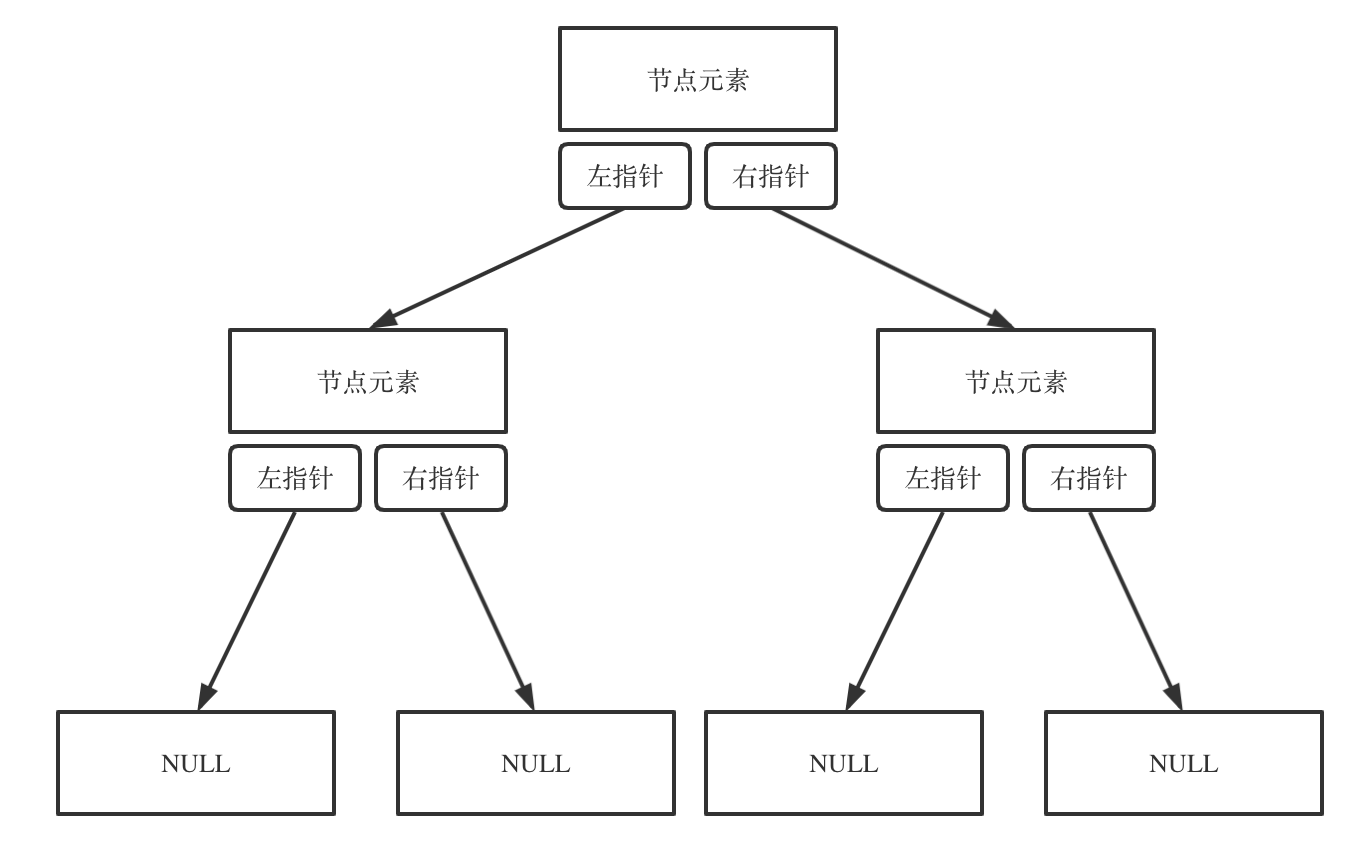
链式存储是大家很熟悉的一种方式,那么我们来看看如何顺序存储呢?
其实就是用数组来存储二叉树,顺序存储的方式如图:
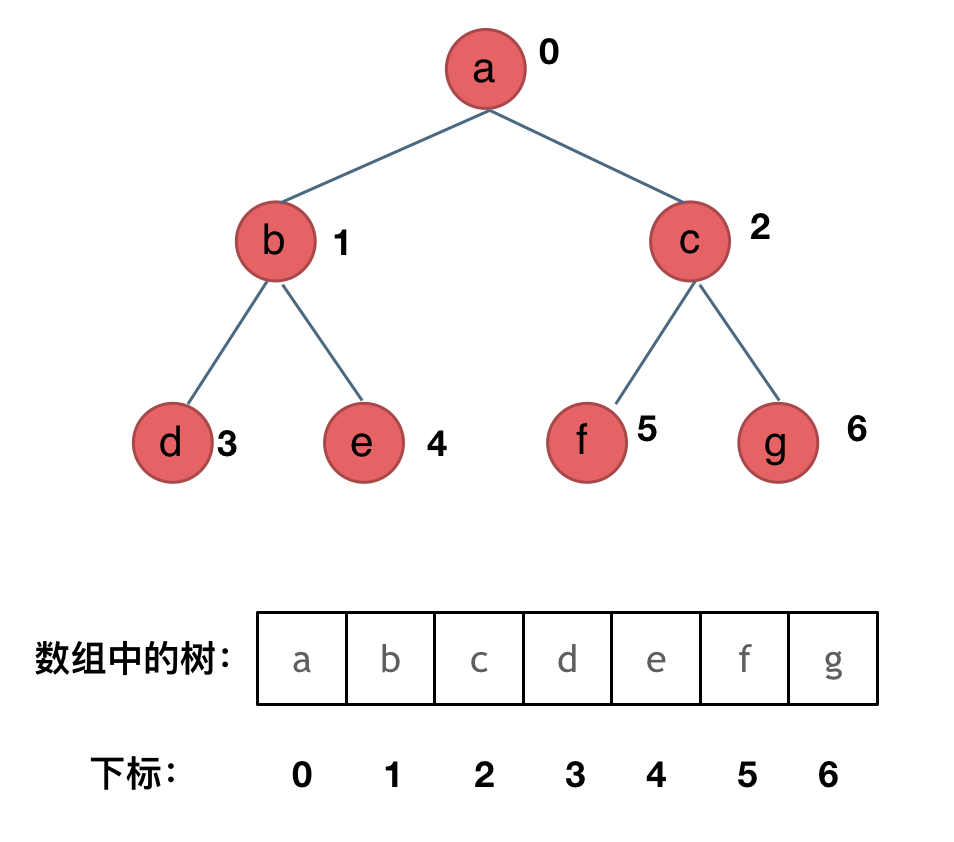
用数组来存储二叉树如何遍历的呢?
如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。
但是用链式表示的二叉树,更有利于我们理解,所以一般我们都是用链式存储二叉树。
所以大家要了解,用数组依然可以表示二叉树。
二叉树的遍历方式
二叉树主要有两种遍历方式:
- 深度优先遍历:先往深走,遇到叶子节点再往回走。
- 广度优先遍历:一层一层的去遍历。
这两种遍历是图论中最基本的两种遍历方式,后面在介绍图论的时候 还会介绍到。
那么从深度优先遍历和广度优先遍历进一步拓展,才有如下遍历方式:
- 深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
- 广度优先遍历
- 层次遍历(迭代法)
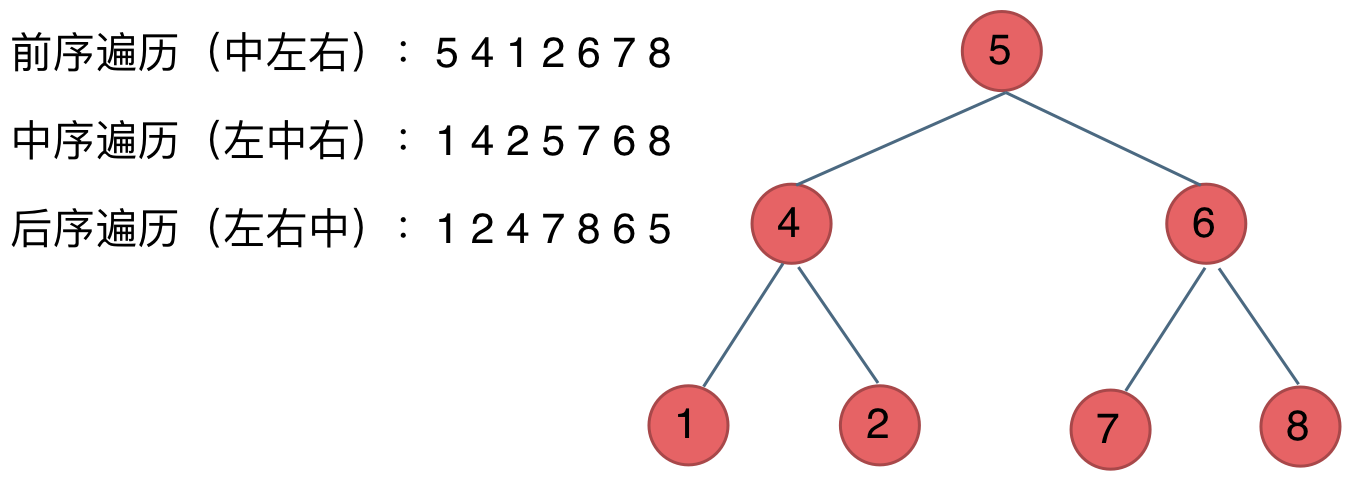
在深度优先遍历中:有三个顺序,前中后序遍历, 有同学总分不清这三个顺序,经常搞混,我这里教大家一个技巧。
这里前中后,其实指的就是中间节点的遍历顺序,只要大家记住 前中后序指的就是中间节点的位置就可以了。
看如下中间节点的顺序,就可以发现,中间节点的顺序就是所谓的遍历方式
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中
大家可以对着如下图,看看自己理解的前后中序有没有问题。
最后再说一说二叉树中深度优先和广度优先遍历实现方式,我们做二叉树相关题目,经常会使用递归的方式来实现深度优先遍历,也就是实现前中后序遍历,使用递归是比较方便的。
之前我们讲栈与队列的时候,就说过栈其实就是递归的一种实现结构,也就说前中后序遍历的逻辑其实都是可以借助栈使用非递归的方式来实现的。
而广度优先遍历的实现一般使用队列来实现,这也是队列先进先出的特点所决定的,因为需要先进先出的结构,才能一层一层的来遍历二叉树。
这里其实我们又了解了栈与队列的一个应用场景了。
二叉树的定义
刚刚我们说过了二叉树有两种存储方式顺序存储,和链式存储,顺序存储就是用数组来存,这个定义没啥可说的,我们来看看链式存储的二叉树节点的定义方式。
C++代码如下:
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
大家会发现二叉树的定义 和链表是差不多的,相对于链表 ,二叉树的节点里多了一个指针, 有两个指针,指向左右孩子。
这里要提醒大家要注意二叉树节点定义的书写方式。
在现场面试的时候 面试官可能要求手写代码,所以数据结构的定义以及简单逻辑的代码一定要锻炼白纸写出来。
因为我们在刷leetcode的时候,节点的定义默认都定义好了,真到面试的时候,需要自己写节点定义的时候,有时候会一脸懵逼!
总结
二叉树是一种基础数据结构,在算法面试中都是常客,也是众多数据结构的基石。
本篇我们介绍了二叉树的种类、存储方式、遍历方式以及定义,比较全面的介绍了二叉树各个方面的重点,帮助大家扫一遍基础。
说到二叉树,就不得不说递归,很多同学对递归都是又熟悉又陌生,递归的代码一般很简短,但每次都是一看就会,一写就废。
2. Leetcode 144 二叉树的前序遍历
难度:⭐️(递归)/⭐️⭐️(迭代)
前序遍历(递归法)
这里帮助大家确定下来递归算法的三个要素。每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
-
确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
-
确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
-
确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
以下以前序遍历为例:
确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值,除了这一点就不需要再处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
void traversal(TreeNode* cur, vector<int>& vec)
确定终止条件:在递归的过程中,如何算是递归结束了呢,当然是当前遍历的节点是空了,那么本层递归就要结束了,所以如果当前遍历的这个节点是空,就直接return,代码如下:
if (cur == NULL) return;
确定单层递归的逻辑:前序遍历是中左右的循序,所以在单层递归的逻辑,是要先取中节点的数值,代码如下:
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
单层递归的逻辑就是按照中左右的顺序来处理的,这样二叉树的前序遍历,基本就写完了,再看一下完整代码(递归):
class Solution {
public:
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
traversal(root, result);
return result;
}
};
复杂度分析:时间O(n) 空间O(h), h为二叉树的最大深度
前序遍历(迭代法)
我们先看一下前序遍历。
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子。
为什么要先加入 右孩子,再加入左孩子呢? 因为这样出栈的时候才是中左右的顺序。
动画如下:

不难写出如下代码: (注意代码中空节点不入栈)
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
result.push_back(node->val);
if (node->right) st.push(node->right); // 右(空节点不入栈)
if (node->left) st.push(node->left); // 左(空节点不入栈)
}
return result;
}
};
复杂度分析:时间O(n) 空间O(h), h为二叉树的最大深度
此时会发现貌似使用迭代法写出前序遍历并不难,确实不难。
此时是不是想改一点前序遍历代码顺序就把中序遍历搞出来了?
其实还真不行!
但接下来,再用迭代法写中序遍历的时候,会发现套路又不一样了,目前的前序遍历的逻辑无法直接应用到中序遍历上。
3.Leetcode 145 二叉树的后序遍历
难度:⭐️(递归)/⭐️⭐️(迭代)
后序遍历(递归法)
前序遍历写出来之后,中序和后序遍历就不难理解了,代码如下:
后序遍历(递归):
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
vec.push_back(cur->val); // 中
}复杂度分析:时间O(n) 空间O(h), h为二叉树的最大深度
后序遍历(迭代法)
再来看后序遍历,先序遍历是中左右,后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了,如下图:

所以后序遍历只需要前序遍历的代码稍作修改就可以了,代码如下:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
if (node->right) st.push(node->right); // 空节点不入栈
}
reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
return result;
}
};
复杂度分析:时间O(n) 空间O(h), h为二叉树的最大深度
4.Leetcode 94 二叉树的中序遍历
难度: ⭐️(递归)/⭐️⭐️⭐️(迭代)
中序遍历(递归法)
中序遍历(递归):
void traversal(TreeNode* cur, vector<int>& vec) {
if (cur == NULL) return;
traversal(cur->left, vec); // 左
vec.push_back(cur->val); // 中
traversal(cur->right, vec); // 右
}
复杂度分析:时间O(n) 空间O(h), h为二叉树的最大深度
中序遍历(迭代法)
为了解释清楚,我说明一下 刚刚在迭代的过程中,其实我们有两个操作:
- 处理:将元素放进result数组中
- 访问:遍历节点
分析一下为什么刚刚写的前序遍历的代码,不能和中序遍历通用呢,因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
动画如下:

中序遍历,可以写出如下代码:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
TreeNode* cur = root;
while (cur != NULL || !st.empty()) {
if (cur != NULL) { // 指针来访问节点,访问到最底层
st.push(cur); // 将访问的节点放进栈
cur = cur->left; // 左
} else {
cur = st.top(); // 从栈里弹出的数据,就是要处理的数据(放进result数组里的数据)
st.pop();
result.push_back(cur->val); // 中
cur = cur->right; // 右
}
}
return result;
}
};
复杂度分析:时间O(n) 空间O(h), h为二叉树的最大深度
补充:中序遍历的迭代法,与前序/后序遍历不同。(后者:遍历子节点时,顺便把另外一个孩子的节点也放进栈,每次从栈顶弹出一个元素;前者:遍历至一个孩子的末端,再返回父亲节点并弹出,然后遍历另一个孩子)
二叉树的统一迭代法
#思路
此时我们在二叉树:一入递归深似海,从此offer是路人 (opens new window)中用递归的方式,实现了二叉树前中后序的遍历。
在二叉树:听说递归能做的,栈也能做! (opens new window)中用栈实现了二叉树前后中序的迭代遍历(非递归)。
之后我们发现迭代法实现的先中后序,其实风格也不是那么统一,除了先序和后序,有关联,中序完全就是另一个风格了,一会用栈遍历,一会又用指针来遍历。
实践过的同学,也会发现使用迭代法实现先中后序遍历,很难写出统一的代码,不像是递归法,实现了其中的一种遍历方式,其他两种只要稍稍改一下节点顺序就可以了。
其实针对三种遍历方式,使用迭代法是可以写出统一风格的代码!
重头戏来了,接下来介绍一下统一写法。
我们以中序遍历为例,在二叉树:听说递归能做的,栈也能做! (opens new window)中提到说使用栈的话,无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况。
那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
如何标记呢,就是要处理的节点(父亲节点)放入栈之后,紧接着放入一个空指针作为标记。 这种方法也可以叫做标记法。
#迭代法中序遍历
中序遍历代码如下:(详细注释)
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
if (node->right) st.push(node->right); // 添加右节点(空节点不入栈)
st.push(node); // 添加中节点
st.push(NULL); // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node->left) st.push(node->left); // 添加左节点(空节点不入栈)
} else { // 只有遇到空节点的时候,才将下一个节点放进结果集
st.pop(); // 将空节点弹出
node = st.top(); // 重新取出栈中元素
st.pop();
result.push_back(node->val); // 加入到结果集
}
}
return result;
}
};
看代码有点抽象我们来看一下动画(中序遍历):

动画中,result数组就是最终结果集。
可以看出我们将访问的节点直接加入到栈中,但如果是处理的节点则后面放入一个空节点, 这样只有空节点弹出的时候,才将下一个节点放进结果集。
此时我们再来看前序遍历代码。
#迭代法前序遍历
迭代法前序遍历代码如下: (注意此时我们和中序遍历相比仅仅改变了两行代码的顺序)
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop();
if (node->right) st.push(node->right); // 右
if (node->left) st.push(node->left); // 左
st.push(node); // 中
st.push(NULL);
} else {
st.pop();
node = st.top();
st.pop();
result.push_back(node->val);
}
}
return result;
}
};
#迭代法后序遍历
后续遍历代码如下: (注意此时我们和中序遍历相比仅仅改变了两行代码的顺序)
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> result;
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop();
st.push(node); // 中
st.push(NULL);
if (node->right) st.push(node->right); // 右
if (node->left) st.push(node->left); // 左
} else {
st.pop();
node = st.top();
st.pop();
result.push_back(node->val);
}
}
return result;
}
};
#总结
此时我们写出了统一风格的迭代法,不用在纠结于前序写出来了,中序写不出来的情况了。
但是统一风格的迭代法并不好理解,而且想在面试直接写出来还有难度的。
所以大家根据自己的个人喜好,对于二叉树的前中后序遍历,选择一种自己容易理解的递归和迭代
法。
5.Leetcode 102 二叉树的层序遍历
难度: ⭐️⭐️(递归)/⭐️⭐️⭐️(迭代)
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。

层序遍历一个二叉树。就是从左到右一层一层的去遍历二叉树。这种遍历的方式和我们之前讲过的都不太一样。
需要借用一个辅助数据结构即队列来实现,队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的逻辑。
而这种层序遍历方式就是图论中的广度优先遍历,只不过我们应用在二叉树上。
使用队列实现二叉树广度优先遍历,动画如下:

这样就实现了层序从左到右遍历二叉树。
代码如下:这份代码也可以作为二叉树层序遍历的模板,打十个就靠它了。
复杂度分析:时间O(n),空间O(n),为单层(最下层)最大可存储节点数
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*> que;
if (root != NULL) que.push(root);
vector<vector<int>> result;
while (!que.empty()) {
int size = que.size();
vector<int> vec;
// 这里一定要使用固定大小size,不要使用que.size(),因为que.size是不断变化的
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if (node->left) que.push(node->left);
if (node->right) que.push(node->right);
}
result.push_back(vec);
}
return result;
}
};
# 递归法
class Solution {
public:
void order(TreeNode* cur, vector<vector<int>>& result, int depth)
{
if (cur == nullptr) return;
if (result.size() == depth) result.push_back(vector<int>());
result[depth].push_back(cur->val);
order(cur->left, result, depth + 1);
order(cur->right, result, depth + 1);
}
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> result;
int depth = 0;
order(root, result, depth);
return result;
}
};
复杂度分析:时间O(n),空间O(h),为二叉树的最大深度
6.Leetcode 107 二叉树的层次遍历 II
难度: ⭐️⭐️(递归)/⭐️⭐️⭐️(迭代)

相对于102.二叉树的层序遍历,就是最后把result数组反转一下就可以了。
7.Leetcode 199 二叉树的右视图

难度: ⭐️⭐️(递归)
层序遍历的时候,判断是否遍历到单层的最后面的元素,如果是,就放进result数组中,随后返回result就可以了。
代码:递归
8.Leetcode 637 二叉树的层平均值

难度:⭐️⭐️(递归)
本题就是层序遍历的时候把一层求个总和在取一个均值。
代码:递归
9.Leetcode 429 N层树的层序遍历
难度:⭐️⭐️(递归)
这道题依旧是模板题,只不过一个节点有多个孩子了
代码:递归
10.Leetcode 515 在每个树行中找最大值
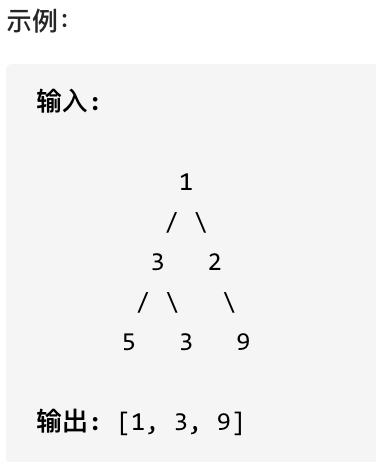
难度:⭐️⭐️(递归)
层序遍历,取每一层的最大值
代码:递归
11.Leetcode 116 填充每个节点的下一个右侧节点指针
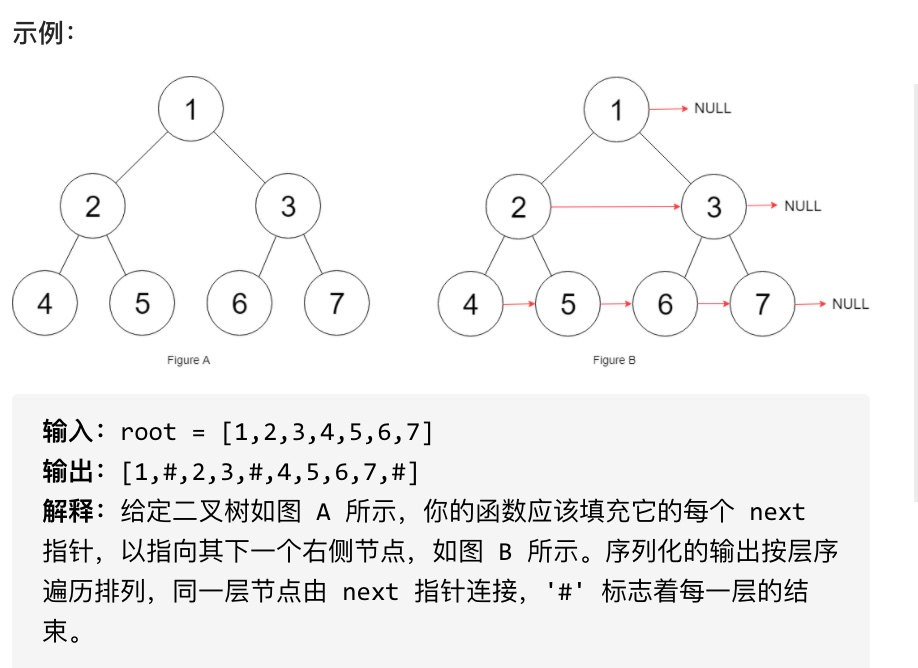
难度:⭐️⭐️⭐️(递归)
本题依然是层序遍历,只不过在单层遍历的时候记录一下本层的头部节点,然后在遍历的时候让前一个节点指向本节点就可以了
12.Leetcode 117 填充每个节点的下一个右侧节点指针II
难度:⭐️⭐️⭐️(递归)
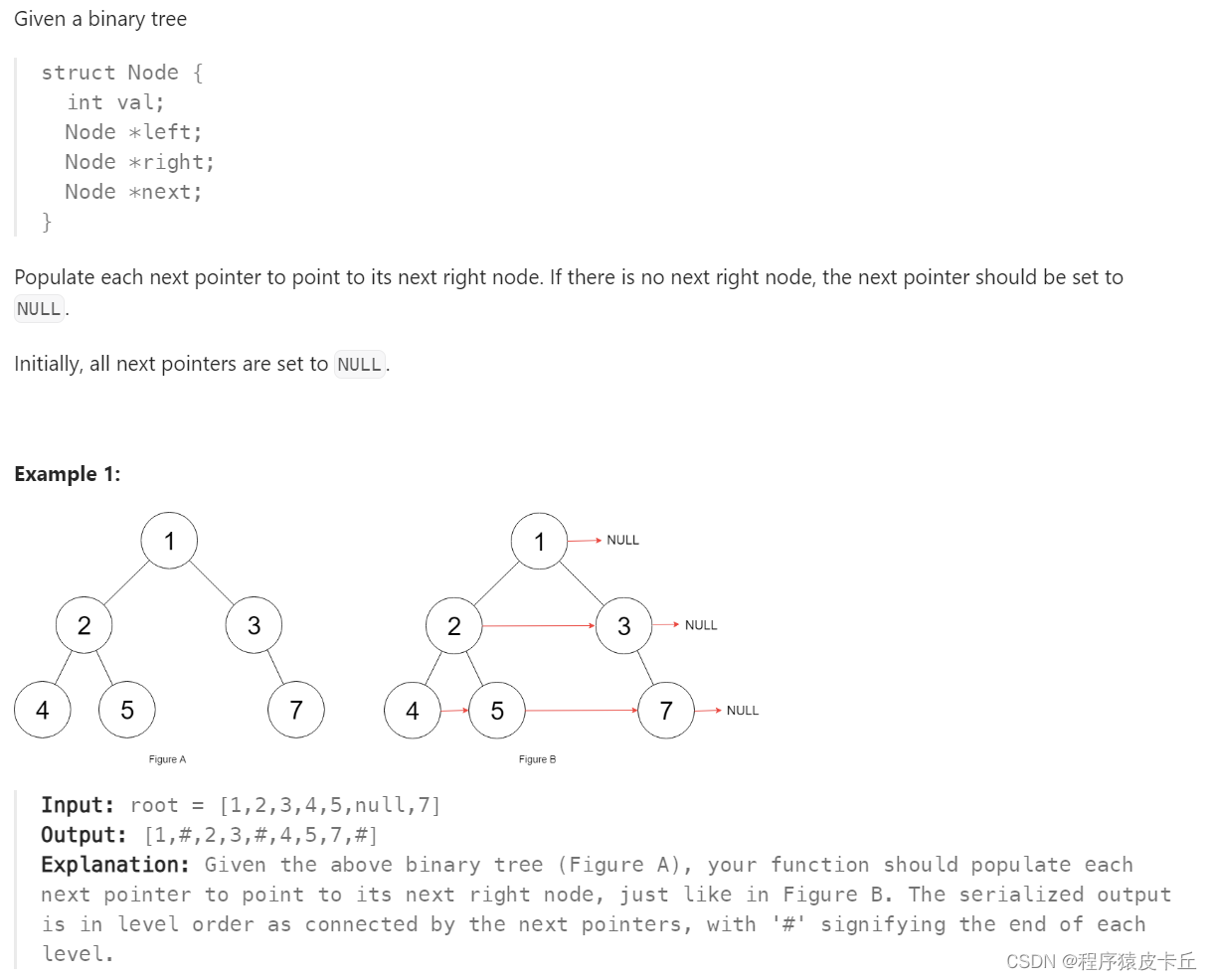
这道题目说是二叉树,但116题目说是完整二叉树,其实没有任何差别,一样的代码一样的逻辑一样的味道
代码:递归+双指针
13.Leetcode 104 二叉树的最大深度
难度:⭐️⭐️(迭代:层序)/⭐️(递归:后序)/⭐️⭐️⭐️(递归:前序)
给定二叉树 [3,9,20,null,null,15,7],

返回它的最大深度 3 。
迭代
使用迭代法的话,使用层序遍历是最为合适的,因为最大的深度就是二叉树的层数,和层序遍历的方式极其吻合。
在二叉树中,一层一层的来遍历二叉树,记录一下遍历的层数就是二叉树的深度,如图所示:
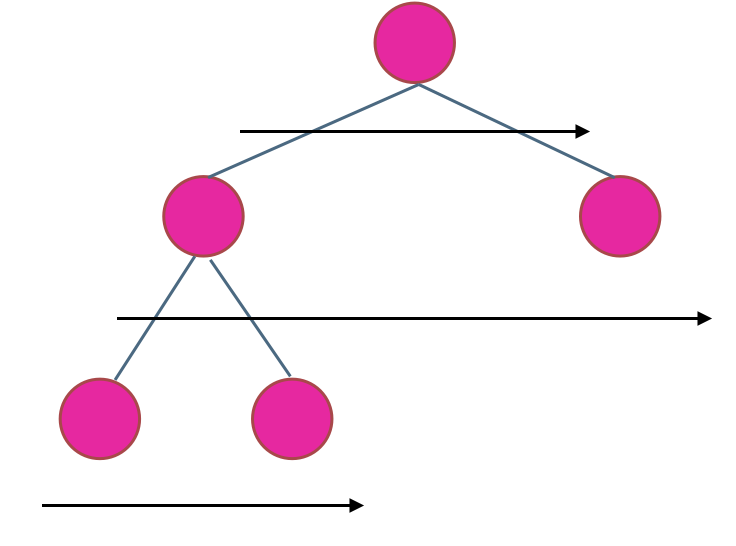
所以这道题的迭代法就是一道模板题,可以使用二叉树层序遍历的模板来解决的。
递归
本题可以使用前序(中左右),也可以使用后序遍历(左右中),使用前序求的就是深度,使用后序求的是高度。
- 二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数或者节点数(取决于深度从0开始还是从1开始)
- 二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数或者节点数(取决于高度从0开始还是从1开始)
而根节点的高度就是二叉树的最大深度,所以本题中我们通过后序求的根节点高度来求的二叉树最大深度。
这一点其实是很多同学没有想清楚的,很多题解同样没有讲清楚。
我先用后序遍历(左右中)来计算树的高度。
1.确定递归函数的参数和返回值:参数就是传入树的根节点,返回就返回这棵树的深度,所以返回值为int类型。
代码如下:
int getdepth(TreeNode* node)
2.确定终止条件:如果为空节点的话,就返回0,表示高度为0。
代码如下:
if (node == NULL) return 0;
3.确定单层递归的逻辑:先求它的左子树的深度,再求右子树的深度,最后取左右深度最大的数值 再+1 (加1是因为算上当前中间节点)就是目前节点为根节点的树的深度。
代码如下:
int leftdepth = getdepth(node->left); // 左
int rightdepth = getdepth(node->right); // 右
int depth = 1 + max(leftdepth, rightdepth); // 中
return depth;
所以整体c++代码如下:
class solution {
public:
int getdepth(TreeNode* node) {
if (node == NULL) return 0;
int leftdepth = getdepth(node->left); // 左
int rightdepth = getdepth(node->right); // 右
int depth = 1 + max(leftdepth, rightdepth); // 中
return depth;
}
int maxDepth(TreeNode* root) {
return getdepth(root);
}
};
代码精简之后c++代码如下:
class solution {
public:
int maxDepth(TreeNode* root) {
if (root == null) return 0;
return 1 + max(maxDepth(root->left), maxDepth(root->right));
}
};
精简之后的代码根本看不出是哪种遍历方式,也看不出递归三部曲的步骤,所以如果对二叉树的操作还不熟练,尽量不要直接照着精简代码来学。
本题当然也可以使用前序,代码如下:(充分表现出求深度回溯的过程)
class solution {
public:
int result;
void getdepth(TreeNode* node, int depth) {
result = depth > result ? depth : result; // 中
if (node->left == NULL && node->right == NULL) return ;
if (node->left) { // 左
depth++; // 深度+1
getdepth(node->left, depth);
depth--; // 回溯,深度-1
}
if (node->right) { // 右
depth++; // 深度+1
getdepth(node->right, depth);
depth--; // 回溯,深度-1
}
return ;
}
int maxDepth(TreeNode* root) {
result = 0;
if (root == NULL) return result;
getdepth(root, 1);
return result;
}
};
可以看出使用了前序(中左右)的遍历顺序,这才是真正求深度的逻辑!
注意以上代码是为了把细节体现出来,简化一下代码如下:
class solution {
public:
int result;
void getdepth(TreeNode* node, int depth) {
result = depth > result ? depth : result; // 中
if (node->left == NULL && node->right == NULL) return ;
if (node->left) { // 左
getdepth(node->left, depth + 1);
}
if (node->right) { // 右
getdepth(node->right, depth + 1);
}
return ;
}
int maxDepth(TreeNode* root) {
result = 0;
if (root == 0) return result;
getdepth(root, 1);
return result;
}
};15.Leetcode 226 翻转二叉树
难度:⭐️(前序/后序)/⭐️⭐️(层序)/⭐️⭐️⭐️⭐️(中序)
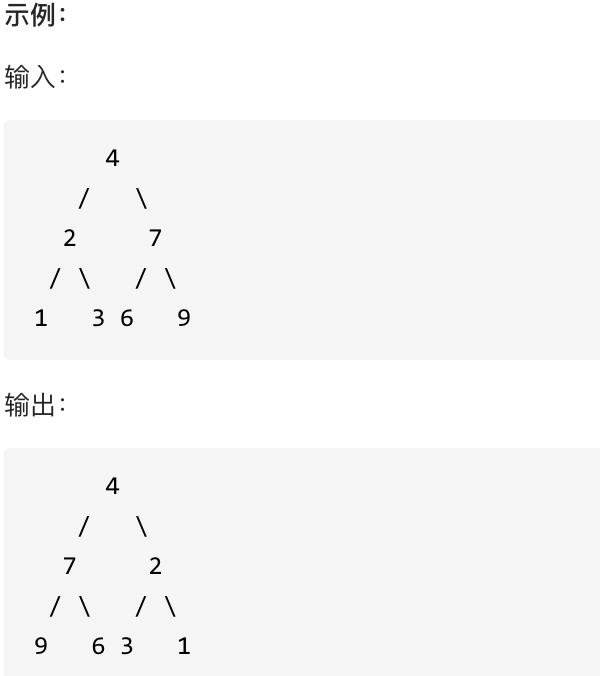
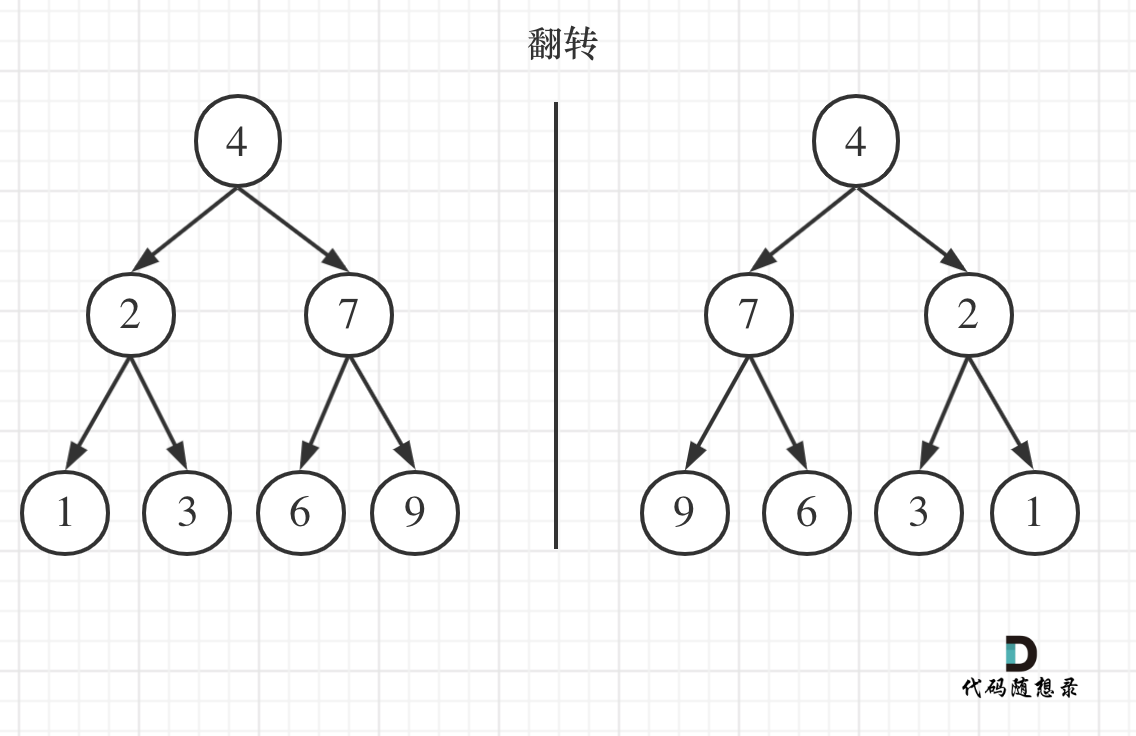
可以发现想要翻转它,其实就把每一个节点的左右孩子交换一下就可以了。
关键在于遍历顺序,前中后序应该选哪一种遍历顺序? (一些同学这道题都过了,但是不知道自己用的是什么顺序)
遍历的过程中去翻转每一个节点的左右孩子就可以达到整体翻转的效果。
注意只要把每一个节点的左右孩子翻转一下,就可以达到整体翻转的效果
这道题目使用前序遍历和后序遍历都可以,唯独中序遍历不方便,因为中序遍历会把某些节点的左右孩子翻转了两次!建议拿纸画一画,就理解了
//解释:中-左-右,左-右-中都可以,但左-中-右不行,首先 左 已经将左子树的孩子节点翻转了一次,而 中 会将左子树翻转到右子树,然后 右 会将 右子树(原本的左子树)再翻转一次,相当于原本的左子树的孩子被翻转了两次,等于没变。
那么层序遍历可以不可以呢?依然可以的!只要把每一个节点的左右孩子翻转一下的遍历方式都是可以的!
代码:前序(递归)/前序(迭代)/后序(递归)/后序(迭代)/层序(递归)
补充:
文中我指的是递归的中序遍历是不行的,因为使用递归的中序遍历,某些节点的左右孩子会翻转两次。
如果非要使用递归中序的方式写,也可以,如下代码就可以避免节点左右孩子翻转两次的情况:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if (root == NULL) return root;
invertTree(root->left); // 左
swap(root->left, root->right); // 中
invertTree(root->left); // 注意 这里依然要遍历左孩子,因为中间节点已经翻转了
return root;
}
};
代码虽然可以,但这毕竟不是真正的递归中序遍历了。
但使用迭代方式统一写法的中序是可以的。
代码如下:
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
stack<TreeNode*> st;
if (root != NULL) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
if (node != NULL) {
st.pop();
if (node->right) st.push(node->right); // 右
st.push(node); // 中
st.push(NULL);
if (node->left) st.push(node->left); // 左
} else {
st.pop();
node = st.top();
st.pop();
swap(node->left, node->right); // 节点处理逻辑
}
}
return root;
}
};
为什么这个中序就是可以的呢,因为这是用栈来遍历,而不是靠指针来遍历,避免了递归法中翻转了两次的情况,大家可以画图理解一下,这里有点意思的。
//个人理解:因为这里st.push()压入的是一个指针的地址值(右值),而不是指针变量(左值),所以即便node->left和node->right进行了swap,那也是这两个变量值发生了变化,而不影响栈中已经压入的地址值。因此当调用st.top()时,弹出的还是原来存的那个节点地址。
相比之下,递归法如果第二次调用的是invertTree(node->right),那传入的是变量(这个变量的值已经被swap过了),因此会出现问题。
补充:morris遍历介绍
morris遍历是二叉树遍历算法的超强进阶算法,跟递归、非递归(栈实现)的空间复杂度,morris遍历可以将非递归遍历中的空间复杂度降为O(1)。从而实现时间复杂度为O(N),而空间复杂度为O(1)的精妙算法。
morris遍历利用的是树的叶节点左右孩子为空(树的大量空闲指针),实现空间开销的极限缩减。
morris遍历的实现原则
记作当前节点为cur。
- 如果cur无左孩子,cur向右移动(cur=cur.right)
- 如果cur有左孩子,找到cur左子树上最右的节点,记为mostright
- 如果mostright的right指针指向空,让其指向cur,cur向左移动(cur=cur.left)
- 如果mostright的right指针指向cur,让其指向空,cur向右移动(cur=cur.right)
实现以上的原则,即实现了morris遍历。
morris遍历的实质
建立一种机制,对 于没有左子树的节点只到达一次,对于有左子树的节点会到达两次
morris遍历的实例
一个树若按层遍历的结构为{1,2,3,4,5,6,7},即该树为满二叉树,头结点值为1,左右孩子为2,3,叶节点为4,5,6,7
一开始图示:

我们按照morris遍历来遍历该树。
1)首先cur来到头结点1,按照morris原则的第二条第一点,它存在左孩子,cur左子树上最右的节点为5,它的right指针指向空,所以让其指向1,cur向左移动到2。
2)2有左孩子,且它左子树最右的节点4指向空,按照morris原则的第二条第一点,让4的right指针指向2,cur向左移动到4
3)4不存在左孩子,按照morris原则的第一条,cur向右移动,在第二步中,4的right指针已经指向了2,所以cur会回到2
4)重新回到2,有左孩子,它左子树最右的节点为4,但是在第二步中,4的right指针已经指向了2,不为空。所以按照morris原则的第二条第二点,2向右移动到5,同时4的right指针重新指向空
5)5不存在左孩子,按照morris原则的第一条,cur向右移动,在第一步中,5的right指针已经指向了1,所以cur会回到1
6)cur回到1,回到头结点,左子树遍历完成,1有左孩子,左子树上最右的节点为5,它的right指针指向1,按照morris原则的第二条第二点,1向右移动到3,同时5的right指针重新指回空
……
当到达最后一个节点7时,按照流程下来,此时7无左右孩子,遍历结束。
ps:建议用一张纸一步一步按照上面的讲解来画,你会更加明白整个morris遍历的。
morris代码实现(前序、中序、后序遍历)
难度:⭐️⭐️⭐️(前序)/⭐️⭐️⭐️(中序)/⭐️⭐️⭐️⭐️⭐️(后序)
前序遍历:
public static void morrisPre(Node head) {
if(head == null){
return;
}
Node cur = head;
Node mostRight = null;
while (cur != null){
// cur表示当前节点,mostRight表示cur的左孩子的最右节点
mostRight = cur.left;
if(mostRight != null){
// cur有左孩子,找到cur左子树最右节点
while (mostRight.right !=null && mostRight.right != cur){
mostRight = mostRight.right;
}
// mostRight的右孩子指向空,让其指向cur,cur向左移动
if(mostRight.right == null){
mostRight.right = cur;
System.out.print(cur.value+" ");
cur = cur.left;
continue;
}else {
// mostRight的右孩子指向cur,让其指向空,cur向右移动
mostRight.right = null;
}
}else {
System.out.print(cur.value + " ");
}
cur = cur.right;
}
System.out.println();
}中序遍历:
public static void morrisIn(Node head) {
if(head == null){
return;
}
Node cur = head;
Node mostRight = null;
while (cur != null){
mostRight = cur.left;
if(mostRight != null){
while (mostRight.right !=null && mostRight.right != cur){
mostRight = mostRight.right;
}
if(mostRight.right == null){
mostRight.right = cur;
cur = cur.left;
continue;
}else {
mostRight.right = null;
}
}
System.out.print(cur.value+" ");
cur = cur.right;
}
System.out.println();
}后续遍历(复杂一点)
public static void morrisPos(Node head) {
if(head == null){
return;
}
Node cur = head;
Node mostRight = null;
while (cur != null){
mostRight = cur.left;
if(mostRight != null){
while (mostRight.right !=null && mostRight.right != cur){
mostRight = mostRight.right;
}
if(mostRight.right == null){
mostRight.right = cur;
cur = cur.left;
continue;
}else {
mostRight.right = null;
printEdge(cur.left);
}
}
cur = cur.right;
}
printEdge(head);
System.out.println();
}
public static void printEdge(Node node){
Node tail =reverseEdge(node);
Node cur = tail;
while (cur != null ){
System.out.print(cur.value+" ");
cur =cur.right;
}
reverseEdge(tail);
}
public static Node reverseEdge(Node node){
Node pre = null;
Node next = null;
while (node != null){
next = node.right;
node.right = pre;
pre = node;
node = next;
}
return pre;
}后序遍历的理解:每次当二次返回parent节点时,将左子树的最右侧节点依次 倒序输出,特别的,最后遍历到整棵树最右边节点的right节点时(也就是遍历结束时),cur=nullptr,此时将整棵树从根节点到最右侧节点的序列 倒序输出。
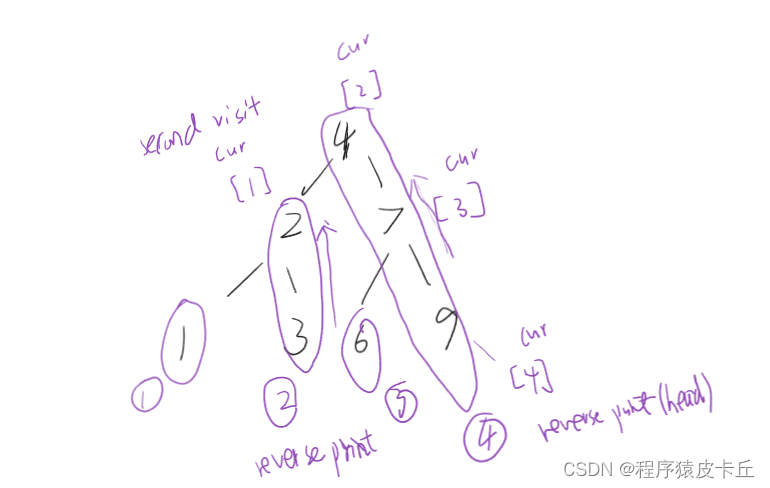
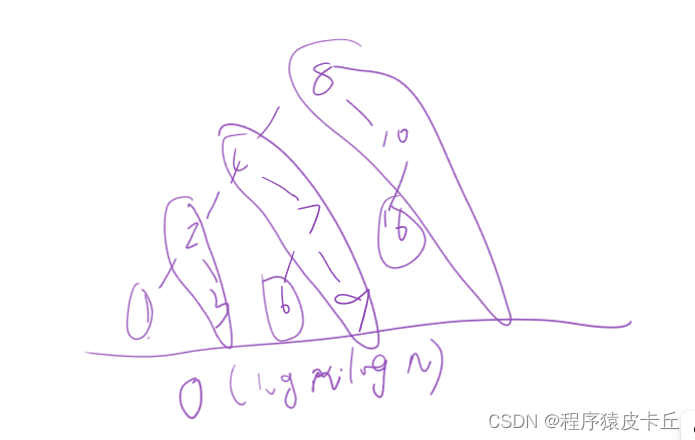
以上就是我今天所要分享的morris遍历,神级算法,时间复杂度为O(N),空间复杂度为O(1)。因为递归遍历二叉树会产生一个O(h)的递归栈的空间复杂度;要是用非递归使用栈来实现也是要产生一个O(h)的空间复杂度。所以morris遍历在二叉树遍历算是神级一般的算法了。
代码:前序遍历(morris)/中序遍历(morris)/后序遍历(morris)
16.Leetcode 101 对称二叉树
难度:⭐️⭐️⭐️
给定一个二叉树,检查它是否是镜像对称的。

那么遍历的顺序应该是什么样的呢?
本题遍历只能是“后序遍历”,因为我们要通过递归函数的返回值来判断两个子树的内侧节点和外侧节点是否相等。
正是因为要遍历两棵树而且要比较内侧和外侧节点,所以准确的来说是一个树的遍历顺序是左右中,一个树的遍历顺序是右左中。
但都可以理解算是后序遍历,尽管已经不是严格上在一个树上进行遍历的后序遍历了。
其实后序也可以理解为是一种回溯,当然这是题外话,讲回溯的时候会重点讲的。
说到这大家可能感觉我有点啰嗦,哪有这么多道理,上来就干就完事了。别急,我说的这些在下面的代码讲解中都有身影。
那么我们先来看看递归法的代码应该怎么写。
递归法
递归三部曲
1.确定递归函数的参数和返回值
因为我们要比较的是根节点的两个子树是否是相互翻转的,进而判断这个树是不是对称树,所以要比较的是两个树,参数自然也是左子树节点和右子树节点。
返回值自然是bool类型。
代码如下:
bool compare(TreeNode* left, TreeNode* right)
2.确定终止条件
要比较两个节点数值相不相同,首先要把两个节点为空的情况弄清楚!否则后面比较数值的时候就会操作空指针了。
节点为空的情况有:(注意我们比较的其实不是左孩子和右孩子,所以如下我称之为左节点右节点)
- 左节点为空,右节点不为空,不对称,return false
- 左不为空,右为空,不对称 return false
- 左右都为空,对称,返回true
此时已经排除掉了节点为空的情况,那么剩下的就是左右节点不为空:
- 左右都不为空,比较节点数值,不相同就return false
此时左右节点不为空,且数值也不相同的情况我们也处理了。
代码如下:
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
else if (left->val != right->val) return false; // 注意这里我没有使用else
注意上面最后一种情况,我没有使用else,而是else if, 因为我们把以上情况都排除之后,剩下的就是 左右节点都不为空,且数值相同的情况。
3.确定单层递归的逻辑
此时才进入单层递归的逻辑,单层递归的逻辑就是处理 左右节点都不为空,且数值相同的情况。
- 比较二叉树外侧是否对称:传入的是左节点的左孩子,右节点的右孩子。
- 比较内侧是否对称,传入左节点的右孩子,右节点的左孩子。
- 如果左右都对称就返回true ,有一侧不对称就返回false 。
代码如下:
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
bool isSame = outside && inside; // 左子树:中、 右子树:中(逻辑处理)
return isSame;
如上代码中,我们可以看出使用的遍历方式,左子树左右中,右子树右左中,所以我把这个遍历顺序也称之为“后序遍历”(尽管不是严格的后序遍历)。
最后递归的C++整体代码如下:
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
// 首先排除空节点的情况
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
// 排除了空节点,再排除数值不相同的情况
else if (left->val != right->val) return false;
// 此时就是:左右节点都不为空,且数值相同的情况
// 此时才做递归,做下一层的判断
bool outside = compare(left->left, right->right); // 左子树:左、 右子树:右
bool inside = compare(left->right, right->left); // 左子树:右、 右子树:左
bool isSame = outside && inside; // 左子树:中、 右子树:中 (逻辑处理)
return isSame;
}
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
return compare(root->left, root->right);
}
};
我给出的代码并不简洁,但是把每一步判断的逻辑都清楚的描绘出来了。
如果上来就看网上各种简洁的代码,看起来真的很简单,但是很多逻辑都掩盖掉了,而题解可能也没有把掩盖掉的逻辑说清楚。
盲目的照着抄,结果就是:发现这是一道“简单题”,稀里糊涂的就过了,但是真正的每一步判断逻辑未必想到清楚。
当然我可以把如上代码整理如下:
class Solution {
public:
bool compare(TreeNode* left, TreeNode* right) {
if (left == NULL && right != NULL) return false;
else if (left != NULL && right == NULL) return false;
else if (left == NULL && right == NULL) return true;
else if (left->val != right->val) return false;
else return compare(left->left, right->right) && compare(left->right, right->left);
}
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
return compare(root->left, root->right);
}
};
这个代码就很简洁了,但隐藏了很多逻辑,条理不清晰,而且递归三部曲,在这里完全体现不出来。
所以建议大家做题的时候,一定要想清楚逻辑,每一步做什么。把题目所有情况想到位,相应的代码写出来之后,再去追求简洁代码的效果。
迭代法
这道题目我们也可以使用迭代法,但要注意,这里的迭代法可不是前中后序的迭代写法,因为本题的本质是判断两个树是否是相互翻转的,其实已经不是所谓二叉树遍历的前中后序的关系了。
这里我们可以使用队列来比较两个树(根节点的左右子树)是否相互翻转,(注意这不是层序遍历)
//个人理解:但是从遍历路径来看,确实类似于层序遍历(广度优先)
使用队列
通过队列来判断根节点的左子树和右子树的内侧和外侧是否相等,如动画所示:

时间复杂度O(n),空间复杂度O(n)
如下的条件判断和递归的逻辑是一样的。
代码如下:
class Solution {
public:
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
queue<TreeNode*> que;
que.push(root->left); // 将左子树头结点加入队列
que.push(root->right); // 将右子树头结点加入队列
while (!que.empty()) { // 接下来就要判断这两个树是否相互翻转
TreeNode* leftNode = que.front(); que.pop();
TreeNode* rightNode = que.front(); que.pop();
if (!leftNode && !rightNode) { // 左节点为空、右节点为空,此时说明是对称的
continue;
}
// 左右一个节点不为空,或者都不为空但数值不相同,返回false
if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
return false;
}
que.push(leftNode->left); // 加入左节点左孩子
que.push(rightNode->right); // 加入右节点右孩子
que.push(leftNode->right); // 加入左节点右孩子
que.push(rightNode->left); // 加入右节点左孩子
}
return true;
}
};
使用栈
细心的话,其实可以发现,这个迭代法,其实是把左右两个子树要比较的元素顺序放进一个容器,然后成对成对的取出来进行比较,那么其实使用栈也是可以的。
时间复杂度O(n),空间复杂度O(h),h为二叉树的高度
只要把队列原封不动的改成栈就可以了,我下面也给出了代码。
//个人理解:从遍历路径来看,类似于前序遍历(中-左-右)或镜像的(中-右-左)
class Solution {
public:
bool isSymmetric(TreeNode* root) {
if (root == NULL) return true;
stack<TreeNode*> st; // 这里改成了栈
st.push(root->left);
st.push(root->right);
while (!st.empty()) {
TreeNode* leftNode = st.top(); st.pop();
TreeNode* rightNode = st.top(); st.pop();
if (!leftNode && !rightNode) {
continue;
}
if ((!leftNode || !rightNode || (leftNode->val != rightNode->val))) {
return false;
}
st.push(leftNode->left);
st.push(rightNode->right);
st.push(leftNode->right);
st.push(rightNode->left);
}
return true;
}
};
具体实现代码:递归/迭代(队列)/迭代(栈)/迭代(不分左右子树直接层序)
总结
这次我们又深度剖析了一道二叉树的“简单题”,大家会发现,真正的把题目搞清楚其实并不简单,leetcode上accept了和真正掌握了还是有距离的。
我们介绍了递归法和迭代法,递归依然通过递归三部曲来解决了这道题目,如果只看精简的代码根本看不出来递归三部曲是如何解题的。
在迭代法中我们使用了队列,需要注意的是这不是层序遍历,而且仅仅通过一个容器来成对的存放我们要比较的元素,知道这一本质之后就发现,用队列,用栈,甚至用数组,都是可以的。
如果已经做过这道题目的同学,读完文章可以再去看看下面这两道题目,思考一下,会有不一样的发现!
17.Leetcode 100 相同的树
难度:⭐️⭐️
18.Leetcode 572 另一个树的子树
难度:⭐️⭐️(暴力深度优先遍历每个子树并进行比较)/⭐️⭐️⭐️⭐️(前序遍历+KMP比较)/⭐️⭐️⭐️⭐️⭐️⭐️(树哈希)
代码:递归子树+迭代比较/迭代子树+迭代比较/前序遍历+KMP比较/树哈希
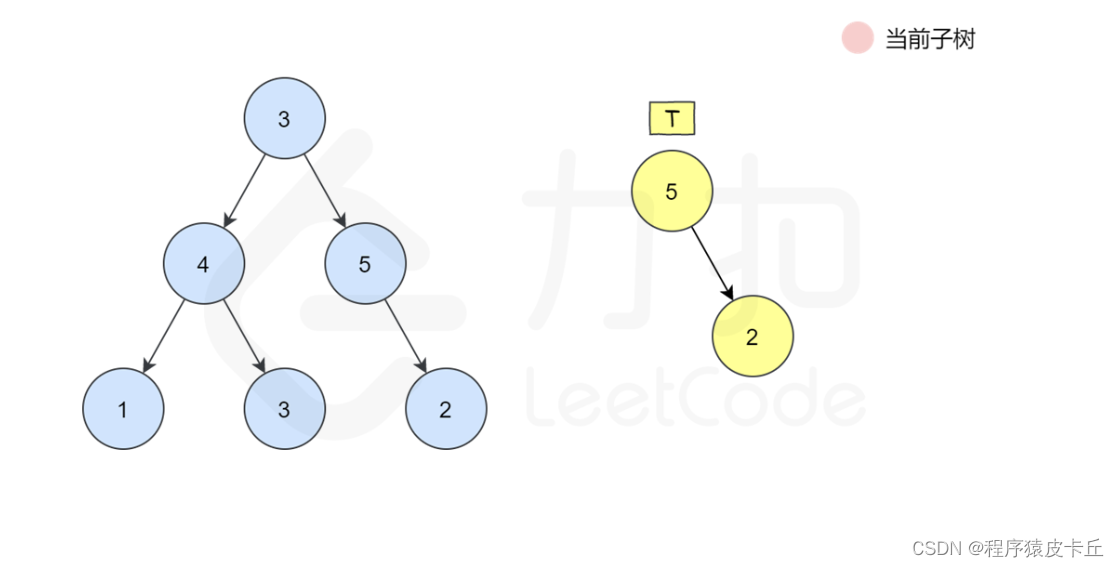
方法一:深度优先搜索暴力匹配
这是一种最朴素的方法——深度优先搜索枚举 sss 中的每一个节点,判断这个点的子树是否和 ttt 相等。如何判断一个节点的子树是否和 ttt 相等呢,我们又需要做一次深度优先搜索来检查,即让两个指针一开始先指向该节点和 ttt 的根,然后「同步移动」两根指针来「同步遍历」这两棵树,判断对应位置是否相等。
时间O(nm) 空间O(h)
方法二:深度优先搜索序列上做串匹配
这个方法需要我们先了解一个「小套路」:一棵子树上的点在深度优先搜索序列(即先序遍历)中是连续的。了解了这个「小套路」之后,我们可以确定解决这个问题的方向就是:把 sss 和 ttt 先转换成深度优先搜索序列,然后看 ttt 的深度优先搜索序列是否是 sss 的深度优先搜索序列的「子串」。
这样做正确吗? 假设 sss 由两个点组成,111 是根,222 是 111 的左孩子;ttt 也由两个点组成,111 是根,222 是 111 的右孩子。这样一来 sss 和 ttt 的深度优先搜索序列相同,可是 ttt 并不是 sss 的某一棵子树。由此可见「sss 的深度优先搜索序列包含 ttt 的深度优先搜索序列」是「ttt 是 sss 子树」的必要不充分条件,所以单纯这样做是不正确的。
为了解决这个问题,我们可以引入两个空值 lNull 和 rNull,当一个节点的左孩子或者右孩子为空的时候,就插入这两个空值,这样深度优先搜索序列就唯一对应一棵树。处理完之后,就可以通过判断「sss 的深度优先搜索序列包含 ttt 的深度优先搜索序列」来判断答案。
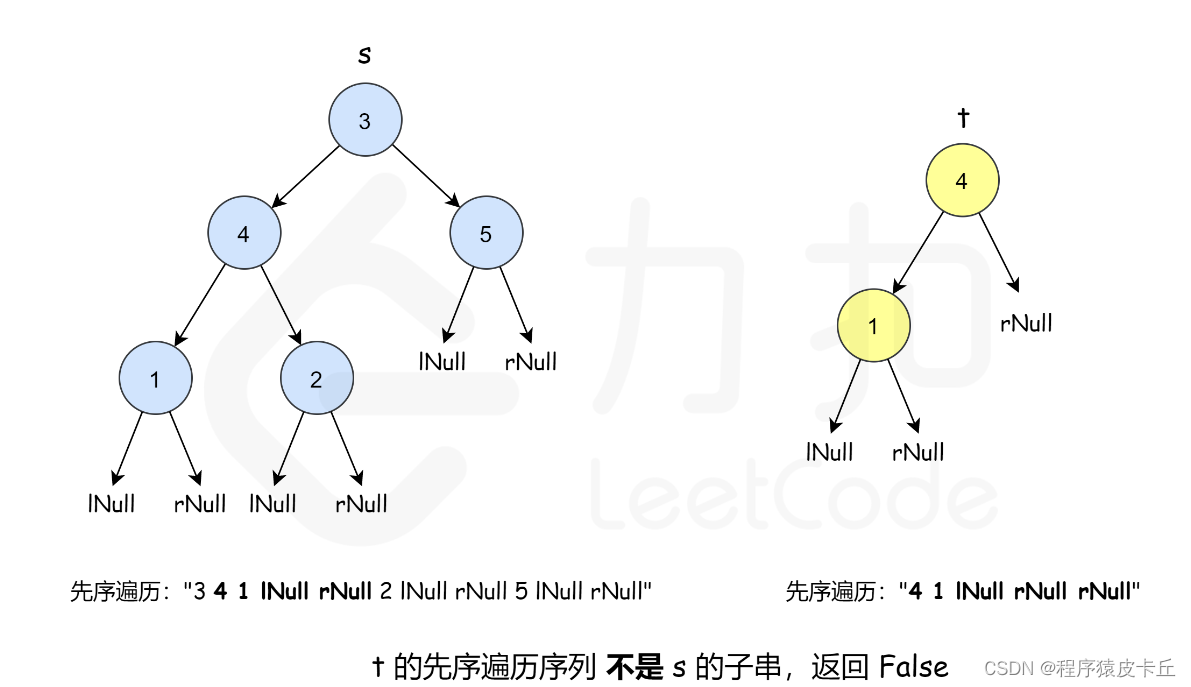
在判断「sss 的深度优先搜索序列包含 ttt 的深度优先搜索序列」的时候,可以暴力匹配,也可以使用 KMP或者 Rabin-Karp算法,在使用 Rabin-Karp算法的时候,要注意串中可能有负值。
时间:O(m+n) 空间O(m+n)
方法三:树哈希
时间:O(argπ(max(m,n))=O(m+n),空间O(argπ(max(m,n))=O(m+n)
19.Leetcode 559 N叉树的最大深度
难度:⭐️⭐️
和之前 13.Leetcode 104 二叉树的最大深度 大同小异。
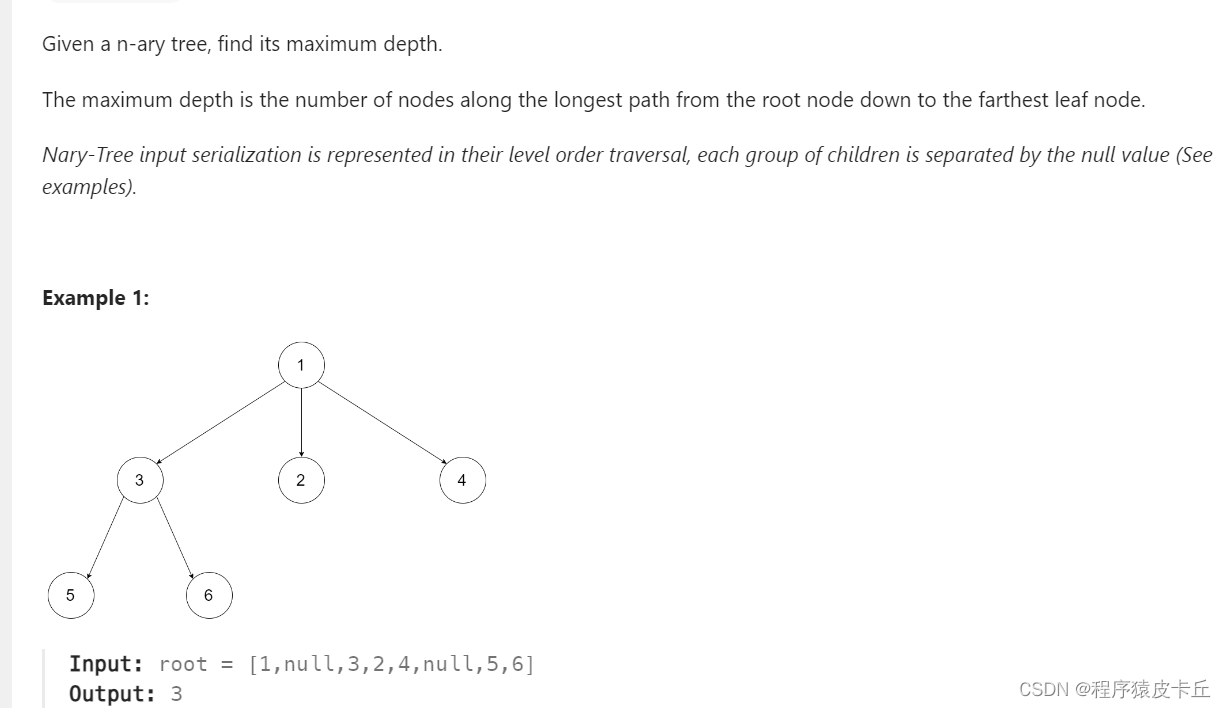
时间复杂度:O(n) 空间复杂度 O(h)/O(logn),h为多叉树的最大深度,logn为单层(最后一层)最多节点数
20. Leetcode 222 完全二叉树的节点个数
难度:⭐️⭐️⭐️(递归+判断是否为完全二叉树)/⭐️⭐️⭐️⭐️(迭代+位运算+遍历查找)
方法1:递归+判断是否为完全二叉树
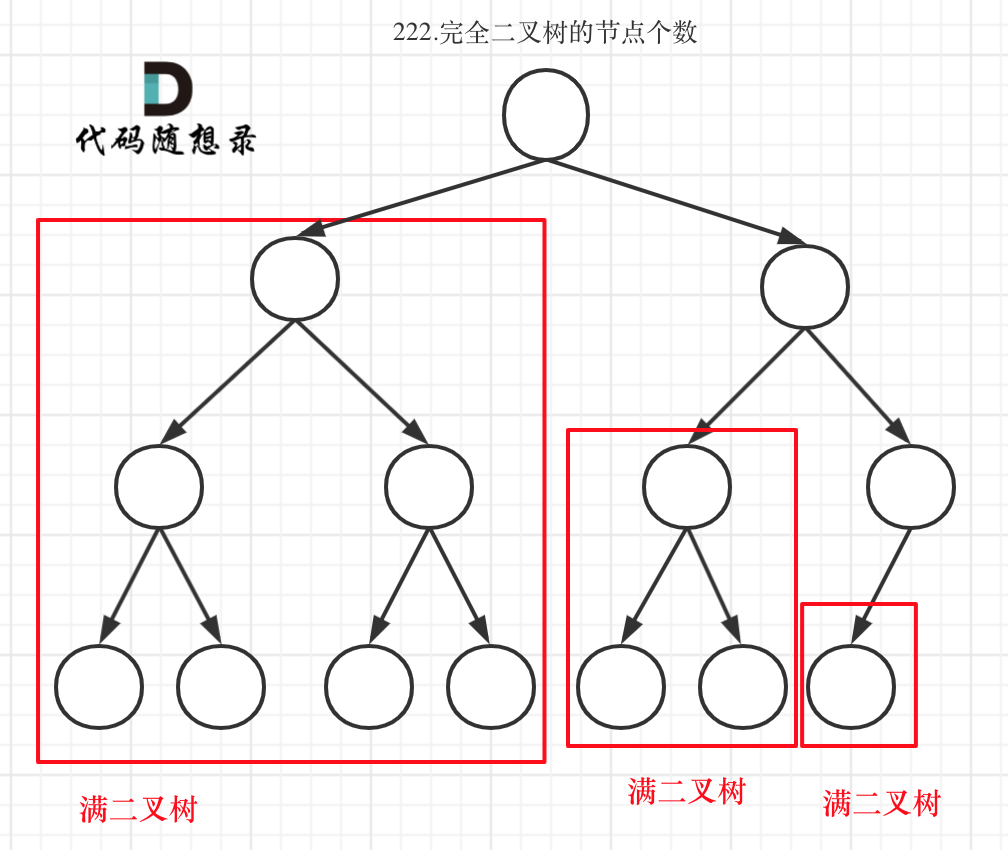
在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^(h-1) 个节点。
大家要自己看完全二叉树的定义,很多同学对完全二叉树其实不是真正的懂了。
我来举一个典型的例子如题:

完全二叉树只有两种情况,情况一:就是满二叉树,情况二:最后一层叶子节点没有满。
对于情况一,可以直接用 2^树深度 - 1 来计算,注意这里根节点深度为1。
对于情况二,分别递归左孩子,和右孩子,递归到某一深度一定会有左孩子或者右孩子为满二叉树,然后依然可以按照情况1来计算。
完全二叉树(一)如图:
完全二叉树(二)如图:
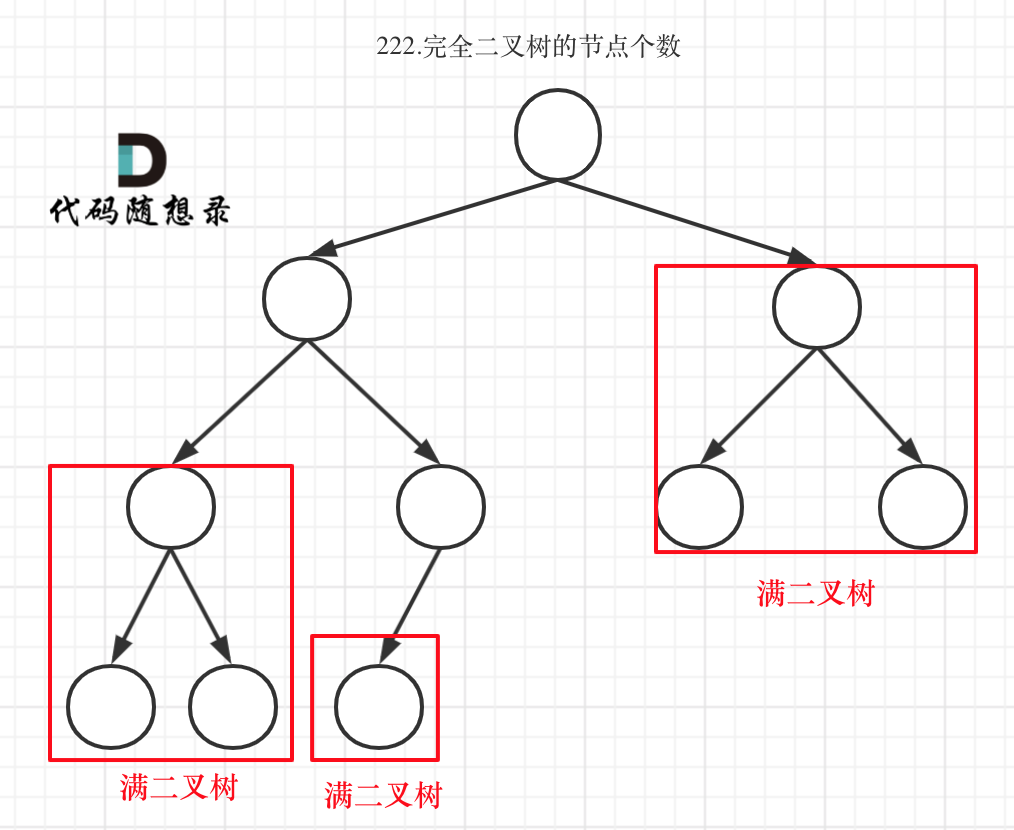
可以看出如果整个树不是满二叉树,就递归其左右孩子,直到遇到满二叉树为止,用公式计算这个子树(满二叉树)的节点数量。
这里关键在于如何去判断一个左子树或者右子树是不是满二叉树呢?
在完全二叉树中,如果递归向左遍历的深度等于递归向右遍历的深度,那说明就是满二叉树。如图:

在完全二叉树中,如果递归向左遍历的深度不等于递归向右遍历的深度,则说明不是满二叉树,如图:
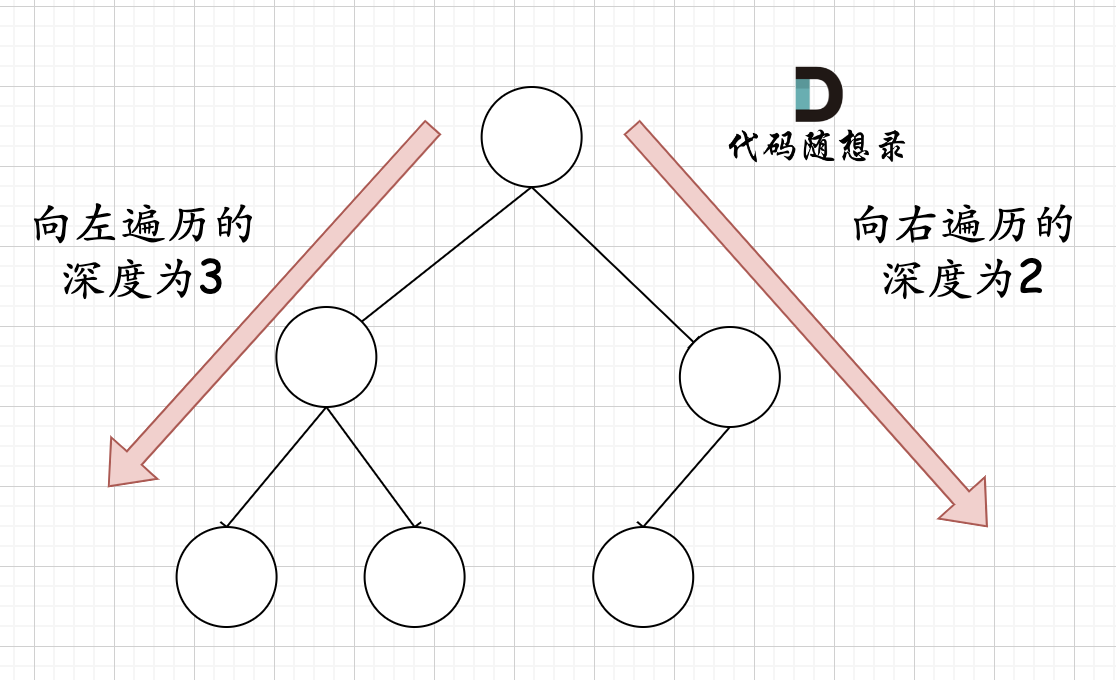
那有录友说了,这种情况,递归向左遍历的深度等于递归向右遍历的深度,但也不是满二叉树,如题:
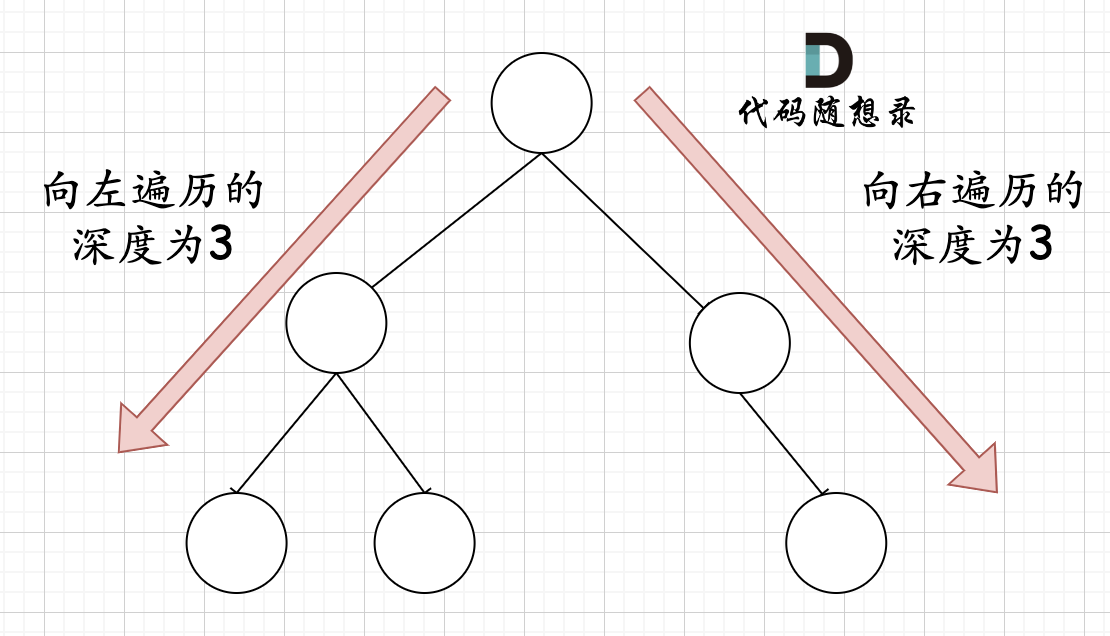
如果这么想,大家就是对 完全二叉树理解有误区了,以上这棵二叉树,它根本就不是一个完全二叉树!
判断其子树是不是满二叉树,如果是则利用公式计算这个子树(满二叉树)的节点数量,如果不是则继续递归,那么 在递归三部曲中,第二部:终止条件的写法应该是这样的:
if (root == nullptr) return 0;
// 开始根据左深度和右深度是否相同来判断该子树是不是满二叉树
TreeNode* left = root->left;
TreeNode* right = root->right;
int leftDepth = 0, rightDepth = 0; // 这里初始为0是有目的的,为了下面求指数方便
while (left) { // 求左子树深度
left = left->left;
leftDepth++;
}
while (right) { // 求右子树深度
right = right->right;
rightDepth++;
}
if (leftDepth == rightDepth) {
return (2 << leftDepth) - 1; // 注意(2<<1) 相当于2^2,返回满足满二叉树的子树节点数量
}
递归三部曲,第三部,单层递归的逻辑:(可以看出使用后序遍历)
int leftTreeNum = countNodes(root->left); // 左
int rightTreeNum = countNodes(root->right); // 右
int result = leftTreeNum + rightTreeNum + 1; // 中
return result;
该部分精简之后代码为:
return countNodes(root->left) + countNodes(root->right) + 1;
最后整体C++代码如下:
class Solution {
public:
int countNodes(TreeNode* root) {
if (root == nullptr) return 0;
TreeNode* left = root->left;
TreeNode* right = root->right;
int leftDepth = 0, rightDepth = 0; // 这里初始为0是有目的的,为了下面求指数方便
while (left) { // 求左子树深度
left = left->left;
leftDepth++;
}
while (right) { // 求右子树深度
right = right->right;
rightDepth++;
}
if (leftDepth == rightDepth) {
return (2 << leftDepth) - 1; // 注意(2<<1) 相当于2^2,所以leftDepth初始为0
}
return countNodes(root->left) + countNodes(root->right) + 1;
}
};
- 时间复杂度:O(log n × log n)
- 空间复杂度:O(log n)
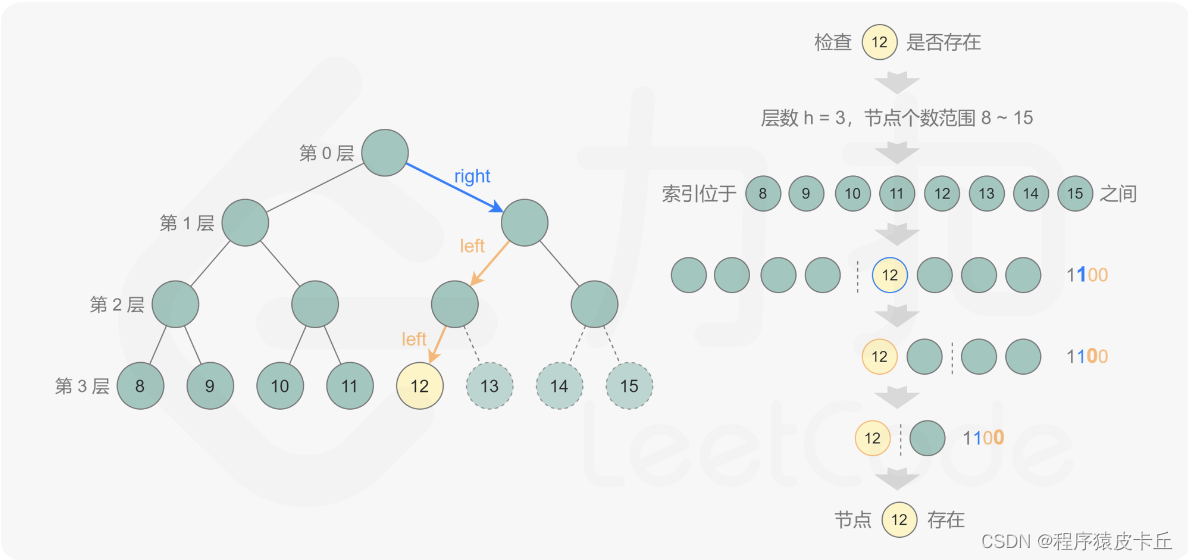
方法2:迭代+位运算+遍历查找















 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









