







【Linux 性能优化系列】Linux 性能优化 -- CPU 性能篇(一) 平均负载、上下文切换、CPU 使用率
【1】相关概念
【1.1】平均负载
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数;
可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,即 ps 命令看到的处于 R 状态(Running 或 Runnable)的进程;
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,即 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程,不可中断状态实际上是系统对进程和硬件设备的一种保护机制;
【1.1.1】平均负载与 CPU 使用率的关系
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高;
【1.2】CPU 上下文
CPU 寄存器,CPU 内置的容量小、但速度极快的内存;
程序计数器,用来存储 CPU 正在执行的指令位置或者即将执行的下一条指令位置;
两者构成了 CPU 在运行任何任务前,必须的依赖环境;
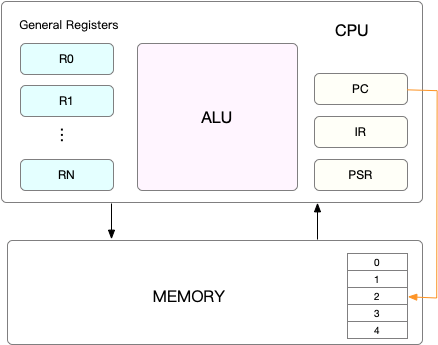
【1.2.1】CPU 上下文切换
即把前一个任务的 CPU 上下文(即 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务的操作;
【1.2.2】CPU 的上下文切换的分类
【1.2.2.1】进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,内核空间(Ring 0)具有最高权限,可以直接访问所有资源;用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用到内核中,才能访问这些特权资源;
注意 : 系统调用,通常称为特权模式切换,而不是上下文切换,一次系统调用的过程,其实是发生了两次 CPU 上下文切换;
进程上下文切换 VS 系统调用
1. 进程是由内核来管理和调度的,进程的切换只能发生在内核态,因此进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态;
2. 进程的上下文切换比系统调用多了一步,在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等用户空间资源保存下来;而加载了下一进程的内核态后,还需要刷新该进程的虚拟内存、栈等用户空间资源;
进程上下文切换的时机
只有在进程调度的时候,才需要切换上下文;Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待 CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,即优先级最高和等待 CPU 时间最长的进程来运行;
进程被调度到 CPU 上运行的时机
1. 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程;当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行;
2. 进程在系统资源不足时,要等到资源满足后才可以运行,此时进程也会被挂起,并由系统调度其他进程运行;
3. 当进程通过睡眠函数 sleep 方法将自己主动挂起时也会重新调度;
4. 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行;
5. 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序;
【1.2.2.2】线程上下文切换
线程是调度的基本单位,而进程则是资源拥有的基本单位
进程 VS 线程
1. 当进程只有一个线程时,可以认为进程就等于线程;
2. 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源,这些资源在上下文切换时是不需要修改的;
3. 线程也有私有数据,这些在上下文切换时也是需要保存的;
线程上下文切换的情况
1. 前后两个线程属于不同进程;此时,由于资源不共享,切换过程就跟进程上下文切换是一样;
2. 前后两个线程属于同一个进程;此时,由于虚拟内存是共享的,切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据;
【1.2.2.3】中断上下文切换
中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件
中断上下文切换并不涉及到进程的用户态,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源;中断上下文,只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等;
【1.3】CPU 使用率
【1.3.1】节拍
为了维护 CPU 时间,Linux 通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数,每发生一次时间中断,Jiffies 的值就加 1;
节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等,不同的系统可能设置不同数值,可以通过查询 /boot/config 内核选项来查看它的配置值;
由于节拍率 HZ 是内核选项,用户空间程序不能直接访问,因此为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,其值固定为 100;
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息;
# 只保留各个CPU的数据
$ cat /proc/stat | grep ^cpu
cpu 280580 7407 286084 172900810 83602 0 583 0 0 0
cpu0 144745 4181 176701 86423902 52076 0 301 0 0 0
cpu1 135834 3226 109383 86476907 31525 0 282 0 0 0
其中,第一列表示的是 CPU 编号,如 cpu0、cpu1 ,而第一行没有编号的 cpu,表示的是所有 CPU 的累加;
其他列则表示不同场景下 CPU 的累加节拍数,单位是 USER_HZ,即 10 ms(1/100 秒),即不同场景下的 CPU 时间;
user(通常缩写为 us),代表用户态 CPU 时间,注意,它不包括下面的 nice 时间,但包括了 guest 时间;
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间,
注意 nice 可取值范围是 -20 到 19,数值越大,优先级反而越低;
system(通常缩写为 sys),代表内核态 CPU 时间;
idle(通常缩写为 id),代表空闲时间,注意,它不包括等待 I/O 的时间(iowait);
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间;
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间;
softirq(通常缩写为 si),代表处理软中断的 CPU 时间;
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间;
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间;
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间;【1.3.2】CPU 使用率
CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比
开机以来的 CPU 使用率计算公式

某段时间内的平均 CPU 使用率计算公式

Linux 给每个进程提供了运行情况的统计信息,即 /proc/[pid]/stat
注意,性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置
【2】相关工具与命令
【2.1】测试模拟工具
stress 是一个 Linux 系统压力测试工具,这里用作异常进程模拟平均负载升高的场景;
sysbench 是一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况;可以将其当成一个异常进程来看,作用是模拟上下文切换过多的问题;
【2.2】mpstat
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标;
命令格式
mpstat [-P {cpu|ALL}] [internal [count]]
命令参数说明
-P {cpu l ALL}:表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal:相邻的两次采样的间隔时间
count:采样的次数,count只能和delay一起使用
结果参数说明
CPU 处理器ID
%usr 在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程
%nice 在internal时间段里,nice值为负的进程(使用nice命令对进程进行降级时)CPU的百分比(%)
%sys 在internal时间段里,核心时间(%)
%iowait 在internal时间段里,硬盘IO等待时间(%)
%irq 在internal时间段里,硬中断时间(%)
%soft 在internal时间段里,软中断时间(%)
%steal 显示虚拟机管理器在服务另一个虚拟处理器时虚拟CPU处在非自愿等待下花费时间的百分比
%guest 显示运行虚拟处理器时CPU花费时间的百分比
%gnice
%idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%)【2.3】pidstat
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标;
命令格式
pidstat 的用法:
pidstat [ 选项 ] [ <时间间隔> ] [ <次数> ]
常用的参数:
-u:默认的参数,显示各个进程的cpu使用统计
-r:显示各个进程的内存使用统计
-d:显示各个进程的IO使用情况
-p:指定进程号
-w:显示每个进程的上下文切换情况
-t:显示选择任务的线程的统计信息外的额外信息
-T { TASK | CHILD | ALL }
TASK表示报告独立的task;CHILD关键字表示报告进程下所有线程统计信息;ALL表示报告独立的task和task下面的所有线程;
注意:task和子线程的全局的统计信息和pidstat选项无关;这些统计信息不会对应到当前的统计间隔,
这些统计信息只有在子线程kill或者完成的时候才会被收集;
-V:版本号
-h:在一行上显示了所有活动,这样其他程序可以容易解析
-I:在SMP环境,表示任务的CPU使用率/内核数量
-l:显示命令名和所有参数使用示例
示例一:查看所有进程的 CPU 使用情况( -u -p ALL)
pidstat
pidstat -u -p ALL
pidstat 和 pidstat -u -p ALL 是等效的;
pidstat 默认显示了所有进程的cpu使用率;
结果说明
PID:进程ID
%usr:进程在用户空间占用cpu的百分比
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令示例二: 内存使用情况统计(-r)
pidstat -r
使用-r选项,pidstat将显示各活动进程的内存使用统计
结果说明
PID:进程标识符
minflt/s: 每秒次缺页错误次数(minor page faults),次缺页错误次数表明虚拟内存地址映射成物理内存地址产生的
page fault次数,不需要从磁盘中加载页
majflt/s: 每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的 page在swap中,
这样的page fault为major page fault,一般在内存使用紧张时产生,需要从磁盘中加载页
VSZ: 该进程使用的虚拟内存(以kB为单位)
RSS: 该进程使用的物理内存(以kB为单位)
%MEM: 该进程使用内存的百分比
Command: 拉起进程对应的命令示例三:显示各个进程的IO使用情况(-d)
pidstat -d
结果说明
PID:进程id
kB_rd/s:每秒从磁盘读取的数据量(KB)
kB_wr/s:每秒写入磁盘数据量(KB)
kB_ccwr/s:任务取消写入磁盘的数据量(KB),当任务截断脏的pagecache的时候会发生
COMMAND:task的命令名示例四:显示每个进程的上下文切换情况(-w)& 针对特定进程统计(-p)
pidstat -t -p 2831
结果说明
PID:进程id
Cswch/s:每秒主动任务上下文切换数量,主动任务上下文切换,是指进程无法获取所需资源,导致的上下文切换;
比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换;
Nvcswch/s:每秒被动任务上下文切换数量,被动任务上下文切换,则是指进程由于时间片已到等原因,
被系统强制调度,进而发生的上下文切换;
比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
Command:命令名示例五:显示选择任务的线程的统计信息外的额外信息 (-t)
pidstat -t -p 2831
结果说明
TGID:主线程的表示
TID:线程id
%usr:进程在用户空间占用cpu的百分比
%system:进程在内核空间占用cpu的百分比
%guest:进程在虚拟机占用cpu的百分比
%CPU:进程占用cpu的百分比
CPU:处理进程的cpu编号
Command:当前进程对应的命令【2.4】iostat
iostat 主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息;
命令格式
iostat [参数] [时间] [次数]
命令参数说明
-c 显示CPU使用情况
-d 显示磁盘使用情况
-k 以K为单位显示
-m 以M为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS使用情况
-p 可以报告出每块磁盘的每个分区的使用情况
-t 显示终端和CPU的信息
-x 显示详细信息使用示例
命令结果重要参数
%iowait:如果该值较高,表示磁盘存在I/O瓶颈
await:一般地,系统I/O响应时间应该低于5ms,如果大于10ms就比较大了
avgqu-sz:如果I/O请求压力持续超出磁盘处理能力,该值将增加;如果单块磁盘的队列长度持续超过2,一般认为该磁盘存在I/O性能问题
需要注意的是,如果该磁盘为磁盘阵列虚拟的逻辑驱动器,需要再将该值除以组成这个逻辑驱动器的实际物理磁盘数目,
以获得平均单块硬盘的I/O等待队列长度
%util:一般地,如果该参数是100%表示设备已经接近满负荷运行了示例一: 显示详细信息 iostat -x
命令:iostat -x
结果参数说明
%user:CPU处在用户模式下的时间百分比
%nice:CPU处在带NICE值的用户模式下的时间百分比
%system:CPU处在系统模式下的时间百分比
%iowait:CPU等待输入输出完成时间的百分比
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比
%idle:CPU空闲时间百分比
Device:设备名称
rrqm/s:每秒合并到设备的读取请求数
wrqm/s:每秒合并到设备的写请求数
r/s:每秒向磁盘发起的读操作数
w/s:每秒向磁盘发起的写操作数
rkB/s:每秒读K字节数
wkB/s: 每秒写K字节数
avgrq-sz:平均每次设备I/O操作的数据大小
avgqu-sz:平均I/O队列长度
await:平均每次设备I/O操作的等待时间(毫秒),一般地,系统I/O响应时间应该低于5ms,如果大于 10ms就比较大了
r_await:每个读操作平均所需的时间;不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间
w_await:每个写操作平均所需的时间;不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间
svctm:平均每次设备I/O操作的服务时间 (毫秒)(这个数据不可信!)
%util:一秒中有百分之多少的时间用于I/O操作,即被IO消耗的CPU百分比,一般地,如果该参数是100%表示设备已经接近满负荷运行了示例二:显示磁盘使用情况 iostat -d 2 3
命令:iostat -d 2 3
结果参数说明
tps:每秒I/O数(即IOPS。磁盘连续读和连续写之和)
kB_read/s:每秒从磁盘读取数据大小,单位KB/s
kB_wrtn/s:每秒写入磁盘的数据的大小,单位KB/s
kB_read:从磁盘读出的数据总数,单位KB
kB_wrtn:写入磁盘的的数据总数,单位KB【2.5】uptime
uptime
02:34:03 up 2 days, 20:14, 1 user, load average: 0.63, 0.83, 0.88
参数说明
02:34:03 : 当前时间
up 2 days, 20:14 : 系统运行时间
1 user : 正在登录用户数
load average: 0.63, 0.83, 0.88 : 过去 1 分钟、5 分钟、15 分钟的平均负载
命令分析说明
1. 如果 1 分钟、5 分钟、15 分钟的三个值基本相同则系统负载很平稳;
2. 如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载;
3. 如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,
所以就需要持续观察,一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,
这时就得分析调查是哪里导致的问题,并要想办法优化了;
注意 : 当平均负载高于 CPU 数量 70% 的时候,就应该分析排查负载高的问题,一旦负载过高,就可能导致进程响应变慢,
进而影响服务的正常功能;【2.6】vmstat
vmstat常用命令格式
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
命令选项说明
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量
-m:显示slabinfo
-n:只在开始时显示一次各字段名称
-s:显示内存相关统计信息及多种系统活动数量
delay:刷新时间间隔,如果不指定,只显示一条结果
count:刷新次数,如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷
-d:显示磁盘相关统计信息
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示,参数有 k 、K 、m 、M,分别代表1000、1024、1000000、1048576字节(byte),默认单位为K(1024 bytes)
-V:显示vmstat版本信息使用示例
vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 361396 196772 55820 359372 0 0 13 21 1 1 2 0 98 0 0
1 0 361392 196524 55820 359616 8 0 236 0 411 527 1 0 90 9 0
2 1 361392 196524 55828 359608 0 0 0 48 370 503 1 1 98 0 0
4 0 361392 196524 55828 359616 0 0 0 0 442 559 1 0 99 0 0
字段说明:
procs(进程)
r:当前运行队列中线程的数目,代表线程处于可运行状态,但CPU还未能执行,这个值可以作为判断CPU是否繁忙的一个指标;
当这个值超过了CPU数目,就会出现CPU瓶颈了;这个我们可以结合top命令的负载值同步评估系统性能;
b:等待IO的进程数量;如果该值一直都很大,说明IO比较繁忙,处理较慢;
memory(内存)
swpd:虚拟内存已使用的大小;如果swpd的值不为0,但是si,so的值长期为0,这种情况不会影响系统性能;
free:空闲的物理内存的大小;
buff:用作缓冲的内存大小;
cache:用作缓存的内存大小;如果cache的值大的时候,说明cache处的文件数多,
如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小;
swap(交换空间,单位:KB);内存够用的时候,这2个值都是0,如果这2个值长期大于0时,
系统性能会受到影响,磁盘IO和CPU资源都会被消耗;
有时我们看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,
如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的;
si:每秒从交换区写到内存的大小;
so:每秒写入交换区的内存大小;
io(单位:块/秒)
bi:每秒读取的块数;
bo:每秒写入的块数;随机磁盘读写的时候,这2个值越大,能看到CPU在IO等待的值也会越大;
system(系统);这2个值越大,会看到由内核消耗的CPU时间会越大;
in:每秒中断数,包括时钟中断;
cs:每秒上下文切换数;
cpu(以百分比表示)
us:用户进程执行时间(user time);
sy:系统进程执行时间(system time);
id:空闲时间(包括IO等待时间);
wa:等待IO时间;wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈;【2.7】top
top命令的使用
top使用格式
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
top参数说明
d: 指定每两次屏幕信息刷新之间的时间间隔,当然用户可以使用s交互命令来改变之
p: 通过指定监控进程ID来仅仅监控某个进程的状态
q: 该选项将使top没有任何延迟的进行刷新,如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行
S: 指定累计模式
s: 使top命令在安全模式中运行,这将去除交互命令所带来的潜在危险
i: 使top不显示任何闲置或者僵死进程
c: 显示整个命令行而不只是显示命令名
交互命令
Ctrl+L: 擦除并且重写屏幕
h或者?: 显示帮助画面,给出一些简短的命令总结说明
k: 终止一个进程,系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号;
一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程;默认值是信号15;
在安全模式中此命令被屏蔽
i: 忽略闲置和僵死进程,这是一个开关式命令
q: 退出程序
r: 重新安排一个进程的优先级别,系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值;
输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权,默认值是10
S: 切换到累计模式
s: 改变两次刷新之间的延迟时间,系统将提示用户输入新的时间,单位为s,如果有小数,就换算成ms;
输入0值则系统将不断刷新,默认值是5s;
需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加
f或者F: 从当前显示中添加或者删除项目
o或者O: 改变显示项目的顺序
l: 切换显示平均负载和启动时间信息
m: 切换显示内存信息
t: 切换显示进程和CPU状态信息
c: 切换显示命令名称和完整命令行
M: 根据驻留内存大小进行排序
P: 根据CPU使用百分比大小进行排序
T: 根据时间/累计时间进行排序
W: 将当前设置写入~/.toprc文件中,这是写top配置文件的推荐方法# 默认每3秒刷新一次
$ top
top - 11:58:59 up 9 days, 22:47, 1 user, load average: 0.03, 0.02, 0.00
Tasks: 123 total, 1 running, 72 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169348 total, 5606884 free, 334640 used, 2227824 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7497908 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 78088 9288 6696 S 0.0 0.1 0:16.83 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kthreadd
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H统计信息区
第一行:任务队列信息,与uptime命令执行结果相同
17:32:34:系统当前时间
up 3 days, 8:04:主机已运行时间
5 users:用户连接数(不是用户数,who命令)
load average: 0.09, 0.12, 0.19:系统平均负载,统计最近1,5,15分钟的系统平均负载
补充:uptime -V可查询版本
第二行:进程信息
Tasks: 287 total:进程总数
2 running:正在运行的进程数
285 sleeping:睡眠的进程数
0 stopped:停止的进程数
0 zombie:僵尸进程数
第三行:CPU信息(当有多个CPU时,这些内容可能会超过两行)
1.5 us:用户空间所占CPU百分比
0.9 sy:内核空间占用CPU百分比
0.0 ni:用户进程空间内改变过优先级的进程占用CPU百分比
97.5 id:空闲CPU百分比
0.2 wa:等待输入输出的CPU时间百分比
0.0 hi:硬件CPU中断占用百分比
0.0 si:软中断占用百分比
0.0 st:虚拟机占用百分比
第四行:内存信息(与第五行的信息类似与free命令)
8053444 total:物理内存总量
7779224 used:已使用的内存总量
274220 free:空闲的内存总量(free+used=total)
359212 buffers:用作内核缓存的内存量
第五行:swap信息
8265724 total:交换分区总量
33840 used:已使用的交换分区总量
8231884 free:空闲交换区总量
4358088 cached Mem:缓冲的交换区总量,内存中的内容被换出到交换区,然后又被换入到内存,但是使用过的交换区没有被覆盖,
交换区的这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入进程信息区
PID:进程id
PPID:父进程id
RUSER:Real user name(看了好多,都是这样写,也不知道和user有什么区别,欢迎补充此处)
UID:进程所有者的id
USER:进程所有者的用户名
GROUP:进程所有者的组名
TTY:启动进程的终端名。不是从终端启动的进程则显示为?
PR:优先级
NI:nice值。负值表示高优先级,正值表示低优先级
P:最后使用的CPU,仅在多CPU环境下有意义
%CPU:上次更新到现在的CPU时间占用百分比
TIME:进程使用的CPU时间总计,单位秒
TIME+:进程所使用的CPU时间总计,单位1/100秒
%MEM:进程使用的物理内存百分比
VIRT:进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
SWAP:进程使用的虚拟内存中被被换出的大小
RES:进程使用的、未被换出的物理内存的大小
CODE:可执行代码占用的物理内存大小
DATA:可执行代码以外的部分(数据段+栈)占用的物理内存大小
SHR:共享内存大小
nFLT:页面错误次数
nDRT:最后一次写入到现在,被修改过的页面数
S:进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
COMMAND:命令名/行
WCHAN:若该进程在睡眠,则显示睡眠中的系统函数名
Flags:任务标志【2.8】perf
【2.8.1】perf top
Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399
Overhead Shared Object Symbol
7.28% perf [.] 0x00000000001f78a4
4.72% [kernel] [k] vsnprintf
4.32% [kernel] [k] module_get_kallsym
3.65% [kernel] [k] _raw_spin_unlock_irqrestore默认情况下perf top是无法显示信息的,需要sudo perf top或者echo -1 > /proc/sys/kernel/perf_event_paranoid
(在Ubuntu16.04,还需要echo 0 > /proc/sys/kernel/kptr_restrict)
即可以正常显示perf top
第一列:符号引发的性能事件的比例,指占用的cpu周期比例
第二列:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块
第三列:DSO的类型
[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库;
[k]表述此符号属于内核或模块
第四列:符号名,有些符号不能解析为函数名,只能用地址表示perf top 界面常用命令
h:显示帮助,即可显示详细的帮助信息
UP/DOWN/PGUP/PGDN/SPACE:上下和翻页
a:annotate current symbol,注解当前符号,能够给出汇编语言的注解,给出各条指令的采样率
d:过滤掉所有不属于此DSO的符号,非常方便查看同一类别的符号
P:将当前信息保存到perf.hist.N中
perf top常用选项
-e <event>:指明要分析的性能事件
-p <pid>:Profile events on existing Process ID (comma sperated list),仅分析目标进程及其创建的线程
-k <path>:Path to vmlinux,Required for annotation functionality,带符号表的内核映像所在的路径
-K:不显示属于内核或模块的符号
-U:不显示属于用户态程序的符号
-d <n>:界面的刷新周期,默认为2s,因为perf top默认每2s从mmap的内存区域读取一次性能数据
-g:得到函数的调用关系图
perf top --call-graph [fractal],路径概率为相对值,加起来为100%,调用顺序为从下往上
perf top --call-graph graph,路径概率为绝对值,加起来为该函数的热度【2.8.2】perf stat
perf stat用于运行指令,并分析其统计结果,虽然perf top也可以指定pid,但是必须先启动应用才能查看信息
perf stat能完整统计应用整个生命周期的信息
命令格式为:
perf stat [-e <EVENT> | --event=EVENT] [-a] <command>
perf stat [-e <EVENT> | --event=EVENT] [-a] — <command> [<options>]输出结果
Performance counter stats for 'system wide':
40904.820871 cpu-clock (msec) # 5.000 CPUs utilized
18,132 context-switches # 0.443 K/sec
1,053 cpu-migrations # 0.026 K/sec
2,420 page-faults # 0.059 K/sec
3,958,376,712 cycles # 0.097 GHz (49.99%)
574,598,403 stalled-cycles-frontend # 14.52% frontend cycles idle (49.98%)
9,392,982,910 stalled-cycles-backend # 237.29% backend cycles idle (50.00%)
1,653,185,883 instructions # 0.42 insn per cycle
# 5.68 stalled cycles per insn (50.01%)
237,061,366 branches # 5.795 M/sec (50.02%)
18,333,168 branch-misses # 7.73% of all branches (50.00%)
8.181521203 seconds time elapsed
输出参数说明
cpu-clock:任务真正占用的处理器时间,单位为ms,CPUs utilized = task-clock / time elapsed,CPU的占用率;
context-switches:程序在运行过程中上下文的切换次数
CPU-migrations:程序在运行过程中发生的处理器迁移次数,
Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU;
CPU迁移和上下文切换:发生上下文切换不一定会发生CPU迁移,而发生CPU迁移时肯定会发生上下文切换;
发生上下文切换有可能只是把上下文从当前CPU中换出,下一次调度器还是将进程安排在这个CPU上执行;
page-faults:缺页异常的次数,
当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,
但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常;
另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
cycles:消耗的处理器周期数,如果把被ls使用的cpu cycles看成是一个处理器的,那么它的主频为2.486GHz,
可以用cycles / task-clock算出
stalled-cycles-frontend:指令读取或解码的质量步骤,未能按理想状态发挥并行左右,发生停滞的时钟周期
stalled-cycles-backend:指令执行步骤,发生停滞的时钟周期
instructions:执行了多少条指令,IPC为平均每个cpu cycle执行了多少条指令
branches:遇到的分支指令数,branch-misses是预测错误的分支指令数【3】实例分析
场景一:CPU 密集型进程
终端1
stress --cpu 1 --timeout 600
终端2
-d 参数表示高亮显示变化的区域
watch -d uptime
..., load average: 1.00, 0.75, 0.39
分析说明
1 分钟的平均负载会慢慢增加到 1.00
终端3
-P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
mpstat -P ALL 5
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:30:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:30:11 all 50.05 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 49.95
13:30:11 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
13:30:11 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
分析说明
有一个 CPU 的使用率为 100%,但它的 iowait 只有 0
终端4
# 间隔5秒后输出一组数据
pidstat -u 5 1
13:37:07 UID PID %usr %system %guest %wait %CPU CPU Command
13:37:12 0 2962 100.00 0.00 0.00 0.00 100.00 1 stress
分析说明
stress 进程的 CPU 使用率为 100%场景二:I/O 密集型进程
终端1
stress -i 1 --timeout 600
终端2
watch -d uptime
..., load average: 1.06, 0.58, 0.37
分析说明
1 分钟的平均负载会慢慢增加到 1.06
终端3
# 显示所有CPU的指标,并在间隔5秒输出一组数据
mpstat -P ALL 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:41:28 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:41:33 all 0.21 0.00 12.07 32.67 0.00 0.21 0.00 0.00 0.00 54.84
13:41:33 0 0.43 0.00 23.87 67.53 0.00 0.43 0.00 0.00 0.00 7.74
13:41:33 1 0.00 0.00 0.81 0.20 0.00 0.00 0.00 0.00 0.00 98.99
分析说明
一个 CPU 的系统 CPU 使用率升高到了 23.87,而 iowait 高达 67.53%
终端4
# 间隔5秒后输出一组数据,-u表示CPU指标
pidstat -u 5 1
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
13:42:08 UID PID %usr %system %guest %wait %CPU CPU Command
13:42:13 0 104 0.00 3.39 0.00 0.00 3.39 1 kworker/1:1H
13:42:13 0 109 0.00 0.40 0.00 0.00 0.40 0 kworker/0:1H
13:42:13 0 2997 2.00 35.53 0.00 3.99 37.52 1 stress
13:42:13 0 3057 0.00 0.40 0.00 0.00 0.40 0 pidstat场景三:大量进程的场景
获取系统 CPU 个数命令
grep 'model name' /proc/cpuinfo | wc -l
1
分析说明
仅仅有一个 CPU
终端1
stress -c 8 --timeout 600
分析说明
终端2
uptime
..., load average: 7.97, 5.93, 3.02
分析说明
由于系统只有 1 个 CPU,明显比 8 个进程要少得多,因而,系统的 CPU 处于严重过载状态,平均负载高达 7.97
终端3
# 间隔5秒后输出一组数据
pidstat -u 5 1
14:23:25 UID PID %usr %system %guest %wait %CPU CPU Command
14:23:30 0 3190 25.00 0.00 0.00 74.80 25.00 0 stress
14:23:30 0 3191 25.00 0.00 0.00 75.20 25.00 0 stress
14:23:30 0 3192 25.00 0.00 0.00 74.80 25.00 1 stress
14:23:30 0 3193 25.00 0.00 0.00 75.00 25.00 1 stress
14:23:30 0 3194 24.80 0.00 0.00 74.60 24.80 0 stress
14:23:30 0 3195 24.80 0.00 0.00 75.00 24.80 0 stress
14:23:30 0 3196 24.80 0.00 0.00 74.60 24.80 1 stress
14:23:30 0 3197 24.80 0.00 0.00 74.80 24.80 1 stress
14:23:30 0 3200 0.00 0.20 0.00 0.20 0.20 0 pidstat场景四 分析 CPU 上下文切换对系统性能的影响
终端一
以10个线程运行5分钟的基准测试,模拟多线程切换的问题
sysbench --num-threads=10 --max-time=300 --max-requests=10000000 --test=threads run
终端二
# 每隔1秒输出1组数据(需要Ctrl+C才结束)
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
6 0 0 6487428 118240 1292772 0 0 0 0 9019 1398830 16 84 0 0 0
8 0 0 6487428 118240 1292772 0 0 0 0 10191 1392312 16 84 0 0 0
主要分析指标
cs 列的上下文切换次数从 35 骤然上升到了 139 万;
r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU 的个数,所以肯定会有大量的 CPU 竞争;
us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,
即 sy 列高达 84%,说明 CPU 主要是被内核占用了;
in 列:中断次数也上升到了 1 万左右,说明中断处理也是个潜在的问题;
终端三
# 每隔1秒输出1组数据(需要 Ctrl+C 才结束)
# -w参数表示输出进程切换指标,而-u参数则表示输出CPU使用指标
$ pidstat -w -u 1
08:06:33 UID PID %usr %system %guest %wait %CPU CPU Command
08:06:34 0 10488 30.00 100.00 0.00 0.00 100.00 0 sysbench
08:06:34 0 26326 0.00 1.00 0.00 0.00 1.00 0 kworker/u4:2
08:06:33 UID PID cswch/s nvcswch/s Command
08:06:34 0 8 11.00 0.00 rcu_sched
08:06:34 0 16 1.00 0.00 ksoftirqd/1
08:06:34 0 471 1.00 0.00 hv_balloon
08:06:34 0 1230 1.00 0.00 iscsid
08:06:34 0 4089 1.00 0.00 kworker/1:5
08:06:34 0 4333 1.00 0.00 kworker/0:3
08:06:34 0 10499 1.00 224.00 pidstat
08:06:34 0 26326 236.00 0.00 kworker/u4:2
08:06:34 1000 26784 223.00 0.00 sshd
从 pidstat 的输出可以发现,CPU 使用率升高是 sysbench 导致的,其 CPU 使用率已经达到 100%;
上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的 pidstat,以及自愿上下文切换频率最高的内核线程 kworker 和 sshd;
# 每隔1秒输出一组数据(需要 Ctrl+C 才结束)
# -wt 参数表示输出线程的上下文切换指标
$ pidstat -wt 1
08:14:05 UID TGID TID cswch/s nvcswch/s Command
...
08:14:05 0 10551 - 6.00 0.00 sysbench
08:14:05 0 - 10551 6.00 0.00 |__sysbench
08:14:05 0 - 10552 18911.00 103740.00 |__sysbench
08:14:05 0 - 10553 18915.00 100955.00 |__sysbench
08:14:05 0 - 10554 18827.00 103954.00 |__sysbench
...
sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但其子线程的上下文切换次数却有很多
终端四
/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信;
/proc/interrupts 提供了一个只读的中断使用情况;
# -d 参数表示高亮显示变化的区域
$ watch -d cat /proc/interrupts
CPU0 CPU1
...
RES: 2450431 5279697 Rescheduling interrupts
...
变化速度最快的是重调度中断(RES),又称为处理器间中断(Inter-Processor Interrupts,IPI),
该中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行,是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制;
参考致谢
本博客为博主的学习实践总结,并参考了众多博主的博文,在此表示感谢,博主若有不足之处,请批评指正。
【3】Ubuntu 14.10 下运行进程实时监控pidstat命令详解


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









