




Bert
论文
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
模型结构
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。
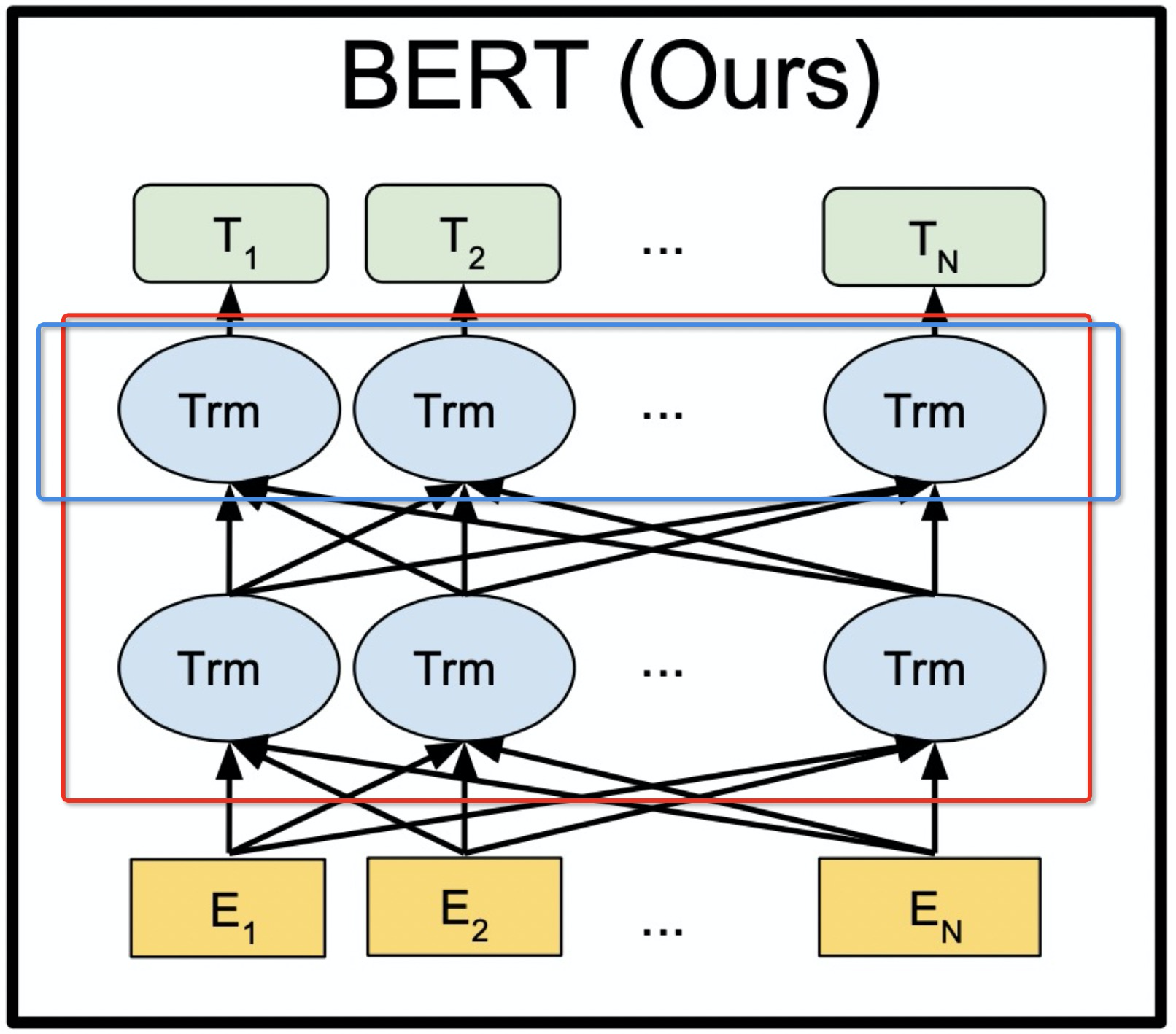
算法原理
BERT并没有采用整个的Transformer结构(Encoder+Decoder),仅仅使用了Transformer结构里的Encoder部分,BERT将多层的Encoder搭建一起组成了它的基本网络结构。
环境配置
注意dtk python torch apex 等版本要对齐
Docker(方式一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10.1-py37-latest
进入docker安装没有的依赖
docker run -dit --network=host --name=bert-pytorch --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.10.0-centos7.6-dtk-22.10.1-py37-latest
docker exec -it llama-tencentpretrain /bin/bash
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
#tensorflow安装包参考conda方式下载地址
pip install tensorflow-2.7.0+git67f0ade9.dtk2210-cp37-cp37m-manylinux2014_x86_64.whl
Dockerfile(方式二)
docker build -t bert:latest .
docker run -dit --network=host --name=bert-pytorch --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 bert:latest
docker exec -it bert-pytorch /bin/bash
#tensorflow安装包参考conda方式下载地址
pip install tensorflow-2.7.0+git67f0ade9.dtk2210-cp37-cp37m-manylinux2014_x86_64.whl
Conda(方式三)
#创建虚拟环境
conda create -n bert-pytorch python=3.7
关于本项目DCU显卡所需的工具包、深度学习库等均可从光合开发者社区下载安装。
其它依赖库参照requirements.txt安装:
pip install -r requirements.txt
数据集
pre_train 数据,本项目使用的是wiki20220401的数据,但数据集压缩后近20GB,解压后300GB下载速度慢,解压占大量空间。由于wiki数据集经常更新,官网并不保留旧版数据集,这里提供处理好的seq128和seq512的数据集网盘下载链接。
(seq128对应PHRASE1)链接:百度网盘 请输入提取码 提取码:l30u
(seq512对应PHRASE2)链接:百度网盘 请输入提取码 提取码:6ap2
这里使用服务器已有的wiki数据集服务器上有已经下载处理好的数据,预训练数据分为PHRASE1、PHRASE2
wiki数据集结构
──wikicorpus_en
│ ├── training
│ ├── wikicorpus_en_training_0.tfrecord.hdf5
│ ├── wikicorpus_en_training_1000.tfrecord.hdf5
│ └── ...
│ └── test
│ ├── wikicorpus_en_test_99.tfrecord.hdf5
│ ├── wikicorpus_en_test_9.tfrecord.hdf5
│ └── ...
#wiki数据集下载与处理示例
cd cleanup_scripts
mkdir -p wiki
cd wiki
wget https://dumps.wikimedia.org/enwiki/20200101/enwiki-20200101-pages-articles-multistream.xml.bz2 # Optionally use curl instead
bzip2 -d enwiki-20200101-pages-articles-multistream.xml.bz2
cd .. # back to bert/cleanup_scripts
git clone https://github.com/attardi/wikiextractor.git
python3 wikiextractor/WikiExtractor.py wiki/enwiki-20200101-pages-articles-multistream.xml # Results are placed in bert/cleanup_scripts/text
./process_wiki.sh '<text/*/wiki_??'
问答SQUAD1.1数据:
squadv1.1数据结构
├── dev-v1.1.json
└── train-v1.1.json
模型权重下载
用于squad训练的bert-large-uncased模型(已转换可直接使用) 提取密码:vs8d
bert-large-uncased_L-24_H-1024_A-16(需要转换)
bert-base-uncased_L-12_H-768_A-12(需要转换)
训练
squad训练
1.模型转换
#如果下载的是.ckpt格式的模型,需要转换为.ckpt.pt格式
python3 tf_to_torch/convert_tf_checkpoint.py --tf_checkpoint uncased_L-24_H-1024_A-16/bert_model.ckpt --bert_config_path uncased_L-24_H-1024_A-16/bert_config.json --output_checkpoint uncased_L-24_H-1024_A-16/model.ckpt.pt
2.参数说明
--train_file 训练数据
--predict_file 预测文件
--init_checkpoint 模型文件
--vocab_file 词向量文件
--output_dir 输出文件夹
--config_file 模型配置文件
--json-summary 输出json文件
--bert_model bert模型类型可选: bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased,bert-base-multilingual-cased, bert-base-chinese
--do_train 是否训练
--do_predict 是否预测
--train_batch_size 训练batch_size
--predict_batch_size 预测batch_size
--gpus_per_node 使用gpu节点数
--local_rank 基于GPU的分布式训练的local_rank(单卡设置为-1)
--fp16 混合精度训练
--amp 混合精度训练
3.运行
#单卡
./bert_squad.sh #单精度 (按自己路径对single_squad.sh里APP设置进行修改)
./bert_squad_fp16.sh #半精度 (按自己路径对single_squad_fp16.sh里APP设置进行修改)
--init_checkpoint使用model.ckpt-28252.pt或者自己转换好的model.ckpt.pt
#多卡
./bert_squad4.sh #单精度 (按自己路径对single_squad4.sh里APP设置进行修改)
./bert_squad4_fp16.sh #半精度 (按自己路径对single_squad4_fp16.sh里APP设置进行修改)
--init_checkpoint使用model.ckpt-28252.pt或者自己转换好的model.ckpt.pt
#多机多卡
#进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改hostfile改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定
cd 2node-run-squad
sh run_bert_squad_4dcu.sh (需要fp16可以在相应single文件APP中增加 --fp16 与 --amp参数)
--init_checkpoint使用model.ckpt-28252.pt或者自己转换好的model.ckpt.pt
PHRASE测试
1.参数说明
--input_dir 输入数据文件夹
--output_dir 输出保存文件夹
--config_file 模型配置文件
--bert_model bert模型类型可选: bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased,bert-base-multilingual-cased, bert-base-chinese
--train_batch_size 训练batch_size
--max_seq_length=128 最大长度(需要和训练数据相匹配)
--max_predictions_per_seq 输入序列中屏蔽标记的最大总数
--max_steps 最大步长
--warmup_proportion 进行线性学习率热身的训练比例
--num_steps_per_checkpoint 多少步保存一次模型
--learning_rate 学习率
--seed 随机种子
--gradient_accumulation_steps 在执行向后/更新过程之前,Accumulte的更新步骤数
--allreduce_post_accumulation 是否在梯度累积步骤期间执行所有减少
--do_train 是否训练
--fp16 混合精度训练
--amp 混合精度训练
--json-summary 输出json文件
2.PHRASE1
#单卡
./bert_pre1.sh #单精度 (按自己路径对single_pre1_1.sh里APP设置进行修改)
./bert_pre1_fp16.sh #半精度 (按自己路径对single_pre1_1_fp16.sh里APP设置进行修改)
#多卡
./bert_pre1_4.sh #单精度 (按自己路径对single_pre1_4.sh里APP设置进行修改)
./bert_pre1_4_fp16.sh #半精度 (按自己路径对single_pre1_4_fp16.sh里APP设置进行修改)
#多机多卡
#进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改hostfile改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定
cd 2node-run-pre
sh run_bert_pre1_4dcu.sh (需要fp16可以在相应single文件APP中增加 --fp16 与 --amp参数)
3.PHRASE2
#单卡
./bert_pre2.sh #单精度 (按自己路径对single_pre2_1.sh里APP设置进行修改)
./bert_pre2_fp16.sh #半精度 (按自己路径对single_pre2_1_fp16.sh里APP设置进行修改)
#多卡
./bert_pre2_4.sh #单精度 (按自己路径对single_pre2_4.sh里APP设置进行修改)
./bert_pre2_4_fp16.sh #半精度 (按自己路径对single_pre2_4_fp16.sh里APP设置进行修改)
#多机多卡
#进入节点1,根据环境修改hostfile,保证两节点文件路径一致,配置相同,按需修改hostfile改为ip a命令后对应节点ip的网卡名,numa可以根据当前节点拓扑更改绑定
cd 2node-run-pre
sh run_bert_pre2_4dcu.sh (需要fp16可以在相应single文件APP中增加 --fp16 与 --amp参数)
result

精度
| 训练 | 卡数 | batch size | 迭代计数 | 精度 |
|---|---|---|---|---|
| PHRASE1 | 1 | 16 | 634step | 9.7421875 |
| SQUAD | 1 | 16 | 3epoch | final_loss : 3.897481918334961 |
应用场景
算法类别
文本理解
热点行业
互联网,教育,科研
源码仓库及问题反馈
ModelZoo / Bert_pytorch · GitLab
参考资料
DeepLearningExamples/PyTorch/LanguageModeling/BERT at master · NVIDIA/DeepLearningExamples · GitHub




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











