







MiniGo
论文
Mastering the game of Go without human knowledge
模型结构
Minogo是一个基于深度强化学习的围棋程序,模型灵感来源于Google DeepMind开发的AlphaGo算法。
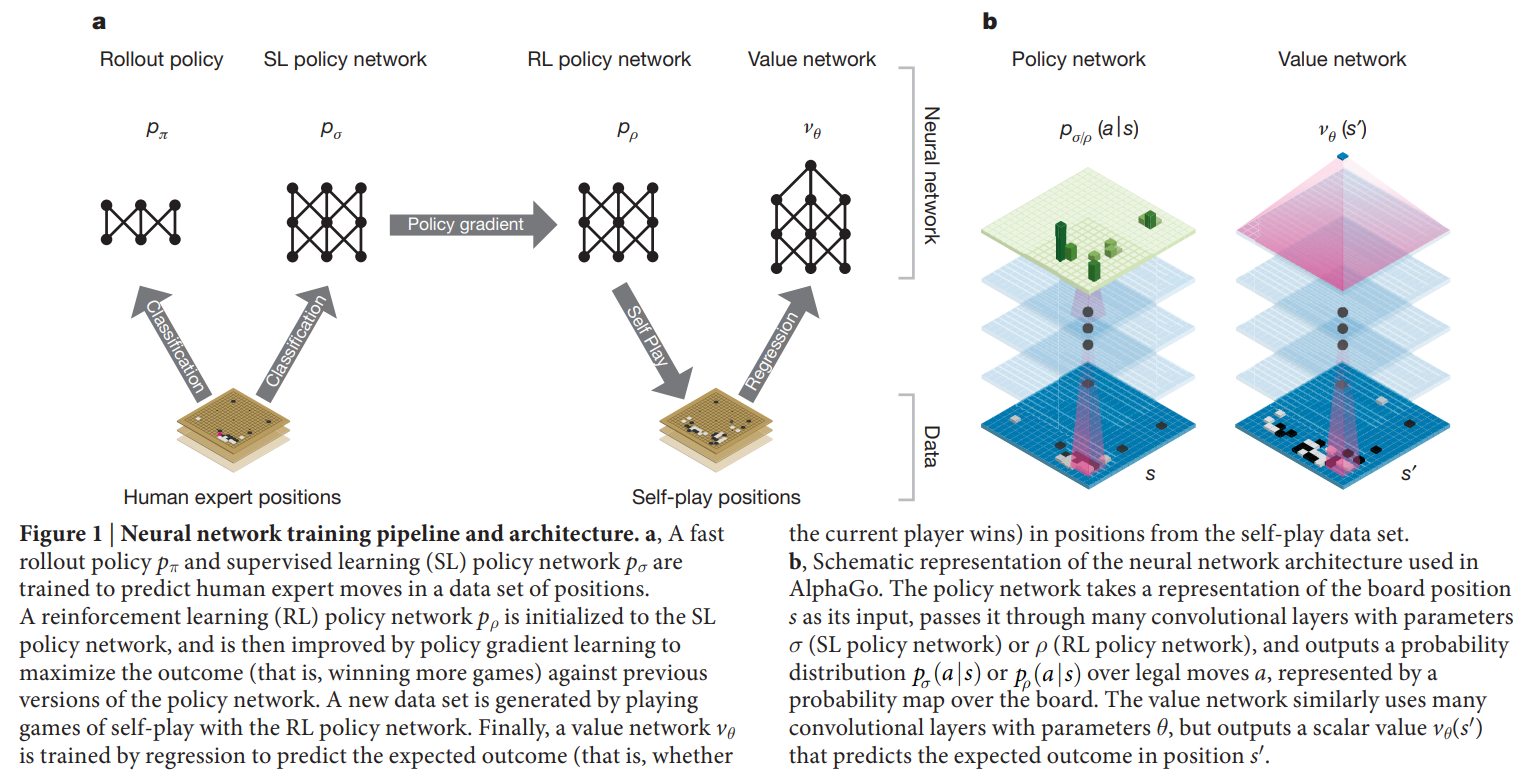
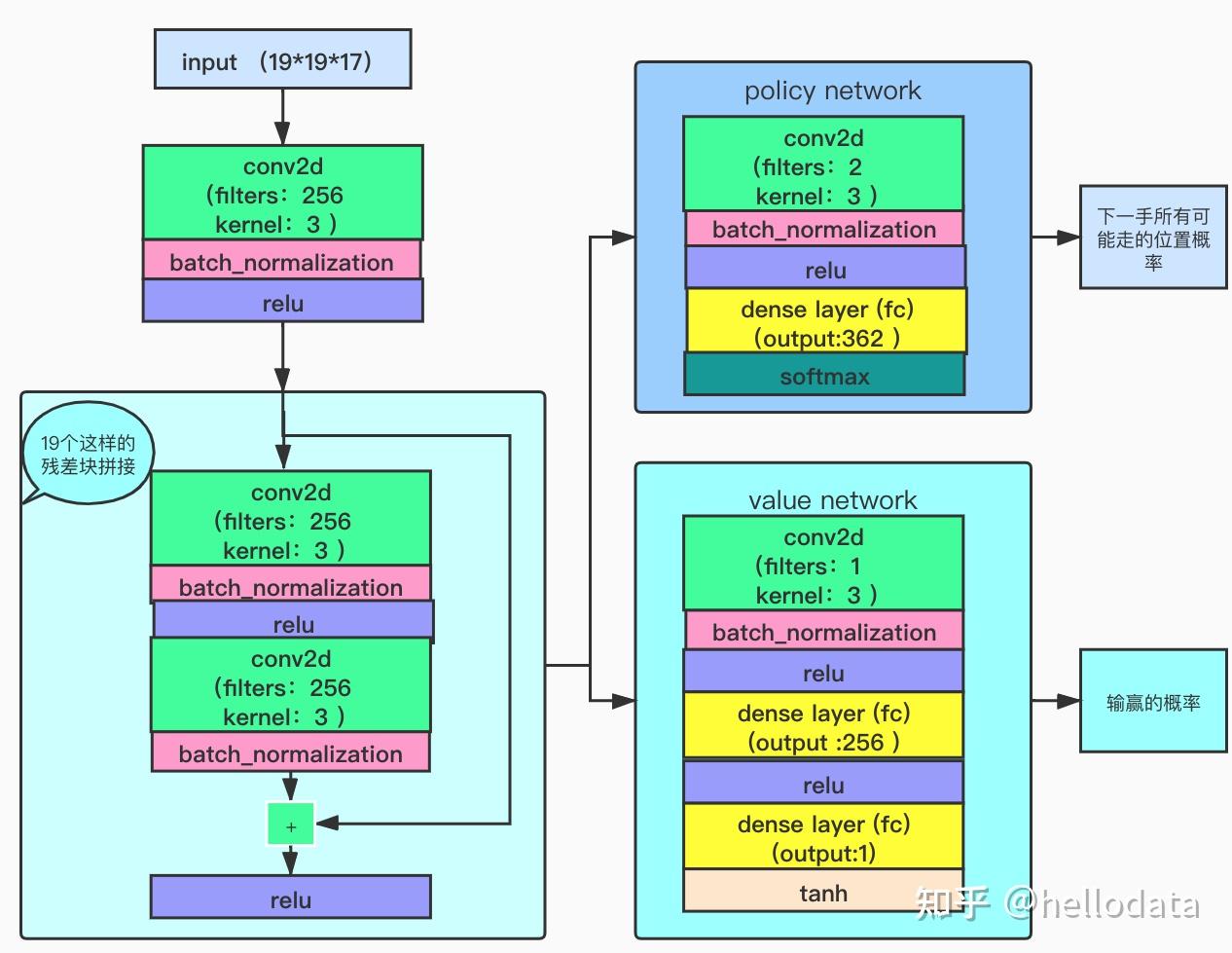
算法原理
该程序基于Tensorflow框架实现。Minigo的核心是AlphaZero论文中描述的强化学习循环。简单地说,使用当前一代网络权重的selfplay被用来生成游戏,这些游戏被用作训练数据来生成下一代网络权重。
环境配置
Docker (方法一)
提供光源拉取的训练的docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:mlperf-minigo-latest
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker run -it --name mlperf_minigo --shm-size=32G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> <Image ID> /bin/bash
Dockerfile (方法二)
docker build --no-cache -t mlperf_minigo:latest .
docker run -it --name mlperf_minigo --shm-size=32G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> <Image ID> /bin/bash
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
镜像版本依赖:
- DTK驱动:dtk22.04.2
- python: python3.8.2
测试目录:
/root/minigo
数据集
训练数据:所有的训练数据都是在强化学习循环的selfplay阶段生成的。 唯一需要下载的数据是checkpoint以及target model,下载数据可按照下述进行:
# Download & extract bootstrap checkpoint.
gsutil cp gs://minigo-pub/ml_perf/0.7/checkpoint.tar.gz .
tar xfz checkpoint.tar.gz -C ml_perf/
# Download and freeze the target model.
mkdir -p ml_perf/target/
gsutil cp gs://minigo-pub/ml_perf/0.7/target.* ml_perf/target/
训练
单机多卡
单机8卡进行性能&&精度测试
cd /root
source env.sh
cd /root/minigo
bash sbatch.sh >& log.txt &
result
精度
采用上述输入数据,加速卡采用Z100L * 8,可最终达到官方收敛要求,即达到目标精度50% win rate vs. checkpoint;
| 卡数 | 类型 | 进程数 | 达到精度 |
|---|---|---|---|
| 8 | FP32 | 8 | 50% win rate vs. checkpoint |
应用场景
算法类别
强化学习
热点应用行业
广媒,科研,金融




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











